Pytorch初学者系列-基础知识
关注博主微信公众号:3分钟秒懂大数据,粉丝2w+;
Hello 各位小伙伴,本章节,我将带领大家学习一下PyTorch的基础知识。对于没有机器学习、深度学习经验的小伙伴们,可以以此为跳板,掌握一点基础概念和知识点,为以后学习打基础,当然,对于有使用经验的,就当温故而知新了。

PyTorch是一个开源的Python机器学习库,基于Torch,用于自然语言处理等应用程序。
2017年1月,由Facebook人工智能研究院(FAIR)基于Torch推出了PyTorch。它是一个基于Python的可续计算包,提供两个高级功能:
1、具有强大的GPU加速的张量计算(如NumPy)。
2、包含自动求导系统的深度神经网络。
PyTorch的特色之一是提供构建动态计算图的框架,这样网络结构就不再是一成不变的了,甚至可以在运行时修正它们。
在神经网络方面,PyTorch的优点还在于使用了多GPU的强大加速能力、定义数据加载器和极简的预处理过程等。
1.1 Tensor简介
Tensor是PyTorch中的基本对象,意思为张量,表示多维的矩阵,是PyTorch中的基本操作对象之一。本文所有案例代码均使用jupyter notebook 进行编写。与Numpy的ndarray类似,Tensor的声明和获取size可以这样:

Tensor的算术运算和选取操作与Numpy -样,因此Numpy相似的运算操作都可以迁移过来:

Tensor与Numpy的array还可以进行互相转换,有专门的转换函数:

1.2 Variable简介
Variable是PyTorch的另一个基本对象(变量),可以把它理解为是对Tensor的一个封装。Variable用于放入计算图中以进行前向传播、反向传播和自动求导,如下图:

在Variable中有三个重要属性:data、grad、creator。其中:
data 表示包含的Tensor数据部分;
grad表示传播方向的梯度,这个属性是延迟分配的.而且仅允许进行一次;
creator表示创建这个Variable的Function的引用,该引用用于回溯整个创建链路。
如果是用户创建的Variable. 其中creator为None,同时这种 Variable 称作 Leaf Variable, autograd 只会给 Leaf Variable 分配梯度。

对于 y.backward(grad_variables), grad_variables 就是 y 求导时的梯度参数,由于autograd仅用于标量,因此当y不是标量且在声明时使用了requires_grad=True 时,必须指定grad_variables参数,在完成原始的反向传播后得到的梯度会用这个grad_variables进行修正,然后将结果保存至Variable的grad中。grad_variables的长度与y要一致。在深度学习中求导与梯度有关,因此grad variables —般会定义类似为[1,0.1,0.01,0.001],表示梯度的方向,取最小的值不会对求导效率有影响。
1.3 CUDA简介
如果安装了支持CUDA版本的PyTorch,就可以启用显卡运算了。torch.cuda 用于设置和运行CUDA操作,它会记录当前选择的GPU,并且分配的所有CUDA张量将默认在上面创建,可以使用torch.cuda.device上下文管理器更改所选设备。
不过,一旦张量被分配,可以直接对其进行操作,而不考虑所选择的设备,结果将始终放在与张量相关的设备上。默认情况下,不支持跨GPU操作,唯一的例外是copy_()。除非启用对等存储器访问,否则对于分布不同设备上的张量, 任何启动操作的尝试都将引发错误。

1.4 模型的保存与加载
Python中对于模型数据的保存和加载操作都是引用Python内置的pickle包, 使用pickle.dump()和pickle.load()方法。在PyTorch中也有同样功能的方法提供。

在torchvision.models模块里,PyTorch提供了一些常用的模型:
• AlexNet
• VGG
• ResNet
• SqueezeNet
• DenseNet
• Inception v3
可以使用torch.util.model_zoo 来预加载它们,具体设置通过参数pretrained=True来实现

加载这类预训练模型的过程中,还可以进行微处理。

1.5 第一个pytorch程序
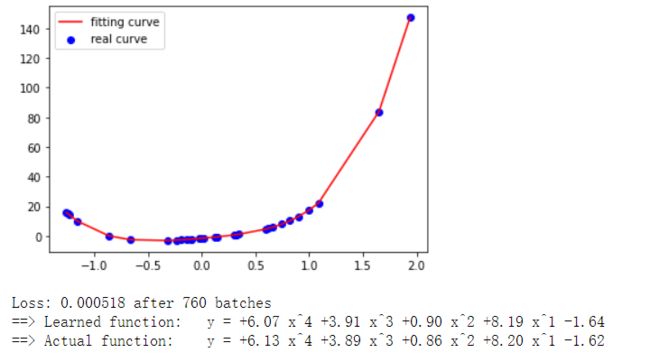
下面的这段程序是对线性回归模型的简单演练。该示例中先创建了一些随机训练样本,让其符合经典线性函数分布,
![]()
并加了一点噪声处理,使得样本出现一定的偏差。接着使用PyTorch创建了一个线性回归的模型,在训练过程中对训练样本进行反向传播,求导后根据指定的损失边界结束训练。最后显示模型学习的结果与真实情况的对比示意图。
#!/usr/bin/env python
from __future__ import print_function
from itertools import count
import numpy as np
import torch
import torch.autograd
import torch.nn.functional as F
from torch.autograd import Variable
import matplotlib.pyplot as plt
random_state = 5000
torch.manual_seed(random_state)
POLY_DEGREE = 4
W_target = torch.randn(POLY_DEGREE,1) * 5
b_target = torch.randn(1) * 5
def make_features(x):
"""创建一个特征矩阵结构为[x,x^2,x^3,x^4]"""
x = x.unsqueeze(1)
return torch.cat([x ** i for i in range(1,POLY_DEGREE + 1)],1)
def f(x):
"""近似函数"""
return x.mm(W_target) + b_target[0]
def poly_desc(W,b):
result = 'y = '
for i, w in enumerate(W):
result += '{:+.2f} x^{} '.format(w, len(W) - i)
result += '{:+.2f}'.format(b[0])
return result
def get_batch(batch_size=32):
"""创建类似(X, f(x))的批数据"""
random = torch.from_numpy(np.sort(torch.randn(batch_size)))
x = make_features(random)
y = f(x)
return Variable(x), Variable(y)
#声明模型
fc = torch.nn.Linear(W_target.size(0),1)
for batch_idx in count(1):
#获取薮据
batch_x,batch_y = get_batch()
#重置求导
fc.zero_grad()
#前向传播
output = F.smooth_l1_loss(fc(batch_x), batch_y)
loss = output.item()
#后向传播
output.backward()
#应用导数
for param in fc.parameters():
param.data.add_(-0.1 * param.grad.data)
#停止条件
if loss < 1e-3:
plt .cla()
plt.scatter(batch_x.data.numpy()[:,0],batch_y.data.numpy() [:,0],label = 'real curve',color = 'b')
plt.plot(batch_x.data.numpy()[:,0], fc(batch_x).data.numpy()[:,0], label='fitting curve', color='r')
plt.legend()
plt.show()
break
print('Loss: {:.6f} after {} batches'.format (loss, batch_idx))
print('==> Learned function:\t' + poly_desc(fc.weight.data.view(-1),fc.bias.data))
print('==> Actual function:\t' + poly_desc(W_target.view(-1),b_target)) 线性回归结果如下图所示:
 以上就是Pytorch初学者系列-基础知识的讲解内容!觉得好的,点赞,在看,分享三连击,谢谢!!!
以上就是Pytorch初学者系列-基础知识的讲解内容!觉得好的,点赞,在看,分享三连击,谢谢!!!
找各类大数据技术文章和面经,就来
<3分钟秒懂大数据>
随时更新互联网大数据组件内容
专为学习者提供技术博文
快和身边的小伙伴一起关注我们吧!