EM算法在GMM中的应用与python实现
文章目录
- 一、混合高斯分布
-
- 1-1 GMM概要
- 1-2 由边缘概率引出的隐变量
- 1-3 隐变量后验概率
- 1-4 完整数据集合以及不完整数据集合
- 1-5 最大似然估计
- 二、推导
-
- 2-1 EM在GMM中的应用
-
- 2-1-1 μ \mu μ最优解
- 2-1-2 Σ \Sigma Σ最优解
- 2-1-3 π \pi π最优解
- 2-2 通过EM算法对混合高斯模型进行参数估计
- 三、python代码实现
一、混合高斯分布
1-1 GMM概要
在k-means中,每个数据样本属于某一个cluster,比如对于第1个数据,可以通过 r 1 = ( 0 , 1 , 0 ) r_1=(0,1,0) r1=(0,1,0)中的指示变量0,1来明确指出该数据属于哪个cluster。关于k-means可以参考我的另一篇博客。
在混合高斯分布(Gaussian Mixture Mode:GMM)中,每个数据样本也是属于某一个cluster,但它的指示变量不再是2元的01,而是用概率来表示,或者说用隐变量来表示。举个例子,数据 x 1 x_1 x1对应的隐变量为 z 1 z_1 z1,他的期望值可以表示为 E [ z 1 ] = ( 0.7 , 0.2 , 0.1 ) E[z_1]=(0.7, 0.2, 0.1) E[z1]=(0.7,0.2,0.1),即 0 < = z 1 k < = 1 0<=z_{1k}<=1 0<=z1k<=1。
下面的推导中会用到以下数学符号:
- x x x: D D D 维度的随机变量
- z z z: k k k维度的随机变量,也是模型的隐变量
- X = { x 1 , x 2 , . . . , x N } X = \{x_1, x_2, ..., x_N\} X={x1,x2,...,xN}: N N N个数据观测数据
- K K K: cluster(聚类)的个数,已知
首先是GMM的概率密度函数:
p ( x ∣ π , μ , Σ ) = ∑ k = 1 K π k N ( x ∣ μ k , Σ k ) p(x|\pi,\mu,\Sigma) = \sum_{k=1}^K\pi_kN(x|\mu_k, \Sigma_k) p(x∣π,μ,Σ)=k=1∑KπkN(x∣μk,Σk)
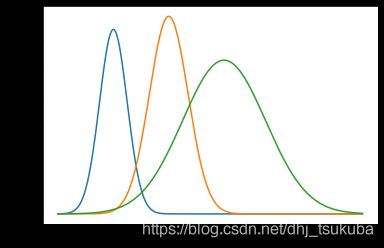
可以明显看到,这是 K K K个高斯分布按比例加权求和的结果。下面用以3个1维高斯分布为例来说明:
import numpy as np
import matplotlib.pyplot as plt
K = 3
n = 301
mu = [-2, 0 ,2]
sigma = [0.5, 0.7, 1.5]
pi = [0.2, 0.3, 0.5]
intervals = np.linspace(-4, 7, n)
pdfs = np.zeros(shape = [n, K])
mix_pdf = np.zeros(shape = [n])
for k in range(K):
pdfs[:, k] = pi[k] * 1/(np.math.sqrt(2*np.math.pi)*sigma[k]) * np.exp(-(intervals-mu[k])**2 / (2*sigma[k]**2))
mix_pdf += pdfs[:, k]
plt.figure()
for k in range(K):
plt.plot(np.linspace(-4,7,n), pdfs[:, k])
plt.show()
plt.figure()
plt.plot(intervals, mix_pdf, c = "r")
plt.show()
下图表示3个1维单高斯分布的概率密度函数(还没有混合),其每个高斯分量的分配比例为 π = ( 0.2 , 0.3 , 0.5 ) \pi=(0.2, 0.3, 0.5) π=(0.2,0.3,0.5), 该比例同时也是每个高斯分量的积分结果,也就是其包围的面积。
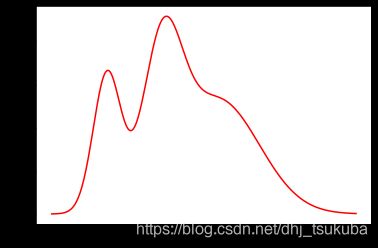
混合之后得到的混合高斯分布概率密度函数如下图所示,积分结果为1。
1-2 由边缘概率引出的隐变量
如果用 p ( x ) p(x) p(x)表示某一数据的分布,我们可以通过边缘概率的计算和乘法公式导出该 p ( x ) p(x) p(x)
p ( x ) = ∑ z p ( x , z ) d z = ∑ z p ( x ∣ z ) p ( z ) d z . . . ( 1 ) p(x) = \sum^{}_{z}p(x,z)dz=\sum_{z}p(x|z)p(z)dz \space\space\space...(1) p(x)=z∑p(x,z)dz=z∑p(x∣z)p(z)dz ...(1)
下面我们重点讨论一下这里的 p ( z ) p(z) p(z)和 p ( x ∣ z ) p(x|z) p(x∣z).
首先我们引入变量 z k z_k zk,这里的 z k z_k zk可以参考k-means中的 r n k r_{nk} rnk,如果第 n n n个数据样本属于 k k k类,则 r n k = 1 r_{nk}=1 rnk=1,而这里的 z k z_k zk用随机变量 { 0 , 1 } \{0,1\} {0,1}表示, z k ∈ { 0 , 1 } z_k\in\{0,1\} zk∈{0,1} 并且 ∑ k z k = 1 \sum_kz_k=1 ∑kzk=1
我们考虑隐变量集合 z = { z 1 , z 2 , . . . z k , . . . , z K } z=\{z_1,z_2, ... z_k,...,z_K\} z={z1,z2,...zk,...,zK}中的 z k z_k zk, z k z_k zk为1 的概率由混合系数 π k \pi_k πk来决定:
p ( z k = 1 ) = π k p(z_k=1)=\pi_k p(zk=1)=πk
很明显, π k \pi_k πk满足 0 ≤ π k ≤ 1 0\leq\pi_k\leq1 0≤πk≤1以及 ∑ k = 1 K π k = 1 \sum_{k=1}^{K}\pi_k=1 ∑k=1Kπk=1, 那么 p ( z ) p(z) p(z)就可以表示为:
p ( z ) = ∏ k = 1 K π k z k p(z)=\prod_{k=1}^{K}\pi_k^{z_k} p(z)=k=1∏Kπkzk
同时,在给定 z z z的条件下我们可以求得数据 x x x的条件概率分布,具体来讲,就是在给定条件 z k = 1 z_k=1 zk=1的条件下, x x x服从第 k k k个(高维或者1维)高斯分布:
p ( x ∣ z k = 1 ) = N ( x ∣ μ k , Σ k ) p(x|z_k=1)=N(x|\mu_k,\Sigma_k) p(x∣zk=1)=N(x∣μk,Σk)
结合上面的 p ( z ) = ∏ k = 1 K π k z k p(z)=\prod_{k=1}^{K}\pi_k^{z_k} p(z)=∏k=1Kπkzk,我们可以得到:
p ( x ∣ z ) = ∏ k = 1 K N ( x ∣ μ k , Σ k ) z k p(x|z)=\prod_{k=1}^{K}N(x|\mu_k, \Sigma_k)^{z_k} p(x∣z)=k=1∏KN(x∣μk,Σk)zk
将这里的 p ( z ) p(z) p(z), p ( x ∣ z ) p(x|z) p(x∣z)带入到(1)中,我们可以得到:
p ( x ) = ∑ z p ( x ∣ z ) p ( z ) d z = ∑ k = 1 K π k N ( x ∣ μ k , Σ k ) p(x)=\sum_zp(x|z)p(z)dz=\sum_{k=1}^{K}\pi_kN(x|\mu_k, \Sigma_k) p(x)=z∑p(x∣z)p(z)dz=k=1∑KπkN(x∣μk,Σk)
可以发现这个式子和混合高斯分布是一样的。
1-3 隐变量后验概率
我们可以通过 p ( z ) p(z) p(z)和 p ( x ∣ z ) p(x|z) p(x∣z),结合贝叶斯公式算出 z z z的后验概率 p ( z ∣ x ) p(z|x) p(z∣x),即可以通过观测数据 x x x得到 z z z的分布:
p ( z k = 1 ∣ x ) = p ( x , z k = 1 ) p ( x ) = p ( z k = 1 ) p ( x ∣ z k = 1 ) ∑ j = 1 K p ( z j = 1 ) p ( x ∣ z j = 1 ) = π k N ( x ∣ μ k , Σ k ) ∑ j = 1 K π j N ( x ∣ μ j , Σ j ) p(z_k=1|x)=\frac{p(x, z_k=1)}{p(x)}=\frac{p(z_k=1)p(x|z_k=1)}{\sum_{j=1}^{K}p(z_j=1)p(x|z_j=1)}\\ =\frac{\pi_kN(x|\mu_k, \Sigma_k)}{\sum_{j=1}^K\pi_jN(x|\mu_j,\Sigma_j)} p(zk=1∣x)=p(x)p(x,zk=1)=∑j=1Kp(zj=1)p(x∣zj=1)p(zk=1)p(x∣zk=1)=∑j=1KπjN(x∣μj,Σj)πkN(x∣μk,Σk)
这里的 p ( x ∣ z k = 1 ) p(x|z_k=1) p(x∣zk=1)是似然, p ( z k = 1 ) p(z_k=1) p(zk=1)是先验概率, 分母是边缘概率。
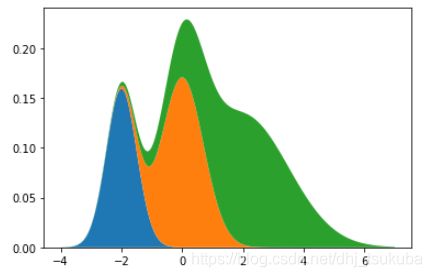
我们可以将这个后验概率理解为,在已知的某个数据点上,混合高斯分布概率密度函数中各个 k k k类分布所占的比例,用 γ ( z k ) \gamma(z_k) γ(zk)来表示,通过下图更容易理解:
1-4 完整数据集合以及不完整数据集合
这里的不完整数据集表示只有数据,但不知道哪一部分数据属于哪个分布,因此联合概率分布 p ( x , z ) p(x,z) p(x,z)无法计算,如下图所示:

相对的,完整数据集表示各个分布的参数都是已知的并且知道哪一部分数据属于哪个分布,可以计算出 p ( x , z ) p(x,z) p(x,z),如下图所示:

EM算法就是用来推测 z z z的分布参数的,从不完整数据集得到完整数据集。
1-5 最大似然估计
z z z的分布参数由 θ \theta θ表示,服从 p ( x ∣ θ ) p(x|\theta) p(x∣θ)生成的 N N N个数据用 D = { x 1 , x 2 , . . . , x N } D=\{x_1, x_2, ..., x_N\} D={x1,x2,...,xN}来表示,找到生成这组数据的最优参数 θ \theta θ的方法就是最大似然估计。将 θ \theta θ作为变量的概率称为似然, p ( x ∣ θ ) p(x|\theta) p(x∣θ)被称为似然函数,找到使似然最大的参数 θ \theta θ称为最大似然估计。
二、推导
2-1 EM在GMM中的应用
首先列出公式中用到的符号:
x x x: d d d维数据
D = { x 1 , x 2 , x 3 , . . . , x N } D=\{x_1, x_2, x_3,...,x_N\} D={x1,x2,x3,...,xN}: N N N个观测数据
X = [ x 1 T x 2 T . . . x N T ] X=\begin{bmatrix}x_1^T\\x_2^T\\...\\x_N^T\end{bmatrix} X=⎣⎢⎢⎡x1Tx2T...xNT⎦⎥⎥⎤: N N N个观测数据组成的矩阵( N × D N\times D N×D)
K K K: 聚类数
z z z: 隐变量,表示某个观测数据是否属于 k k k类, K K K维
Z = [ z 1 T z 2 T . . . z N T ] Z = \begin{bmatrix}z_1^T\\z_2^T\\...\\z_N^T\end{bmatrix} Z=⎣⎢⎢⎡z1Tz2T...zNT⎦⎥⎥⎤: N N N个隐变量的矩阵( N × K N\times K N×K)
观测N个数据时,混合高斯分布的对数似然函数:
l n p ( x ∣ π , μ , Σ ) = l n ∏ n = 1 N { ∑ k = 1 K π k N ( x n ∣ μ k , Σ k ) } = ∑ n = 1 N l n { ∑ k = 1 K π k N ( x n ∣ μ k , Σ k ) } lnp(x|\pi, \mu, \Sigma)=ln\prod_{n=1}^{N} \{\sum_{k=1}^{K} \pi_kN(x_n|\mu_k, \Sigma_k)\} \\\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space=\sum_{n=1}^{N} ln\{\sum_{k=1}^{K} \pi_kN(x_n|\mu_k, \Sigma_k)\} lnp(x∣π,μ,Σ)=lnn=1∏N{k=1∑KπkN(xn∣μk,Σk)} =n=1∑Nln{k=1∑KπkN(xn∣μk,Σk)}
该对数似然函数就是我们需要优化的对象,这里的 l n ln ln 对数部分很难求解析解,因此我们需要用以迭代法为基础的EM算法来求解。
下面给出EM算法的整体思路:
- 初始化: 对需要优化的对象参数 π \pi π, μ \mu μ, Σ \Sigma Σ进行初始化赋值,然后计算出对数似然函数的结果
- E-step:计算后验概率 γ ( z n k ) \gamma(z_{nk}) γ(znk)
- M-step:将对数似然函数关于 π \pi π, μ \mu μ, Σ \Sigma Σ偏微分置为0,求参数最优解
- 收敛判断:再次计算对数似然函数,设定一个阈值,如果与前一次的差值小于该阈值则判断为收敛,停止迭代更新,否则从M-step开始循环
2-1-1 μ \mu μ最优解
首先我们对 l n N ( x ∣ μ , Σ ) ln N(x|\mu,\Sigma) lnN(x∣μ,Σ)关于 μ \mu μ求偏微分,这里会用到矩阵求微分的公式,同时我们假设协方差矩阵 Σ \Sigma Σ为对角阵,即数据之间相互独立
∂ ∂ x x T A x = ( A + A T ) x \frac{\partial{}}{\partial{x}}x^TAx=(A+A^T)x ∂x∂xTAx=(A+AT)x
下面开始求偏微分:
∂ ∂ μ l n N ( x ∣ μ , Σ ) = ∂ ∂ μ l n 1 ( 2 π ) d 2 Σ 1 2 e x p [ − 1 2 ( x − μ ) T Σ − 1 ( x − μ ) ] = ∂ ∂ μ [ − d 2 l n ( 2 π ) − 1 2 l n ∣ Σ ∣ − 1 2 ( x − μ ) T Σ − 1 ( x − μ ) ] = ∂ ∂ μ [ − 1 2 ( x − μ ) T Σ − 1 ( x − μ ) ] = ( − 1 ) ( − 1 2 ) ( Σ − 1 + ( Σ − 1 ) T ) ( x − μ ) = Σ − 1 ( x − μ ) \begin{aligned} &\frac{\partial{}}{\partial{\mu}}ln N(x|\mu,\Sigma)\\ =&\frac{\partial{}}{\partial{\mu}}ln \frac{1}{(2\pi)^{\frac{d}{2}}\Sigma^{\frac{1}{2}}}exp[-\frac{1}{2}(x-\mu)^T\Sigma^{-1}(x-\mu)]\\ =&\frac{\partial{}}{\partial{\mu}}[-\frac{d}{2}ln(2\pi)-\frac{1}{2}ln|\Sigma|-\frac{1}{2}(x-\mu)^T\Sigma^{-1}(x-\mu)]\\ =&\frac{\partial{}}{\partial{\mu}}[-\frac{1}{2}(x-\mu)^T\Sigma^{-1}(x-\mu)]\\ =&(-1)(-\frac{1}{2})(\Sigma^{-1}+(\Sigma^{-1})^T)(x-\mu)\\ =&\Sigma^{-1}(x-\mu) \end{aligned} =====∂μ∂lnN(x∣μ,Σ)∂μ∂ln(2π)2dΣ211exp[−21(x−μ)TΣ−1(x−μ)]∂μ∂[−2dln(2π)−21ln∣Σ∣−21(x−μ)TΣ−1(x−μ)]∂μ∂[−21(x−μ)TΣ−1(x−μ)](−1)(−21)(Σ−1+(Σ−1)T)(x−μ)Σ−1(x−μ)
μ \mu μ的最大化,下面的 N n k = N ( x n ∣ μ k , Σ k ) N_{nk}=N(x_n|\mu_k, \Sigma_k) Nnk=N(xn∣μk,Σk),对数似然函数 L = l n p ( X ∣ π , μ , Σ ) L=lnp(X|\pi, \mu, \Sigma) L=lnp(X∣π,μ,Σ)
这里涉及到对数函数求微分: ( l n f ) ′ = f ′ f (lnf)^{'}=\frac{f^{'}}{f} (lnf)′=ff′
∂ ∂ μ N = N ( ∂ ∂ μ l n N ) = N Σ − 1 ( x − μ ) \frac{\partial}{\partial{\mu}}N=N(\frac{\partial}{\partial{\mu}}lnN)=N\Sigma^{-1}(x-\mu) ∂μ∂N=N(∂μ∂lnN)=NΣ−1(x−μ)
∂ ∂ μ k L = ∂ ∂ μ k ∑ n = 1 N l n { ∑ j = 1 K π j N ( x n ∣ μ j , Σ j ) } = ∑ n = 1 N π k ∂ ∂ μ k N n k ∑ j = 1 K π j N n j = ∑ n − 1 N π k N n k Σ k − 1 ( x n − μ k ) ∑ j = 1 K π j N n j = ∑ n = 1 N π k N n k ∑ j = 1 K π j N n j Σ k − 1 ( x n − μ k ) = Σ k − 1 ∑ n = 1 N γ ( z n k ) ( x n − μ k ) \begin{aligned} &\frac{\partial}{\partial{\mu_k}}L\\ =&\frac{\partial}{\partial{\mu_k}}\sum_{n=1}^Nln\{\sum_{j=1}^K\pi_jN(x_n|\mu_j, \Sigma_j)\}\\ =&\sum_{n=1}^N\frac{\pi_k\frac{\partial}{\partial{\mu_k}}N_{nk}}{\sum_{j=1}^K\pi_jN_{nj}}=\sum_{n-1}^N\frac{\pi_kN_{nk}\Sigma_k^{-1}(x_n-\mu_k)}{\sum_{j=1}^K\pi_jN_{nj}}\\ =&\sum_{n=1}^N\frac{\pi_kN_{nk}}{\sum_{j=1}^K\pi_jN_{nj}}\Sigma^{-1}_k(x_n-\mu_k)\\ =&\Sigma_k^{-1}\sum_{n=1}^N\gamma(z_{nk})(x_n-\mu_k) \end{aligned} ====∂μk∂L∂μk∂n=1∑Nln{j=1∑KπjN(xn∣μj,Σj)}n=1∑N∑j=1KπjNnjπk∂μk∂Nnk=n−1∑N∑j=1KπjNnjπkNnkΣk−1(xn−μk)n=1∑N∑j=1KπjNnjπkNnkΣk−1(xn−μk)Σk−1n=1∑Nγ(znk)(xn−μk)
下面将该微分置为0求 μ k \mu_k μk的最大值:
∑ n = 1 N γ ( z n k ) ( x n − μ k ) = 0 ∑ n = 1 N γ ( z n k ) x n − μ k ∑ n = 1 N γ ( z n k ) = 0 μ k = ∑ n = 1 N γ ( z n k ) x n ∑ n = 1 N γ ( z n k ) = 1 N k ∑ n = 1 N γ ( z n k ) x n \sum_{n=1}^N\gamma(z_{nk})(x_n-\mu_k)=0\\ \sum_{n=1}^N\gamma(z_{nk})x_n-\mu_k\sum_{n=1}^N\gamma(z_{nk})=0\\ \mu_k=\frac{\sum_{n=1}^N\gamma(z_{nk})x_n}{\sum_{n=1}^N\gamma(z_{nk})}=\frac{1}{N_k}\sum_{n=1}^N\gamma(z_{nk})x_n n=1∑Nγ(znk)(xn−μk)=0n=1∑Nγ(znk)xn−μkn=1∑Nγ(znk)=0μk=∑n=1Nγ(znk)∑n=1Nγ(znk)xn=Nk1n=1∑Nγ(znk)xn
2-1-2 Σ \Sigma Σ最优解
和求 μ k \mu_k μk一样,这里先求 l n N ( x ∣ μ , Σ ) lnN(x|\mu,\Sigma) lnN(x∣μ,Σ)对 Σ \Sigma Σ的微分,推导中利用了矩阵论中二次型和trace的关系:
x T A x = t r ( A x x T ) x^TAx=tr(Axx^T) xTAx=tr(AxxT),矩阵对数的微分(对称矩阵): ∂ ∂ A l n ∣ A ∣ = ( A − 1 ) T = A − 1 \frac{\partial{}}{\partial{A}}ln|A|=(A^{-1})^T=A^{-1} ∂A∂ln∣A∣=(A−1)T=A−1,trace求微分:
∂ ∂ A t r ( A − 1 B ) = − ( A − 1 B A − 1 ) T \frac{\partial{}}{\partial{A}}tr(A^{-1}B)=-(A^{-1}BA^{-1})^{T} ∂A∂tr(A−1B)=−(A−1BA−1)T
l n N = − D 2 l n ( 2 π ) − 1 2 l n ∣ Σ ∣ − 1 2 ( x − μ ) T Σ − 1 ( x − μ ) = − D 2 l n ( 2 π ) − 1 2 l n ∣ Σ ∣ − 1 2 t r ( Σ − 1 ( x − μ ) ( x − μ ) T ) \begin{aligned} lnN&=-\frac{D}{2}ln(2\pi)-\frac{1}{2}ln|\Sigma|-\frac{1}{2}(x-\mu)^T\Sigma^{-1}(x-\mu)\\ &=-\frac{D}{2}ln(2\pi)-\frac{1}{2}ln|\Sigma|-\frac{1}{2}tr(\Sigma^{-1}(x-\mu)(x-\mu)^T) \end{aligned} lnN=−2Dln(2π)−21ln∣Σ∣−21(x−μ)TΣ−1(x−μ)=−2Dln(2π)−21ln∣Σ∣−21tr(Σ−1(x−μ)(x−μ)T)
∂ ∂ Σ ( l n N ) = − 1 2 Σ k − 1 + 1 2 ( Σ k − 1 ( x n − μ k ) ( x n − μ k ) T Σ k − 1 ) \frac{\partial{}}{\partial{\Sigma}}(lnN)=-\frac{1}{2}\Sigma^{-1}_k+\frac{1}{2}(\Sigma_k^{-1}(x_n-\mu_k)(x_n-\mu_k)^T\Sigma^{-1}_k) ∂Σ∂(lnN)=−21Σk−1+21(Σk−1(xn−μk)(xn−μk)TΣk−1)
下面对对数似然函数求关于 Σ k \Sigma_k Σk的微分:
∂ ∂ Σ k L = ∂ ∂ Σ k ∑ n = 1 N l n { ∑ j = 1 K π j N ( x n ∣ μ j , Σ j ) } = ∑ n = 1 N π k ∂ ∂ Σ k N n k ∑ j = 1 K π j N n j = ∑ n − 1 N π k N n k ∂ ∂ Σ k l n N n k ∑ j = 1 K π j N n j = ∑ n − 1 N π k N n k ∑ j = 1 N π j N n j { − 1 2 Σ k − 1 + 1 2 ( Σ k − 1 ( x n − μ k ) ( x n − μ k ) T Σ k − 1 ) } \begin{aligned} &\frac{\partial}{\partial{\Sigma_k}}L\\ =&\frac{\partial}{\partial{\Sigma_k}}\sum_{n=1}^Nln\{\sum_{j=1}^K\pi_jN(x_n|\mu_j, \Sigma_j)\}\\ =&\sum_{n=1}^N\frac{\pi_k\frac{\partial}{\partial{\Sigma_k}}N_{nk}}{\sum_{j=1}^K\pi_jN_{nj}}=\sum_{n-1}^N\frac{\pi_kN_{nk}\frac{\partial{}}{\partial{\Sigma_k}}lnN_{nk}}{\sum_{j=1}^K\pi_jN_{nj}}\\ =&\sum_{n-1}^N\frac{\pi_kN_{nk}}{\sum_{j=1}^N\pi_jN_{nj}}\{-\frac{1}{2}\Sigma^{-1}_k+\frac{1}{2}(\Sigma_k^{-1}(x_n-\mu_k)(x_n-\mu_k)^T\Sigma^{-1}_k)\} \end{aligned} ===∂Σk∂L∂Σk∂n=1∑Nln{j=1∑KπjN(xn∣μj,Σj)}n=1∑N∑j=1KπjNnjπk∂Σk∂Nnk=n−1∑N∑j=1KπjNnjπkNnk∂Σk∂lnNnkn−1∑N∑j=1NπjNnjπkNnk{−21Σk−1+21(Σk−1(xn−μk)(xn−μk)TΣk−1)}
将该微分置0,提出 Σ k − 1 \Sigma_k^{-1} Σk−1:
( Σ k − 1 ) ∑ n = 1 N γ ( z n k ) { I − ( x n − μ k ) ( x n − μ k ) T Σ k − 1 } = ∑ n = 1 N γ ( z n k ) = ∑ n = 1 N γ ( z n k ) ( x n − μ k ) ( x n − μ k ) T Σ k − 1 Σ k = 1 N k ∑ n = 1 N γ ( z n k ) ( x n − μ k ) ( x n − μ k ) T (\Sigma_k^{-1})\sum_{n=1}^N\gamma(z_{nk})\{I-(x_n-\mu_k)(x_n-\mu_k)^T\Sigma_k^{-1}\}=\\ \sum_{n=1}^N\gamma(z_{nk})=\sum_{n=1}^{N}\gamma(z_{nk})(x_n-\mu_k)(x_n-\mu_k)^T\Sigma_k^{-1}\\ \Sigma_k=\frac{1}{N_k}\sum_{n=1}^{N}\gamma(z_{nk})(x_n-\mu_k)(x_n-\mu_k)^T (Σk−1)n=1∑Nγ(znk){I−(xn−μk)(xn−μk)TΣk−1}=n=1∑Nγ(znk)=n=1∑Nγ(znk)(xn−μk)(xn−μk)TΣk−1Σk=Nk1n=1∑Nγ(znk)(xn−μk)(xn−μk)T
2-1-3 π \pi π最优解
和前面的2个参数不同,对于 π \pi π有这样一个限制: ∑ k = 1 K π k = 1 \sum_{k=1}^K\pi_k=1 ∑k=1Kπk=1,求限制条件下的最优解需要用到拉格朗日乘数法,朗格朗日乘子用 λ \lambda λ表示,需要求最优解的函数用下式表示:
G = L + λ ( ∑ k = 1 K π k − 1 ) G=L+\lambda(\sum_{k=1}^K\pi_k-1) G=L+λ(k=1∑Kπk−1)
这里的 L L L代表对数似然函数
∂ ∂ π k G = ∂ ∂ π k ∑ n = 1 N l n { ∑ j = 1 K π j N ( x n ∣ μ j , Σ j ) } + ∂ ∂ π k λ ( ∑ k = 1 K π k − 1 ) = ∑ n = 1 N N n k ∑ j = 1 K π j N n j + λ = ∑ n = 1 N π k π k N n k ∑ j = 1 K π j N n j + λ = 1 π k γ ( z n k ) + λ = N k π k + λ = 0 N k = − λ π k N = ∑ k = 1 K N k = − λ ∑ k = 1 K π k = − λ π k = N k − λ = N k N \begin{aligned} \frac{\partial{}}{\partial{\pi_k}}G=&\frac{\partial{}}{\partial{\pi_k}}\sum_{n=1}^Nln\{\sum_{j=1}^K\pi_jN(x_n|\mu_j, \Sigma_j)\}+\frac{\partial{}}{\partial{\pi_k}}\lambda(\sum_{k=1}^K\pi_k-1)\\ =&\sum_{n=1}^N\frac{N_{nk}}{\sum_{j=1}^K\pi_jN_{nj}}+\lambda=\sum_{n=1}^N\frac{\pi_k}{\pi_k}\frac{N_{nk}}{\sum_{j=1}^K\pi_jN_{nj}}+\lambda\\ =&\frac{1}{\pi_k}\gamma(z_{nk})+\lambda=\frac{N_k}{\pi_k}+\lambda=0\\ N_k=&-\lambda\pi_k\\ N=&\sum_{k=1}^KN_k=-\lambda\sum_{k=1}^K\pi_k=-\lambda\\ \pi_k=&\frac{N_k}{-\lambda}=\frac{N_k}{N} \end{aligned} ∂πk∂G===Nk=N=πk=∂πk∂n=1∑Nln{j=1∑KπjN(xn∣μj,Σj)}+∂πk∂λ(k=1∑Kπk−1)n=1∑N∑j=1KπjNnjNnk+λ=n=1∑Nπkπk∑j=1KπjNnjNnk+λπk1γ(znk)+λ=πkNk+λ=0−λπkk=1∑KNk=−λk=1∑Kπk=−λ−λNk=NNk
2-2 通过EM算法对混合高斯模型进行参数估计
- 初始化: 对需要优化的对象参数 π \pi π, μ \mu μ, Σ \Sigma Σ进行初始化赋值,然后计算出对数似然函数的结果
- E-step:计算后验概率 γ ( z n k ) \gamma(z_{nk}) γ(znk)
γ ( z n k ) = p ( z k = 1 ∣ x ) = p ( z k = 1 ) p ( x ∣ z k = 1 ) ∑ j = 1 K p ( z k = 1 ) p ( x ∣ z k = 1 ) = π k N ( x ∣ μ k , Σ k ) ∑ j = 1 K π j N ( x ∣ μ j , Σ j ) \begin{aligned} \gamma(z_{nk})=&p(z_k=1|x)\\ =&\frac{p(z_k=1)p(x|z_k=1)}{\sum_{j=1}^Kp(z_k=1)p(x|z_k=1)}\\ =&\frac{\pi_kN(x|\mu_k, \Sigma_k)}{\sum_{j=1}^K\pi_jN(x|\mu_j, \Sigma_j)} \end{aligned} γ(znk)===p(zk=1∣x)∑j=1Kp(zk=1)p(x∣zk=1)p(zk=1)p(x∣zk=1)∑j=1KπjN(x∣μj,Σj)πkN(x∣μk,Σk)
- M-step:将对数似然函数关于 π \pi π, μ \mu μ, Σ \Sigma Σ偏微分置为0,求参数最优解
μ k ∗ = 1 N k ∑ n = 1 N γ ( z n k ) x n Σ k ∗ = 1 N k ∑ n = 1 N γ ( z n k ) ( x n − μ k ) ( x n − μ k ) T π k = N k N = ∑ n = 1 N γ ( z n k ) N \mu_k^{*}=\frac{1}{N_k}\sum_{n=1}^N\gamma(z_{nk})x_n\\ \Sigma_k^{*}=\frac{1}{N_k}\sum_{n=1}^N\gamma(z_{nk})(x_n-\mu_k)(x_n-\mu_k)^T\\ \pi_k=\frac{N_k}{N}=\frac{\sum_{n=1}^N\gamma(z_{nk})}{N} μk∗=Nk1n=1∑Nγ(znk)xnΣk∗=Nk1n=1∑Nγ(znk)(xn−μk)(xn−μk)Tπk=NNk=N∑n=1Nγ(znk)
- 收敛判断:再次计算对数似然函数,设定一个阈值,如果与前一次的差值小于该阈值则判断为收敛,停止迭代更新,否则从M-step开始循环
L n e w = l n p ( X ∣ π , μ , Σ ) = ∑ n = 1 N l n { ∑ j = 1 K π j N ( x n ∣ μ j , Σ j ) } L n e w − L o l d < ϵ L_{new}=lnp(X|\pi, \mu, \Sigma)=\sum_{n=1}^Nln\{\sum_{j=1}^K\pi_jN(x_n|\mu_j,\Sigma_j)\}\\ L_{new}-L_{old} < \epsilon Lnew=lnp(X∣π,μ,Σ)=n=1∑Nln{j=1∑KπjN(xn∣μj,Σj)}Lnew−Lold<ϵ
三、python代码实现
具体的代码实现可以参考我的github,这里只贴出一部分核心代码
def plot_gmm_contour(mu, sigma, pi, K):
X, Y = np.meshgrid(np.linspace(x_min, x_max), np.linspace(y_min, y_max))
XX = np.array([X.ravel(), Y.ravel()]).T
Z = np.sum(np.array([[pi[k] * st.multivariate_normal.pdf(d, mu[k], sigma[k]) for k in range(K)] for d in XX]), axis = 1)
Z = Z.reshape(X.shape)
CS = plt.contour(X, Y, Z, alpha = 0.5, zorder = -100)
plt.title("pdf contour of a GMM")
# EM iteration
def iterate(step):
global mu, sigma, pi
plt.clf()
print("step: {}".format(step))
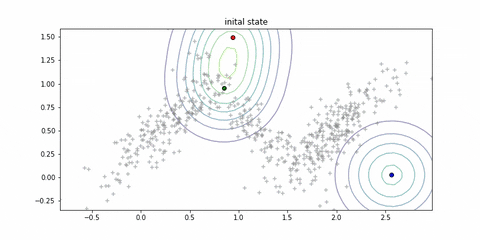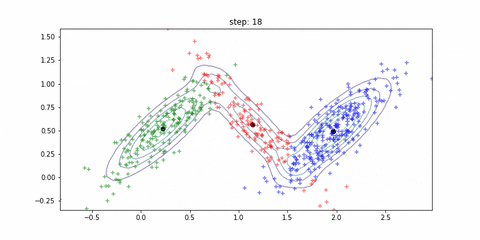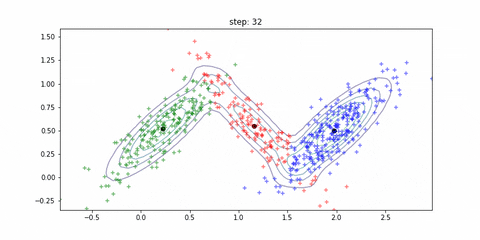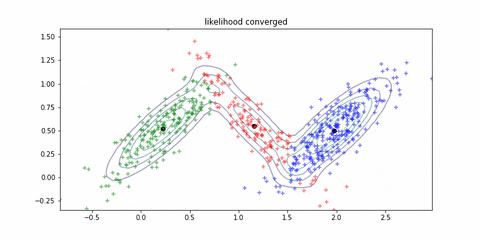
if step <= 3:
print("initial state")
plt.scatter(data[:, 0], data[:, 1], s = 30, c = "gray", alpha = 0.5, marker = "+")
for i in range(3):
plt.scatter(mu[i, 0], mu[i, 1], c = c[i], marker = "o", edgecolors = "k", linewidths = 1)
plot_gmm_contour(mu, sigma, pi, K)
plt.title("inital state")
return
# E step
likelihood = likelihood_cal(data, mu, sigma, pi, K)
gamma = (likelihood.T / np.sum(likelihood, axis = 1)).T
N_k = [np.sum(gamma[:, k]) for k in range(K)]
# M step
# pi
pi = N_k / N
# mu
mu_tmp = np.zeros(shape = [K, D])
for k in range(K):
for i in range(len(data)):
mu_tmp[k] += gamma[i, k] * data[i]
mu_tmp[k] /= N_k[k]
mu_prev = mu.copy()
mu = mu_tmp.copy()
print("updated mu:\n{}".format(mu))
# sigma
sigma_tmp = np.zeros(sigma.shape)
for k in range(K):
for i in range(len(data)):
sigma_tmp[k] += gamma[i, k] * np.dot((data[i] - mu[k])[:, np.newaxis], (data[i] - mu[k])[:, np.newaxis].T)
sigma_tmp[k] /= N_k[k]
sigma_prev = sigma.copy()
sigma = sigma_tmp.copy()
print("updated sigma:\n{}".format(sigma))
# update likelihood
sum_log_likelihood_prev = np.sum(np.log(likelihood))
sum_log_likelihood = np.sum(np.log(likelihood_cal(data, mu, sigma, pi, K)))
diff = sum_log_likelihood - sum_log_likelihood_prev
print("sum log likelihood: {}".format(sum_log_likelihood))
print("diff: {}".format(diff))
for i in range(np.sum(n)):
plt.scatter(data[i, 0], data[i, 1], s = 30, c = c[np.argmax(gamma[i])], alpha = 0.5, marker = "+")
for k in range(K):
ax = plt.axes()
ax.arrow(mu_prev[k, 0], mu_prev[k, 1], mu[k, 0] - mu_prev[k, 0], mu[k, 1] - mu_prev[k, 1], lw = 0.8, head_width = 0.02, head_length = 0.02, fc = "k", ec = "k")
plt.scatter(mu_prev[k, 0], mu_prev[k, 1], c = c[k], marker = "o", alpha = 0.8)
plt.scatter(mu[k, 0], mu[k, 1], c = c[k], marker = "o", edgecolors = "k", linewidths = 1)
# plt.title("steps: {}".format(step))
plot_gmm_contour(mu, sigma, pi, K)
if np.abs(diff) < 0.0001:
plt.title("likelihood converged")
else:
plt.title("step: {}".format(step))
迭代的动态过程如下所示: