PyTorch入门-语言模型
1. 语言模型概念
语言模型可以对一段文本的概率进行估计,对信息检索,机器翻译,语音识别等任务有着重要的作用。
对于语言序列,语言模型就是计算该序列的概率,即 :
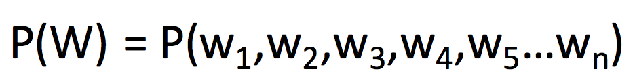
从机器学习的角度来看:语言模型是对语句的概率分布的建模。
通俗解释:判断一个语言序列是否是正常语句,即是否是人话 。
2. torchtext的基本使用
import torchtext
from torchtext.vocab import Vectors
import torch
import numpy as np
import random
USE_CUDA = torch.cuda.is_available()
# 为了保证实验结果可以复现,我们经常会把各种random seed固定在某一个值
random.seed(53113)
np.random.seed(53113)
torch.manual_seed(53113)
if USE_CUDA:
torch.cuda.manual_seed(53113)
BATCH_SIZE = 32
EMBEDDING_SIZE = 650
MAX_VOCAB_SIZE = 50000
说明:
- 继续使用上次的text8作为我们的训练,验证和测试数据
- TorchText的一个重要概念是Field,它决定了你的数据会如何被处理。我们使用TEXT这个field来处理文本数据。我们的TEXT field有lower=True这个参数,所以所有的单词都会被lowercase。
- torchtext提供了LanguageModelingDataset这个class来帮助我们处理语言模型数据集。
- build_vocab可以根据我们提供的训练数据集来创建最高频单词的单词表,max_size帮助我们限定单词总量。
- BPTTIterator可以连续地得到连贯的句子,BPTT的全程是back propagation through time。
TEXT = torchtext.data.Field(lower=True)
train, val, test = torchtext.datasets.LanguageModelingDataset.splits(path=".",
train="text8.train.txt", validation="text8.dev.txt", test="text8.test.txt", text_field=TEXT)
TEXT.build_vocab(train, max_size=MAX_VOCAB_SIZE)
print("vocabulary size: {}".format(len(TEXT.vocab)))
VOCAB_SIZE = len(TEXT.vocab)
train_iter, val_iter, test_iter = torchtext.data.BPTTIterator.splits(
(train, val, test), batch_size=BATCH_SIZE, device=-1, bptt_len=32, repeat=False, shuffle=True)
结果:
vocabulary size: 50002
说明:
- 为什么我们的单词表有50002个单词而不是50000呢?因为TorchText增加了两个特殊的token,表示未知的单词,表示padding。
- 模型的输入是一串文字,模型的输出也是一串文字,他们之间相差一个位置,因为语言模型的目标是根据之前的单词预测下一个单词。
3. torch.nn的一些基本模型
- Linear
- RNN
- LSTM
- GRU
(1)定义模型
- 继承nn.Module
- 初始化函数
- forward函数
- 其余可以根据模型需要定义相关的函数
import torch
import torch.nn as nn
class RNNModel(nn.Module):
""" 一个简单的循环神经网络"""
def __init__(self, rnn_type, ntoken, ninp, nhid, nlayers, dropout=0.5):
''' 该模型包含以下几层:
- 词嵌入层
- 一个循环神经网络层(RNN, LSTM, GRU)
- 一个线性层,从hidden state到输出单词表
- 一个dropout层,用来做regularization
'''
super(RNNModel, self).__init__()
self.drop = nn.Dropout(dropout)
self.encoder = nn.Embedding(ntoken, ninp)
if rnn_type in ['LSTM', 'GRU']:
self.rnn = getattr(nn, rnn_type)(ninp, nhid, nlayers, dropout=dropout)
else:
try:
nonlinearity = {'RNN_TANH': 'tanh', 'RNN_RELU': 'relu'}[rnn_type]
except KeyError:
raise ValueError( """An invalid option for `--model` was supplied,
options are ['LSTM', 'GRU', 'RNN_TANH' or 'RNN_RELU']""")
self.rnn = nn.RNN(ninp, nhid, nlayers, nonlinearity=nonlinearity, dropout=dropout)
self.decoder = nn.Linear(nhid, ntoken)
self.init_weights()
self.rnn_type = rnn_type
self.nhid = nhid
self.nlayers = nlayers
def init_weights(self):
initrange = 0.1
self.encoder.weight.data.uniform_(-initrange, initrange)
self.decoder.bias.data.zero_()
self.decoder.weight.data.uniform_(-initrange, initrange)
def forward(self, input, hidden):
''' Forward pass:
- word embedding
- 输入循环神经网络
- 一个线性层从hidden state转化为输出单词表
'''
emb = self.drop(self.encoder(input))
output, hidden = self.rnn(emb, hidden)
output = self.drop(output)
decoded = self.decoder(output.view(output.size(0)*output.size(1), output.size(2)))
return decoded.view(output.size(0), output.size(1), decoded.size(1)), hidden
def init_hidden(self, bsz, requires_grad=True):
weight = next(self.parameters())
if self.rnn_type == 'LSTM':
return (weight.new_zeros((self.nlayers, bsz, self.nhid), requires_grad=requires_grad),
weight.new_zeros((self.nlayers, bsz, self.nhid), requires_grad=requires_grad))
else:
return weight.new_zeros((self.nlayers, bsz, self.nhid), requires_grad=requires_grad)
(2)初始化一个模型:
model = RNNModel("LSTM", VOCAB_SIZE, EMBEDDING_SIZE, EMBEDDING_SIZE, 2, dropout=0.5)
if USE_CUDA:
model = model.cuda()
说明:
- 我们首先定义评估模型的代码。
- 模型的评估和模型的训练逻辑基本相同,唯一的区别是我们只需要forward pass,不需要backward pass
def evaluate(model, data):
model.eval()
total_loss = 0.
it = iter(data)
total_count = 0.
with torch.no_grad():
hidden = model.init_hidden(BATCH_SIZE, requires_grad=False)
for i, batch in enumerate(it):
data, target = batch.text, batch.target
if USE_CUDA:
data, target = data.cuda(), target.cuda()
hidden = repackage_hidden(hidden)
with torch.no_grad():
output, hidden = model(data, hidden)
loss = loss_fn(output.view(-1, VOCAB_SIZE), target.view(-1))
total_count += np.multiply(*data.size())
total_loss += loss.item()*np.multiply(*data.size())
loss = total_loss / total_count
model.train()
return loss
(3)定义下面的一个function,使得一个hidden state和计算图之前的历史分离。
# Remove this part
def repackage_hidden(h):
"""Wraps hidden states in new Tensors, to detach them from their history."""
if isinstance(h, torch.Tensor):
return h.detach()
else:
return tuple(repackage_hidden(v) for v in h)
(4)定义loss function和optimizer。
loss_fn = nn.CrossEntropyLoss()
learning_rate = 0.001
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
scheduler = torch.optim.lr_scheduler.ExponentialLR(optimizer, 0.5)
(5)训练模型
- 模型一般需要训练若干个epoch
- 每个epoch我们都把所有的数据分成若干个batch
- 把每个batch的输入和输出都包装成cuda tensor
- forward pass,通过输入的句子预测每个单词的下一个单词
- 用模型的预测和正确的下一个单词计算cross entropy loss
- 清空模型当前gradient
- backward pass
- gradient clipping,防止梯度爆炸
- 更新模型参数
- 每隔一定的iteration输出模型在当前iteration的loss,以及在验证集上做模型的评估
import copy
GRAD_CLIP = 1.
NUM_EPOCHS = 2
val_losses = []
for epoch in range(NUM_EPOCHS):
model.train()
it = iter(train_iter)
hidden = model.init_hidden(BATCH_SIZE)
for i, batch in enumerate(it):
data, target = batch.text, batch.target
if USE_CUDA:
data, target = data.cuda(), target.cuda()
hidden = repackage_hidden(hidden)
model.zero_grad()
output, hidden = model(data, hidden)
loss = loss_fn(output.view(-1, VOCAB_SIZE), target.view(-1))
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), GRAD_CLIP)
optimizer.step()
if i % 1000 == 0:
print("epoch", epoch, "iter", i, "loss", loss.item())
if i % 10000 == 0:
val_loss = evaluate(model, val_iter)
if len(val_losses) == 0 or val_loss < min(val_losses):
print("best model, val loss: ", val_loss)
torch.save(model.state_dict(), "lm-best.th")
else:
scheduler.step()
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
val_losses.append(val_loss)
结果:
epoch 0 iter 0 loss 10.821578979492188
best model, val loss: 10.782116411285918
epoch 0 iter 1000 loss 6.5122528076171875
epoch 0 iter 2000 loss 6.3599748611450195
epoch 0 iter 3000 loss 6.13856315612793
epoch 0 iter 4000 loss 5.473214626312256
epoch 0 iter 5000 loss 5.901871204376221
epoch 0 iter 6000 loss 5.85321569442749
epoch 0 iter 7000 loss 5.636535167694092
epoch 0 iter 8000 loss 5.7489800453186035
epoch 0 iter 9000 loss 5.464158058166504
epoch 0 iter 10000 loss 5.554863452911377
best model, val loss: 5.264891533569864
epoch 0 iter 11000 loss 5.703625202178955
epoch 0 iter 12000 loss 5.6448974609375
epoch 0 iter 13000 loss 5.372857570648193
epoch 0 iter 14000 loss 5.2639479637146
epoch 1 iter 0 loss 5.696778297424316
best model, val loss: 5.124550380139679
epoch 1 iter 1000 loss 5.534722805023193
epoch 1 iter 2000 loss 5.599489212036133
epoch 1 iter 3000 loss 5.459986686706543
epoch 1 iter 4000 loss 4.927192211151123
epoch 1 iter 5000 loss 5.435710906982422
epoch 1 iter 6000 loss 5.4059576988220215
epoch 1 iter 7000 loss 5.308575630187988
epoch 1 iter 8000 loss 5.405811786651611
epoch 1 iter 9000 loss 5.1389055252075195
epoch 1 iter 10000 loss 5.226413726806641
best model, val loss: 4.946829228873176
epoch 1 iter 11000 loss 5.379891395568848
epoch 1 iter 12000 loss 5.360724925994873
epoch 1 iter 13000 loss 5.176026344299316
epoch 1 iter 14000 loss 5.110936641693115
best_model = RNNModel("LSTM", VOCAB_SIZE, EMBEDDING_SIZE, EMBEDDING_SIZE, 2, dropout=0.5)
if USE_CUDA:
best_model = best_model.cuda()
best_model.load_state_dict(torch.load("lm-best.th"))
(6)使用最好的模型在valid数据上计算perplexity
val_loss = evaluate(best_model, val_iter)
print("perplexity: ", np.exp(val_loss))
结果:
perplexity: 140.72803934425724
(7)使用最好的模型在测试数据上计算perplexity
test_loss = evaluate(best_model, test_iter)
print("perplexity: ", np.exp(test_loss))
结果:
perplexity: 178.54742013696125
(8)使用训练好的模型生成一些句子
hidden = best_model.init_hidden(1)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
input = torch.randint(VOCAB_SIZE, (1, 1), dtype=torch.long).to(device)
words = []
for i in range(100):
output, hidden = best_model(input, hidden)
word_weights = output.squeeze().exp().cpu()
word_idx = torch.multinomial(word_weights, 1)[0]
input.fill_(word_idx)
word = TEXT.vocab.itos[word_idx]
words.append(word)
print(" ".join(words))
结果:
s influence clinton decision de gaulle is himself sappho s iv one family banquet was made published by paul and by a persuaded to prevent arcane of animate poverty based at copernicus bachelor in search services and in a cruise corps references eds the robin series july four one nine zero eight summer gutenberg one nine six four births one nine two eight deaths timeline of this method by the fourth amendment the german ioc known for his from one eight nine eight one seven eight nine management was established in one nine seven zero they had