Entity Relation Fusion for Real-Time One-Stage Referring Expression Comprehension 2021
**本文内容仅代表个人理解,如有错误,欢迎指正**
*****(原论文在方法部分写得有点套娃的意思,实在是有点乱,内心os:心平气和心平气和)
1. Problems
- 这篇论文主要提出两个问题:
1) 用一个向量来对Query进行表示,没有对Query当中丰富的物体关系进行推理,即没有有效地利用Query中的信息。
2) 采用特征金字塔提取图像不同层级的特征,得到不同尺度的特征图。分别在不同尺度的特征图上对目标物体进行框选,忽略了处于不同尺度特征图上的物体之间的相关性。
2. Points
1. 提出Entity Relation Fusion Network (ERFN)模型
2. 提出Language Guided Multi-Scale Fusion (LGMSF)模型,以语言为指导,将不同尺度特征图上的物体表示融合为一张特征图。
“Language Guided Multi-Scale Fusion(LGMSF) model for extracting different visual featureof objects with different scales on one feature map. ”
3. 提出Relation Guided Feature Fusion (RGFF)模型,在自注意力的基础上,通过从Query中提取出实体信息来增强特征图中目标的特征表示,通过从Query中提取物体之间的关系来指导物体特征融合。
“Relation Guided Feature Fusion(RGFF) model extracts entities in the language expression toenhance the referred entity feature in the visual object feature map, and further extracts relations to guide object feature fusion basedon the self-attention mechanism.”
* 基本上,这篇论文想实现的功能如图一所示。

图一
3. Main Components

- 如Figure 2所示,ERFN模型主要可以分为三个部分,其中特征提取部分与预测部分属于常规操作,这里不多赘述,主要介绍LGMSF模型与RGFF模型。
1)特征提取部分:利用CNN backbone+FPN提取不同尺度的feature maps,利用RNN提取textual features。
2)LGMSF模型与RGFF模型:
3)预测部分:预测目标物体的位置。
3.1 Language Guided Multi-Scale Fusion (LGMSF)模型
- LGMSF model主要工作:在query的指导下,将图片输入CNN backbone+FPN得到的多个不同尺度的特征图融合为一个特征图,并且融合后的特征图包含了query中包含的所有物体的特征。
- 具体步骤:
1) 首先是将不同尺度的特征图采样到一个特定的大小,并分别用两个卷积层与MLP层对visual feature和language feature的通道数进行调整,得到 与
与 。
。
2) 计算每个特征图上每个位置的visual feature与language feature之间的匹配程度(类似于计算相关性),得到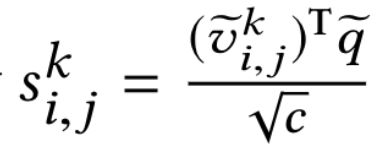 。其中,
。其中,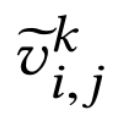 是在k特征图上在每个位置(i, j)上的特征。然后将
是在k特征图上在每个位置(i, j)上的特征。然后将 过一层softmax函数得到语言指导下的注意力权重
过一层softmax函数得到语言指导下的注意力权重 ,再分别利用权重与相对应层的特征图进行Element-wise Dot,可以得到语言指导下注意力后(原属于不同层级的)特征图,最后将这三张特征图进行element-wise Addition,得到融合的特征图
,再分别利用权重与相对应层的特征图进行Element-wise Dot,可以得到语言指导下注意力后(原属于不同层级的)特征图,最后将这三张特征图进行element-wise Addition,得到融合的特征图 。
。
3.2 Relation Guided Feature Fusion (RGFF)模型
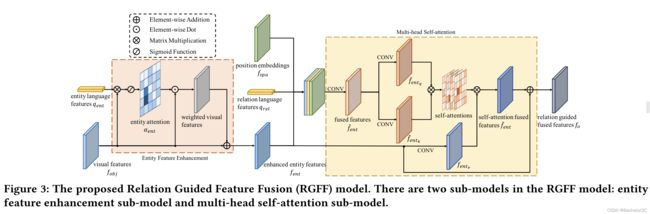
- RGFF model主要工作:增强【query中涉及到的实体】的特征,并在【query中涉及的物体关系】指导下融合物体特征。
- 具体步骤:
1) 首先利用一个Word Classfier,对word features进行分类,提取出属于Entity和Relation的feature。简单来说就是,去预测query中每个词的类别,然后得到属于Entity和Relation的representation。("To predict the category of each word in the language expression to get the entity and relation representations in language expression.")
2) 利用entity representation与LGMSF得到的fused feature map做attention,得到注意力后的weighted visual features,再将这个注意力后的weighted visual features与fused feature map相加,得到enhanced entity features。(其实就是在特征图里突出实体特征)
3) 对position embeddings、relation language features和enhanced entity features进行融合,得到fused features。进行自注意力操作,即Q、K都来自fused features,V来自enhanced entity features。自注意力操作后,得到self-attention fused features,将其与enhanced entity features相加作为最终relation guided fused features。
**最后grounding module的输入一共有三个,第一个是language representation;第二个是relation guided fused features;第三个是position embedding。
4. Experimental Results
- 总体实验效果差强人意,一阶段模型的比较不够充分。
- 官方解释:"Features of objects with large scale can be suppressed by other objects with smaller scales from other layers." 所以在RefCOCO和RefCOCO+的test A中表现不好(因为testA中gt基本都是人,属于大物体)?但在testB中表现良好,因为testB中大多gt都非人?(WHY?)

- 消融实验
- 其中,L表示LGMSF,s表示self-attention,e表示entity enhancement feature,r表示relation feature,p表示position embedding。

- 可视化结果
- entity attention还能看出点什么东西,即确实突出了实体的特征;但是relation attention就完全迷惑了,不知道作者想体现什么,就跟RGFF里relation操作一样,不明所以。