强化学习:马尔科夫决策过程(MDP)
马尔科夫决策过程
- 马尔科夫决策过程
- 马尔科夫过程
- 马尔科夫奖励过程
- 回报(return)
- 状态价值函数(value function)
- 贝尔曼方程
- 马尔科夫决策过程
- 定义
- 策略
- 贝尔曼方程
- 最优价值函数
- 最优策略
- 贝尔曼最优方程
马尔科夫过程
马尔科夫性: 系统的下一个状态 St+1 S t + 1 仅与当前状态有关系,而与如何之前的状态没有关系。也就是说,下一个状态并不取决于之前的状态。(不具备记忆性?)
定义: 一个状态 St S t 具备马尔科夫性,当且仅当: P(St+1|St)=P(St+1|St,St−1,⋯,S1) P ( S t + 1 | S t ) = P ( S t + 1 | S t , S t − 1 , ⋯ , S 1 )
从这个定义中可以得知,之前的状态如何并不会影响下一步的状态。
对于一个马尔科夫状态 s s 和后续状态s′ s ′ ,其间的状态转移概率可以定义为:
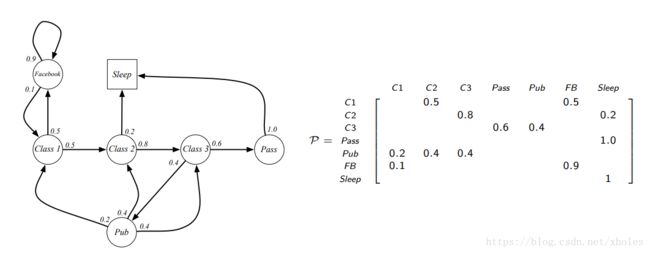
假设一共有 n n 个状态,且都具备马尔科夫性,那么它们之间的转换概率可以使用矩阵表示:
矩阵行表示当前状态,列表示下一个状态,对应的值为两个状态转移的概率。因此,可以得知每列的和为1。
一个马尔科夫过程是无记忆的随机过程,例如一个随机的状态序列,其中每个状态都具备马尔科夫性。马尔科夫过程(马尔科夫链)可以定义为一个元组(tuple) <S,P> < S , P > ,其中 S S 是一个组数目有限的状态,P P 是状态转移概率矩阵。
$$
马尔科夫奖励过程
马尔科夫奖励(reward)过程是一个带值得马尔科夫链。通常可以被定义为一个元组 <S,P,R,γ> < S , P , R , γ > ,其中 S S 是一个有限的状态集;P P 是状态转移概率矩阵; R R 是回报函数,Rs=E[Rt+1|St=s] R s = E [ R t + 1 | S t = s ] ; γ γ 是衰减因子, γ∈[0,1] γ ∈ [ 0 , 1 ] 。
回报(return)
回报函数 Gt G t 是从时间步 t t 之后的总的衰减奖励。
衰减因子的值会影响后续状态转移的回报值。 γ γ 小则更注重短期(myopic)回报$$;相应地
,$\gamma$若是较大,则表示更加注重长期(far-sight)回报。
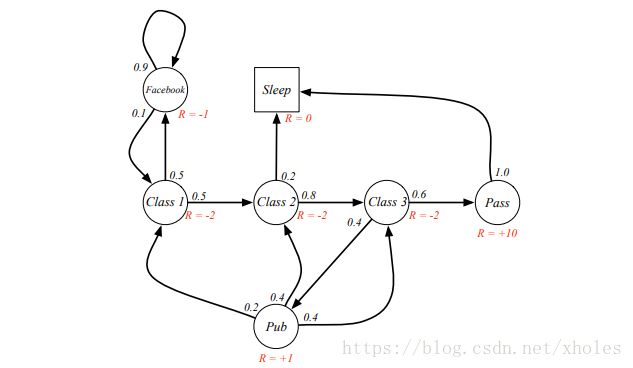
为什么需要衰减因子?
1)避免在马尔科夫回环中产生无限大的值
2)未来并不不确定,因此不需要全部回报
3)符合人类的实践行为—注重眼前效益
…
状态价值函数(value function)
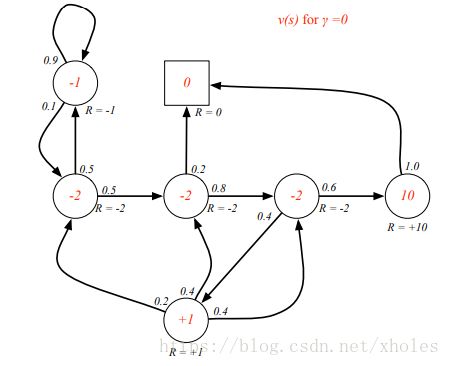
价值函数描绘的是状态的长期价值。一个状态的回报值与其形成的马尔科夫链有关系,不同的链具有不同的回报值。因此,一个马尔科夫随机过程中状态 s s 的状态价值函数可以定义为其回报的期望:
贝尔曼方程
从给出的例子中可以看出,马尔科夫链是可以存在回环的,这就回给求回报时带来一定的困难。尤其当 γ≠0 γ ≠ 0 时。通过观察所定义的状态价值函数,它可以分解为直接回报和后继状态的衰减值:
将上述式子改写成矩阵形式:
这是一个线性方程组,结合线性代数的知识可以直接求解(如果满足要求的话):
对于小的MRP问题,可以直接使用上述式子求解。但对于大型的问题,则需要使用迭代的方法来进行求解。如:
-动态规划法
-蒙特卡罗法
-时间差分学习法
马尔科夫决策过程
定义
一个马尔科夫决策过程(MDP)是一个带决策的马尔科夫奖励过程,是一个其中任意状态具备马尔科夫性的环境。
马尔科夫决策过程可以使用一个元组 <S,A,P,R,γ> < S , A , P , R , γ > 表示,其中:
S S 表示一个有限的状态组,
A A 是一个有限的行为组,
P P 是状态转移概率矩阵,R R 是回报函数;
Pass′=P[St+1=s′|St=s,At=a] P s s ′ a = P [ S t + 1 = s ′ | S t = s , A t = a ]γ γ 是衰减因子, γ∈[0,1] γ ∈ [ 0 , 1 ] 。
一个马尔科夫简单的例子如下:

策略
一个策略 π π 是给定状态下关于行为的概率分布:
-一个策略完全定义了agent的行为。
-MDP策略取决于当前的状态,非历史状态。
-策略是固定的,不是随时间变化的。
对于给定的一个MDP M=<S,A,P,R,γ> M =< S , A , P , R , γ > 和对应的策略 π π ,其状态序列 S1,S2,⋯ S 1 , S 2 , ⋯ 是一个马尔科夫过程 <S,Pπ> < S , P π > ;状态及回报序列 S1,R2,S2,⋯ S 1 , R 2 , S 2 , ⋯ 是一个马尔科夫奖励过程 <S,Pπ,Rπ,γ> < S , P π , R π , γ > 。
相应地,状态价值函数可以定义为:
另外,可以新定义行为价值函数:
贝尔曼方程

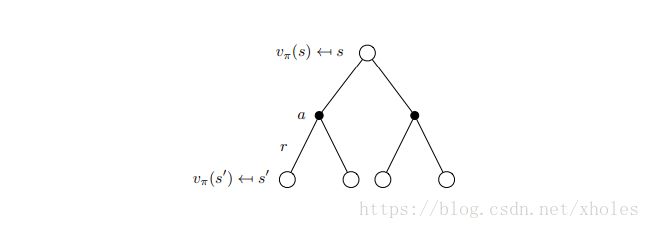
改写为矩阵形式则有:
最优价值函数
最优状态价值函数
最优行为价值函数
最优价值函数指出了在马尔科夫决策过程中可能的最好决策结果,当我们知道最优结果时则称这个马尔科夫决策过程(MDP)是已解(solved)的。
最优策略
定义一种偏序:
如果对于任意的 s s 有 vπ(s)≥vπ′(s) v π ( s ) ≥ v π ′ ( s ) ,那么 π≥π′ π ≥ π ′ .
定理:
对于任意的MDP:
存在一个最优的策略 π∗ π ∗ 使得对于任意的 π π 有 π∗≥π π ∗ ≥ π ;
所有的最优策略对应最优状态价值函数,即: vπ∗(s)=v∗(s) v π ∗ ( s ) = v ∗ ( s )
所有的最优策略对应最优行为价值函数,即: qπ∗(s,a)=q∗(s,a) q π ∗ ( s , a ) = q ∗ ( s , a )
最优策略的寻找可以通过最大化 q∗(s,a) q ∗ ( s , a ) :
对于任意的MDP过程,总是存在一个确定的最优策略;一旦知道 q∗(s,a) q ∗ ( s , a ) 则可以直接得到最优策略。
贝尔曼最优方程
贝尔曼最优方程是非线性的,通常没有闭式解。但可以通过迭代法来求得数值解:
1、值迭代(value iteration)
2、策略迭代(policy iteration)
3、Q学习
4、Sarsa
References
[1]UCL Course on RL
[2]强化学习入门 第一讲 MDP