重写equals时,为什么还要重写hashcode?
重写equals,为什么还要重写hashcode,大部分的复习资料都会这么写:
“如果两个对象相等,则 hashcode 一定也是相同的。两个对象相等,对两个对象分别调用 equals 方法都返回 true。但是,两个对象有相同的 hashcode 值,它们也不一定是相等的 。因此,equals 方法被覆盖过,则 hashCode 方法也必须被覆盖。”
加粗部分原话是对的,但是和本问题毫无关系。他只是把hashmap中哈希冲突的理论进行了简单的套用,就想当然的认为据此就可以得出,重写equals就必须重写hashcode,实则是大错特错。真正的原因其实是这样的:
1.euqals和==的区别。
这个相信大家稍微深入复习,都会很清晰。即equals 和 == 都是Object的方法。如果不对equals进行重写,那么他们就是功能是相同的,即比较两个对象的地址值是否相同。String中,之所以调用equals来比较两个字符串的值是否相同,是因为它重写了equals方法。
2.什么时候重写equlas,就要重写hashcode方法?
类里要用到hashmap、hashSet等散列表(来达到去重效果)的时候。如果在我们的类中,不需要用到散列表,那么只需要重写equals即可。因为重写equals方法,仅仅是为了满足我们特定的需求(一般是比较属性值是否相同)。而不重写hashcode,并不会影响我们实现这类需求。
3.为什么使用散列表时重写equals,还有重写hashcode?
因为hashcode默认使用地址进行散列的。此时equals比较是相同的,但是hashmap内部却仍然认为这是两个对象,导致运行结果和我们期望的不符。
举例说明:
现在定义一个Student类和一个测试类。Student包括姓名和年龄。
public class Student {
String Name;
int age;
public Student(String Name,int age){
this.Name = Name;
this.age = age;
}
public class Test {
public static void main(String[] args) {
Student s1 = new Student("小方",12);
Student s2 = new Student("小方",12);
System.out.println(s1.equals(s2));
}
}

此时,程序返回false。
当我们重写equals后
public class Student {
String Name;
int age;
public Student(String Name,int age){
this.Name = Name;
this.age = age;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Student student = (Student) o;
return age == student.age &&
Objects.equals(Name, student.Name);
}
}
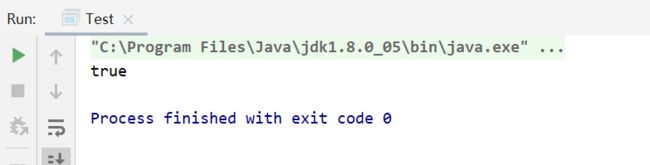
此时,我们想要的效果已经达到了。但是如果加入一个使用hashset来去重呢?
public class Test {
public static void main(String[] args) {
Set<Student> set = new HashSet<>();
Student s1 = new Student("小方",12);
Student s2 = new Student("小方",12);
set.add(s1);
set.add(s2);
System.out.println(set.size());
for(Student s:set){
System.out.println(s);
}
System.out.println(s1.equals(s2));
}
}

遍历hashset的值,我们居然发现,hashset的size竟然是2,两个被我们定义为equals的对象,竟然全都被写进去了。
现在,在Student类中重写hashcode。
public class Student {
String Name;
int age;
public Student(String Name,int age){
this.Name = Name;
this.age = age;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Student student = (Student) o;
return age == student.age &&
Objects.equals(Name, student.Name);
}
@Override
public int hashCode() {
return Objects.hash(Name, age);
}
@Override
public String toString() {
return "Student{" +
"Name='" + Name + '\'' +
", age=" + age +
'}';
}
}
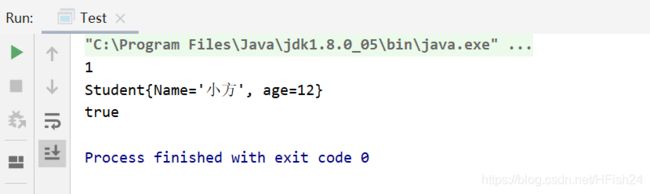
可以看到,此时,hashset中只有1个对象了,也就是说另一个被去重了。这是为什么呢?
答案是从hashmap的源码中找。因为hashset的底层就是用hashmap来是实现的。先看hashset的add方法
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
可以看到,是把这个值存到了map里,其中,PRESENT==new Object();再看map的put方法,调用了putval。
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
源码内容众多,但是我们只需要关注第13行那里。即当要put一个值的时候,要比较他的hash值和equals值。只有这两个都相同时,才认为这是两个相同的值。在本例中,如果不重写hashcode,此处的hash值就是对象的地址值,这当然是不同的。
总结: 重写equals,还要重写hashcode,是因为如果不重写hashcode,两个对象的hashcode值可能还是不同的,此时不满足hashmap中判断为同一个对象的条件,而会被认为是两个对象。重写hashcode,要对我们比较的属性都进行hash,从而保证了他们的hashcode也是一样的。