RNN学习
文章目录
- 文献阅读
-
- 摘要
- 过程
- 结论
- LSTM长短期记忆递归神经网络
-
- 数学公式
- 原理
- LSTM反向传播
- 代码
- 总结
This week,a paper which mainly proposes a hybrid climate learning model (HCLM) that uses climate model CM and deep learning model LSTM to improve rainfall forecasting has been read.In addition, I have learned the Long Short Term Memory neural network and understand the basic formula of forward propagation, the principle of LSTM and the role of each gate.
本周阅读了一篇文献,该文献主要提出了一种混合气候学习模型(HCLM),该模型利用气候模型CM和深度学习模型LSTM来改进降雨预报。此外,学习了LSTM长短期记忆递归神经网络,了解了前向传播的基本公式以及LSTM的原理,每个门的作用。
文献阅读
题目:Consensus Forecast of Rainfall Using Hybrid
Climate Learning Model
作者:Neethu Madhukumar , Student Member, IEEE, Eric Wang , Member, IEEE, Yi-Fan Zhang , Member, IEEE,and Wei Xiang , Senior Member,
摘要
降雨事件预测主要使用气候模型CM对同一降雨事件产生多个预报。深度学习方法的最新进展为从大气候数据中研究复杂的天气模式提供了非凡的能力。本文提出了一种混合气候学习模型(HCLM),该模型利用CM和深度学习模型来改进降雨预报。更具体地说,一个概率多层感知器(PMLP)网络从CM生成的预测中评估多个预测并选择最佳预测。接下来,所选预报将传递到混合深度长短期记忆(HD-LSTM)网络,该网络回顾并学习所选预报与相应降雨量和温度观测值的关系,以生成第二天的降雨量预报。来自澳大利亚不同气候区的实验结果表明,HCLM优于现有的最先进的气候和深度学习模型。
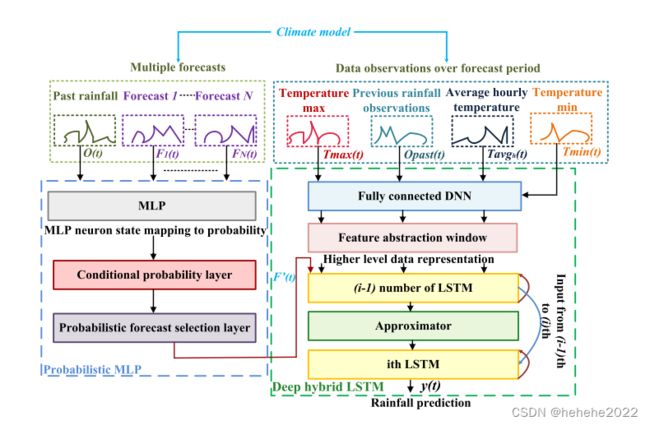
HCLM 结构图如上。来自CM的多个预测被输入到PMLP网络,该网络对预测进行条件概率评估,以找到最好的 N N N个预测中的最佳预测。PMLP的输出与预测期间的输入数据观测数据一起输入到HD-LSTM。HD-LSTM通过分析PMLP预报和在所选预测期内观测到的输入数据来预测降雨量。
PMLP用于对最佳预报进行排序和选择,HD-LSTM发现PMLP选择的预报与预测次日降雨的相应数据观测之间的相关性。PMLP 网络评估每个预测的概率,并选择概率最高的一个预测。HD-LSTM分析PMLP的输出以及预测期内观察到的天气变化,以产生第二天的降雨预报。
混合气候学习模型
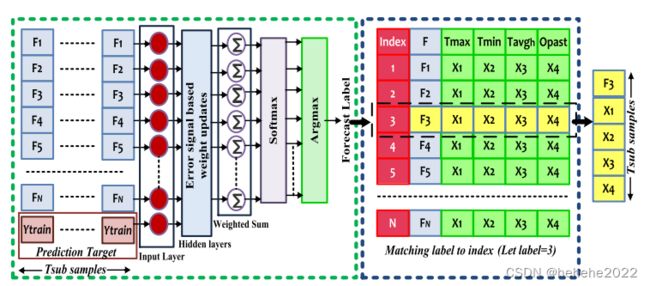
在上图所示的 PMLP 结构中,N 个输入预测被传递到 PMLP 的输入层。 CM对降雨事件产生的N个预报表示为:Fn(t) 为n∈{1,2,…,N} 在t∈{1,2,…,T} 并传递到 PMLP 的输入层进行进一步细化。Opast(t) 是过去的降雨观测结果。每个预测的模式在不同的时间段内会发生变化,因此PMLP学习Fn(t) 和Opast(t) 两者之间的关系表示多个Tsub (数据块的大小)数据块。
作者通过对比7天的预报误差发现,每个期间都有一个比其他预测更可靠的预测。因此,该期间的其余预测可以被驳回。因此,建议根据每个预报的模式对每个预报和多个降雨观测进行排名Tsub 用于选择最佳预测的数据块。在不同数据块上对任何特征的概率选择比许多基准方法表现更好。本文中使用的数据集,Tsub=21 使用随机搜索算法选择天数。
PMLP 分析所有Fn(t) 对于多个降雨模式Tsub 数据块。训练后,相似降雨模式和相似预报相互关系的PMLP从Fn(t) 作为其输出,它预测这是最佳预测。针对给定输入确定每个隐藏层节点的错误信号。节点使用这些错误来更新每个连接权重的值。对于PMLP,让Wmlv 表示权重值从v 层的神经元(m−1) 到l 层的神经元m 和W 是集合Wmlv ∀l,v,m .因此,对于给定的输入集,输出可以表示为Sn(Fn(t);W) ,是输入和权重的函数。PMLP softmax 层估计所有预测的条件概率。
HD-LSTM
PMLP的输出被提供给HD-LSTM进行进一步分析。HD-LSTM学习PMLP输出与观测数据之间的关系,以预测第二天的降雨量。对于所使用的CM,数据观测值为最高温度 T m a x ( t ) T_{\mathrm{ max}}(t) Tmax(t),最低温度 T m i n ( t ) T_{\mathrm{ min}}(t) Tmin(t),过去的降雨量 O p a s t ( t ) O_{\mathrm{ past}}(t) Opast(t)和平均每小时温度 T a v g h ( t ) T_{\rm avg_{h}}(t) Tavgh(t)。为了便于推导,我们表示 x ( t ) x(t) x(t),因为HD-LSTM和 U U U数据类型的输入数据表示为 x u ( t ) x_{u}(t) xu(t)。这里对于派生,用 [ T m a x ( t ) , T m i n ( t ) , O p a s t ( t ) , T a v g h ( t ) ] = [ x 1 ( t ) , x 2 ( t ) , x 3 ( t ) , x 4 ( t ) ] [T_{\mathrm{ max}}(t), T_{\mathrm{ min}}(t), O_{\mathrm{ past}}(t), T_{\rm avg_{h}}(t)] = [x_{1}(t), x_{2}(t), x_{3}(t), x_{4}(t)] [Tmax(t),Tmin(t),Opast(t),Tavgh(t)]=[x1(t),x2(t),x3(t),x4(t)].为了简化推导,首先推导一种类型的观察,用 x ( t ) x(t) x(t)表示。
对于PMLP选定的预测 F ′ ( t ) F'(t) F′(t),HD-LSTM在其输入处应用完全连接的DNN,以选择最佳预测期内的数据观测值。此数据将传递到 K K KLSTM 层。然后,网络分析预测与观测数据变化之间的时间相关性。LSTM的公式可以表示
![]()
HD-LSTM 输入处的一个全连接 DNN 实现了选择窗口。它选择数据观测值 x x x,该观测值与最佳预测期间 z z z 的数据观测值相同。DNN 将所选预测标签与观测数据集的索引进行匹配。这有助于网络在PMLP预报和观测值中的时间变化之间建立关系。所以 W x h x ( t ) W_{xh}x(t) Wxhx(t)变为了 W x ‾ h x ( t ) ‾ W_{\overline {x}h}\overline {x(t)} Wxhx(t)
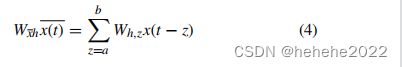
因此本文使用的HD-LSTM公式改为:
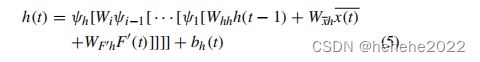
过程
数据预处理和特征提取:
PMLP 输入是多个降雨预报和过去的降雨观测。被输入到PMLP以选择最佳预测PMLP 的训练集可以表示为 Q = { F n ( t ) , t = 1 , 2 , 3.... , T } Q=\{Fn(t),t=1,2,3....,T\} Q={Fn(t),t=1,2,3....,T},输出F’(t),Xu(t),U型观测数据传递给HD-LSTM。HD-LSTM的训练集表示为 R = { ( x u ( t ) , F ′ ( t ) ) , t = 1 , … , T } R =\{(x_{u}(t),F'(t)), t= 1,\ldots, T\} R={(xu(t),F′(t)),t=1,…,T}。
结构选择和参数调整:参数调整既繁琐又昂贵,因为网络会根据不同超参数集的性能进行多次迭代。优化的关键超参数是输入序列的长度和隐藏层中的节点数。20% 的dropout用于防止过度拟合。
PMLP模型优化:
调优完成后,得到最优参数。接下来,对模型进行训练,以找到给定输入的最佳预测。PMLP 通过搜索包含所有预测的数据集通过反向传播学习,以找到可提高性能的最佳预测。这为网络提供了高质量梯度进行学习更新。
实时预测:
训练完成后,PMLP 将预测;通过分析给定的多个预测集 F n ( t ) F_{n}(t) Fn(t)的最佳预测。PMLP 使用 (2) 选择最佳预测作为其输出。
模型串联:
F ′ ( t ) F'(t) F′(t)是使用PMLP获得的最佳预测。对于在预测期内观察到的天气数据变化,观测 x u ( t ) x_{u}(t) xu(t)进行时间分析,并获得最佳预报。为此,PMLP 输出连接到 HD-LSTM。
HD-LSTM模型优化:
步骤 2 和 3 应用于 HD-LSTM 以进行模型优化。对于一般的降雨事件,人们认为最近的天气数据对于预测更为重要。但是,较旧的数据可以帮助模型识别总体趋势和运动。因此,序列长度的选择是为降雨数据完成的。
降雨事件预测:
对于给定的数据观测和 F ′ ( t ) F'(t) F′(t),PMLP选择的最佳预报,HD-LSTM预测第二天的降雨量。
结论
在本文中,提出了一种 HCLM。HCLM 根据 CM 为降雨事件生成的多个预报构建其未来降雨预测。HCLM 使用 PMLP 网络和 HD-LSTM 网络进行设计。PMLP从多个CM预报中选择最佳预报,HD-LSTM查找所选预报与预报时间内的温度和降雨观测结果的关系。该评估在澳大利亚六个主要气候区的十个不同地点进行。结果表明,HCLM预测的降雨量比CM和深度学习模型更类似于实际降雨量,在所有分析的位置的平均年结果。模型预测降雨的潜力已在消融研究、RMSE 和皮尔逊相关性方面建立。因此,可以得出结论,HCLM在预测流行气候和深度学习模型的降雨量方面有显着改进。
LSTM长短期记忆递归神经网络
LSTM从被设计之初就被用于解决一般递归神经网络中普遍存在的长期依赖问题,使用LSTM可以有效的传递和表达长时间序列中的信息并且不会导致长时间前的有用信息被忽略(遗忘)。与此同时,LSTM还可以解决RNN中的梯度消失/爆炸问题。
LSTM的思路:RNN是想把所有的信息都记住,不管是有用的信息还是没用的信息;而LSTM 则设计一个记忆细胞,具备选择记忆的功能,可以选择记忆重要信息,过滤掉噪声信息,减轻记忆负担。
前向传播:
LSTM图
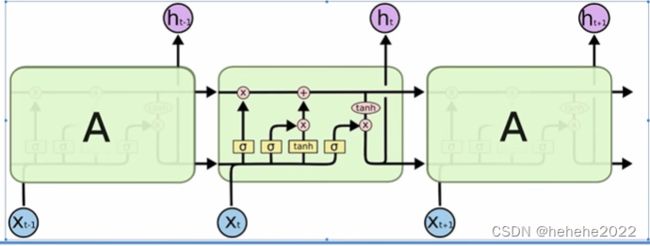
RNN图
LSTM的单元结构:
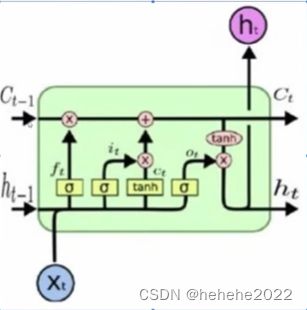
记忆细胞C,状态H,可以看到t-1时刻的记忆细胞和t-1时刻的状态经过单元输出新的记忆细胞和新的状态。单元内有3个sigmoid函数(输出值在0-1),也叫门单元,ft是遗忘门,it是更新门,ot是输出门。
数学公式
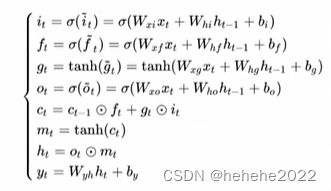
原理
记忆细胞:在LSTM的每个时间步里面,都有一个记忆细胞,这个东西给了LSTM选择记忆功能,使得LSTM有能力自由选择每个时间步里面记忆的内容。
遗忘门ft所做的是遗忘掉过去留下的记忆Ct-1,ft经过一个sigmoid值是介于0-1之间的,比如可以表示为[0001001…],ft和Ct-1相乘就会把对应0的部分的记忆遗忘掉,1的保留。
更新门:与更新门作用的是gt,gt相当于生成的新的记忆,但这个新的记忆并不是都全部有用,所以需要一个门有选择的去提取,更新门也就是选择对最终结果有帮助的进行记忆,否则遗忘掉。
新的记忆Ct也就是将过去的记忆经过筛选和现在经过筛选的记忆相加得到新的记忆Ct。
输出门选择Ct中的一部分使用,得到ht。
LSTM反向传播
将LSTM的公式展开如下图:
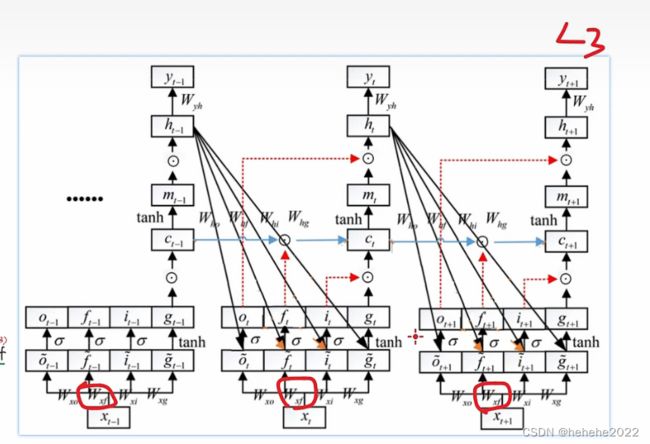
反向传播过程:
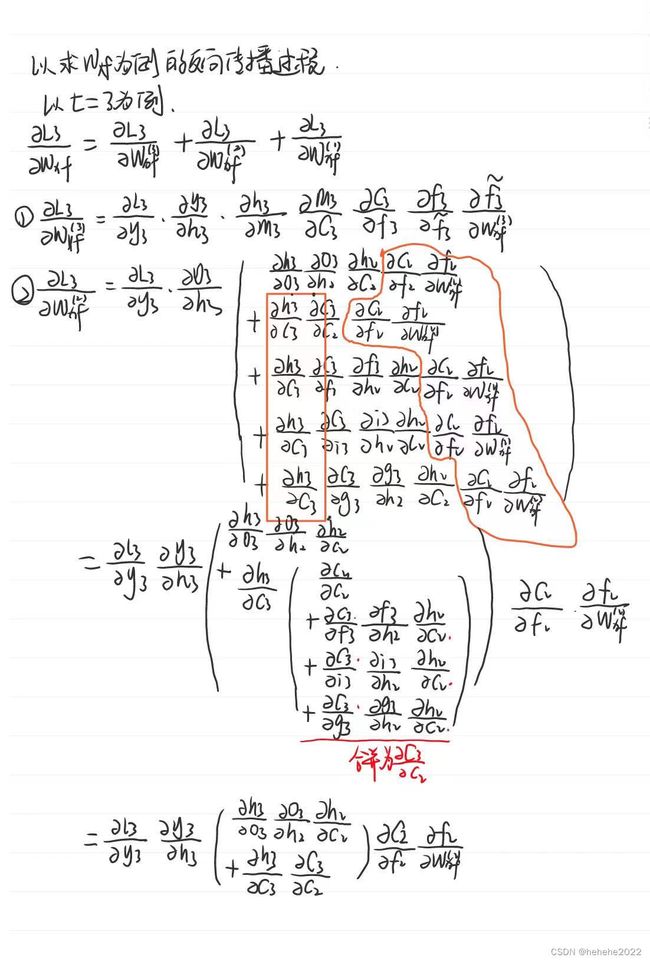
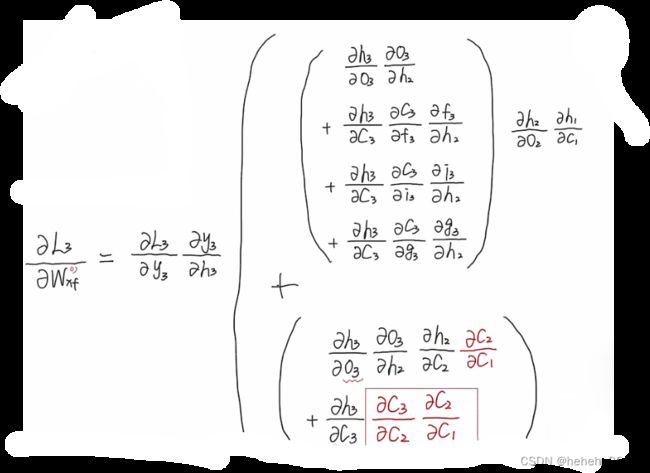

这个式子由四项相加得到,模型可以通过学习调控三个W的大小从而控制这个导数的大小,使得这项的结果接近于1。从反向推到可以看出当时间跨度越长路径很多,公式中连乘的项就越长,很容易梯度消失,但是连乘项可以通过调整参数实现1X1X1…的效果,连乘效果削弱,降低梯度消失的可能性。
代码
用RNN预测sin函数
1.导包
import torch.utils.data
from torch import optim, nn
import numpy as np
import matplotlib.pyplot as plt
2.参数设置
num_time_steps = 50
#训练时循环次数
input_size = 1
#输入维度
hidden_size = 16
#隐藏层节点个数
output_size = 1
#输出维度
相当于每个节点1维扩展成了16维然后再映射到1维
3.通过pytorch建立RNN模型
#网络结构定义
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.rnn = nn.RNN(
input_size=input_size,
#输入数据的维度,比如使用one-hot编码单词,300个值表示一个字母维度就是300
hidden_size=hidden_size,
#隐藏层节点的个数
num_layers=1,#叠加的层数,此处只叠加一层
#即RNN经过几层堆叠得到结果
batch_first=True
#RNN默认输入是(seq_len, batch_size, input_size),此时batch_size在第一维度,所以需要设置成True
)
self.liner = nn.Linear(hidden_size, output_size)
def forward(self, x, hidden_prev):
out, hidden_prev = self.rnn(x, hidden_prev)
out = out.view(-1, hidden_size)
out = self.liner(out)
out = out.unsqueeze(dim=0)
return out, hidden_prev
4.训练RNN模型
#训练网络
model = Net()#初始化RNN
criterion = nn.MSELoss()#定义损失函数
optimizer = optim.Adam(model.parameters(), 1e-2)#优化器
hidden_prev = torch.zeros(1, 1, hidden_size) #初始化h0,即开始向后一层传递的记忆单元
for iter in range(6000):
start = np.random.randint(3, size=1)[0]#在0~3之间随机取开始的时刻点
# print(start)
time_steps = np.linspace(start, start + 10, num_time_steps)
#在开始点和开始点+10之间均匀的取50个点,用于绘制图像,做数据集
data = np.sin(time_steps)
#计算数据预期值
data = data.reshape(num_time_steps, 1)
x = torch.tensor(data[:-1]).float().view(1, num_time_steps - 1, 1)
#将数据转为Tensor类型:(batch_size,seq_len, input_size)
y = torch.tensor(data[1:]).float().view(1, num_time_steps - 1, 1)
output, hidden_prev = model(x, hidden_prev)
#output输出的是预测的49个值的结果,hp是隐藏层每个维度的输出值
# print('output',output.size())
# print('prev',hidden_prev.size())
hidden_prev = hidden_prev.detach()
#将原来变量赋值一份并转为Tensor格式
loss = criterion(output, y)
#计算误差值
model.zero_grad()
#梯度清零
loss.backward()
optimizer.step()
#反向传播优化
#每训练100次输出一次误差
if iter % 100 == 0:
print("Iter: {} loss: {} ".format(iter, loss))
总结
本周主要了解了LSTM,学习LSTM前向传播的公式以及反向传播的过程,了解了LSTM可以解决RNN中的梯度消失的问题。