torchvision.datasets.ImageFolder前的数据整理及使用方法
通常在一个完整的神经网络训练流程中,我们常常需要构建Dataset和Dataloader用于后续模型训练时的数据读取,一般我们自己定义一个Dataset类,重写
__geiitem__和__len__函数来构建Dataset。然而对于简单图像分类任务而言,无需自己定义Dataset类,调用torchvision.datasets.ImageFolder函数即可构建自己的Dataset,非常方便。
本代码参考李沫老师的《动手学深度学习》
一. 将数据集整理成函数指定格式
既然是调用API,那么数据集必然得按照API的要求去组织, torchvision.datasets.ImageFolder 要求数据集按照如下方式组织:
A generic data loader where the images are arranged in this way:
root/dog/xxx.png
root/dog/xxy.png
root/dog/xxz.png
···
root/cat/123.png
root/cat/nsdf3.png
root/cat/asd932_.png
其中dog和cat表示图片的标签。在根目录下,我们需要将每一个种类都创建一个文件夹,并在该文件夹下存入该种类对应的图片。如果我们的图片分为apple、banana和orange三类,那么我们就需要创建三个文件夹,名称对应三个标签,文件夹下存放标签对应的图片。
然而有时候我们拿到的数据集并不是正好这种格式的,这时就需要我们整理数据集,人工整理非常耗时,下面我将以一组数据集为例,介绍如何用程序将数据集整理成需要的格式,其他格式的数据集也可以作参考。
1.1 原始数据集格式
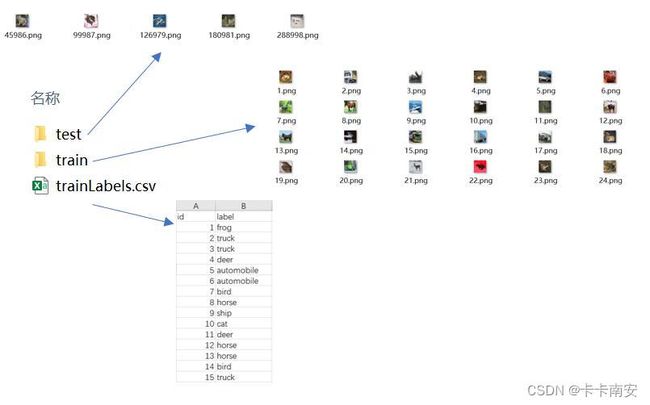
- test:待分类的图片,共5张
- train:训练集图片,共1000张
- trainLabels.csv:训练集中每张图片对应的种类
1.2 整理数据集
import collections
import math
import os
import shutil
import pandas as pd
import torch
import torchvision
from torch import nn
from d2l import torch as d2l
'''下载数据集'''
#@save
d2l.DATA_HUB['cifar10_tiny'] = (d2l.DATA_URL + 'kaggle_cifar10_tiny.zip','2068874e4b9a9f0fb07ebe0ad2b29754449ccacd')
data_dir = d2l.download_extract('cifar10_tiny') #返回根目录的地址
首先,我们用以下函数读取CSV文件中的标签,它返回一个字典,该字典将文件名中不带扩展名的部分映射到其标签。
#@save
def read_csv_labels(fname):
"""读取fname来给标签字典返回一个文件名"""
with open(fname, 'r') as f:
# 跳过文件头行(列名)
lines = f.readlines()[1:]
tokens = [l.rstrip().split(',') for l in lines]
return dict(((name, label) for name, label in tokens))
labels = read_csv_labels(os.path.join(data_dir, 'trainLabels.csv'))
print('# 训练样本 :', len(labels))
print('# 类别 :', len(set(labels.values())))
'''
输出:
# 训练样本 : 1000
# 类别 : 10
其中label为以下内容:
{'1': 'frog',
'2': 'truck',
'3': 'truck',
'4': 'deer',
'5': 'automobile',
'6': 'automobile',
···}
'''
接下来,我们定义reorg_train_valid函数来将验证集从原始的训练集中拆分出来。 此函数中的参数valid_ratio是验证集中的样本数与原始训练集中的样本数之比。 更具体地说,令 n 等于样本最少的类别中的图像数量,而 r 是比率。 为保证验证集中每个种类的图片数量相同,验证集将为每个类别拆分出 max(⌊nr⌋,1) 张图像。 因此最终验证集图片的总量为max(⌊nr⌋,1)乘以类别数
在此案例中,最少类别中的图片数量为85,比例为0.1,因此最终验证集的数量为 ⌊85×0.1⌋×10=80
#@save
def copyfile(filename, target_dir):
"""将文件复制到目标目录"""
os.makedirs(target_dir, exist_ok=True)
shutil.copy(filename, target_dir)
#@save
def reorg_train_valid(data_dir, labels, valid_ratio):
"""将验证集从原始的训练集中拆分出来"""
# 训练数据集中样本最少的类别中的样本数
n = collections.Counter(labels.values()).most_common()[-1][1]
# 验证集中每个类别的样本数
n_valid_per_label = max(1, math.floor(n * valid_ratio))
label_count = {}
# 遍历训练集中的所有图片
for train_file in os.listdir(os.path.join(data_dir, 'train')):
# 获取图片对应的label
label = labels[train_file.split('.')[0]]
# 获取图片地址
fname = os.path.join(data_dir, 'train', train_file)
# 将图片复制到label对应的文件夹下
copyfile(fname, os.path.join(data_dir, 'train_valid_test',
'train_valid', label))
# 如果验证集还没存满,则把图片存到对应label的验证集下
if label not in label_count or label_count[label] < n_valid_per_label:
copyfile(fname, os.path.join(data_dir, 'train_valid_test',
'valid', label))
label_count[label] = label_count.get(label, 0) + 1
# 如果验证集存满了,则把图片存到对应label的训练集下
else:
copyfile(fname, os.path.join(data_dir, 'train_valid_test',
'train', label))
return n_valid_per_label
函数reorg_train_valid会生成一个大文件夹train_valid_test,里面有三个文件夹,分别是:
- train_valid:存放所有图片,即1000张
- valid:存放验证集图片,即80张
- train:存放训练集图片,即920张
每一个文件夹下都是各个种类对应的文件夹。
下面的reorg_test函数用来整理测试集,以方便预测时读取。
#@save
def reorg_test(data_dir):
"""在预测期间整理测试集,以方便读取"""
# 将图片存入unknow文件夹内
for test_file in os.listdir(os.path.join(data_dir, 'test')):
copyfile(os.path.join(data_dir, 'test', test_file),
os.path.join(data_dir, 'train_valid_test', 'test',
'unknown'))
测试集的图片将保存在一个名为unknown的文件夹下。
最后,我们使用一个函数来调用前面定义的函数read_csv_labels、reorg_train_valid和reorg_test。
"""输入为根目录的地址和比率"""
def reorg_cifar10_data(data_dir, valid_ratio):
labels = read_csv_labels(os.path.join(data_dir, 'trainLabels.csv'))
reorg_train_valid(data_dir, labels, valid_ratio)
reorg_test(data_dir)
valid_ratio = 0.1
reorg_cifar10_data(data_dir, valid_ratio)
运行后,根目录下将会生成一个名为train_valid_test的文件夹,里面包含test、train、train_valid和valid四个文件夹。

二. 调用torchvision.datasets.ImageFolder构造Dataset
torchvision.datasets.ImageFolder(root,transform,target_transform,loader)
- root:图片存储的根目录,即各类别文件夹所在目录的上一级目录,在上面的例子中,训练集的根目录为
./train_valid_test/train - transform:对图片进行预处理的操作(函数),原始图片作为输入,返回一个转换后的图片
- target_transform:对图片类别进行预处理的操作,输入为 target,输出对其的转换。如果不传该参数,即对 target 不做任何转换,返回的顺序索引 0,1, 2…
- loader:表示数据集加载方式,通常默认加载方式即可
另外,该 API 有以下成员变量:
- self.classes:用一个 list 保存类别名称
- self.class_to_idx:类别对应的索引,与不做任何转换返回的 target 对应
- self.imgs:保存(img-path, class) tuple的 list,与我们自定义 Dataset类的 __getitem__返回值类似
构造训练集、验证集、测试集的Dataset如下所示:
"""图像增广,可以根据自己需求修改"""
transform_train = torchvision.transforms.Compose([
# 在高度和宽度上将图像放大到40像素的正方形
torchvision.transforms.Resize(40),
# 随机裁剪出一个高度和宽度均为40像素的正方形图像,
# 生成一个面积为原始图像面积0.64到1倍的小正方形,
# 然后将其缩放为高度和宽度均为32像素的正方形
torchvision.transforms.RandomResizedCrop(32, scale=(0.64, 1.0),
ratio=(1.0, 1.0)),
torchvision.transforms.RandomHorizontalFlip(),
torchvision.transforms.ToTensor(),
# 标准化图像的每个通道
torchvision.transforms.Normalize([0.4914, 0.4822, 0.4465],
[0.2023, 0.1994, 0.2010])])
transform_test = torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize([0.4914, 0.4822, 0.4465],
[0.2023, 0.1994, 0.2010])])
"""构造Dataset"""
train_ds, train_valid_ds = [torchvision.datasets.ImageFolder(
os.path.join(data_dir, 'train_valid_test', folder),
transform=transform_train) for folder in ['train', 'train_valid']]
valid_ds, test_ds = [torchvision.datasets.ImageFolder(
os.path.join(data_dir, 'train_valid_test', folder),
transform=transform_test) for folder in ['valid', 'test']]
在训练期间,我们需要指定上面定义的所有图像增广操作。 当验证集在超参数调整过程中用于模型评估时,不应引入图像增广的随机性。 在最终预测之前,我们根据训练集和验证集组合而成的训练模型进行训练,以充分利用所有标记的数据。
构造好Dataset后就可以继续构造Dataloader:
train_iter, train_valid_iter = [torch.utils.data.DataLoader(
dataset, batch_size, shuffle=True, drop_last=True)
for dataset in (train_ds, train_valid_ds)]
valid_iter = torch.utils.data.DataLoader(valid_ds, batch_size, shuffle=False,
drop_last=True)
test_iter = torch.utils.data.DataLoader(test_ds, batch_size, shuffle=False,
drop_last=False)
最后就拿着Dataloader去开心地炼丹吧~