基于Pytorch迁移学习+集成学习的水果霉变区分设计与实现
1.数据集的介绍
此次采用的数据集中有六种水果,六种水果都有自己的对应的好坏水果集, 数据量:一共12050张图片,包含训练集,测试集和验证集,训练集:共7240张图片,测试集:共1796张图片,验证集:共3014张图片,每一个图片的类型为(256,256,3)维度的图片, 我们对训练集的数据的不同类别进行了可视化。

图 1 训练数据集
可以看出每一个类别的数据分布还是很均匀的大约每一个水果的数据都有600个好的水果集和霉变的水果集,总共是有12个类别,通过大量真实数据图进行训练,训练数据样本图片如下:
 图 2. 训练数据样本
图 2. 训练数据样本
都是一些很日常生活的照片十分常见,这样有助于我们后续进行拓展应用开发
2.数据的分析和导入
通过导入数据包的相关路径进行数据的导入,先选择一个样例图进行展示并打印其相关的维数以及其图片的像素分布,为之后图像预处理的实现做准备。

图 3 样例图及其像素分布
可以看出整体图片数据的像素分布还是不太均匀的,不太适合我们的直接进行训练,所以要首先对此进行归一化和标准化。
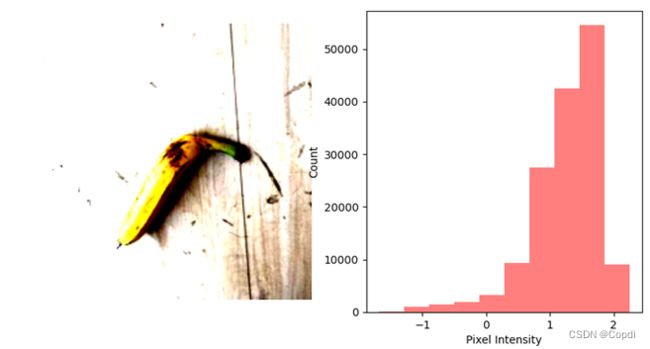
图 4 样例图及其像素分布
对数据进行了标准化和归一化,将数据平均值范围控制在[0,1],方差在1作用,实现对于数据的缩放,避免大数值区间的属性过分支配了小数值区间的属性,使数据在处理时更加方变快捷,也保证程序运行时收敛加快。.归一化和标准化参数选用[0.485, 0.456, 0.406], [0.229, 0.224, 0.225]这是是官方对于Imagenet图片数据统一的归一化标准化处理的参数,可以更加贴合我们后面预训练的模型网络
3数据的预处理
在没有对数据进行图像增广时,测试集和测试集的数据显示如下图:

图 5 验证集图像数据集
对训练集的数据进行分割,分割成训练集和测试集,并对进行了图像增广,我们对数据进行水平翻转、垂直翻转、角度旋转,更改图像的饱和度,设置随机放射变化随机等等,使得我们的图片呈现效果如下,对数据进行图像增广后,数据的方向、饱和度和亮度发生了变化,如下图
 图 6 图像增广数据集
图 6 图像增广数据集
通过这些变换,使得我们数据更有泛化性训练出来的网络结构健壮性更强。使得我们训练的模型更贴切于水果分类霉变这一数据集,同时后续这样的处理也会影响迁移学习之间的学习过程
4. 训练模型
整体使用迁移学习+集成学习的思路。首先选用densenet121,googlenet,resnet101,efficientnet进行迁移学习,在迁移学习中修改其输出层的相关参数,进行训练,训练完成后进行采用集成学习[10]将四个框架模型进行了集成得到了最终的模型。在迁移训练中神经网络主干特征提取部分所提取到的特征是通用的,我们将其冻结起来训练以加快训练效率,同时也防止权值被破坏。在冻结阶段,模型的主干被冻结了,特征提取网络不发生改变。
占用的显存较小,仅对网络进行微调。在解冻阶段,模型的主干不被冻结了,特征提取网络会发生改变。占用的显存较大,网络所有的参数都会发生改变。使用一个流程图进行说明,集成学习采用的就是boosting,相当于并行学习

将每一个网络对一个图片的预测结果进行累加堆积在一起,然后选出其中类别值预测值最大的那个作为我们的预测类别进行输出,实现起来也很简单.
同时我们也使用了tensorboard在中间不断的去记录每一个epoch的loss和acc相关值,同时保存最后每一个网络训练出来的最佳模型参数架构.存储到对应的文件夹下.

0~3分别对应四个网络架构的模型,里面记录了训练集和验证集中的acc和loss值以及,xxx_grid记录其相关最佳模型的各层参数值.
对于训练过程之中采用的是调优方式选用Adam优化和损失函数选用交叉熵损失函数,学习率调整使用ReduceLROnPlateau调整方法,基于epoch的acc值进行自动调整.冻结训练时Adam调优只针对于最后一层分类层的调优,而解冻训练则是对于全局网络做一个整体的调优.
4.测试模型的性能
使用混淆矩阵[11](Confusion Matrix),又称为可能性矩阵或错误矩阵。混淆矩阵是可视化工具。在图像精度评价中,主要用于比较分类结果和实际测得值,可以把分类结果的精度显示在一个混淆矩阵里面。来帮助我们分析整个模型,可以看出对应类别的预测值和真实值的分别情况,还可以看到模型将真实的标签误判成了啥标签,辅助我们进行对模型框架的调整.
而对于多分类问题,ROC曲线的绘制,我们首先将模型导入训练,将标签值使用独热化显示,使得标签值只由0和1组成, 1的位置表明了它的类别.同时在模型预测端口加一个softmax出口,要是分类器对该测试样本分类正确,则该样本标签中1对应的位置在概率矩阵P中的值是大于0对应的位置的概率值的。基于这两点,将标签矩阵L和概率矩阵P分别按行展开,转置后形成两列,这就得到了一个二分类的结果。所以,此方法经过计算后可以直接得到最终的ROC曲线。使用sklearn.metrics.roc_auc_score参数average值为micro帮助我们实现,同时计算出其对应的auc值,最后使用matplotlib函数库,来绘制出多分类的图
评价指标对模型进行评价包括:准确率,各个类别的精确率、召回率、特异性、F1-score、ROC曲线。下面给出相应指标的计算公式
准确率指的是对于所有预测结果为正例的样本中,真实标签真的是正样本的个数在其中的比例

图 8 准确率公式
召回率指的是对于所有真实标签为正例的样本中,预测结果真的是正样本的个数在其中的比例
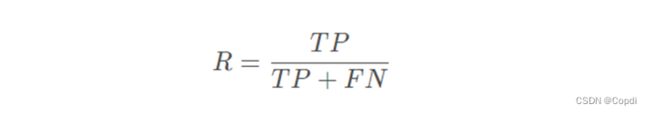
图 9 召回率公式
F1分数(F1 Score),是统计学中用来衡量二分类模型精确度的一种指标。它同时兼顾了分类模型的精确率和召回率。

图 10 F1分数
5.模型的拓展应用
使用PyQt5工具包,利用已经训练好的模型来实现自主选择相关的图片进行预测,先构建一个界面板块,同时加一个可以导入jpg文件的入口,使得用户可以选择自己本地的照片,然后进行上传,然后模型先调用后台的predict模块的函数进行对单个图片的预测,同时将结果返还给页面,页面在展示给用户
项目结果
1计算平台参数:
运行环境:
Anaconda:python 3.7
troch:1.10.0+cu113
torchaudio:0.10.0+cu113
torchvision:0.11.0+cu113
2.ROC曲线和混淆矩阵
根据评判标准,可得:
准确率(Accuracy)—— 针对整个模型,分类正确的样本个数占所有样本个数的比例。
精确率(Precision)——分类正确的正样本个数占分类器分成的所有正样本个数的比例。
灵敏度(Sensitivity)——就是召回率(Recall),分类正确的正样本个数占正样本个数的比例。
F1-Score——精确率和召回率的调和均值。
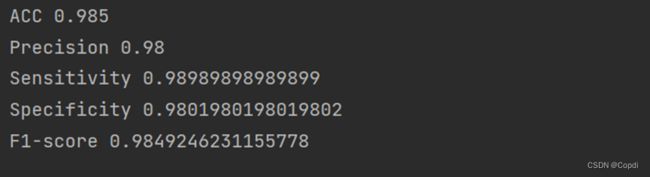
图 11 指标数据
ROC曲线指受试者工作特征曲线, 是根据一系列不同的二分类方式,以真阳性率(灵敏度)为纵坐标,假阳性率(1-特异度)为横坐标绘制成的曲线,接收者操作特征,roc曲线上每个点反映着对同一信号刺激的感受性。
ROC曲线有个很好的特性:当测试集中的正负样本的分布变换的时候,ROC曲线能够保持不变。在实际的数据集中经常会出现样本类不平衡,即正负样本比例差距较大,而且测试数据中的正负样本也可能随着时间变化。
我们对多分类进行ROC曲线的实现:

图 12 多分类ROC曲线
由上图ROC曲线可以看出,模型训练得很好,准确率较高。原因可能是数据量和分类的类别确实不是很多,且水果图片很贴切我们所用的迁移学习方法,所以训练模型得出的结果很好。
下面是对于多分类的情况进行评判:
多分类的混淆矩阵中,0-11的标签依次是Apple_Bad、Apple_Good、Banana_Bad、Banana_Good、Guava_Bad、Guava_Good、Lime_Bad、Lime_Good、Orange_Bad、Orange_Good、Pomegranate_Bad、Pomegranate_Good。显示标签自己与其他标签相对应的关系。
我们实现了对数据没有进行图像增广的模型预测,和实现图像增广的模型预测,并对两者进行了混淆矩阵的绘制,以及训练。
下图是没有进行图像增广的数据,绘制出的混淆矩阵。
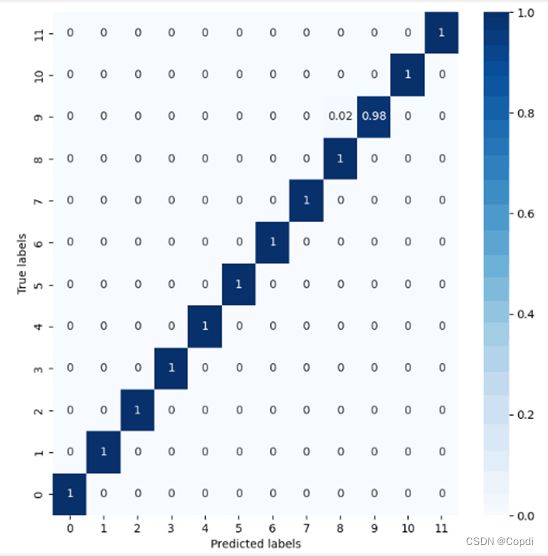
图 13 混淆矩阵
从图例可以看出,整体神经网络预测的效果很好,只有标签9对应着的是Orange_Good错预测成了Oragne_Bad,同时这个概率发生的可能性仅为0.02,而且其他类别的预测也与实际相当。分类效果显著。
下图是对数据进行了图像增广,所绘制出的混淆矩阵。
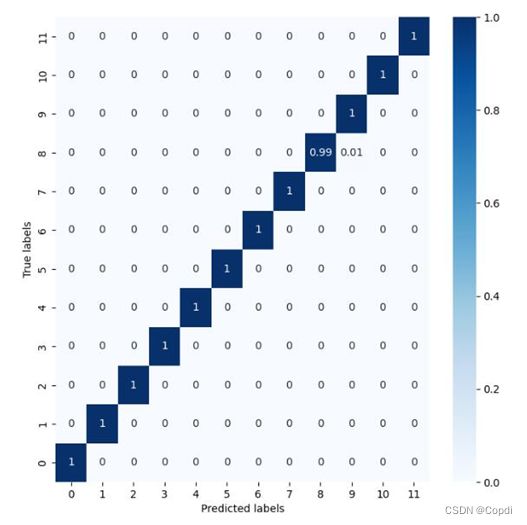
图 14 图像增广后的混淆矩阵
从图例可以看出,整体神经网络预测的效果很好,只有标签8对应着的是Orange_Bad错预测成了Oragne_Good,同时这个概率发生的可能性仅为0.01,而且其他类别的预测也与实际相当,分类效果显著。
基于图像增广的数据:
损失值:0.0121 准确率:0.9990
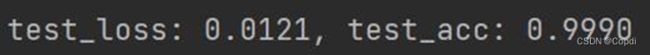
图 15 基于图像增广的结果
可以得出使用了图像增广的在冻结阶段,因为图像的相关变化和扭曲使得我们的数据变得识别更难,但是解冻通过全局的修改可以使得我们的网络结构更加贴合我们的实际应用取得了更好的结构。虽然识别的准确率提升不大,但是对于理解整个网络也有很好的作用
3迁移学习各项网络参数
3.1densenet121_0的迁移学习效果
训练结果如下,通过tensorborad图像我们可以看出,经过10次冻结和解冻训练后,训练集精度最后为99.68%,经过10次冻结和解冻训练后,测试集精度最后为99.85%,Tensorborad绘制的热力图,我们可以看到随着迭代次数的增加,每次训练的准确率集中于90%-99%,说明迁移学习效果良好,随着迭代次数的增加,每次训练的损失越来越小,说明迁移学习效果良好。

 图 16 densenet121_0的迁移学习效果
图 16 densenet121_0的迁移学习效果
使用densenet121_0预训练模型的网络参数:
图 17 densenet121_0预训练模型的网络参数
3.2googlenet的迁移学习效果
类似的,训练集精度最后为99.43%,经过10次冻结和解冻训练后,测试集精度最后为99.49%,热力图中,我们可以看到随着迭代次数的增加,每次训练的准确率集中于90%-98%,说明迁移学习效果良好,随着迭代次数的增加,每次训练的损失越来越小,说明迁移学习效果良好。

 图 19 googlenet的迁移学习效果
图 19 googlenet的迁移学习效果
使用googlenet预训练模型的网络参数:

图 20 googlenet预训练模型的网络参数
3.3resnet101的迁移学习效果
类似的,训练集精度最后为99.64%,经过10次冻结和解冻训练后,测试集精度最后为99.49%,热力图中,我们可以看到随着迭代次数的增加,每次训练的准确率集中于90%-98%,说明迁移学习效果良好,随着迭代次数的增加,每次训练的损失越来越小,说明迁移学习效果良好。

 图 21 resnet101的迁移学习效果
图 21 resnet101的迁移学习效果
使用resnet101预训练模型的网络参数:

图 22 resnet101预训练模型的网络参数
3.4efficientnet的迁移学习效果
类似的,训练集精度最后为99.78%,经过10次冻结和解冻训练后,测试集精度最后为99.70%,热力图中,我们可以看到随着迭代次数的增加,每次训练的准确率集中于90%-99%,说明迁移学习效果良好,随着迭代次数的增加,每次训练的损失越来越小,说明迁移学习效果良好。

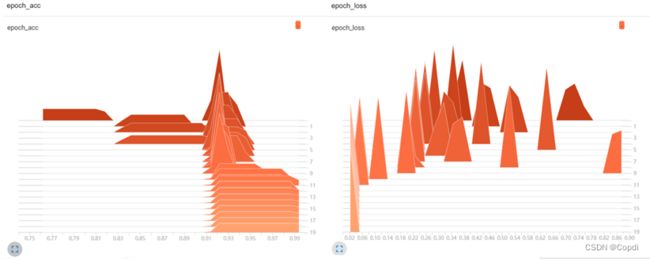
图 23 efficientnet的迁移学习效果
使用efficientnet_b3预训练模型的网络参数:

图 24 efficientnet_b3预训练模型的网络参数
4PyQt的拓展应用
最后的测试中我们使用PyQt进行图形界面的操作,对实际图片进行预测。PyQt是一个Python模块集。它有超过300类,将近6000个函数和方法,它是一个多平台的工具包。
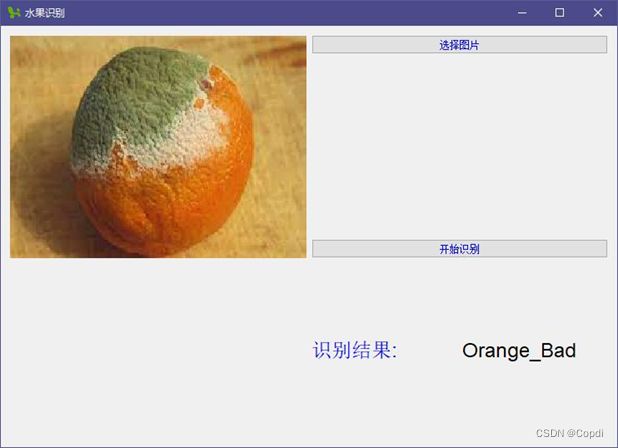
图 25 PyQt图形界面
选择网络上的随机相关图片,进行测试,可以看出测试的效果还是很不错的,成功的预测出来了.
总结:
本文提出通过使用迁移学习+集成学习的思想来实现对于常见水果的好坏进行分类,使用Pytorch官方基于imageNet所训练好成熟框架体系,选择了机器学习界十分流行的四大网络架构densenet,googlenet,resnet,efficientnet使用迁移学习的办法,只修改其输出层的相关参数,进行冻结训练,在迭代训练过10次之后,对模型进行了解冻训练,使其可以修改整个网络结构参数,让我们的网络结构更加的贴合我们实际所使用的分类图像,同时四个网络训练框架训练完成之后,采用集成学习的思想,将四个框架模型进行了集成得到了我们最终的网络架构,同时为了提升数据的泛化性,对实验数据进行了随机的裁剪,色调调节,归一化标准化,随机放射变化等一系列图像的预处理和图像增广。
最后在测试阶段,我们训练的网络架构在测试集上的表现预测的准确率也达到了99.9%,可以看出我们整个模型具有特别好的分类效果,只有很小的几率会发生错误,同时我们将模型进行导出,使用PyQt包,进行了扩展应用,用户可以使用该部分代码,手动选择一张图片,进行识别。
相关资源获取:包括代码,文档,数据集,ppt,还有已经训练好的模型
基于Pytorch的迁移学习+集成学习的水果霉变区分的设计与实现-机器学习文档类资源-CSDN下载