LSTM学习
文章目录
- 前言
- 文献阅读
-
- 摘要
- 贡献
- 方法
- 评价指标
- 结论
- LSTM学习
- 总结
前言
This week,a paper which mainly proposes a novel DL framework combining multiple nested long short term memory networks (MTMC-NLSTM) for accurate AQI forecasting has been read.In addition,the Long Short Term Memory neural network ,mainly including the process of LSTM forward propagation with code has been studied.
本周阅读文献《Multivariate Air Quality Forecasting With Nested Long Short Term Memory Neural Network》,这篇文献主要提出了一种结合多个嵌套长短期记忆网络的深度学习框架进行AQI预测;然后对LSTM进行学习,主要学习了用代码实现LSTM前向传播的过程。
文献阅读
题目:Multivariate Air Quality Forecasting With Nested Long Short Term Memory Neural Network
作者:Jin, N (Jin, Ning); Zeng, YK (Zeng, Yongkang); Yan, K (Yan, Ke) ; Ji, ZW (Ji, Zhiwei)
摘要
基于人工智能的空气质量指数(AQI)预测是可持续和智能工业环境设计领域的研究热点。现有机器学习(ML)和深度学习(DL)技术在提供准确预测结果以保护环境方面存在两大主要障碍主要,分别是不同AQI成分之间的相互相关性以及高度波动的AQI模式变化。该文提出一种结合多个嵌套长短期记忆网络的深度学习框架(MTMC-NLSTM),在联邦学习的指导下,进行准确的AQI预测。将所提出的MTMC-NLSTM模型的性能与传统的ML模型、DL方法以及混合DL模型进行了比较。实验结果表明,所提方法的性能优于所有比较模型。
贡献
本文主要研究将LSTM网络升级为嵌套LSTM网络(NLSTM),它在每个LSTM单元中额外增加了一个嵌套LSTM单元。提出一种用于多元AQI数据预测的多任务多通道(MTMC)NLSTM网络(MTMC-NLSTM)。利用离散平稳小波变换(DSWT)将原始数据按频率分解为多个子信号。然后,每个子信号都附加一个NLSTM模型,用于短期AQI预测。
1.采用NLSTM进行AQI分量预测。NLSTM神经网络于2018年提出。这是第一个利用NLSTM进行AQI成分预测的工作。在此基础上,对NLSTM进行扩展,提出多通道NLSTM结构。
2.基于联邦学习的多任务多通道 NLSTM 神经网络。本文提出一种MTMC算法来预测AQI的六个组成部分,而不是分别训练和测试AQI的六个组成部分,同时通过联邦学习启蒙。所提出的MTMC学习结构通过同时考虑AQI不同分量之间的内部相关性,增强了数据驱动的预测性能。
3.综合比较研究。将所提出的MTMC-NLSTM模型的性能与传统机器学习(ML)模型的性能进行了比较,包括多层感知(MLP),支持向量回归(SVR)和各种DL模型。所提方法的性能优于所有比较的现有模型。
方法
AQI预测框架的流程图如下:
![]()
输入AQI数据,对于每个分量,先对数据进行归一化处理,然后进行三级小波变换,用提出的神经网络对子信号进行训练。
离散平稳小波变换
小波变换(WT)是一种数据预处理方法,具有良好的数据稳定性能。本文采用具有多贝西小波基函数的DSWT将原始数据分解为多个子信号,包括去噪的低频分量和去噪高频分量。分解后,将原始数据中混合的信息解析为多个子信号,从而提高预测精度。
NLSTM
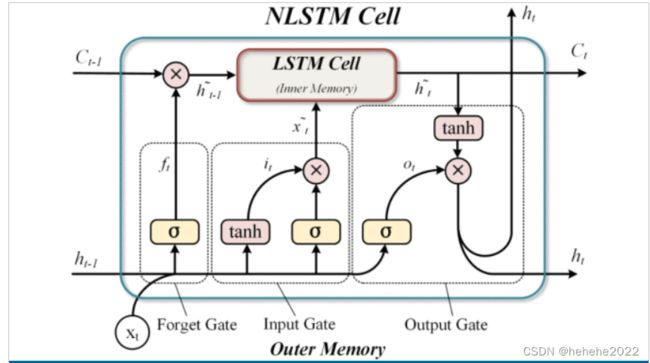 NLSTM 存储单元将另一个 LSTM 内存单元嵌套到原始 LSTM 单元中。外部存储单元可以自由地选择性地读写内部单元的相关长期信息。总体而言,这种结构提高了原始 LSTM 神经网络结构的鲁棒性,能够记忆和处理长期历史信息。在 LSTM 中,输出门遵循的原则是,与当前时间步长无关的信息仍然值得记住。按照上述逻辑,NLSTM在预测具有波动变化的时间序列数据方面更具优势。
NLSTM 存储单元将另一个 LSTM 内存单元嵌套到原始 LSTM 单元中。外部存储单元可以自由地选择性地读写内部单元的相关长期信息。总体而言,这种结构提高了原始 LSTM 神经网络结构的鲁棒性,能够记忆和处理长期历史信息。在 LSTM 中,输出门遵循的原则是,与当前时间步长无关的信息仍然值得记住。按照上述逻辑,NLSTM在预测具有波动变化的时间序列数据方面更具优势。
存储单元状态的更新ct是通过添加两部分制成的,即
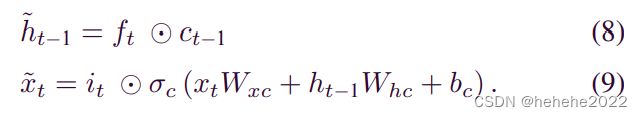
使用另一个 LSTM 单元替换ct普通 LSTM 模型中的计算方程构成 NLSTM 单元。外部 LSTM 称为外部存储器,内部 LSTM 称为内部存储器。在普通的LSTM单元中,存储单元的状态ct更新如下:
ct=h~t−1 +x~t
NLSTM 单元中,该过程被内部 LSTM 单元取代,其中xt和ht−1分别是短期和长期记忆输入。内部LSTM单元的结构与普通单元相同,如下所示:
![]()

所提出的预测方法的整个过程包括以下三个主要步骤:
步骤1:使用零分归一化对六个AQI时间序列数据进行归一化。然后使用小波变换将归一化AQI数据的每个样本分解为四个子信号。
步骤2:将步骤1处理的数据分为训练集和测试集,作为MTMC神经网络的输入。该网络有 24 个输入对应于 24 个子信号,6 个输出对应于六个 AQI 的预测值。网络通过基于训练集中的 24 个子信号拟合六个 AQI 的实际值来训练。在训练过程中,训练集的 5% 被拆分为验证集。训练神经网络时,AQI 的预测是基于测试集生成的。
第 3 步:将步骤 2 中获得的预测非规范化为原始量级。然后对预测结果进行评估,根据误差的严重性和拟合的有效性来检查预测性能。
评价指标
四个评估指标,即平均绝对误差 (MAE)、均方根误差 (RMSE)、平均绝对百分比误差 (MAPE) 和 r 平方 (R2),对预测的准确性进行了评价,验证了所提方法的有效性。
实验结果

模型在四个评估指标方面优于所有比较方法,包括MAE,RMSE,MAPE和R2.所提出的MCMT-NLSTM神经网络框架提供了更好的原始数据拟合,从而得到更准确的预测结果。
结论
本文的贡献是用于多元空气污染物浓度预测的创新MTMC学习框架。多元AQI数据的训练和预测过程并行进行,与联邦学习相启发。根据实验结果,所提方法能够非常接近地跟踪实际AQI,MAE,RMSE和MAPE值均小于3。对空气污染的准确预测支持了环境管理决策,并通过向政府提供及时的环境信息对人类健康至关重要。
LSTM学习
LSTM的API:
CLASS torch.nn.LSTM(*args, **kwargs)的参数:
input_size – The number of expected features in the input x(输入序列特征的大小)
hidden_size – The number of features in the hidden state h(h的大小)
num_layers – Number of recurrent layers. (堆叠的层数) bias – If False, then the layer does not use bias weights b_ih and b_hh. Default: True(决定 b_ih 和 b_hh是否可以丢弃)
batch_first – If True, then the input and output tensors are provided as (batch, seq, feature) instead of (seq, batch, feature). Note that this does not apply to hidden or cell states. See the Inputs/Outputs sections below for details. Default: False(默认batch在中间一维)
dropout – If non-zero, introduces a Dropout layer on the outputs of each LSTM layer except the last layer, with dropout probability equal to dropout. Default: 0
bidirectional – If True, becomes a bidirectional LSTM. Default: False(双向)
proj_size – If > 0, will use LSTM with projections of corresponding size. Default: 0(LSTMP,为了减小LSTM 的参数和计算量)
传入的输入Inputs: input, (h_0, c_0)
input:输入序列,大小为(N,L,H in )
h_0:初始值

输出:Outputs: output, (h_n, c_n)
output:模型的序列输出,大小为(L,N,D∗Hout )
演示调用官方的LSTM的API:
#定义常量,bs块大小,T时间
import torch
import torch.nn as nn
# 定义常量
bs, T, i_size, h_size = 2, 3, 4, 5
# proj_size = 3
input = torch.randn(bs, T, i_size) # 输入序列
c0 = torch.randn(bs, h_size) # 初始值,不需要训练
h0 = torch.randn(bs, h_size)
# h0 = torch.randn(bs, proj_size)
# 调用官方LSTM API
lstm_layer = nn.LSTM(i_size, h_size, batch_first=True)
# lstm_layer = nn.LSTM(i_size, h_size, batch_first=True, proj_size=proj_size)
output, (h_final, c_final) = lstm_layer(input, (h0.unsqueeze(0), c0.unsqueeze(0)))
print(output)
print(output.shape, h_final.shape, c_final.shape)
输出
tensor([[[ 0.0646, 0.2626, -0.4449, 0.1008, -0.3899],
[-0.0540, 0.4603, -0.3255, 0.1206, -0.1900],
[ 0.0450, 0.1745, -0.0695, 0.0960, -0.2173]],
[[-0.1420, -0.0881, 0.3784, 0.0850, -0.1860],
[-0.0081, 0.0408, 0.0051, 0.4927, -0.1601],
[-0.0079, 0.0765, 0.1276, 0.1734, -0.2499]]],
grad_fn=)
上面是调用LSTM的API,下面写LSTM的模型实现前向传播的过程:
def lstm_forward(input, initial_states, w_ih, w_hh, b_ih, b_hh):
h0, c0 = initial_states # 初始状态
bs, T, i_size = input.shape
h_size = w_ih.shape[0] // 4
prev_h = h0
prev_c = c0
batch_w_ih = w_ih.unsqueeze(0).tile(bs, 1, 1) # [bs, 4*h_size, i_size]
batch_w_hh = w_hh.unsqueeze(0).tile(bs, 1, 1) # [bs, 4*h_size, h_size]
output_size = h_size
output = torch.zeros(bs, T, output_size) # 输出序列
for t in range(T):
x = input[:, t, :] # 当前时刻的输入向量,[bs, i_size]
w_times_x = torch.bmm(batch_w_ih, x.unsqueeze(-1)) # [bs, 4*h_size, 1]
w_times_x = w_times_x.squeeze(-1) # (bs, 4*h_size)
w_times_h_prev = torch.bmm(batch_w_hh, prev_h.unsqueeze(-1)) # [bs, 4*h_size, 1]
w_times_h_prev = w_times_h_prev.squeeze(-1) # [bs, 4*h_size]
# 分别计算输入门(i)、遗忘门(f)、cell门(g)、输出门(0)
i_t = torch.sigmoid(w_times_x[:, :h_size] + w_times_h_prev[:, :h_size] + b_ih[:h_size] + b_hh[:h_size])
f_t = torch.sigmoid(w_times_x[:, h_size:2 * h_size] + w_times_h_prev[:, h_size:2 * h_size]
+ b_ih[h_size:2 * h_size] + b_hh[h_size:2 * h_size])
g_t = torch.tanh(w_times_x[:, 2 * h_size:3 * h_size] + w_times_h_prev[:, 2 * h_size:3 * h_size]
+ b_ih[2 * h_size:3 * h_size] + b_hh[2 * h_size:3 * h_size])
o_t = torch.sigmoid(w_times_x[:, 3 * h_size:4 * h_size] + w_times_h_prev[:, 3 * h_size:4 * h_size]
+ b_ih[3 * h_size:4 * h_size] + b_hh[3 * h_size:4 * h_size])
prev_c = f_t * prev_c + i_t * g_t
prev_h = o_t * torch.tanh(prev_c)
output[:, t, :] = prev_h
return output, (prev_h, prev_c)
output_custom, (h_final_custom, c_final_custom) = lstm_forward(input, (h0, c0), lstm_layer.weight_ih_l0,
lstm_layer.weight_hh_l0, lstm_layer.bias_ih_l0,
lstm_layer.bias_hh_l0)
print(output_custom)
结果与上面调用API的结果是一致的。
tensor([[[ 0.0646, 0.2626, -0.4449, 0.1008, -0.3899],
[-0.0540, 0.4603, -0.3255, 0.1206, -0.1900],
[ 0.0450, 0.1745, -0.0695, 0.0960, -0.2173]],
[[-0.1420, -0.0881, 0.3784, 0.0850, -0.1860],
[-0.0081, 0.0408, 0.0051, 0.4927, -0.1601],
[-0.0079, 0.0765, 0.1276, 0.1734, -0.2499]]], grad_fn=)
总结
本文主要学习了LSTM中torch.nn.LSTM的参数的含义,用代码实现了前向传播的过程。