超分算法TTSR:Learning Texture Transformer Network for Image Super-Resolution 基于参考图像Ref的超分辨率重建
这篇文章TTSR应该是第一次将transformer引入到超分任务中,且是基于参考图像的超分重建RefSR,文章发表在CVPR2020。基于参考图像的超分不同于单图像超分,更注重于图像细节的还原,通过迁移参考图像中的相似纹理来还原HR图像。基于参考图像的超分文章并不多,这种方法的局限性比较大。TTSR是基于SRNTT这篇文章进行了改进,加入注意力机制,能选择更相似的纹理来完成SR图像恢复。
原文链接:TTSR:Learning Texture Transformer Network for Image Super-Resolution[CVPR 2020]
SRNTT:Image Super-Resolution by Neural Texture Transfer
源码:https://github.com/researchmm/TTSR
TTSR:Learning Texture Transformer Network for Image Super-Resolution
- Abstract
- 1 Introduction
- 2 Method
-
- 2.1 Texture Transformer
-
- 2.1.1 Learnable Texture Extractor
- 2.1.2 Relevance Embedding
- 2.1.3 Hard-Attention
- 2.1.4 Soft-Attention
- 2.2 Cross-Scale Feature Integration
- 2.3 LOSS
- 3 Experiments
- 4 Conclusion
Abstract
图像超分辨率(SR),目的是从低分辨率图像(LR)中恢复真实纹理,以达到整张图像超清放大的要求。(就是细节更精确)事实上使用PSNR/SSIM这种评估方法只是一个全局的平均,在很难看出细节处理的好坏。本文不同于单图像超分SISR,是一种基于参考图像的超分RefSR,在先前的工作中,SRNTT表现较好,但并没有使用注意力机制来迁移纹理特征,也就是说在基于参考图像这种方法下并没有充分体现迁移方法的作用。因此在SRNTT的基础上,本文提出了一种类似Transformer结构的新方法,通过注意力可以发现深层特征对应,从而可以传递准确的纹理特征。
单图像超分SISR的输入是一张单独的图像,而基于参考图像的超分RefSR的输入是LR图像和一张高度相似的HR参考图像。
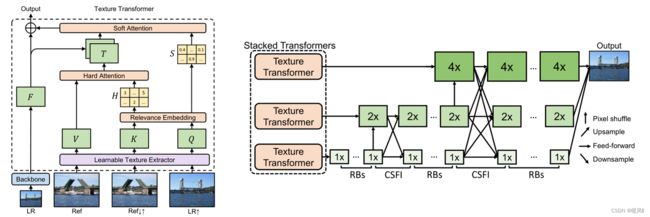
TTSR由四个模块组成,包括:DNN的可学习纹理提取器(learnable texture extractor by DNN),相关性嵌入模块(a relevance embedding module),用于纹理传递的硬注意力模块(hard-attention module for texture transfe)和用于纹理合成的软注意力模块(soft-attention module for texture synthesi)。能够有效地搜索与迁移高清的纹理信息,最大程度地利用了参考图像的信息,并正确地将高清纹理迁移到生成的超分辨率结果当中,解决纹理模糊纹理失真的问题。
TTSR可以以跨尺度的方式进一步堆叠,从而完成不同放大倍数的(例如,从x1倍、x2、x4倍放大比例)纹理恢复。
1 Introduction
对图像超分辨率的研究通常分为两种方式:单图像超分辨率(SISR)和基于参考的图像超分辨率(RefSR)。
- 传统的SISR通常会导致模糊效果,因为高分辨率(HR)纹理在重建的过程中被过度破坏、丢失,无法恢复。尽管提出了基于生成对抗网络(GANs)的SR方法来缓解上述问题,但由GANs产生的伪影进一步对图像SR任务构成了巨大挑战。
- 出现了基于参考图像的超分辨率技术。用一张与输入图像相似的高分辨率图像,辅助整个超分辨率的复原过程。从而图像超分问题由较为困难的纹理恢复/生成转化为了相对简单的纹理搜索与迁移,使得超分辨率结果在视觉效果上有了显著的提升。
为了解决这些问题,提出了一种新的用于图像超分辨率的纹理变换网络(TTSR)。
- DNN的可学习纹理提取器(LTE):提取纹理特征
- 相关性嵌入模块(RE):估计Q和K之间的相似性从而建立LR和Ref图像的相关性
- 用于纹理传递的硬注意力模块(HA):记录参考图像中与LR图像最相似的部分的位置
- 用于纹理合成的软注意力模块(SA):记录参考图像中与LR图像相似度最高的相似度
此外,还提出了一个跨尺度特征集成模块来堆叠纹理变换器,可以跨不同尺度学习特征,以实现更强大的特征表示。
2 Method
作者主要提出了一个Texture Transformer,这个结构内包含四个部分:可学习纹理提取器LTE、相关性嵌入RE、硬注意力模块HA、软注意力模块SA。从参考图像中提取与LR图像高度相似的纹理部分迁移到重建的LR图像中来填补细节。
再由TTSR堆叠来获得跨尺度表征。
首先看看TTSR的输入是 L R 、 R e f 、 R e f ↑ ↓ 、 L R ↑ LR、Ref、Ref↑↓、LR↑ LR、Ref、Ref↑↓、LR↑,分别代表LR图像、HR参考图像、4×双三次下采样再上采样参考图像和4×双三次上采样LR图像。Ref↓↑ 的获得依次应用双三次下采样和上采样,为了和LR↑图像在分辨率上保持一致。
2.1 Texture Transformer

2.1.1 Learnable Texture Extractor
纹理提取器目的是为了提取到适合图像生成任务的纹理信息。主流的方法是使用预训练好的VGG网络来提取浅层特征作为图像的纹理信息。
- 但是VGG网络的设计初衷是为了提取语义信息来完成图像分类识别,而高级的语义信息与低层级的纹理信息有着很大的差异。
- 此外,预训练并固定权重VGG网络缺乏灵活性,对不同任务的纹理特征提取是有差异的。
因此LTE模块提出了一种浅层的卷积神经网络,由五个卷积层和两个池化层组成。会在Transformer 的训练过程中不断更新参数。事实上,LTE网络就是从VGG网络中提取出的几层。该网络能够在训练中找到最适合图像生成任务的纹理信息,为后面的纹理搜索与迁移提供了很好的基础,进而更加有利于高质量结果的生成。贴一下网络结构。

LTE模块对输入的三张图像分别提取特征作为transformer的Q、K、V,分别代表查询Query、键Key、值Value。
- Q获取的是LR上采样图像(LR↑)的纹理特征,用于纹理检索
- K是参考图先下采样再上采样(Ref↓↑)的纹理特征,用于纹理检索
- V是参考图(Ref)的纹理特征,用于纹理迁移
整体步骤:首先Q在K中搜索出最相似的部分,但是K经过了模糊处理,所以用高清的V中对应部分迁移填补在LR重建图像中。
K为什么要先下采样再上采样?为了保持和LR上采样图像相同的分辨率和相似的清晰度。相似清晰度下能更好的比较语义或纹理特征,相同级别的相似度衡量更准确。(LR↑图像实际就是HR图像经过下采样再上采样)
具体来说就是:首先估计同样低清晰度下的Q与K的相似度,找到LR与Ref图像之间的相关性(纹理检索),这个相关性包括最相似的位置和相似的程度,根据注意力权重使用清晰度高的V将高清纹理特征迁移到要重建的图像中来恢复细节部分。
2.1.2 Relevance Embedding
在feature map的层面,估计Ref图像K和LR图像Q的相似性。输入图像后,通过特征提取器分为若干patch,然后将每个patch展成向量形式。Q、K中的任意两个patch向量就可以用余弦相似度表示。以内积的方式计算 Q 和 K 中的特征块两两之间的相关性。内积越大的地方代表两个特征块之间的相关性越强,可迁移的高频纹理信息越多。
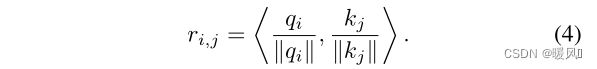
根据相关性 r i , j r_{i,j} ri,j计算得到一个硬注意力图H和一个软注意力图S。硬注意力图记录了K 中对应Q 中最相关的特征块的位置;软注意力图记录了这个最相关的特征块的相关程度,即内积大小。
2.1.3 Hard-Attention
在SRNTT中都是将Ref的整张feature map的特征迁移过来,直接使用一整个V的加权求和,很容易产生blur。因此作者在本文中进行了改进,只迁移那些最匹配的块。(并且按匹配程度的来控制其权重,也就是软注意力)
在硬注意力模块HA中,根据相似度 r i , j r_{i,j} ri,j,找到每个Q中特征块在K中最相似的位置块,记录在硬注意力图H中。从 V 中迁移对应位置的高清特征块,得到一个迁移高频纹理特征图 T。T 的每个位置包含了参考图像中与LR↑最相似的位置的高频纹理特征。T 随后会与backbone中的特征F进行通道级联,并通过一个卷积层得到融合的特征。

![]()
2.1.4 Soft-Attention
在软注意力模块SA中,根据相似度 r i , j r_{i,j} ri,j,算出每个Q中特征块在K中最相似的位置块的相似度,记录在软注意力图S中。相关性强的纹理信息能够赋予相对更大的权重;相关性弱的纹理信息,能够因小权重得到抑制。因此,软注意力模块能够使得迁移过来的高频纹理特征得到更准确的利用。

最后将迁移高频纹理特征图T、相关性权重S、LR图像特征F结合得到输出 F o u t F_{out} Fout
![]()
concat拼接,conv卷积,⊙元素相乘。
F是LR图像中得到的粗略提特征,是整张图像的框架,而根据权重图S将T中的参考细节添加到LR图像特征F中。就是用怎么的一个方式来利用参考图像中丰富清晰的细节来重建LR图像。靠HA找到最相似的部分,靠SA获得相似程度,两张图很像就多用一些,不像就少用一些参考图。
2.2 Cross-Scale Feature Integration

通过堆叠TTSR来获得多尺度重建。只是简单的堆叠很难产生好的重建效果,所以作者有针对性地提出了跨层级的特征融合机制,在堆叠过程使用了上下采样和卷积来连接,从而使得网络的特征表达能力增强,提高生成图像的质量。RBs指残差块,CSFI就是通过上采样、下采样将不同尺度特征进行concat。
2.3 LOSS
本文的训练损失函数由三部分组成,分别为重建损失,对抗损失和感知损失,公式如下:

Reconstruction loss:(MES - L1)

L r e c L_{rec} Lrec重建损失就是预测结果 I S R I_{SR} ISR与Ground Truth I H R I_{HR} IHR的L1损失。很多实验已经证明相对于 L2,L1 效果更好。
Adversarial loss:(GAN)

adv是GAN的损失,用的是Gradient Punishment梯度惩罚的形式,通过让梯度的值保持在一个范围内令训练更稳定。
Perceptual loss:(VGG + LTE)
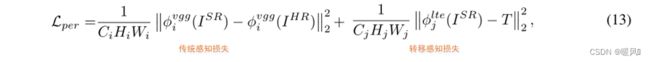
per(perceptual loss)感知损失,分为两部分。一部分选取了 VGG 网络特征级计算L2损失;另一部分,选取了文中训练得到的纹理提取器第j层纹理特征图,与迁移纹理特征T计算L2损失,这一项纹理感知损失可以将生成图像约束为具有与T相似的纹理特征,从而更加有效的迁移HR纹理。转移感知损失通过约束SR结果和Texture图的距离来促进网络学习参考图的纹理,最终提升视觉效果。
3 Experiments
训练:
RefSR数据集CUFED5。训练集包含11871对,每对由输入图像和参考图像组成。
测试:
CUFED5测试集中有126幅测试图像,每幅图像都附有4幅具有不同相似度的参考图像。
为了测试泛化能力:在Sun80、Urban100和Manga109上测试。
Sun80包含80幅自然图像,每幅图像都与多幅参考图像配对。
Urban100,将其LR图像视为参考图像。由于Urban100都是具有强自相似性的建筑图像,因此这种设计实现了自相似搜索。
Manga109,同样缺少参考图像,随机抽取该数据集中的HR图像作为参考图像。因为这个数据集是由线条、曲线和平面颜色区域构成的,这些都是常见的图案。
图像增强:随机水平和垂直翻转、旋转90°、180° 、和270°
输入每个patch为:9个40×40的LR,9个160×160的HR和Ref。
在YCbCr空间的Y通道上,根据PSNR和SSIM评估SR结果。
4 Conclusion
本文提出的TTSR方法是一种基于参考图像Ref方法的超分重建。使用类似Transformer的结构,凭借attention机制充分利用了LR图和参考图的相似关联性,对图像的恢复获得了较好的效果,得到了比较优秀的纹理表征。
TTSR的思路简单来说就是:首先找到LR与Ref图像之间的相关性(纹理检索),这个相关性包括最相似的位置和相似的程度,根据注意力权重使用HR版的Ref图像将高清纹理特征迁移到要重建的图像中来恢复细节部分。
基于Ref的重建方法并不是很多,因为要利用参考图像,而参考图像在实际应用时很难获取,其应用受到了很大的限制。
Landmark 模型通过图像检索技术,从网络上爬取与输入图像相似的高分辨率图像,再进一步通过图像配准操作,最终合成得到对应的超分辨率结果,其依赖过多,且速度会受到很大的影响。CrossNet 方法进一步优化上述图像配准过程,提出了基于光流估计的模型结构。但其结果的优劣很大程度上依赖于光流计算的准确与否,性能在很大程度上取决于LR和Ref图像之间的对齐质量,并且光流等对准方法耗时较长,大大限制了上述模型的适用性。最近的工作SRNTT在LR和Ref图像的VGG特征之间应用了patch匹配,以交换相似的纹理特征。然而,SRNTT忽略了原始图像和参考纹理之间的相关性,并将所有特征的迁移平等地馈送到主网络中。而本文的TTSR是在SRNTT基础上加入了注意力机制,进行了改进。但还是逃脱不了基于参考图像方法本身的缺陷。
最后祝各位科研顺利,身体健康,万事胜意~