数据导入与预处理-第6章-04pandas综合案例
数据导入与预处理-第6章-04pandas综合案例
- 1 pandas综合案例-运动员信息数据
-
- 1.1 查看数据
- 1.2 数据处理与分析
1 pandas综合案例-运动员信息数据
1.1 查看数据
导入数据:
import numpy as np
import pandas as pd
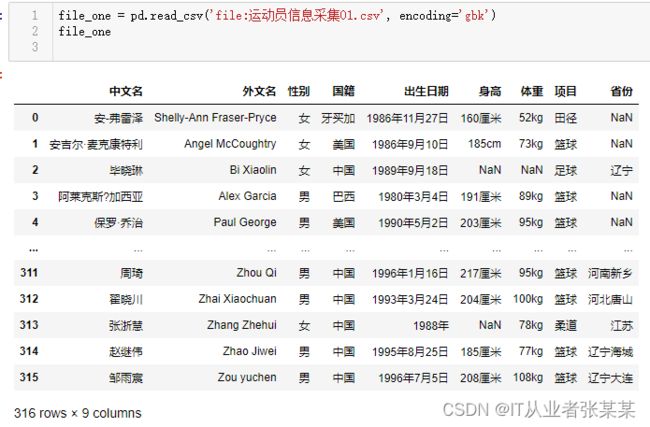
查看数据-运动员信息采集01.csv
数据下载地址:
https://download.csdn.net/download/m0_38139250/86789510
下载后解压到工程目录下即可
file_one = pd.read_csv('file:运动员信息采集01.csv', encoding='gbk')
file_one
输出为:
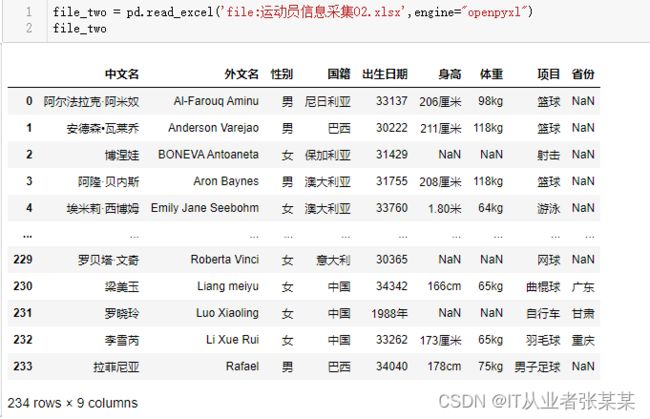
查看数据-运动员信息采集02.excel
file_two = pd.read_excel('file:运动员信息采集02.xlsx',engine="openpyxl")
file_two
输出为:
合并数据
# 采用外连接的方式合并数据
all_data = pd.merge(left=file_one,right=file_two, how='outer')
all_data
输出为:

1.2 数据处理与分析
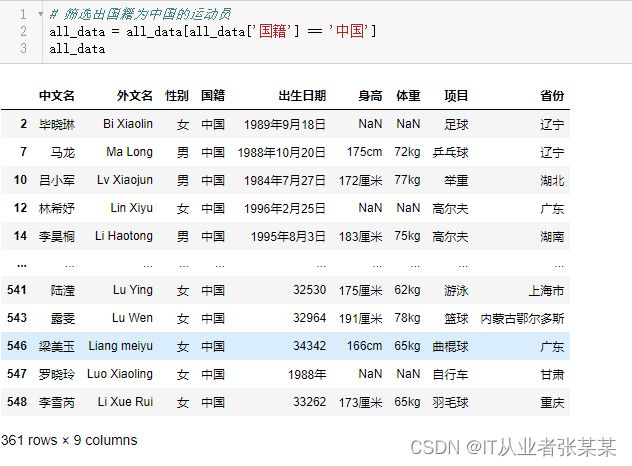
筛选出国籍为中国的运动员
# 筛选出国籍为中国的运动员
all_data = all_data[all_data['国籍'] == '中国']
all_data
输出为:
查看DataFrame类对象的摘要
# 查看DataFrame类对象的摘要,包括各列数据类型、非空值数量、内存使用情况等
all_data.info()
输出为:

检测all_data中是否有重复值
# 检测all_data中是否有重复值
all_data[all_data.duplicated().values==True]
输出为:

删除all_data中的重复值
# 删除all_data中的重复值,并重新对数据进行索引
all_data = all_data.drop_duplicates(ignore_index=True)
all_data.head(10)
输出为:
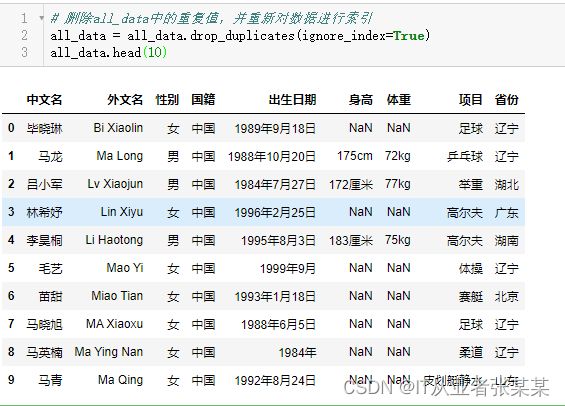
筛选出项目为篮球的运动员并访问“出生日期”一列的数据
# 筛选出项目为篮球的运动员
basketball_data= all_data[all_data['项目'] == '篮球']
# 访问“出生日期”一列的数据
basketball_data['出生日期']
输出为:
修改出生日期列
import datetime
basketball_data = basketball_data.copy()
# 将以“x”天显示的日期转换成以“x年x月x日”形式显示的日期
initial_time = datetime.datetime.strptime('1900-01-01', "%Y-%m-%d")
for i in basketball_data.loc[:, '出生日期']:
if type(i) == int:
new_time = (initial_time + datetime.timedelta(days=i)).strftime('%Y{y}%m{m}%d{d}').format(y='年', m='月', d='日')
basketball_data.loc[:, '出生日期'] = basketball_data.loc[:, '出生日期'].replace(i, new_time)
# 为保证出生日期的一致性,这里统一使用只保留到年份的日期
basketball_data.loc[:, '出生日期'] = basketball_data['出生日期'].apply(lambda x:x[:5])
basketball_data['出生日期'].head(10)
输出为:

筛选男篮运动员
# 筛选男篮球运动员
male_data = basketball_data[basketball_data['性别'].apply(lambda x :x =='男')]
male_data = male_data.copy()
# 计算身高平均值(四舍五入取整)
male_height = male_data['身高'].dropna()
fill_male_height = round(male_height.apply(lambda x : x[0:-2]).astype(int).mean())
fill_male_height = str(int(fill_male_height)) + '厘米'
# 填充缺失值
male_data.loc[:, '身高'] = male_data.loc[:, '身高'].fillna(fill_male_height)
# 为方便后期使用,这里将身高数据转换为整数
male_data.loc[:, '身高'] = male_data.loc[:, '身高'].apply(lambda x: x[0:-2]).astype(int)
# 重命名列标签索引
male_data.rename(columns={'身高':'身高/cm'}, inplace=True)
male_data
输出为:

筛选女篮球运动员数据
# 筛选女篮球运动员数据
female_data = basketball_data[basketball_data['性别'].apply(
lambda x :x =='女')]
female_data = female_data.copy()
data = {'191cm':'191厘米','1米89公分':'189厘米','2.01米':'201厘米',
'187公分':'187厘米','1.97M':'197厘米','1.98米':'198厘米',
'192cm':'192厘米'}
female_data.loc[:, '身高'] = female_data.loc[:, '身高'].replace(data)
# 计算女篮球运动员平均身高
female_height = female_data['身高'].dropna()
fill_female_height = round(female_height.apply(lambda x : x[0:-2]).astype(int).mean())
fill_female_height =str(int(fill_female_height)) + '厘米'
# 填充缺失值
female_data.loc[:, '身高'] = female_data.loc[:, '身高'].fillna(fill_female_height)
# 为方便后期使用,这里将身高数据转换为整数
female_data['身高'] = female_data['身高'].apply(lambda x : x[0:-2]).astype(int)
# 重命名列标签索引
female_data.rename(columns={'身高':'身高/cm'}, inplace=True)
female_data
输出为:

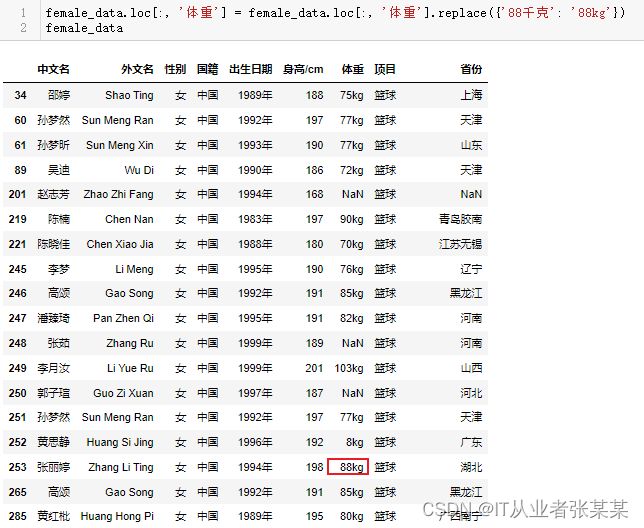
替换数据
# 替换数据
female_data.loc[:, '体重'] = female_data.loc[:, '体重'].replace({'88千克': '88kg'})
female_data
输出为:
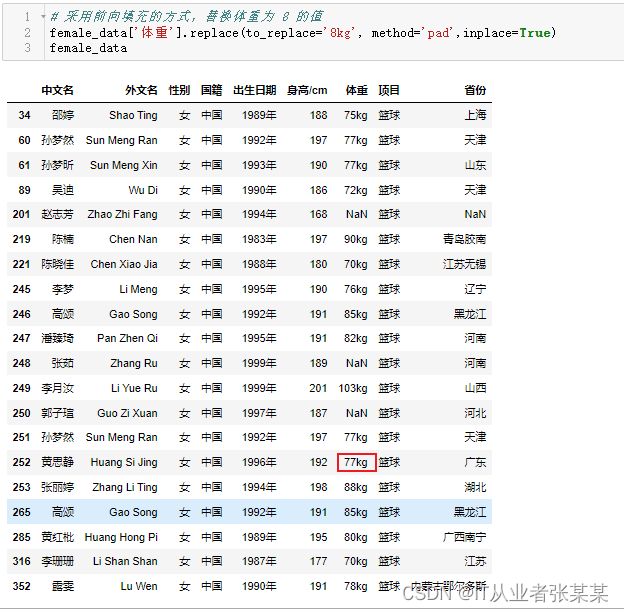
采用前向填充的方式,替换体重为 8 的值
# 采用前向填充的方式,替换体重为 8 的值
female_data['体重'].replace(to_replace='8kg', method='pad',inplace=True)
female_data
输出为:
计算女篮球运动员的平均体重
# 计算女篮球运动员的平均体重
female_weight = female_data['体重'].dropna()
female_weight = female_weight.apply(lambda x :x[0:-2]).astype(int)
fill_female_weight = round(female_weight.mean())
fill_female_weight = str(int(fill_female_weight)) + 'kg'
# 填充缺失值
female_data.loc[:,'体重'].fillna(fill_female_weight, inplace=True)
female_data
输出为:

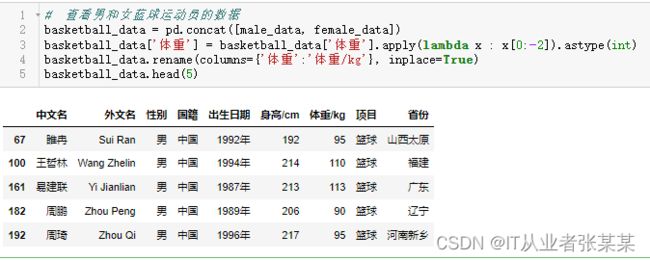
查看男和女蓝球运动员的数据
# 查看男和女蓝球运动员的数据
basketball_data = pd.concat([male_data, female_data])
basketball_data['体重'] = basketball_data['体重'].apply(lambda x : x[0:-2]).astype(int)
basketball_data.rename(columns={'体重':'体重/kg'}, inplace=True)
basketball_data.head(5)
输出为:
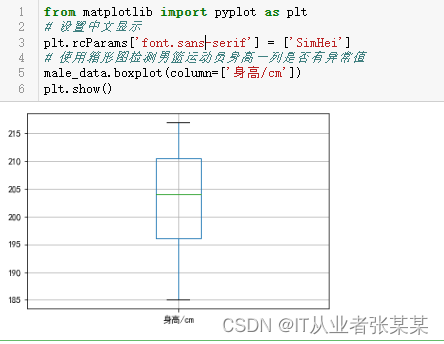
设置中文显示 使用箱形图检测男篮运动员身高一列是否有异常值
from matplotlib import pyplot as plt
# 设置中文显示
plt.rcParams['font.sans-serif'] = ['SimHei']
# 使用箱形图检测男篮运动员身高一列是否有异常值
male_data.boxplot(column=['身高/cm'])
plt.show()
输出为:
使用箱形图检测女篮运动员身高一列是否有异常值
# 使用箱形图检测女篮运动员身高一列是否有异常值
female_data.boxplot(column=['身高/cm'])
plt.show()
输出为:

定义3σ原则检测函数
# 定义基于3σ原则检测的函数
def three_sigma(ser):
# 计算平均数
mean_data = ser.mean()
# 计算标准差
std_data = ser.std()
# 根据数值小于μ-3σ或大于μ+3σ均为异常值
rule = (mean_data-3*std_data>ser) | (mean_data+3*std_data<ser)
# 返回异常值的位置索引
index = np.arange(ser.shape[0])[rule]
# 获取异常值数据
outliers = ser.iloc[index]
return outliers
# 使用3σ原则检测女篮运动员的体重数据
female_weight = basketball_data[basketball_data['性别'] == '女']
three_sigma(female_weight['体重/kg'])
输出为:

使用3σ原则检测男篮运动员的体重数据
# 使用3σ原则检测男篮运动员的体重数据
male_weight = basketball_data[basketball_data['性别'] == '男']
three_sigma(male_weight['体重/kg'])
输出为:

以性别分组,对各分组执行求平均数操作,并要求平均数保留一位小数
# 以性别分组,对各分组执行求平均数操作,并要求平均数保留一位小数
basketball_data.groupby('性别').mean().round(1)
输出为:

根据计算的年龄值绘制直方图
import matplotlib.pyplot as plt
# 设置图表中文字的字体为黑体
plt.rcParams['font.sans-serif'] = ['SimHei']
# 根据出生日期计算年龄
ages = 2020 - basketball_data['出生日期'].apply(lambda x : x[0:-1]).astype(int)
# 根据计算的年龄值绘制直方图
ax = ages.plot(kind='hist')
# 设置直方图中x轴、y轴的标签为“年龄(岁)”和“频数”
ax.set_xlabel('年龄(岁)')
ax.set_ylabel('频数')
# 设置x轴的刻度为“ages的最小值, ages的最小值+2, ..., ages最大值+1”
ax.set_xticks(range(ages.min(),ages.max()+1, 2))
plt.show()
输出为:

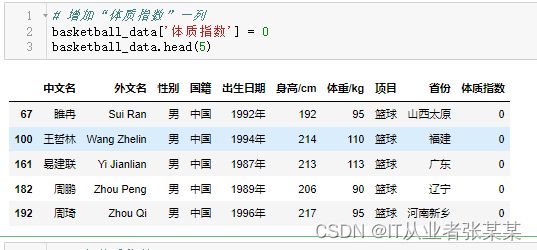
增加“体质指数”一列
# 增加“体质指数”一列
basketball_data['体质指数'] = 0
basketball_data.head(5)
输出为:
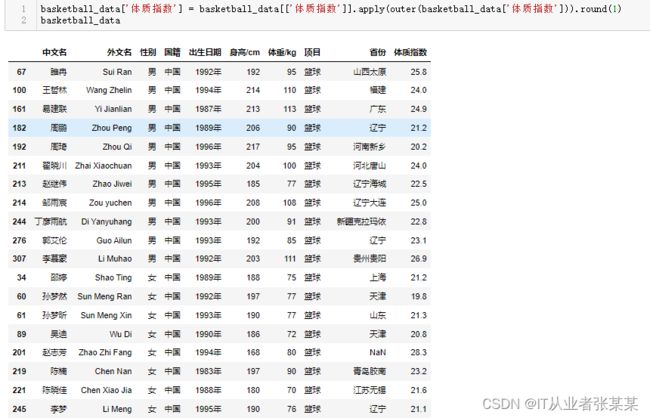
计算体质指数
# 计算体质指数
def outer(num):
def ath_bmi(sum_bmi):
weight = basketball_data['体重/kg']
height = basketball_data['身高/cm']
sum_bmi = weight / (height/100)**2
return num + sum_bmi
return ath_bmi
basketball_data['体质指数'] = basketball_data[['体质指数']].apply(outer(basketball_data['体质指数'])).round(1)
basketball_data
输出为:
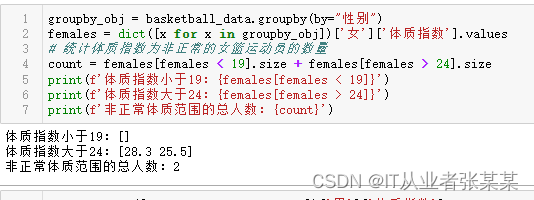
统计体质指数为非正常的女篮运动员的数量
groupby_obj = basketball_data.groupby(by="性别")
females = dict([x for x in groupby_obj])['女']['体质指数'].values
# 统计体质指数为非正常的女篮运动员的数量
count = females[females < 19].size + females[females > 24].size
print(f'体质指数小于19:{females[females < 19]}')
print(f'体质指数大于24:{females[females > 24]}')
print(f'非正常体质范围的总人数:{count}')
输出为:
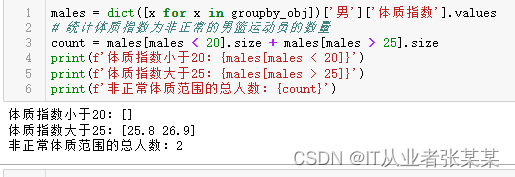
统计体质指数为非正常的男篮运动员的数量
males = dict([x for x in groupby_obj])['男']['体质指数'].values
# 统计体质指数为非正常的男篮运动员的数量
count = males[males < 20].size + males[males > 25].size
print(f'体质指数小于20:{males[males < 20]}')
print(f'体质指数大于25:{males[males > 25]}')
print(f'非正常体质范围的总人数:{count}')
输出为: