python数据分析之描述性统计分析
目录
一、数据获取(可用数据集):
二、python常用的工具包:(即用即查)
三、简单数据分类:
四、基本的描述性分析
1、数据预览
2、异常值分析——需要对数据进行单变量及整体异常值分析(具体问题具体分析)
3、对比分析
4、分布分析
五、数据简单可视化分析:matplotlib;seaborn;plotly
1、柱状图
2、直方图
3、箱线图
4、折线图
5、饼图
一、数据获取(可用数据集):
1、Kaggle&天池(大数据竞赛平台);
2、UCI数据集网站(包含多领域数据);
3、scikit-learn网址(适合学习阶段)
二、python常用的工具包:(即用即查)
数据分析工具:numpy ;scipy ;pandas
数据可视化工具:matplotlib
数据挖掘与建模工具:scikit-learn;TensorFlow
官方主页:NumPy 官方主页:SciPy 官方主页:Matplotlib — Visualization with Python
官方主页:scikit-learn: machine learning in Python — scikit-learn 0.16.1 documentation官方主页:pandas - Python Data Analysis Library
三、简单数据分类:
1、定类数据;
2、定序数据;
3、定距数据(间隔):可以界定数据大小同时,可测定差值,但无绝对零点,乘除无意义。例如温度。
4、定比数据(比率):可以界定数据大小,可测定差值,有绝对零点,乘除有意义,最常见的数值型数据。
四、基本的描述性分析
1、数据预览
df=pd.read_csv("D:/Users/DXX/Desktop/dxx.code/Python学习/HR_comma_sep.csv")
df.info()
df.describe()
df.sample(n=10) #抽样个数
df.sample(frac=0.0005) #抽样百分比info()——用于获取 DataFrame 的简要摘要,以便快速浏览数据集
describe()——用于对数据进行统计学估计,输出行名分别为:count(行数),mean(平均值),std(标准差),min(最小值),25%(第一四分位数),50%(第二四分位数),75%(第三四分位数),max(最大值)。


2、异常值分析——需要对数据进行单变量及整体异常值分析(具体问题具体分析)
###对每组变量进行异常值分析
#"satisfaction_level"
sl_s=df["satisfaction_level"]
sl_s.describe()
sl_s[sl_s.isnull()]
df[sl_s.isnull()]
sl_s=sl_s.dropna() #dropna()删除nan;fillna()填充nan
np.histogram(sl_s.values,bins=np.arange(0.0,1.1,0.1)) #负偏
#"last_evaluation"
le_s=df["last_evaluation"]
le_s.describe()
le_s[le_s<=1]
q_low=le_s.quantile(q=0.25)
q_high=le_s.quantile(q=0.75)
q_interval=q_high-q_low
k=1.5
le_s=le_s[le_s>q_low-k*q_interval][le_samh_s.quantile(q=0.25)-1.5*(amh_s.quantile(q=0.75)-amh_s.quantile(q=0.25))][amh_s 最后实现:将数据中的nan值、超出正常范围的取值和不正确的属性值去除
3、对比分析
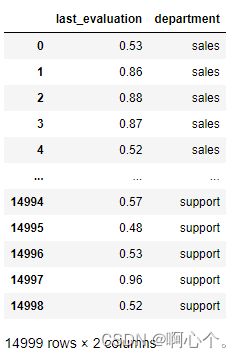
print(df.iloc[:,[1,8]])
df.loc[:,["last_evaluation","department"]]
#loc和iloc的区别:loc按照表格名称索引;iloc按照位置索引;loc和iloc的区别:loc按照表格名称索引;iloc按照位置索引
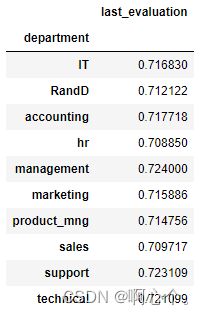
#分组,并计算均值
df.loc[:,["last_evaluation","department"]].groupby("department").mean()
#分组,应用匿名函数lambda进行组内运算
df.loc[:,["average_montly_hours","department"]].groupby("department")["average_montly_hours"].apply(lambda x:x.max()-x.min()) #自定义计算极差
groupby()——主要的作用是进行数据的分组以及分组后地组内运算(简单的均值计算 or 指自定义匿名函数运算)

4、分布分析
import scipy.stats as ss
import pandas as pd
import numpy as np
ss.norm #生成一个正态分布的对象
ss.norm.stats(moments="mvsk") #正态分布的均值;方差;偏度;峰度;
ss.norm.pdf(0.0) #x=0对应的概率密度函数值
ss.norm.ppf(0.9) #取值范围在[0,1]——累积分布函数为0.9对应的x值
ss.norm.cdf(2) #x为2时,累积分布函数的取值.(范围[0,1])
ss.norm.cdf(2)-ss.norm.cdf(-2)
ss.norm.rvs(size=10) #生成10个正态分布的数据
#(其他用法同正态分布)
ss.chi2 #卡方分布
ss.t #t分布
ss.f #f分布 五、数据简单可视化分析:matplotlib;seaborn;plotly
1、柱状图
###柱状图
plt.bar(np.arange(len(df["salary"].value_counts())),df["salary"].value_counts()) #arange()生成一个指定1终点2起点和3步长的列表
plt.show()
2、直方图
###直方图
sns.displot(df["satisfaction_level"],bins=10,kde=True) #kde=True有曲线
plt.show() 
3、箱线图
###箱线图
sns.boxplot(y=df["time_spend_company"])
sns.boxplot(x=df["time_spend_company"],saturation=0.75,whis=3) #whis上界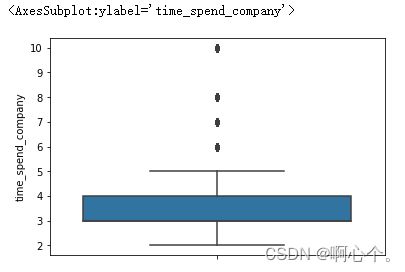

4、折线图
###折线图
sns.pointplot(x="time_spend_company",y="left",data=df)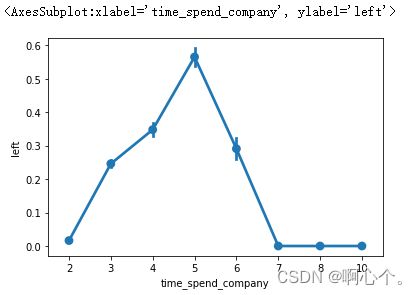
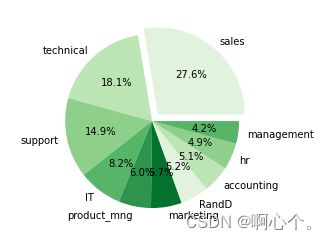
5、饼图
###饼图
lbs=df["department"].value_counts().index
explodes=[0.1 if i=="sales" else 0 for i in lbs] #与其他类别分隔开
plt.pie(df["department"].value_counts(normalize=True),explode=explodes,labels=lbs,autopct="%1.1f%%",colors=sns.color_palette("Greens"))