Pytorch源码分析
目录
命名空间/类/方法/函数/变量
torch.autograd.Function中的ctx参数
DDP(DistributedDataParallel)的构造函数
torch.floor(input, out=None)
nametuple
argmax
view函数
void c10::TensorImpl::refresh_contiguous
void c10::TensorImpl::refresh_numel
numel()函数
ExecutionStep
DeviceGuardImplInterface
CAFFE_ENFORCE
Concat层
im2col
torch.ones()
state_dict
DataPtr
at
autograd
torch.rand和torch.randn
torch.jit.trace
各种错误
THCudaCheck FAIL file=torch\csrc\generic\StorageSharing.cpp line=252 error=63 : OS call failed or operation not supported on this OS
Pytorch 代码构成
AdaptiveMaxPooling2d.cu文件
THC——基于CUDA的张量代数库
C10、ATen、torch
命名空间/类/方法/函数/变量
torch.autograd.Function中的ctx参数
计算的上下文环境Context,这个参数用于在前向计算和反向传播之间共享张量。
经常用到的就是在ctx中保存输入张量的值,这个上下文环境可以在反向传播中被用到,通过输入张量的值,结合后一层的输出梯度grad_output,来计算前一层的输入梯度grad_input。
DDP(DistributedDataParallel)的构造函数
每个进程都有一个模型(module)。在构造函数中,DDP首先获得该module的引用,然后将module.state_dict()从master进程广播到全体进程,使得所有进程具有相同的初始状态。state_dict的返回值是buffer等不在参数列表中但是代表了网络状态的数据,例如batch normalization中的running_mean。不同进程间梯度的汇总、求和和同步是通过一个Reducer类实现的。在构造函数中初始化了一个Reducer对象,并通过该对象管理梯度计算。在Reducer对象的构造函数中,首先将所有的参数装进若干个bucket(桶),之后一桶一桶地计算可以提高效率。参数进入桶的顺序和其在数组Model.parameters中的顺序相反,后向传播中最后一层的梯度是最先被计算完毕的,因此应该最先参加求和。然后,Reducer为每个参数注册了一个autograd_hook,在该参数被计算完毕后触发。
torch.floor(input, out=None)
说明:床函数,返回一个新张量,包含输入input张量每个元素的floor,即取不大于元素的最大整数。
参数:
- input(Tensor) -- 输入张量
- out(Tenosr, 可选) -- 输出张量
nametuple
namedtuple是一个 工厂函数,定义在python标准库的collections模块中,使用此函数可以创建一个可读性更强的元组
namedtuple函数所创建(返回)的是一个 元组的子类(python中基本数据类型都是类,且可以在buildins模块中找到)
namedtuple函数所创建元组,中文名称为具名元组
在使用普通元组的时候,我们只能通过index来访问元组中的某个数据 使用具名元组,我们既可以使用index来访问,也可以使用具名元组中每个字段的名称来访问
具名元组和普通元组所需要的内存空间相同,所以 不必使用性能来权衡是否使用具名元组
argmax
argmax(f(x))是使得函数 f(x)取得最大值所对应的变量点x(或x的集合)。
arg即argument,此处意为“自变量”。
view函数
view函数相当于numpy的reshape。
view函数只能用在contiguous的变量上。
如果在调用view函数之前用了transpose, permute之类的,需要先调用contiguous(),把变量变成在内存中连续分布的形式。
x.contiguous().view(2, -1)
不确定的数用“-1”表示。
void c10::TensorImpl::refresh_contiguous
Recompute the cached contiguity of a tensor. Call this if you modify sizes or strides.
void c10::TensorImpl::refresh_numel
Recompute the cached numel of a tensor. Call this if you modify sizes.
numel()函数
返回数组中元素的个数
ExecutionStep
用于进行迭代计算:
message ExecutionStep {
optional string name = 1;
//ExecutionStep要么可以包含一个substep的集合,要么可以包含一些要运行的network的名称,但两者不能同时被设置
repeated ExecutionStep substep = 2;
repeated string network = 3;
//当前的迭代需要运行的轮次,substeps和networks需要被顺序执行,每次执行被视为一轮迭代
optional int64 num_iter = 4;
//迭代执行结束的判断条件
optional string criteria_network = 5;
//如果这个字段被设置,那么就周期性的执行
optional int64 run_every_ms = 11;
//对于sub-steps,是顺序执行还是并行执行
optional bool concurrent_substeps = 6;
//一个用来判断当前执行是否需要终结的标志
optional string should_stop_blob = 9;
//如果为真,则当前执行仅执行一次,注意仅当should_stop_blob有效时才有效
optional bool only_once = 10;
//是否为当前执行构建一个子workspace
optional bool create_workspace = 12;
//子执行的并行度
optional int32 num_concurrent_instances = 13;
}DeviceGuardImplInterface
DeviceGuardImplInterface represents the virtual interface which provides functionality to provide an RAII class for device and stream switching, via DeviceGuard.
RAII是Resource Acquisition Is Initialization(wiki上面翻译成 “资源获取就是初始化”)的简称,是C++语言的一种管理资源、避免泄漏的惯用法。利用的就是C++构造的对象最终会被销毁的原则。RAII的做法是使用一个对象,在其构造时获取对应的资源,在对象生命期内控制对资源的访问,使之始终保持有效,最后在对象析构的时候,释放构造时获取的资源。
CAFFE_ENFORCE
判断数据合法性,如果不合法会报错
Concat层
Concat层的作用就是将两个及以上的特征图按照在channel或num维度上进行拼接,并没有eltwise层的运算操作
im2col
caffe里的卷积运算实际上是把待输入图像和卷积核都转换成矩阵,然后通过矩阵的乘法一步得出
caffe中卷积采用的是im2col和sgemm的方式
使用im2col的方法将卷积转为矩阵相乘
sgemm完成矩阵乘法
torch.ones()
torch.ones(*sizes, out=None) → Tensor返回一个全为1 的张量,形状由可变参数sizes定义。
参数:
- sizes (int...) – 整数序列,定义了输出形状
- out (Tensor, optional) – 结果张量
>>> torch.ones(2, 3)
1 1 1
1 1 1
[torch.FloatTensor of size 2x3]
>>> torch.ones(5)
1
1
1
1
1
[torch.FloatTensor of size 5]
state_dict
state_dict本质上是Python字典对象
在pytorch中,torch.nn.Module模块中的state_dict变量存放训练过程中需要学习的权重和偏执系数,state_dict作为python的字典对象将每一层的参数映射成tensor张量,需要注意的是torch.nn.Module模块中的state_dict只包含卷积层和全连接层的参数,当网络中存在batchnorm时,例如vgg网络结构,torch.nn.Module模块中的state_dict也会存放batchnorm's running_mean。
DataPtr
这个类位于最底层,用来直接维护tensor所需的内存。
at
命名空间,ATen目录下的文件使用
autograd
在PyTorch中,autograd是所有神经网络的核心内容,为Tensor所有操作提供自动求导方法。
它是一个按运行方式定义的框架,这意味着backprop是由代码的运行方式定义的。
autograd.Variable 是autograd中最核心的类。 它包装了一个Tensor,并且几乎支持所有在其上定义的操作。一旦完成了你的运算,你可以调用 .backward()来自动计算出所有的梯度。
Variable有三个属性:data,grad以及creator。
访问原始的tensor使用属性.data; 关于这一Variable的梯度则集中于 .grad; .creator反映了创建者,标识了是否由用户使用.Variable直接创建(None)。
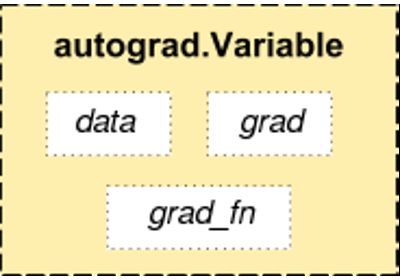
还有一个对autograd的实现非常重要的类——Function。Variable 和Function数是相互关联的,并建立一个非循环图,从而编码完整的计算过程。每个变量都有一个.grad_fn属性引用创建变量的函数(除了用户创建的变量,它们的grad_fn是None)。
torch.rand和torch.randn
y = torch.rand(5,3) #均匀分布
y=torch.randn(5,3) #标准正态分
均匀分布 torch.rand(*sizes, out=None) → Tensor 返回一个张量,包含了从区间[0, 1)的均匀分布中抽取的一组随机数。张量的形状由参数sizes定义。
标准正态分布 torch.randn(*sizes, out=None) → Tensor 返回一个张量,包含了从标准正态分布(均值为0,方差为1,即高斯白噪声)中抽取的一组随机数。张量的形状由参数sizes定义。
torch.jit.trace
使用torch.jit.trace,您可以获取现有模块或python函数,提供示例输入,然后运行该函数,记录在所有张量上执行的操作。 我们将生成的记录转换为Torch Script方法,该方法作为ScriptModule的正向方法安装。 该模块还包含原始模块所具有的任何参数。
Example:
import torch
def foo(x, y):
return 2*x + y
traced_foo = torch.jit.trace(foo, (torch.rand(3), torch.rand(3)))
注意:由于跟踪仅记录张量上的操作,因此它不会记录任何控制流操作,如if语句或循环。 当这个控制流在你的模块中保持不变时,这很好,它通常只是内联配置决策。 但有时控制流实际上是模型本身的一部分。 例如,序列到序列转换中的波束搜索是输入的(变化的)序列长度上的循环。 在这种情况下,跟踪不合适,并且应使用脚本编写波束搜索。
torch.jit.trace函数接受一个模块或函数以及一组示例输入。然后,它在跟踪遇到的计算步骤时通过函数或模块运行示例输入,并输出执行Tracing操作的基于图形的函数。Tracing非常适用于不涉及数据相关控制流的简单模块和功能,例如标准卷积神经网络。但是,如果Tracing具有依赖于数据的if语句和循环的函数,则仅记录由示例输入执行的执行路径调用的操作。换句话说,不捕获控制流本身。 为了转换包含依赖于数据的控制流的模块和函数,提供了一种 Script机制。 Script显式将模块或功能代码转换为Torch Script,包括所有可能的控制流路径。
各种错误
THCudaCheck FAIL file=torch\csrc\generic\StorageSharing.cpp line=252 error=63 : OS call failed or operation not supported on this OS
They are not supported on Windows. Something like doing multiprocessing on CUDA tensors cannot succeed, there are two alternatives for this.
1. Don’t use multiprocessing. Set the num_worker of DataLoader to zero.
2. Share CPU tensors instead. Make sure your custom DataSet returns CPU tensors.
Pytorch 代码构成
AdaptiveMaxPooling2d.cu文件
1. adaptive_max_pool2d_out_cuda / adaptive_max_pool2d_cuda
2. adaptive_max_pool2d_out_cuda_template
3. adaptivemaxpool
实现了AdaptiveMaxPooling2d的前向
1. adaptive_max_pool2d_backward_out_cuda / adaptive_max_pool2d_backward_cuda
2. adaptive_max_pool2d_backward_out_cuda_template
3. atomicadaptivemaxgradinput / adaptivemaxgradinput
实现了AdaptiveMaxPooling2d的反向
THC——基于CUDA的张量代数库

C10、ATen、torch
我们知道PyTorch的的代码主要由C10、ATen、torch三大部分组成的。其中:
1,C10,来自于Caffe Tensor Library的缩写。这里存放的都是最基础的Tensor库的代码,可以运行在服务端和移动端。PyTorch目前正在将代码从ATen/core目录下迁移到C10中。C10的代码有一些特殊性,体现在这里的代码除了服务端外还要运行在移动端,因此编译后的二进制文件大小也很关键,因此C10目前存放的都是最核心、精简的、基础的Tensor函数和接口。
C10目前最具代表性的一个class就是TensorImpl了,它实现了Tensor的最基础框架。
C10中还使用/修改了来自llvm的SmallVector,在vector元素比较少的时候用以代替std::vector,用以提升性能;
2,ATen,来自于 A TENsor library for C++11的缩写;PyTorch的C++ tensor library。ATen部分有大量的代码是来声明和定义Tensor运算相关的逻辑的,除此之外,PyTorch还使用了aten/src/ATen/gen.py来动态生成一些ATen相关的代码。ATen基于C10,Gemfield本文讨论的正是这部分;
Aten,Aten的核心源文件
TH,Torch张量计算库
THC,Torch CUDA张量计算库
THCUNN,Torch CUDA神经网络库
THNN,Torch神经网络库
3,Torch,部分代码仍然在使用以前的快要进入历史博物馆的Torch开源项目,比如具有下面这些文件名格式的文件:
TH* = TorcH
THC* = TorcH Cuda
THCS* = TorcH Cuda Sparse (now defunct)
THCUNN* = TorcH CUda Neural Network (see cunn)
THD* = TorcH Distributed
THNN* = TorcH Neural Network
THS* = TorcH Sparse (now defunct)
THP* = TorcH Python其核心模块的说明
├── autograd (梯度处理)
├── backends (后向处理,包含cuda、cudnn、mkl、mkldnn、openmp和quantized库)
├── csrc (csrc目录包含与Python集成有关的所有代码。这与lib(它包含与Python无关的Torch库)形成对比。csrc取决于lib,反之则不然。具体包含api、autograd、cuda、distributed、generic、jit、multiprocessing、onnx、tensor和utils)
├── cuda (cuda)
├── distributed (分布式处理,包括autograd)
├── distributions
├── jit (用于最优性能编译)
├── legacy (低于0.5版本才有)
├── lib (它包含与Python无关的Torch库,具体包括:c10d、libshm和libshm_windows)
├── multiprocessing (cuda多线程处理)
├── nn (与神经网络有关的操作与声明,具体包括backends、intrinsic、modules、parallel、qat、quantized和utils)
├── onnx (模型交换格式)
├── optim (优化)
├── quantization (量化)
├── utils (具体包括backcompat、bottleneck、data、ffi、hipify和tensorboard)
代码目录中的third party(1.3版本)
├── third_party(谷歌、Facebook、NVIDIA、Intel等开源的第三方库)
│ ├── benchmark(谷歌开源的benchmark库)
│ ├── cpuinfo(Facebook开源的cpuinfo,检测cpu信息)
│ ├── cub(NVIDIA开源的CUB is a flexible library of cooperative threadblock primitives and other utilities for CUDA kernel programming)
│ ├── eigen(线性代数矩阵运算库)
│ ├── fbgemm(Facebook开源的低精度高性能的矩阵运算库,目前作为caffe2 x86的量化运算符的backend)
│ ├── foxi(ONNXIFI with Facebook Extension)
│ ├── FP16(Conversion to/from half-precision floating point formats)
│ ├── FXdiv(C99/C++ header-only library for division via fixed-point multiplication by inverse)
│ ├── gemmlowp(谷歌开源的矩阵乘法运算库Low-precision matrix multiplication,https://github.com/google/gemmlowp)
│ ├── gloo(Facebook开源的跨机器训练的通信库Collective communications library with various primitives for multi-machine training)
│ ├── googletest(谷歌开源的UT框架)
│ ├── ideep(Intel开源的使用MKL-DNN做的神经网络加速库)
│ ├── ios-cmake(用于ios的cmake工具链文件)
│ ├── miniz-2.0.8(数据压缩库,Miniz is a lossless, high performance data compression library in a single source file)
│ ├── nccl(NVIDIA开源的多GPU通信的优化原语,Optimized primitives for collective multi-GPU communication)
│ ├── neon2sse(与ARM有关,intende to simplify ARM->IA32 porting)
│ ├── NNPACK(多核心CPU加速包用于神经网络,Acceleration package for neural networks on multi-core CPUs)
│ ├── onnx(Open Neural Network Exchange,Facebook开源的神经网络模型交换格式,目前Pytorch、caffe2、ncnn、coreml等都可以对接)
│ ├── onnx-tensorrt(ONNX-TensorRT: TensorRT backend for ONNX)
│ ├── protobuf(谷歌开源的protobuf)
│ ├── psimd(便携式128位SIMD内部函数,Portable 128-bit SIMD intrinsics)
│ ├── pthreadpool(用于C/C++的多线程池,pthread-based thread pool for C/C++)
│ ├── pybind11(C ++ 11和Python之间的无缝可操作性支撑库,Seamless operability between C++11 and Python)
│ ├── python-enum(Python标准枚举模块,Mirror of enum34 package (PeachPy dependency) from PyPI to be used in submodules)
│ ├── python-peachpy(用于编写高性能汇编内核的Python框架,PeachPy is a Python framework for writing high-performance assembly kernels)
│ ├── python-six(Python 2 and 3兼容性库)
│ ├── QNNPACK(Facebook开源的面向移动平台的神经网络量化加速库)
│ ├── README.md
│ ├── sleef(SIMD Library for Evaluating Elementary Functions,SIMD库,用于评估基本函数)
│ ├── tbb(Intel开源的官方线程构建Blocks,Official Threading Building Blocks (TBB))
│ └── zstd((Facebook开源的Zstandard,快速实时压缩算法库)