yolov1论文通俗解读
论文:https://arxiv.org/pdf/1506.02640.pdf
关于代码,不是很推荐跑yolov1的代码,学yolov1主要还是为学习后面的yolo算法打个基础,代码跑v5或v7的就可以了。
yolo的思想
用一个神经网络直接预测目标物体的类别和边界框的坐标、长宽、置信度。

Yolo的三大优势
①够快。two-stage思想的目标检测算法相比one-stage的算法还多了一步筛选框的步骤,拿找结婚对象做比喻,yolo好比是自己与对象接触了解然后自己做决定,two-stage好比是自己与对象接触然后还多了一步比如让父母或朋友参考讨论。因此yolov1的速度很快,但是精度要略微逊色于当时的先进算法。

②yolo考虑到了图像全局的信息。比如说你要遇到的目标在图像的中间,但是图像边缘的信息也会参与考虑进来。

③yolo学习到了目标物体的可概括性表征信息。说白了,就是用训练所用的数据训练出模型后,拿新的数据来测试,yolo出错的概率更小,也就是所谓的泛化性更强。

检测流程
将图像输入神经网络,最终会得到SxS大小(S即长宽大小)的特征图,这里暂且不考虑batch和特征图的深度。我们可以把这个特征图看成这样一个图:

然后每个格子分别来预测下自己负责的部分是啥东西,像上面这幅图49个格子,那么这49个格子都要来做检测。当要预测的对象的中点落在了一个格子的区域内,那这个对象就归这个格子来预测了。

要预测的东西分别有:x,y,w,h,置信度,假设是个十分类任务,还要预测十个概率值(分别计算属于各个类别的概率,概率最大的那个类别就是分类的结果)。
x和y就是一个格子要预测的边界框的中心点的坐标(相对于目前的格子的,不是整张图的坐标);w和h预测的是相对于整张图像的该目标的长宽,意思就是这个长宽的数值占图像长宽多少比例这样;置信度表示的是这个格子预测的地方,有具体物体而不是背景的可能性有多大,数值范围在0~1。预测是背景置信度直接是0,预测含有物体时,就要给出含有物体的可能性多大,这个数值其实就是预测的框和真实的人手工标出来的框的IOU值。
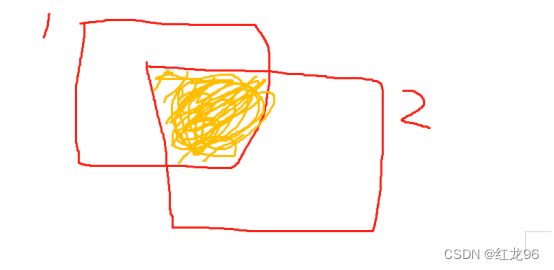
我们假设1号框是当前格子预测出来的框,2号框是我们人工标出来的框,IOU就是橙色部分面积与橙色部分面积加上白色部分面积的比值。

关于要预测的分类概率,这里要预测的是条件概率,它的条件前提就是这个网格有包含物体,公式如下:

但是Pr(Object)的数值要么是0要么是1,也就是要么是背景要么含有物体,所以预测分类的概率可以理解为:有物体就预测下它分属于各个类别的概率,确定是个背景的话就不管它了。
这里再强调一遍,上面x,y,w,h,置信度,分类概率的预测,都是每一个网格分别进行。不过yolov1是让每个格子都会计算两次x,y,w,h,置信度,即计算两个框,就像我们考完试都要多看看题检查一下。
这里论文还有提到,当我们训练好了模型,来进行测试时,测试结果返回的那个得分与这个分类的概率并不是同一个东西。

像上面这个图就是我们用yolo得到的一个结果,除了预测出目标物体的框、属于什么类别,还会得到一个范围在0~1之间的一个分数,这个分数的计算如下:

意思就是这个分数的计算是:由预测的属于这个类别的概率,乘以预测的置信度。即综合考虑了这个目标是一个物体的概率和属于这个类别的概率。
以上就是一套yolov1进行下来的流程,我们可以思考下,上面那个被划分为49个网格的图片,假设要预测的类别有20种,那么最终会预测几个数值?最终答案如下:7x7x(5x2+20)。
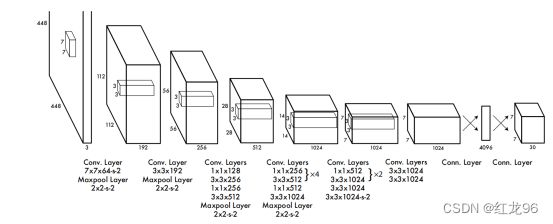
网络架构设计
yolov1的网络设计非常简单,一句话概括就是卷积网络提特征,全连接网络搞下游检测任务。网络结构图如下:
yolov1采用的激活函数如下:
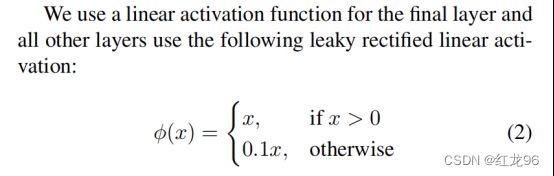
大意就是:数值大于0的话就保持不变,小于0的话也别舍弃它而是让它的大小缩小十倍。
损失函数
yolov1的损失函数采用均方误差,就是预测值与真实值的差的平方,再开一个根号。要计算的误差也就是之前我们预测的那几个:x,y,w,h,置信度,分类概率。误差分为这几类:位置误差(x,y,w,h)、置信度误差、分类误差。这里论文里提到了这种损失函数在yolo中存在两个问题:
①一张图里不包含物体的区域要远多于包含物体的区域,因此置信度误差的数值可能会偏大,这是不利于模型训练的,因此要将含有物体的区域的置信度误差和不含物体的区域的置信度误差分开来计算,并设定超参数来强化前者的权重,削弱后者的权重。

②对于大目标物体和小目标物体,大目标物体如果只是偏个10厘米可能不算差的很多,但对于小目标来说这个误差就很大了。也就是说,该损失函数对于大目标和小目标物体是不平等的。因此在计算位置误差时,要给w和h都计算平方根再来计算,这样w和h越大,大小增长得也就越慢,能一定程度缓解对小目标物体检测效果较差的问题。
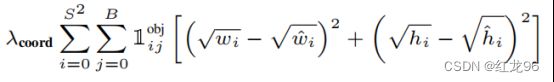
最终yolov1的损失函数如下:

这里我们要注意一点,我们之前提过,每个网格都要预测2次位置和置信度(损失函数里的那个B就是指这个次数),但是不管这个B设为多少,预测分类概率都只要预测一次就行了。那么B次的预测自然也会产生B次分类概率,那么我们选用哪一次的结果做为最终的分类概率呢?论文里给出的回答是:看哪次预测得到的框和真实框的IOU最高就用那个。

其他训练策略
①学习率。yolov1的学习率策略,说白了就是先升再降。开头把学习率设为0.001,然后在第1次训练中慢慢升高为0.01,然后之后75次训练学习率都为0.01,然后降低学习率为0.001,连续训练30次,再把学习率降为0.0001,连续训练30次。

②通过dropout和数据增强来减小过拟合的风险。这里都是常规策略。

③非极大值抑制。前面我们有提到,每个网格都要进行预测工作,但这样会有一个问题,就是两个很相近的网格,会对图像里同一个物体进行预测,这会导致同一个物体有好几个框。比如下图中出现了3个框,就是1、2、3号网格分别预测的结果。

而非极大值抑制就是要从这几个预测框只挑选一个出来,而评判的标准就是看每个预测框和真实框之间的IOU大小。
yolov1的局限性
①yolov1让图像里每个网格只预测2个框和1个分类结果,这么做有一个缺陷,就是当一个大物体旁边有一个小物体时,可能无法检测出来,而是会把小物体也算进大物体里面,通俗得说,对俩靠的很近得物体分类效果不好,而且对小物体尤其不友好。

②当预测的物体长宽比不常见或者说训练数据里没有时,yolov1预测的效果会有不好的影响。同时因为网络架构中采用了多次的降采样,这导致图像损失了信息,使得提取的特征会相对粗糙,从而影响了检测效果。

③还有就是对小物体的检测不友好。有的误差数值对于大物体检测出来的框可能只是很小的误差,但对于小物体检测出来的框可能就是很大的数值了。还有就是像IOU的计算结果就受到了框的大小很大的影响。
