学习笔记:动手学深度学习 17 权重衰退
Python 3.8.8 (default, Apr 13 2021, 15:08:03) [MSC v.1916 64 bit (AMD64)] on win32
In[2]: import matplotlib.pyplot as plt
Backend Qt5Agg is interactive backend. Turning interactive mode on.
In[3]: import torch
...: from torch import nn
...: from d2l import torch as d2l
n_train, n_test, num_inputs, batch_size = 20, 100, 200, 5
true_w, true_b = torch.ones((num_inputs, 1)) * 0.01, 0.05
train_data = d2l.synthetic_data(true_w, true_b, n_train)
train_iter = d2l.load_array(train_data, batch_size)
test_data = d2l.synthetic_data(true_w, true_b, n_test)
test_iter = d2l.load_array(test_data, batch_size, is_train=False)
"""训练数据越少,越简单,越容易过拟合"""
Out[5]: '训练数据越少,越简单,越容易过拟合'
"""初始化模型参数"""
Out[6]: '初始化模型参数'
def init_params():
w = torch.normal(0, 1, size=(num_inputs, 1), requires_grad=True)
b = torch.zeros(1, requires_grad=True)
return [w, b]
"""定义 L2 范数惩罚"""
Out[8]: '定义 L2 范数惩罚'
def l2_penalty(w):
return torch.sum(w.pow(2)) / 2
"""对所有项求平方后并将它们求和"""
Out[10]: '对所有项求平方后并将它们求和'
"""定义训练代码实现"""
Out[11]: '定义训练代码实现'
def train(lambd):
w, b = init_params()
net, loss = lambda X: d2l.linreg(X, w, b), d2l.squared_loss
num_epochs, lr = 100, 0.003
animator = d2l.Animator(xlabel='epochs', ylabel='loss', yscale='log',
xlim=[5, num_epochs], legend=['train', 'test'])
for epoch in range(num_epochs):#每一次数据迭代
for X, y in train_iter: #每一次从迭代器中拿出一个x和y
#with torch.enable_grad():
# 增加了L2范数惩罚项,广播机制使l2_penalty(w)成为一个长度为`batch_size`的向量。
l = loss(net(X), y) + lambd * l2_penalty(w)
l.sum().backward()
d2l.sgd([w, b], lr, batch_size)
if (epoch + 1) % 5 == 0:
animator.add(epoch + 1, (d2l.evaluate_loss(net, train_iter, loss),
d2l.evaluate_loss(net, test_iter, loss)))
print('w的L2范数是:', torch.norm(w).item())
Traceback (most recent call last):
File "C:\ProgramData\Anaconda3\lib\site-packages\IPython\core\interactiveshell.py", line 2909, in _run_cell
transformed_cell = self.transform_cell(raw_cell)
File "C:\ProgramData\Anaconda3\lib\site-packages\IPython\core\interactiveshell.py", line 3198, in transform_cell
cell = self.input_transformer_manager.transform_cell(raw_cell)
File "C:\ProgramData\Anaconda3\lib\site-packages\IPython\core\inputtransformer2.py", line 593, in transform_cell
lines = self.do_token_transforms(lines)
File "C:\ProgramData\Anaconda3\lib\site-packages\IPython\core\inputtransformer2.py", line 578, in do_token_transforms
changed, lines = self.do_one_token_transform(lines)
File "C:\ProgramData\Anaconda3\lib\site-packages\IPython\core\inputtransformer2.py", line 558, in do_one_token_transform
tokens_by_line = make_tokens_by_line(lines)
File "C:\ProgramData\Anaconda3\lib\site-packages\IPython\core\inputtransformer2.py", line 487, in make_tokens_by_line
for token in tokenize.generate_tokens(iter(lines).__next__):
File "C:\ProgramData\Anaconda3\lib\tokenize.py", line 512, in _tokenize
raise IndentationError(
File "", line 12
l.sum().backward()
^
IndentationError: unindent does not match any outer indentation level
def train(lambd):
w, b = init_params()
net, loss = lambda X: d2l.linreg(X, w, b), d2l.squared_loss
num_epochs, lr = 100, 0.003
animator = d2l.Animator(xlabel='epochs', ylabel='loss', yscale='log',
xlim=[5, num_epochs], legend=['train', 'test'])
for epoch in range(num_epochs):#每一次数据迭代
for X, y in train_iter: #每一次从迭代器中拿出一个x和y
with torch.enable_grad():
# 增加了L2范数惩罚项,广播机制使l2_penalty(w)成为一个长度为`batch_size`的向量。
l = loss(net(X), y) + lambd * l2_penalty(w)
l.sum().backward()
d2l.sgd([w, b], lr, batch_size)
if (epoch + 1) % 5 == 0:
animator.add(epoch + 1, (d2l.evaluate_loss(net, train_iter, loss),
d2l.evaluate_loss(net, test_iter, loss)))
print('w的L2范数是:', torch.norm(w).item())
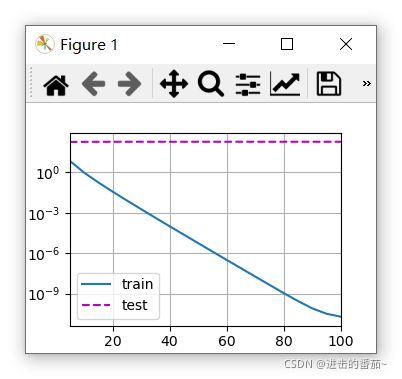
train(lambd=0)
w的L2范数是: 13.083698272705078
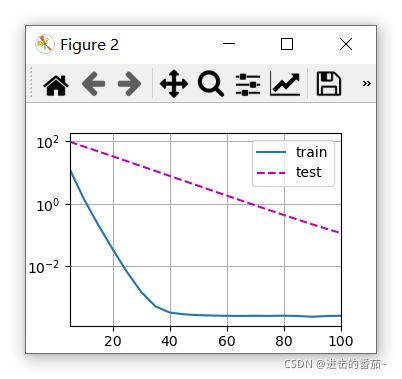
train(lambd=3)
w的L2范数是: 0.3547653555870056 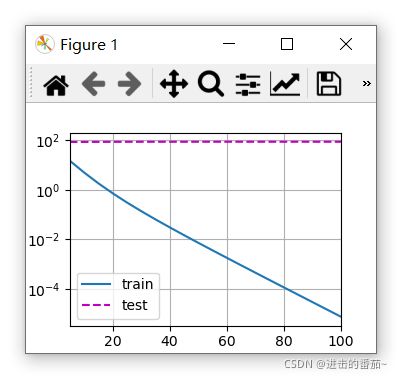

简洁实现
def train_concise(wd):
net = nn.Sequential(nn.Linear(num_inputs, 1))
for param in net.parameters():
param.data.normal_()
loss = nn.MSELoss()
num_epochs, lr = 100, 0.003
# 偏置参数没有衰减。
trainer = torch.optim.SGD([
{"params":net[0].weight,'weight_decay': wd},
{"params":net[0].bias}], lr=lr)
animator = d2l.Animator(xlabel='epochs', ylabel='loss', yscale='log',
xlim=[5, num_epochs], legend=['train', 'test'])
for epoch in range(num_epochs):
for X, y in train_iter:
with torch.enable_grad():
trainer.zero_grad()
l = loss(net(X), y)
l.backward()
trainer.step()
if (epoch + 1) % 5 == 0:
animator.add(epoch + 1, (d2l.evaluate_loss(net, train_iter, loss),
d2l.evaluate_loss(net, test_iter, loss)))
print('w的L2范数:', net[0].weight.norm().item())
train_concise(0)
w的L2范数: 14.020862579345703
train_concise(3)
w的L2范数: 0.3540894091129303