2016-CVPR-YOLO
论文下载:http://arxiv.org/abs/1506.02640
代码下载:https://github.com/pjreddie/darknet
此篇博客为半原创,在翻译论文的同时参考了网上的一些翻译与理解,受益颇多,在此感谢其他博主。
参考资料没有列全,深感抱歉。
文中如有错误,请积极指出,一起学习,共同进步。
物体检测一系列方法:DPM、R-CNN、Fast R-CNN、Faster R-CNN、YOLO、YOLOv2、SSD、Mask R-CNN等会陆续更新。
Title:You Only Look Once: Unified, Real-Time Object Detection
Writer: Joseph Redmon, Santosh Divvalay, Ross Girshick, Ali Farhadiy
关注RBG大神的相关论文。
Abstract
- 这篇文章提出了一个新的检测方法:You Only Look Once(YOLO)
- 之前的物体检测方法通常都转变为一个分类问题,比如R-CNN、Fast R-CNN等,YOLO将检测转变为一个回归问题。
(注意:分类问题的输出变量是有限个离散值;回归问题用于预测输入变量和输出变量之间的关系,输出变量是连续值,回归模型表示从输入变量到输出变量之间的函数。回归问题的学习等价于函数拟合:选择一条函数曲线使其很好地拟合未知数据且很好地预测未知数据。 )
- YOLO从输入的图像,仅仅经过一个neural network(即将目标区域位置预测和目标类别预测整合于单个神经网络模型),直接得到bounding boxes(包围盒)以及每个bounding box所属类别的概率。因为整个检测过程仅有一个网络,所有YOLO可以直接end-to-end的优化。
(注意:end-to-end,即输入是原始数据,输出是预测目标,只关心输入和输出,中间步骤不管。即原始数据输入到CNN网络中,直接输出图像中所有目标的位置和类别。原来的输入端不是直接的原始数据,而是在原始数据中提取的特征。)
- YOLO结构十分的快,标准的YOLO版本实时处理图像45帧/秒,一个较小版本Fast YOLO,可以达到155帧/秒。它的mAP依然可以达到其他实时监测算法的两倍。
(注意:mean Average Precision,平均精确率,目标检测中衡量识别精度的指标。过程:1.先把所有bounding box找出来,并加上confidence ;2.然后每一类根据confidence从大到小排列;3.每个confidence算出其recall和precision得到每一类的ap曲线 ;4.取mean。)
- 同时相比较于其他的state-of-art detection systems(先进的检测系统),尽管YOLO有更多的localization errors(定位错误,即,坐标错误),但是它有更少的false-positive。
(注意:false-positive就是指误报数,即将负类预测为正类数。文章中提到的backgroud errors指的就是false-positive。)
- YOLO可以学习到物体更泛化的特征,在将YOLO用到其他领域的图像时(比如artwork),其检测效果要优于DPM、R-CNN这类方法。
(注意:关于DPM、R-CNN的论文也要精读。)
1 Introduction
- 设计理念来源:人类只要看一眼图像,就能立刻知道图像中的物体在哪里,以及物体之间的相互作用。人类的视觉系统是快速和准确的,允许我们执行复杂的任务。因此YOLO借鉴了这种思想。
- 现有检测系统:将物体检测问题转变为一个分类问题,采用一个分类器去评估一张图像中,各个位置一定区域的window或者bounding box内,是否包含一个物体?包含了哪些物体?
- DPM:(Deformation Parts Models,可变形的零件模型?)采用的是sliding window(滑动窗)的方式去检测。
(注意:sliding window方式就是穷举搜索(Exhaustive Search),选择一个窗口扫描整张图像,改变大小再扫描图像。通过改变窗口大小来适应物体的不同尺寸。做法原始,耗时,杂乱。)
- R-CNN、Fast R-CNN:采用的是region proposals(候选框)的方法,先生成一些可能包含待检测物体的potential bounding box,再通过一个分类器判断每个bounding box里是否包含物体,以及物体所属类别的probablity或者confidence。这种方法的pipeline需要经过好几个独立的部分,所以检测速度很慢,也难以去优化,因为每个独立的部分都需要单独训练。
(注意:selective search选择性搜索,用于目标检测的区域推荐算法,根据颜色、纹理、大小和形状的兼容性,计算相似区域的层次分组。采用图像分割以及使用一种层次算法适应不同尺寸的图像,多样性(使用颜色、纹理、大小等多种策略对分割好的区域进行合并)、计算速度快。)
- YOLO:将物体检测问题转变为回归问题,end-to-end方法。直接从图像像素(即输入)到bounding box和probabilities(即输出)。YOLO系统看了一眼图像就能predict是否存在物体,他们在哪个位置,所以就叫做You Only Look Once(是不是很人类视觉系统很像?)。YOLO的idea十分简单,如图1:
将图像输入一个单独的CNN网络,就会predict出boundingboxes,以及这些bounding boxes所属类别的概率。YOLO用一整幅图像来训练,同时可以直接优化detection performance(检测性能)。

- YOLO优点:
- YOLO检测系统非常快。因为将检测架构设计成一个回归问题,不需要复杂的pipeline。在Titan X(顶级显卡配置)上,不需要经过批处理,标准版本的YOLO系统可以每秒处理45帧图像;Fast YOLO可以处理150帧图像。这就意味着YOLO可以以小于25ms延迟的处理速度,实时地处理视频。同时,YOLO实时监测的mAP是其他实时监测系统的两倍。
(注意:一般电影都是30帧/s,高清版是60帧/s。)
- YOLO在做predict的时候,使用的是全局图像。与sliding window和region proposals这类方法不同,YOLO一次看一整张图像,所以它可以将物体整体的class information和appearance information 进行encoding。目前最好的是Fast R-CNN,较容易误将图像中的background patches看成是物体,因为它看的范围比较小。YOLO的background errors比Fast R-CNN少一半多。
- YOLO学到物体更泛化的特征表示。当在自然场景图像上训练YOLO,再在artwork图像上去测试YOLO时,YOLO的表现甩DPM、R-CNN好几条街。YOLO模型更能适应新的领域。
(注意:结构上的主要特点就是unified detection,使得模型的运行速度快,可以直接学习图像的全局信息,且可以end-to-end训练)
- 但相比R-CNN系列物体检测方法,YOLO具有以下缺点:
- 识别物体位置精准性差。
- 召回率低。
2 Unified Detection
- YOLO将对象检测的单独部分统一为一个neural network,使用来自整个图像的特征来预测每个边界框,并且同时predict图像的所有边框,这意味着它在全局范围内对完整的图像和图像中的对象产生了影响。YOLO设计实现end-to-end训练和实时速度,同时保持较高的平均精度。
- YOLO检测系统,先将输入图像分成S x S个grid(栅格),如果一个物体的中心掉落在一个grid cell内,这个grid cell就负责检测这个物体。
- 每一个grid cell预测B个bounding boxes和它们的confidence scores。这些confidence scores反映了这个模型是否包含物体,以及是这个物体的可能性是多少。confidence的计算公式为:
![]()
如果这个cell中不存在object,则score就为0;否则score就为predictedbox与ground truth之间的IOU。
(注意:IOU,intersectionover union,就是模型的预测窗口和目标窗口的重叠率,是DetectionResult与GroundTruth的交集比上它们的并集。)
- 每一个bounding box包含5个predictions:x, y, w, h, confidence。(x, y)表示bounding box的中心与grid cell边界的相对值;width、height则是相对于整幅图像的预测值;confidence就是IoU值。
- 每一个grid cell还要预测C个conditional class probabilities(条件类别概率,针对grid cell):Pr(Classi|Object)。这些概率被限制在一个object的grid cell上,不管grid cell 中包含多少个bounding boxes,每个grid cell只预测每个类别的条件概率。
- 在测试阶段,将每个grid cell的conditional class probabilities与每个box的confidence predictions相乘:
![]()
上面得到每个bounding box的class-specific confidence score。这样就把bounding box中预测的类别概率与bounding box中的object很好的契合,都进行了encoding。
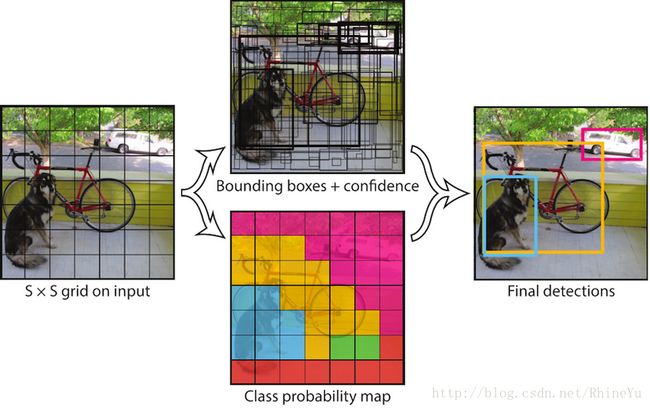
- 上图解释,将YOLO用于PASCAL VOC数据集时:
- 本文使用的S=7,即将一张图像分成7x7=49个grid cells
- 每一个grid cell预测B=2个bounding boxes(每个bounding box都有5个值,(x, y, w, h, confidence))
- 同时,PASCAL数据集中有20个类别,则,C=20
- 因此,最后的prediction是7x7x30的tensor
- 卷积层负责提取特征,全连接层负责预测。
2.1 Design
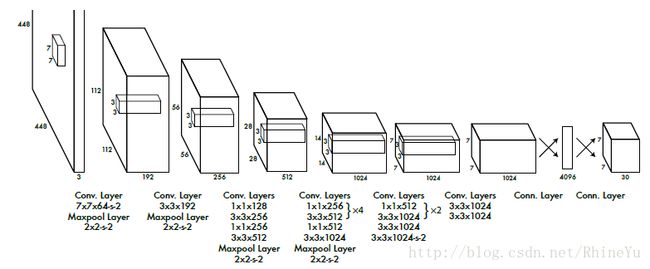
- YOLO仍用CNN实现,在PASCAL VOC检测数据集上进行评估。最初的卷积层从图像中提取特征,全连接层预测输出概率和坐标。YOLO的CNN结构取自两篇论文:GoogLeNet、Network in Network(要去读!)。YOLO有24个卷积层,随后是2个全连接层。不像GoogLeNet中使用的inception modules,YOLO采用了Network in NetWork中的结构,在3x3卷积层之后,跟着一个1x1的层。网络结构如下图所示:
(注意:GoogLeNet提出了Inception module的概念,旨在强化基本特征提取模块的功能,一般的卷积层只是一味增加卷积层的深度,但是在单层上卷积核只有一种,比如对于VGG,单层卷积层只有3X3大小的,这样特征提取的功能可能就比较弱。GoogLeNet想的就是能不能增加单层卷积层的宽度,即在单层卷积层上使用不同尺度的卷积核,GoogLenet构建了Inception module这个基本单元,基本的Inceptionmodule中有1x1卷积核,3x3卷积核,5x5卷积核还有一个3x3下采样)
(注意:Network in Network,提出两个重要观点:
1.1×1卷积的使用
文中提出使用mlpconv网络层替代传统的convolution层。mlp层实际上是卷积加传统的mlp(多层感知器),因为convolution是线性的,而mlp是非线性的,后者能够得到更高的抽象,泛化能力更强。在跨通道(crosschannel,cross feature map)情况下,mlpconv等价于卷积层+1×1卷积层,所以此时mlpconv层也叫cccp层(cascadedcross channel parametric pooling)。
2.CNN网络中不使用FC层(全连接层)
文中提出使用Global AveragePooling取代最后的全连接层,因为全连接层参数多且易过拟合。做法即移除全连接层,在最后一层(文中使用mlpconv),后面加一层AveragePooling层。
以上两点,之所以重要,在于,其在较大程度上减少了参数个数,确能够得到一个较好的结果。而参数规模的减少,不仅有利用网络层数的加深(由于参数过多,网络规模过大,GPU显存等不够用而限制网络层数的增加,从而限制模型的泛化能力),而且在训练时间上也得到改进。)
- 这个YOLO在ImageNet classification任务上进行pretrain(以一半的图像尺寸:224x224),然后再将图像尺寸变为448x448,用于detection。YOLO一共使用了24个Convolution Layers,4个Maxpool Layers和2个Fully Connected Layers。Fast YOLO版本只有9个卷积层,filters也更少。最后输出的Tensor为7x7x30,7x7对应了49个grid cells,30对应了预测值,其中8维是回归的box坐标,2维是bounding box的confidence,20维是类别。
2.2 Training
- 预训练分类网络:YOLO在ImageNet 1000-class competition dataset上预训练一个分类网络。预训练的网络是上图中网络的前20层Convolution Layers,加上一个average-pooling layer,最后一个是Fully connected layer。(此时网络是224*224)
- 这个预训练的网络,本文训练了大约1周时间,在ImageNet2012的validating dataset上的top-5精度为88%,本文的training以及inference都是用Darknet(an open soure neural network in C and CUDA)卷积网络框架完成的。
- 两个小细节:
- 训练检测网络:转换模型去执行检测任务,Ren et al.(paper:Object Dectection Networks on Convolutional Feature Maps)指出了在预训练的model上增加convolution layer以及connected layer可以改善模型性能。因此,在预训练的基础上,增加了4个卷积层和2个全连接层,这些新加的层的参数是随机初始化的。检测要求细粒度的视觉信息,所以将图像的输入分辨率从224x224调整至448x448。
- 最后输出的为class probabilities以及bounding box coordinates。但在输出时,根据图像的width、height将bounding box的width、height进行归一化,将值归一化到0~1的区间。同样将bounding box中的坐标(x, y)通过grid cells的offset归一化到0~1之间。模型的最后一层,本文使用一个线性激活函数,其余层都使用leaky rectified linear activation(渗漏整流线性单元):
-
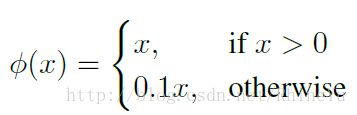
- 损失函数方面:
- 损失函数的设计目标就是往坐标(x,y,w,h), confidence, classification这三个方面达到很好的平衡。
- 本文使用的是sum-squared error(和方误差,容易优化)来作为优化目标。但是它将localization error(10维)与classification error(20维)认为同等地位去衡量优化,如果二者权值一致,会使得模型不稳定,训练发散。因为许多grid cells不包含物体,使得这些cells的confidence score为0,这些不包含物体的grid cells的梯度更新,将会以压倒性的优势,覆盖掉包含物体的grid cells进行的梯度更新。为了解决这个问题, 本文将localization error以及classification error的loss重新用权重衡量,以平衡上述的失衡问题。简单的说,就是增加bounding box coordinate的loss和减少不包含物体的grid cells的confidence的loss,设置两个参数:λcoord=5(更重视10维的位置预测)和λnoobj=0.5(减少不包含物体的confidence loss)。而对于包含物体的box的confidence loss的权值还是原来的1。
- Sum-squared error同样在不同大小的bounding box之间存在误差,它将large box和small box的loss同等对待。因为相较于large box与groundtruth的偏离,small box偏离一点,结果差别就很大,而large box偏离大一点,对结果的影响较小。 为了解决这个问题,用了一个很巧妙的trick,即最后并不是直接输出bounding box的width、height,而是w,h的平方根。如下图(平方根函数图像)所示,当bounding box的width、height越小时,发生偏移后,其反映在Y轴上的变化越大。这样就正确反映了large box与small box对于偏移的敏感性不同。
(注意:即增大small box的敏感度,减少large box的敏感度。)

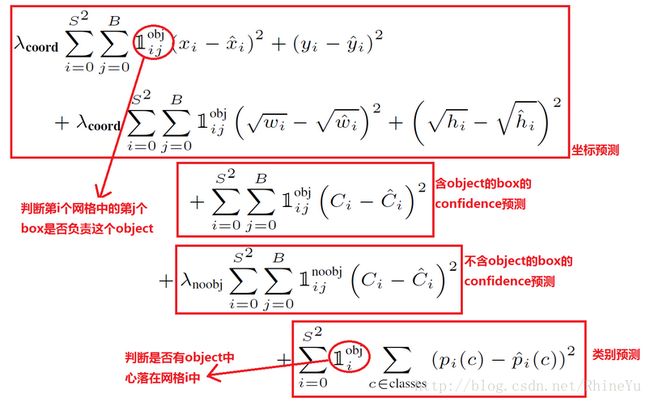
- 在YOLO中,每个grid cell 预测多个bounding boxes,但在训练中,希望每个object(grond true box)只有一个bounding box专门负责(一个object,一个bbox)。具体做法是与object(ground true box)的IoU最大的bounding box负责该object的预测。这种做法称为bounding box predictor的specialization(专职化)。随着训练的进行,每一个predictor对特定训练时,需要优化的目标函数(loss function)如下:
注意:
- 上式中loss function在只有当grid cell中存在object时,才会对classification error进行惩罚。(条件概率)
- 上式中loss function也只有在当box predictor对groundtruth box负责的时候,才会对bounding box coordinate error进行惩罚。(即predictor预测IoU最大的物体)
- 训练中,一共进行了135轮迭代,验证数据集来自PASCAL VOC 2007和2012。测试2012时也包含了2007年数据。训练中,bachthsize(批尺寸)为64,momentum(梯度下降法中一种常用的加速技术)为0.9,decay(权值衰减,防止过拟合)为0.0005。Learning rate的设置:
- 在第一轮epoch中,learning rate逐渐从10-3增加到10-2。如果训练时从一个较大的learning rate开始,通常因为不稳定的梯度,而使得模型发散。
- 之后,保持learning rate为10-2直到epoch=75
- 再接下来的30轮epoch,learning rate为10-4
(注意:冲量是梯度下降中一种常用的加速技术。对于深度网络中,参数众多,参数值初始位置随机,同样大小的学习率,对于某些参数可能合适,对另外一些参数可能偏小(学习过程缓慢),对另外一些参数可能太大(无法收敛,甚至发散),而学习率一般而言对所有参数都是固定的,所以无法同时满足所有参数的要求。通过引入Momentum可以让那些因学习率太大而来回摆动的参数,梯度能前后抵消,从而阻止发散。)
- 防止过拟合(原因:数据太少+模型太复杂):使用了dropout和data augmentation技术:
- Dropout: 在第一层全连接层后面增加了一个dropout layer,其rate=0.5,以防止层之间的co-adaptation。
(注意:经过交叉验证,隐含节点dropout率等于0.5的时候效率最好,原因是0.5时dropout随机生成的网络结构最多)
- Data augementation: 引入了随机缩放比例和翻译的原始图像大小的20%,还在HSV颜色空间中随机调整图像的曝光率和饱和度,达到1:5。
(注意:数据增强是为了获取更多数据,常见做法:通过一定规则扩充数据。如在物体分类问题里,物体在图像中的位置、姿态、尺度,整体图片敏感度等都不会影响分类结果。可以通过图像平移、翻转、缩放、切割等手段将数据成倍扩充。)
2.3 Inference
- 在训练好 YOLO 网络模型后,在 PASCAL VOC 数据集上进行 inference,每一张图像得到 98 个 bounding boxes,以及每个 bounding box 的所属类别概率。
- 当图像中的物体较大,或者处于 grid cells 边界的物体,可能在多个 cells 中被定位出来。可以用Non-Maximal Suppression(NMS,非极大值抑制) 进行去除重复检测的物体,可以使最终的 mAP 提高2−3%,相比较于 NMS 对于 DPM、R-CNN 的提高,不算大。
(注意:NMS,针对某一类别,选择概率最大的bounding box,然后计算它和其他bounding box的IoU值,如果IoU值大于0.5,说明重复率较大,该得分设为0,如果不大于0.5,则不改;这样一轮后,再选择剩下的score里面最大的那boundingbox,然后计算该bounding box和其它bounding box的IoU,重复以上过程直到最后。)
2.4 Limitations ofYOLO
- YOLO对相互靠的很近的物体(挨在一起且中点都落在一个grid cell上的情况),还有很小的群体检测效果不好,因为每个grid cell中只能预测两个box,并且只属于一类。
- 测试图像中,当同一类物体出现新的、不常见的长宽比时,YOLO的泛化能力偏弱。
- Loss functions中对于small bounding boxes,以及large bounding boxes的误差,均等对待。尽管已经用了平方根的方法优化了这个问题,但是这个问题还没有很好的解决。
- YOLO中最主要的误差仍是定位不准造成的误差。
3 效果
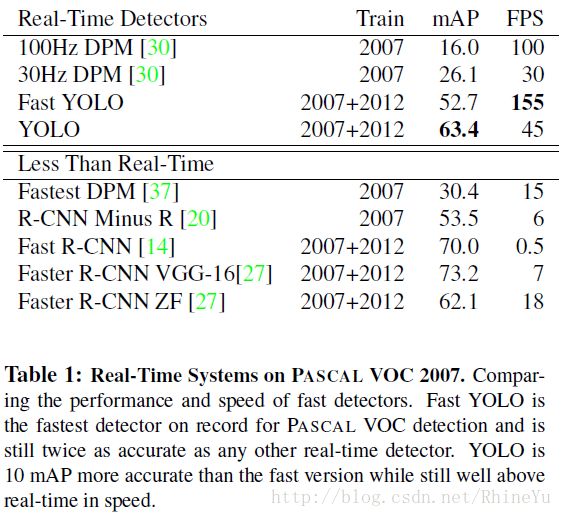
下表给出了YOLO与其他物体检测方法,在检测速度和准确性方面的比较结果(使用VOC2007数据集)
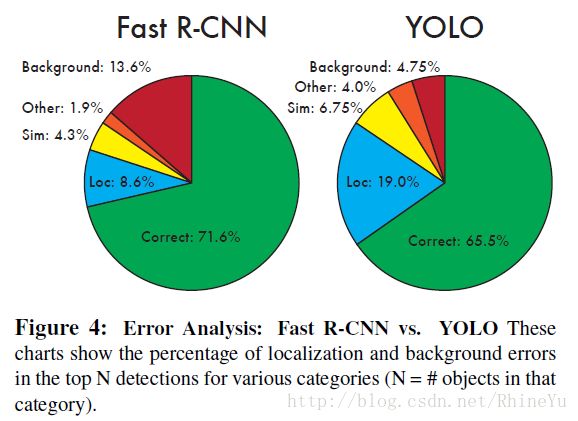
- 论文中还给出了YOLO与Fast R-CNN在各方面的识别误差比例,如下图。YOLO对背景内容的误判率(4.75%)比Fast R-CNN的误判率(13.6%)低很多。但是YOLO的定位准确率较差,占总误差比例的19%,而Fast R-CNN仅为8.6%。
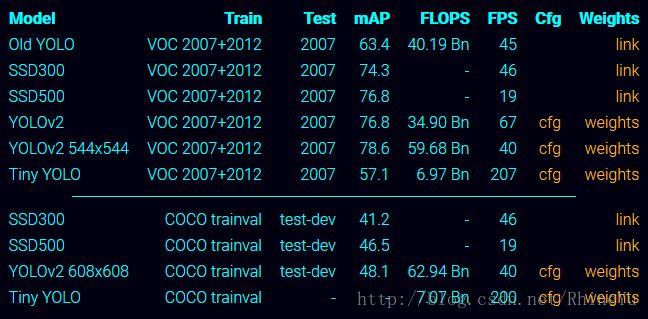
4 改进YOO v2
- 为提高物体定位精准性和召回率,作者又提出了YOLO9000(paper—YOLO9000:Better,Faster,Stronger),提高训练图像的分辨率,引入了Faster R-CNN中anchor box的思想,对各网络结构及各层的设计进行了改进,输出层使用卷积层替代YOLO的全连接层,联合使用COCO物体检测标注数据和ImageNet物体分类标注数据训练检测模型。相比YOLO,YOLO9000在识别种类、精度、速度和定位准确性等方面都有大大提升。
- SSD: Single Shot MultiBox Detector,是采用单个深度神经网络模型实现目标检测和识别的方法,该方法综合了Faster R-CNN的anchor box (候选窗口)和YOLO单个神经网络检测思路(end-to-end)。与YOLO不同的是,SSD在输出层只用卷积层,而不是全连接层。
参考资料
内容主要参考如下博客:
- 论文阅读:You Only Look Once: Unified, Real-Time Object Detection
http://blog.csdn.net/u010167269/article/details/52638771
- YOLO(You Only Look Once)算法详解
http://blog.csdn.net/u014380165/article/details/72616238
- 图解YOLO
https://zhuanlan.zhihu.com/p/24916786?refer=xiaoleimlnote
- YOLO详解
https://zhuanlan.zhihu.com/p/25236464
- 开源代码
https://pjreddie.com/darknet/yolo/