异常检测算法综述
一、异常检测
随着人工智能的火热,运维人员也开始考虑将算法引入运维领域,对传统DevOps的核心功能进行优化改进。异常检测是运维不可或缺的重要要功能模块之一,可以提升企业运维能力和效率,释放运维人力。
传统的异常检测主要是通过设置固定阈值的方式实现对业务重要指标(如流量、QPS等)、硬件资源指标(如CUP、内存等)、请求耗时指标等进行异常监控,阈值往往需要随着业务调整进行手动优化,当业务监控指标较多时,Op人员很难对所有的监控指标做到快速、准确反映。基于AI算法的异常检测则提出了动态阈值的概念。
异常的特点:
- 指标数据具有时序性
- 异常点明显大于或小于其他观测点

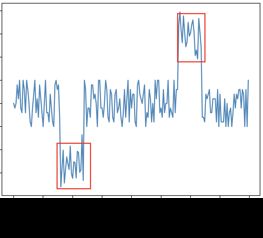
异常的影响:
- 突增:如新用户突然访问或爬虫导致流量突增,一般影响不大,可忽略
- 突降:如网络抖动导致用户操作阻塞,流量会突然下降,一般影响不大,可忽略
- 急剧上升:如系统遭到攻击/用户大量突发访问,使得流量出现暴涨,若没有自动扩容措施,可能会导致系统雪崩,给业务带来损失
- 断崖式下降:如可能由于网络中断/服务宕机等原因导致流量出现断崖式下降甚至为0,给业务造成损失
二、检测方法
异常检测算法主要包含四种类型:统计方法、指标预测法、无监督方法及有监督方法。
2.1 统计方法
2.1.1 构建置信域
根据数据分布来判断异常点,核心在于构建数据的置信域,常见方法:N-σ、Tukey Test
(1)N-σ检测方法:根据均值 和标准差
和标准差 构建置信域(如下左图所示),若数据不在置信域中,则认为是异常点。置信域区间如下
构建置信域(如下左图所示),若数据不在置信域中,则认为是异常点。置信域区间如下
![]()
改进空间:若分布不满足正态性,N-σ方法不再合适,可以检测序列的分布情况,结合统计分布分位点同样可以刻画数据的置信域

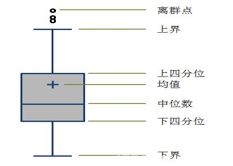
(2)Tukey Test检测方法:根据数据的Q3和Q1分位点的差值![]() ,构建数据的置信域上下限(如上中图所示)。若数据不在置信域中,则任务是异常点。置信域区间如下
,构建数据的置信域上下限(如上中图所示)。若数据不在置信域中,则任务是异常点。置信域区间如下
![]()
(3)优缺点
- 优点:操作简单,计算量少,适合推广
- 缺点:需要调参,不能检测上下文异常场景(如下图)

2.1.2 极端异常点检测
根据数据分布来判断异常点,核心在于确定极端异常点,异常数据必定为最大或最小值。主要方法是ESD系列方法。
(1)ESD检测方法:基于Grubbs’ Test,检验最大值或最小值偏离均值的程度,控制检测点的个数。均值 可以表示趋势,基于残差构建统计量
可以表示趋势,基于残差构建统计量
![]()
若满足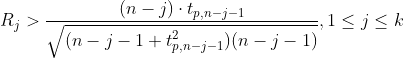 ,则认为该点是异常点
,则认为该点是异常点
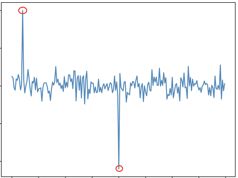
(2)S-ESD检测方法:ESD方法对周期性上凸/下凹是敏感的,去掉周期性因素![]() ,构建误差项
,构建误差项
![]()
(3)S-H-ESD检测方法:异常值会拉伸均值和方差,使用更加鲁棒的中位数![]() 和绝对中位差MAD替换ESD中的均值与标准差
和绝对中位差MAD替换ESD中的均值与标准差
![]()
缺点:无法捕捉到序列的周期性,可能会将在特殊时点上的正常值判断为异常值
2.2 指标预测法
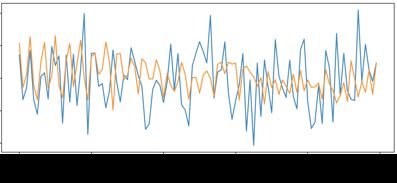
一般是基于当前时点的近期历史数据预测下一个时点的指标值,再与真实值作比较,判断其是否为异常值。因此,通常包含预测器和检测器。预测器对指标值进行预测,检测器对预测结果进行判断。这里主要介绍几个常见的预测器方法
2.2.1 时序回归方法
基于时间序列回归分析方法对目标指标做回归预测,并结合相关策略,判断是否是异常点
(1)ARMA(可逆性&平稳性序列)
![]()

(2)指数平滑(Holt-Winters)

2.2.2 鲁棒回归
检测方法:鲁棒回归不易受异常点影响,对异常点具有较好的抗敏性和鲁棒性。与均方差损失
 (收敛于均值,对异常点敏感)
(收敛于均值,对异常点敏感)
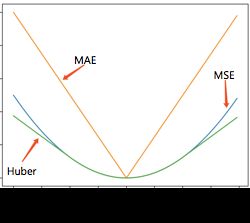
相比,通常具体如下两种损失(绝对值损失 & Huber损失)
 (收敛于中位数,0处不可微)
(收敛于中位数,0处不可微)
![Huber=\frac{1}{n}\sum_{i=1}^{n}[\chi_{|w^T x_i-y_i |<\delta} \frac{1}{2} (w^T x_i-y_i )^2 + \chi_{|w^T x_i-y_i |\ge\delta} (\delta|w^T x_i-y_i |-\frac{1}{2}\delta^2)]](http://img.e-com-net.com/image/info8/36ddf70b6c4646d1b997bebc4052e537.gif) (全局可微、降低异常点影响)
(全局可微、降低异常点影响)
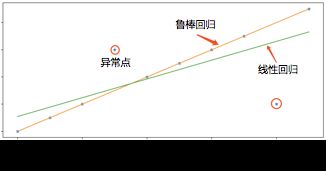
优点:
- 对异常点不敏感,鲁棒性好
- 适用于小样本拟合,可以应用于快速的、批量的异常检测中
- 可以作为局部异常值修复和缺失值填充方法
2.3 无监督方法
根据样本点的分布情况,采用某些基于距离的无监督算法,可以找出一些异常点
2.3.1 IForest
Isolation Forest(孤立森林):异常点一般都是非常稀有的,在iTree中会很快被划分到叶子节点
step1.建树:分裂时,会随机选取一个特征,然后在该特征的最大值和最小值之间随机选择一个分切面,在左、右节点上再进行同样的分割,最终生成了一棵随机二叉树(iTree)。根节点到叶子节点(样本)的路径距离(样本在树的深度)就是样本分裂次数,记为h
step2.建森林:从样本集D中随机抽取n个样本(≪|D|)重复第1步构建多棵树,形成一个森林;
step3.建指标:样本在所有随机树中的分裂次数hh的平均值![]() ;
;
step4.归一化(异常得分):指标归一化处理(0,1),异常点接近于1
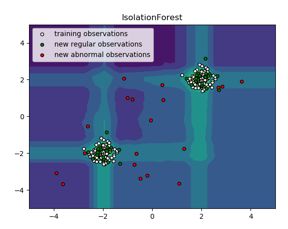
优点:
- 适用于高纬度、海量数据集
- 适合分布式计算
- 鲁棒性强
2.3.2 One Class SVM
训练生成一个超球面,将训练样本尽可能包裹起来
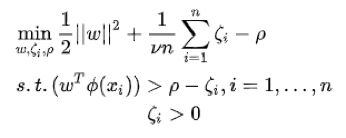
![]()
![]()

优点:
- OneClassSVM不是一种异常点检测方法,而是一种新颖点检测方法:它的训练集不包含异常点,因为模型可能会去匹配这些异常点。但在数据维度很高,或者数据分布没有任何假设的情况下,OneClassSVM也可以作为一种很好的异常检测方法。
- 在二分类问题中,若样本分布严重失衡,可以将占比少的类别看作异常点,采用无监督的OneClassSVM完成分类。
2.3.3 DBSCAN
基于局部质心聚合,生成可聚合的样本簇,孤立的样本则是不可聚合的异常样本点。主要有四个核心概念
- 核心点
- 密度直达
- 密度可达
- 密度相连

优点:
- 不需要事先指定聚类个数,且可以发现任意形状的聚类;
- 对异常点不敏感,在聚类过程中能自动识别出异常点;
缺点:
- 耗时、参数调优复杂
【无监督异常检测】的缺点:
- 面临着与概率统计方法一样的问题,对周期性序列中的一些波动不敏感
- 需要较多的数据进行训练,存储模型,耗资源
2.4 有监督方法
基于异常标注数据,采用监督二分类方法,对异常点直接进行预测,是一种端到端的预测方式。常用模型LR、SVM、XGBoost、DNN等。评估指标一般采用召回率、准确率、AUC等。
优点
- 基于标注数据的有监督分类算法体系成熟;
- 只要合适的数据,通常可以实现端到端的预测,更加智能化。
缺点
- 标注数据缺陷。人工标注耗时耗力;基于规则的标注灵活性较差,标注的数据准确性较差,需要不断调整规则; 短期内很难获取到足够多的正样本;
- 样本数据通常存在严重的失衡情况
总结:运维异常检测系统的搭建是一个循序渐进的过程。初始阶段,数据积累不多,一般采用统计方法或时序预测器&检测器的方式来快速实现系统的搭建,这既可以在一定程度上满足业务需求,也可以为后续复杂的机器学习算法积累数据。这一阶段检测的效果往往不是很理想,需要业务RD和Op人员进行一定的干预和监控。当数据积攒到足够数量(主要是异常数据)后,便可通过无监督和有监督的算法来对异常检测系统进行升级优化,提升异常检测的效率和准确度,减少人工干预。