NER[2] - 文章解读:A Survey on Deep Learning for Named Entity Recognition
本文是翻译一篇NER综述原文:A Survey on Deep Learning for Named Entity Recognition
文章链接:https://arxiv.org/abs/1812.09449v3
摘要
- NER 简介
- 1. NER 数据资源和流行工具
-
- 1.1 资源
- 1.2 NER 工具
- 2. NER 的性能评估指标
- 3. NER 中的深度学习技术
-
- 3.1 DL 为什么那么有效
- 3.2 模型分层标准
- 3.3 输入的分布式表示
-
- 3.3.1 Word-level 表示
- 3.3.2 Character-level 表示
-
- (1) CNN 用于 char-level 表示
- (2) RNN 用于 char-level 表示
- 3.3.3 混合表示(Hybrid Representation)
- 3.4 Context Encoder Architectures
-
- 3.4.1 CNN
- 3.4.2 RNN
- 3.4.3 递归神经网络
- 3.4.4 神经语言模型
- 3.4.5 Deep Transformer
- 3.5 Tag decoder
-
- 3.5.1 MLP + softmax
- 3.5.2 CRF
- 3.5.3 RNN
- 3.5.4 指针网络
- 3.6 基于 DL 的NER 总结
- 4. 应用深度学习技术 到 NER
-
- 4.1 深度多任务学习
- 4.2 深度迁移学习
- 4.3 深度主动学习
- 4.4 深度强化学习
- 4.5 NER 中的深度对抗学习
- 4.6 Neural Attention
- 5. 展望与挑战
-
- 5.1 难点
-
- 5.1.1 数据标注
- 5.1.2 非正式文本和新实体
- 5.2 展望
- 6. 推荐论文
NER 简介
命名实体识别(NER)的任务是识别 mention 命名实体的文本范围,并将其分类为预定义的类别,例如人,位置,组织等。 NER 是各种自然语言应用(例如问题解答,文本摘要和机器翻译) 的基础。尽管早期的NER系统有着较好的识别精度,但是却严重依赖精心设计规则,需要大量的人力取整理和设计。近年来, 随着深度学习的使用, 使得 NER 系统的精度获得了质的提升. 在本文中,作者对 NER 的现有深度学习技术进行了全面回顾。
- 介绍NER资源,包括标记的NER语料库和现成的NER工具。
- 将现有结构分为三部分:输入的分布式表示(Distributed representations for input),上下文编码器(Context encoder) 和标签解码器(tag decoder)。
- 介绍最具代表性的深度学习技术在 NER 中的应用, 包含 多任务学习, 迁移学习, 主动学习, 强化学习 和 对抗学习, Attention 等。
- 介绍NER系统面临的挑战,并概述了该领域的未来方向。
(1)NER 技术概览
下图忽略网络中间细节, 展示了 NER 任务的目标。首先网络的输入是一个一个的词,记做 w 1 w_1 w1, w 2 w_2 w2,…, w n w_n wn。NER 任务的目标就是给出一个命名实体的起始和终止边界, 并给出该命名实体的类别. 如 Michael Jeffrey Jordan 就是一个命名实体, 它的起止位置为[w1,w3],实体类型为 Person。
![NER[2] - 文章解读:A Survey on Deep Learning for Named Entity Recognition_第1张图片](http://img.e-com-net.com/image/info8/f51a7405456449df82fc1d73f372a8b8.jpg)
一般来说, 做 NER 有四种方法, 和一般机器学习任务的方法一样:
- 基于规则: 手工制定符合什么条件的是什么词/类别. 优点是不需要标注数据, 缺点是制定规则和维护都很麻烦, 而且迁移成本高. 比较出名的有LaSIE-II, NetOwl等。
- 无监督方法: 基于无监督算法, 不需要标注数据, 不过准确度一般有限。
- 基于特征的机器学习方法:需要标注数据, 同时一般结合精心设计的特征.常用的模型如 HMM, 决策树, 最大熵模型, CRF 等.常用的特征包含词级别特征(大小写,词的形态, 词性标记), 文档和语料特征(局部语法和共现)等。
- 基于深度学习的方法: 需要标注数据, 自动学习特征, 可以端到端的搞
现在一般领域性比较强,数据量特别少的会用规则,其余基本上都是机器学习或者深度学习。尤其是在数据量比较充足的时候,深度学习一般都可以获得比较不错的指标, 有时也会加一些规则辅助。
1. NER 数据资源和流行工具
1.1 资源
论文里给出了很多英文语料, 如下图所示:
![NER[2] - 文章解读:A Survey on Deep Learning for Named Entity Recognition_第2张图片](http://img.e-com-net.com/image/info8/ec4e82dd47f8440e9a11b351d3379d9f.jpg)
实际论文中, 用 CoNLL03 和 OntoNotes 两个的多一些.
-
CoNLL03包含两种语言的路透社新闻标注:英语和德语。
- 英语数据集包含大部分体育新闻,并在四种实体类型(人员,位置,组织和其他)中进行了标注。
-
OntoNotes项目的目标是标注大型语料库
- 包括各种类型(博客,新闻,脱口秀,广播,Usenet新闻组和对话电话语音)以及结构信息(语法和谓词参数结构)和浅语义(单词).
- 发行版1.0到发行版5.0共有5个版本。
- 这些文本用18种粗粒度实体类型(由89个子类型组成)进行标注。
1.2 NER 工具
由学术界 提供的有 StanfordCoreNLP, OSU Twitter NLP, Illinois NLP, NeuroNER, NERsuite, Polyglot, and Gimli. 工业界提供的有 spaCy, NLTK, OpenNLP, LingPipe, AllenNLP, and IBM Watson.
下图是工具的汇总和对应链接:
![NER[2] - 文章解读:A Survey on Deep Learning for Named Entity Recognition_第3张图片](http://img.e-com-net.com/image/info8/5e7cc341f57c40afbd74e15de1b668b4.jpg)
对我个人来说, 一般中文项目用 HanNLP, StanfordCoreNLP, NLTK, spaCy 多一些.
2. NER 的性能评估指标
作者给出了 精确匹配(Exact-match Evaluation) 和 宽松匹配(Relaxed-match Evaluation) 评估两种. 不过用的不多这里就不写了。
首先为了计算 F1, 定义一下 TP, FP, FN
- True Positive(TP): 实体被 NER 识别并标记为该类型 同时和 ground truth 对上了 False
- Positive(FP): 实体被 NER 识别并标记为该类型 但是和 ground truth 对不上 False
- Negative(FN): 实体没有被识别和标记为该类型, 但 ground truth 是
有了它们仨, 就可以算精确度(Precision), 召回率(Recall)和 F1 值了.

举个例子:
“张三 爱 北京 天安门 前 的 毛主席”###”Person O Location Location O O Person”###”Location O Person Location O Location Person”
上面###左侧是原, 中间是 ground truth, 左侧是 预测的标签. 这里需要注意的是, 我们的 TP, FP, FN 是针对单个类别的. 因此此时计算 Location 的F1的话, TP = 1(第四个), FP = 1(第一个), FN = 2(第三个和 第六个), Precision 就是 0.5, Recall 是 1 / 3 1/3 1/3 , F1的值就是0.4。
有了每个类别的指标后, 有两种办法把它们综合在一起:
- Macro averaged F-score: 根据每个类型的值来计算,得到平均值, 相当于把每个类型平等对待 Micro
- averaged F-score: 综合所有实体的所有类别的贡献来计算平均值, 相当于把每个实体平等看待.
一般 Micro 方法更容易受到样本不均衡的影响, 容易使得表现较好的大数样本掩盖表现不好的小数据量类别.
3. NER 中的深度学习技术
3.1 DL 为什么那么有效
NER 受益于 深度学习的好处主要有三点:
- NER 受益于 DL 的高度非线性, 相比于传统的线性模型(线性 HMM 和 线性链 CRF), 深度学习模型能够学到更复杂的特征
- 深度学习能够自动学习到对模型有益的特征, 传统的机器学习方法需要需要繁杂的特征工程, 而深度学习则不需要
- 深度学习可以端到端的搭建模型, 这允许我们搭建更复杂的 NER 系统.
3.2 模型分层标准
传统的模型分层标准为: 字符层(character-level), 词层(word-level), 标签层(tag level). 该论文认为传统的模型分层标准不合理. 原因是 word level 这个表述不准确. 原始数据可以以 word 为单位进行输入, 也可以是在 char level 后, 有char 组合得到.因此论文提出新的分类方法:
- 输入的分布式表示( Distributed representations for input ): 基于 char 或者 word
嵌入的向量, 同时辅以 词性标签(POS), gazetter 等人工特征. - 语义编码(context encoder): 该层通过
CNN, RNN, LM, Transformer 等网络获取语义依赖. - 标签解码(tag decoder): 预测输入序列对应的标签,
常用的如 softmax, CRF, RNN, 指针网络(Point Network)
下图给出该分类的示意:
![NER[2] - 文章解读:A Survey on Deep Learning for Named Entity Recognition_第4张图片](http://img.e-com-net.com/image/info8/8f7aa852cc9041368939773795344da8.jpg)
3.3 输入的分布式表示
分布式表示通过把词映射到低维空间的稠密实值向量, 其中每个维度都表示隐含的特征维度. 一般 NER 系统的输入采用三种表示: word-level, char-level, 混合(hybrid) 表示.
需要注意的是, 该论文针对的是英语 NER, 因此这里的词是指 has, Jeff 这种, 字是指 a, b, c 这种.
3.3.1 Word-level 表示
很流行的一种方法, 通常使用无监督算法如:连续词袋模型(CBOW) 和 skip-gram 模型对大量文本进行预训练, 得到每个词对应的向量表示. 其模型示意如下图所示:
![NER[2] - 文章解读:A Survey on Deep Learning for Named Entity Recognition_第5张图片](http://img.e-com-net.com/image/info8/43d905e0a6de49a88ee53fd3f8c676d7.jpg)
其中 CBOW 是给定周围词来预测中心词,skip gram 模型是给定中心词预测周围的词。
Word level 比较好用的工具是 Word2Vec 和 Glove, 除此之外还有 fastText, SENNA等。
3.3.2 Character-level 表示
除了词级别的, 还可以用基于字级别的向量表示, 现有的字符级标识对于显示利用子单词级信息(如前缀和后缀)很有用. 字符级表示的另一个优点是可以减轻未登录词(OOV)的问题. 所以字符级表示可以处理没见过的词,同时共享词素信息.
通常有两个广泛使用的提取字符级表示的体系结构: 基于 CNN 的和 基于 RNN 的模型. 下图分别介绍它们.
(1) CNN 用于 char-level 表示
论文(End-to-end Sequence Labeling via Bi-directional LSTM-CNNs-CRF) 利用 CNN 提取单词的字符级表示, 然后字符级表示与 word 级表示连在一起作为最终的词表示输入到 RNN 中.
论文(Leveraging linguistic structures for named entity recognition with bidirectional recursive neural networks) 应用了一系列的卷积和 highway 层来生成单词的字符级表示. 最终该表示被输入到双向递归网络中.
论文(Neural reranking for named entity recognition) 提出了一种用于 NER 的神经网络 reranking 模型, 其中使用了固定窗口大小的卷积层来提取词的字符级表示.
论文(Deep contextualized word representations) 提出了 ELMo 词表示, 它是通过在双层双向语言模型上进行字符级卷积运算得到的.
(2) RNN 用于 char-level 表示
下图给出了一个常见的 RNN 用于提取 char level表示的结构. 其中输入为 “start, J, o, r, d, a, n, end”. 通过 lookup embedding 得到字符的向量表示 “W = w0, w1, w2, w3, w4, w5, w6, w7”. 该层后有一个双向的 RNN. 正向的 RNN那接收 W 的正序列, 并将最终时间步的输出h正作为正向 RNN 的输出. 同理反向 RNN 接收 W 的倒序列, 得到最终时间步的输出 h 反 h^反 h反. 最终词的表示有 h 正 h^正 h正 和 h 反 h^反 h反 拼接得到。
![NER[2] - 文章解读:A Survey on Deep Learning for Named Entity Recognition_第6张图片](http://img.e-com-net.com/image/info8/5e2523c445ed40e09403bafd04e80e66.jpg)
论文(Neural architectures for named entity recognition) 利用双向 LSTM 提取单词的字符级表示, 和前面经典的 CNN+BLSTM+CNN 的做法类似, 将 BLSTM 得到的字符级词表示和预训练得到的词向量连接在一起, 作为最终的 词表示.
论文(Attending to characters in neural sequence labeling models) 使用 门控机制(gate)控制字符级信息和预训练得到的单词嵌入相结合, 通过 gate, 该模型能够动态地决定从字符或者单词级组分中使用多少信息.
论文(Named entity recognition with stack residual lstm and trainable bias decoding) 引入了具有堆叠残差(stack resdual) LSTM 和可训练偏差解码的神经网络 NER 模型, 其中输入的 word 表示来自从 RNN 中提取的字符级特征与词嵌入的结合.
论文(Multi-task cross-lingual sequence tagging from scratchMulti-task cross-lingual sequence tagging from scratch) 开发了一种以统一的方式处理跨语言和多任务联合训练的模型. 改论文采用了一个深层次的双向 GRU结构, 来从单词的字符序列中学习丰富的形态表示. 而后将字符级表示和单词嵌入连接起来得到单词的最终表示.
3.3.3 混合表示(Hybrid Representation)
除了基于字和词的表示外, 一些研究还使用了额外的信息, 如 gazetteers 和 lexical similarity 等 添加到 word 表示中, 添加这些人工特征虽然会增加模型的表现, 不过可能降低模型的迁移泛化能力.
在论文 (Bidirectional lstm-crf models for sequence tagging) 中, 作者用了四个额外特征 : 拼写特征, 文本特征, 词向量和 gazetteer 特征. 他们的实验结果表明, 额外的特征能够提升标注的准确性.
论文 (Named entity recognition with bidirectional lstm-cnns) 使用 BiLSTM 和 字符级的 CNN网络. 模型输入除了 词嵌入之外, 还包含词级别特征(开头大写, lexicons) , 字级别特征(每个字符使用了4维额外特征: 大写, 小写, 标签符号, 其他).
论文 (Disease named entity recognition by combining conditional random fields and bidirectional recurrent neural networks) 使用了基于 CRF 的神经网络徐彤来识别疾病命名实体. 该系统使用了很多额外的特征: words, POS tags, chunking, word shape (dictionary 和 morphological 特征).
论文(Fast and accurate entity recognition with iterated dilated convolutions) 将 100 维的词向量与 5 维的 word shape 特征向量(是否全部大写, 不是全部大写, 开投字母大写, 包含大写字母)进行连接.
论文(Multi-channel bilstm-crf model for emerging named entity recognition in social media) 使用 词嵌入, 字嵌入 和 与词相关的语法嵌入(POS 标签, 一寸角色, 单词位置, head 位置) 来构造词表示.
论文(Robust lexical features for improved neural network named-entity recognition) 发现神经网络常常会抛弃大部分的词法(lexical) 特征. 他们提出一个可以离线训练的并且可以用于任何神经网络系统的新词法表示. 该词法表示的维度为 120, 每个词都有一个, 通过计算词与实体类型的相似度得到.
3.4 Context Encoder Architectures
神经网络 NER 系统的第二层通过接收上一层的嵌入向量来学习语义编码. 论文将该层分为四类: CNN, RNN, 递归神经网络, transformer。
3.4.1 CNN
Collobert 等(Natural language processing (almost) from scratch) 用整个句子的信息来对词进行标记, 其网络结构如下图所示:
![NER[2] - 文章解读:A Survey on Deep Learning for Named Entity Recognition_第7张图片](http://img.e-com-net.com/image/info8/ef37dd6a7834422693756a69a63bd7f5.jpg)
每个词通过向量嵌入转化为对应的向量. 之后通过卷积层来得到局部的特征. 卷积层的输出大小与输入的句子长度有关. 为了获取固定维度的句子表示, 在卷积后增加了池化层. 池化可以用最大池化或者平均池化.最后 tag decoder 使用该句子表示来得到标签的概率分布.
论文(Named entity recognition in chinese clinical text using deep neural network) 使用卷积层和一系列的全局隐层节点来生成全局的特征表示. 之后局部特征和全局特征被联合输入到标准的仿射网络来进行临床实体识别。
论文(Joint extraction of multiple relations and entities by using a hybrid neural network) 观察到 RNN 靠后时间步的影响要大于前面时间步的词. 然而对于整个句子来说, 重要的特征有可能出现在各个角落. 因此他们提出 BLSTM-RE 模型, 其中 BLSTM 用来不做长期依赖特征, 同时 CNN 用来学习 高级别(high-level)表示. 之后特征被输入到 sigmoid 分类器. 最终 整个句子表示(由 BLSTM 生成) 和 关系表示(sigmoid 分类器生成的) 被输入到另一个 LSTM 网络来预测实体。
论文(Fast and accurate entity recognition with iterated dilated convolutions) 提出膨胀卷积神经网络(Iterated Dilated Convolutional Neural Networks, ID-CNNs), 该模型在大文本和结构化预测上拥有比传统 CNN 更好的表现. ID-CNNs 的时间复允许固定深度的卷积在整个文档上并行的跑. 下图给出膨胀 CNN 模块的结构. 其中展示了四个堆叠的宽度为3的膨胀卷积. 对于膨胀卷积, 输入宽度的影响会随着深度的增加指数型增长, 同时每层的分辨率没有什么损失. 实验表明, 相比于传统得到 Bi-LSTM-CRF 有 14-20x 倍的加速, 同时保持相当高的准确率。
下图为 膨胀 CNN 模块示意图, 最大膨胀深度为 4, 宽度为 3. 对最后一个神经元有贡献的神经元都被加黑显示.
![NER[2] - 文章解读:A Survey on Deep Learning for Named Entity Recognition_第8张图片](http://img.e-com-net.com/image/info8/66b1273d442f43fb8b6c0f960bd68713.jpg)
3.4.2 RNN
RNN 以及它的变体 LSTM 和 GRU 被证明在序列数据中有较好的效果. 其中前向 RNN 能够有效利用过去的信息, 反向 RNN 能够利用未来的信息, 因此 双向 RNN 能够利用整个序列的信息, 因此 双向 RNN成为深度语义编码的标配结构. 一个传统的基于 RNN 的语义编码结构如下图所示:
![NER[2] - 文章解读:A Survey on Deep Learning for Named Entity Recognition_第9张图片](http://img.e-com-net.com/image/info8/d8b422524a9c415ca07323accb016c64.jpg)
Huang 等(Bidirectional lstm-crf models for sequence tagging) 最先使用 BiLSTM+CRF 结构用于序列标注问题(POS, chunking 和 NER). 之后涌现出很多工作都使用 BiLSTM 作为基本结构来编码语义信息。
论文(Toward mention detection robustness with recurrent neural networks) 表明, RNN 不仅在通用情况下超过传统系统, 同时在英语的跨领域情况下也能达到最优的性能(相对误差减少 9%). 在跨语言的情况下, 在类似的荷兰语 NER 任务中, RNN 明显优于传统方法(相对误差减少 22%)。
论文(Neural Models for Sequence Chunking) 通过研究 DNN 用于序列分块的方法, 提出了一种替代方法, 并提出了三种神经网络模型, 以便每个块都可以作为完整的标记单元. 实验结果表明, 所提出的神经序列分块模型可以再文本分块和槽填充任务上实现最佳性能。
论文(Multi-task cross-lingual sequence tagging from scratch) 将深度 GRUs 用于 字符级和 词级别表示上来进行形态学和语义信息编码. 之后作者进一步扩展模型到跨语言和多任务的中。
论文(Named entity recognition with parallel recurrent neural networks) 在同一输入上采用了多个独立的双向 LSTM 单元. 他们的模型通过使用模型间的正则项促进了 LSTM 单元之间的多样性. 通过将计算分散到多个 LSTM 中, 他们发现模型的中参数减少了。
3.4.3 递归神经网络
递归神经网络是非线性自适应模型,能够通过以拓扑顺序遍历给定的结构来学习深度的结构化信息。 命名实体与语言成分高度相关,例如名词短语。但是,典型的顺序标注方法很少考虑句子的短语结构。为此,论文(Leveraging linguistic structures for named entity recognition with bidirectional recursive neural networks, char level 那里有说) 提出对NER的成分结构中的每个节点进行分类。该模型递归地计算每个节点的隐藏状态向量,并通过这些隐藏向量对每个节点进行分类。下图显示了如何为每个节点递归计算两个隐藏状态特征。自下而上的方向计算每个节点的子树的语义成分,而自上而下的对应对象将包含子树的语言结构传播到该节点。给定每个节点的隐藏矢量,网络将计算命名实体类型加特殊非实体类型的概率分布。
![NER[2] - 文章解读:A Survey on Deep Learning for Named Entity Recognition_第10张图片](http://img.e-com-net.com/image/info8/1d8c3918afd94dceb7e4010146bc4964.jpg)
3.4.4 神经语言模型
语言模型用来描述序列的生成。给定一个序列 ( t 1 , t 2 , … , t N ) (t_1,t_2,…,t_N) (t1,t2,…,tN). 则得到该序列的概率为:
![NER[2] - 文章解读:A Survey on Deep Learning for Named Entity Recognition_第11张图片](http://img.e-com-net.com/image/info8/11f2fc54ce91445aaff821a58d648732.jpg)
类似的, 一个后向模型得到该序列的概率
![NER[2] - 文章解读:A Survey on Deep Learning for Named Entity Recognition_第12张图片](http://img.e-com-net.com/image/info8/726d94d89d8943a1b224426dd3b1bb85.jpg)
对于神经语言模型, 可以用 RNN 的每个时间步 t k t_k tk的输出得到概率 p ( t k ) p(t_k) p(tk). 在每个位置上, 可以得到两个语义相关的表示(前向和后向), 之后将它们俩结合作为最终语言模型向量表示 t k t_k tk. 这种语言模型知识已经被很多论文证实在序列标注中很有用.
论文(Semi-supervised multitask learning for sequence labeling) 提出一个序列标注模型, 该模型要求模型除了预测标签意外, 还要预测它周围的词, 网络结构如下图所示:
![NER[2] - 文章解读:A Survey on Deep Learning for Named Entity Recognition_第13张图片](http://img.e-com-net.com/image/info8/e9b4e6ff8da647dba556a9d0052d6f54.jpg)
在每个时间步, 要求模型预测当前词的标签和下一个词. 反向的网络就预测当前标签和前一个词, 这样网络就预测了当前标签和周围的词。
论文(Semisupervised sequence tagging with bidirectional language model) 提出 TagLM, 一个语言模型增强序列标注器. 该标注器同时考虑了预训练词嵌入和双向语言模型嵌入.
下图展示了 LM-LSTM-CRF 的网络结构.
![NER[2] - 文章解读:A Survey on Deep Learning for Named Entity Recognition_第14张图片](http://img.e-com-net.com/image/info8/9fd5b7c5b55e41b4a2fceaa43557b157.jpg)
其中左侧下方是 字符级的嵌入, 通过双向 LSTM 得到. 中间 三个黑点那个是预训练得到的词向量, 虚线右侧将上下文嵌入得到的 LM 部分. 它们三个连接得到一个综合的表示, 被输入到 BLSTM 和 CRF 中得到标记序列.
3.4.5 Deep Transformer
Transformer 这个大家也很熟悉了, 它在论文中的结构如下图所示:
![NER[2] - 文章解读:A Survey on Deep Learning for Named Entity Recognition_第15张图片](http://img.e-com-net.com/image/info8/a22859c4114e4081884a831830de6e3b.jpg)
实际使用中用的是左侧的那个块中的东西. 很多任务表明 Transformer 在序列生成等多种任务上有很好的表现, 同时可以并行, 效率高.
3.5 Tag decoder
Tag 是NER 的最后一层, 它接收语义表示输出标注序列. 常见的解码方式为: MLP + softmax, CRF, RNN 和指针网络(pointer network). 下图给出了它们的结构示意图:
![NER[2] - 文章解读:A Survey on Deep Learning for Named Entity Recognition_第16张图片](http://img.e-com-net.com/image/info8/2d6663646ae24280aac24d2ceeb7037b.jpg)
3.5.1 MLP + softmax
这个太常见了, 比如 BLSTM 的输出后面跟一个全连接层进行降维, 再接 softmax 得到标签的概率分布.
3.5.2 CRF
自从 CRF 被提出加到神经网络后面用于解码后, 几乎成了一个标配了. 主要是因为 CRF 可以利用全局信息进行标记. 下面以 BLSTM+CRF 那篇论文为网络结构, 说一下 CRF 的原理.
BLSTM 的输出经过 softmax 后得到的是一个 n×k 的矩阵 P, 其中n 是序列长度, k 是类别数量. 因此 Pi,j 表示第 i 个词的 第 j 个预测标签. 对于某一预测序列 y=(y1,y2,…,yn), 可以定义如下分数:
![NER[2] - 文章解读:A Survey on Deep Learning for Named Entity Recognition_第17张图片](http://img.e-com-net.com/image/info8/54cb34a4f3764df986b58ebf50eb44df.jpg)
其中 A 是转移分数, 其中 Ai,j 表示从标签 i 转移到 标签 j 的分数. y0 和 yn+1 表示 start 和 end 标签. 因此转移矩阵 A 是一个 k+2 的方阵. 将每个可能的序列得分 s 综合起来 输入到 softmax 中, 得到每个序列对应的概率
![NER[2] - 文章解读:A Survey on Deep Learning for Named Entity Recognition_第18张图片](http://img.e-com-net.com/image/info8/3c5face9996849e580e565f425503860.jpg)
在训练期间, 将会最大化正确标签的对数概率, 即
![NER[2] - 文章解读:A Survey on Deep Learning for Named Entity Recognition_第19张图片](http://img.e-com-net.com/image/info8/f1bc5cfd05104383bc14df92de6de740.jpg)
其中 Y X Y_X YX 表示输入序列 X 对应的所有可能的标签序列. 通过最大化上式, 模型将会学习有效正确的标签顺序, 避免如(IOB) 这样的输出. 在解码时, 求解使得分数 s 最高的标签序列:
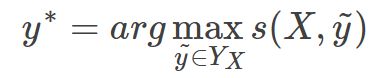
因为这里的转移矩阵只考虑了 bigram 的相互作用. 所以在优化和解码时可以直接用 DP 计算.
不过论文(Segment-level sequence modeling using gated recursive semi-markov conditional random fields) 认为, CRF 虽然强, 但是却不能充分利用段落(segment) 级别的信息, 这是因为词级别的编码表示不能完全表达段落的内在属性. 因此改论文提出 门递归半马尔科夫条件随机场(gated recursive semi-markov CRFs). 该模型直接对段落进行建模, 而不是 词, 并通过 门控递归卷积神经网络自动的学习段落级特征,
近期, 论文(Hybrid semi-markov crf for neural sequence labeling) 提出混合 半马尔科夫 CRFs(hybrid semi-Markov CRFs) 用于序列标注. 该方法直接采用段落而不是词作为基本单元, 词级别特征被用于推导段落分数. 因此该方法能够同时使用 词和段落级别的信息.
3.5.3 RNN
有一部分研究采用 RNN 来解码标注. 这里以论文(Deep active learning for named entity recognition)为例, 说一下解码流程. 如上图 C 所示, 图中的 h i E n c h^{Enc}_i hiEnc 表示编码隐层向量, h i D e c h^{Dec}_i hiDec 表示解码隐藏层向量, 初始时, 给定 Go 标记(类似于 start), 当前时间点的编码向量和上一时间步的解码向量, 模型输出当前时刻的解码向量, 即

解码向量经过softmax 得到标签的概率分布, 取概率最大的作为最终标记. 如此循环直到解码完成.
3.5.4 指针网络
指针网络应用RNN来学习输出序列的条件概率,其中元素是与输入序列中的位置相对应的离散 token。 它通过使用softmax概率分布作为“指针”来表示可变长度词典。
3.6 基于 DL 的NER 总结
下图给出了近期在 NER 方面的工作汇总
![NER[2] - 文章解读:A Survey on Deep Learning for Named Entity Recognition_第20张图片](http://img.e-com-net.com/image/info8/aa0caf9c105245379838414de822c1a1.jpg)
总结一下:
- 在语义编码截断, 用的最多的是 RNN(其中 LSTM最多, GRU 要少一点)
- 解码用的最多的是 CRF. BiLSTM+CRF 组合的网络结构用的最多
- 在向量嵌入方面, 词的话 Word2vec, Glove, SENNA 用的比较多
- 字符级别的 LSTM 比 CNN 多一点.
- 额外特征方面, POS 用的更多一点, 但是,关于是否应该使用外部知识(例如,地名词典和 POS)或如何将其集成到基于DL的NER模型,尚未达成共识。 然而,对诸如新闻文章和网络文档之类的通用域文档进行了大量实验。 这些研究可能无法很好地反映特定领域资源的重要性,例如在特定领域中的地名词典。
4. 应用深度学习技术 到 NER
论文介绍了了 多任务学习(multi-task learning), 深度迁移学习(deep transfer learning), 深度主动学习(deep active learning), 深度强化学习(deep reinforcement learning), 深度对抗学习(deep adversarial learning) 和 神经元注意力(neural attention) 用于 NER 的进展.
4.1 深度多任务学习
多任务学习是一种可以一起学习一组相关任务的方法。 通过考虑不同任务之间的关系,与单独学习每个任务的算法相比,多任务学习算法有望获得更好的结果。
论文(Natural language processing (almost) from scratch) 训练了一个窗口/句子(window/sentence) 网络来同时训练 POS,Chunk,NER和SRL任务。 在窗口网络中共享第一线性层的参数,在句子网络中共享第一卷积层的参数。 最后一层是特定于任务的。 通过最小化所有任务的平均损失来实现训练。 这种多任务机制使训练算法能够发现对所有感兴趣任务有用的内部表示形式。
论文(Multi-task cross-lingual sequence tagging from scratch) 提出了一个多任务联合模型,以学习特定于语言的规律性,同时训练POS,Chunk和NER任务。
论文(Semi-supervised multitask learning for sequence labeling) 发现,通过在训练过程中加入 无监督语言建模训练目标,序列标记模型可以实现性能改进。
除了将NER与其他序列标记任务一起考虑之外,多任务学习框架可以应用于实体和关系的联合提取, 如论文(Joint extraction of entities and relations based on a novel tagging scheme) 和 论文(Joint extraction of multiple relations and entities by using a hybrid neural network).
或将NER建模为两个相关的子任务:实体分割和实体类别预测, 如论文(A multitask approach for named entity recognition in social media data) 和 论文(Multi-task domain adaptation for sequence tagging).
4.2 深度迁移学习
迁移学习旨在利用从源领域中学习到的知识来在目标域上执行机器学习任务. 在 NLP 中, 迁移学习也称为领域适应, 对于 NER 任务, 传统方法是通过自举算法(boostrapping alogrithms). 不过近期已经有很多工作使用深度学习来做 NER 的跨领域识别了.
论文(Transfer joint embedding for crossdomain named entity recognition) 提出了一种跨领域 NER 的迁移联合嵌入( transfer joint embedding, TJE )方法, TJE 使用标签嵌入技术将多类分类问题转化为低维潜变量空间中的回归问题. 实验结果证明了该方法在 ACE 2005 数据集上跨不同领域的有效性.
论文(Named entity recognition for novel types by transfer learning) 观察到相关的命名实体类型经常共享词汇和上下文特征. 因此论文中使用两层神经网络来学习源命名实体类型和目标命名实体类型之间的相关性. 该方法适用于源域和目标域具有相似性(但不相同)的情况.
在迁移学习的设置中, 不同的神经模型通常在源任务和目标任务之间共享模型参数的不同部分. 论文(Transfer learning for sequence tagging with hierarchical recurrent networks) 首先研究了表示的不同层次的可传递性. 而后他们针对跨领域, 跨语言, 跨应用场景提出了三种不同的参数共享架构. 如果两个任务具有可映射的标签集时, 则共享的它们的 CRF 层. 实验结果表明, 在数据集不充足的情况下, 该方法使得模型在各个数据集上的表现都得到了提升.
论文(Transfer learning and sentence level features for named entity recognition on tweets) 扩展了上述论文的方法, 允许对非正式语料库进行联合训练(如 WNUT 2017), 同时该模型还使用了句子级别的特征表示.
论文(Improve neural entity recognition via multi-task data selection and constrained decoding) 提出了一种具有领域适应性的多任务模型, 其中全连接层在不同的数据集间共享, 但 CRF是独立计算的. 该模型的主要优点是, 在数据选择过程中会过滤掉分布不同且注释准则未对齐的实例.
最近, 论文(Neural adaptation layers for cross-domain named entity recognition) 通过引入三个神经适应层(单词, 句子, 输出适应层)为 NER 引入了一种微调方法.
4.3 深度主动学习
主动学习背后的关键思想是,如果允许从机器学习算法中选择学习的数据,则机器学习算法的性能将大大降低。 深度学习通常需要大量的训练数据,而这些数据的获取成本很高。 因此,将深度学习与主动学习相结合可以减少数据标注的工作量。
主动学习的训练会进行多轮。但是,传统的主动学习方案对于深度学习而言是昂贵的,因为在每一轮之后,它们都需要使用新标注的样本对分类器进行完全重新训练。由于从头开始进行再训练对于深度学习不切实际,论文(Deep active learning for named entity recognition) 建议对每批新标签进行NER的增量训练。他们将新标记的样本与现有样本混合,并在新一轮查询标签之前为少数几个 epoch 更新神经网络权重。具体而言,在每轮开始时,主动学习算法将要标注的句子选择为预定义的 budget。在接收到选定的标记后,通过对扩充数据集进行训练来更新模型参数。序列标记模型由CNN字符级编码器,CNN 词级编码器和LSTM标签解码器组成。主动学习算法在选择要标记的句子时采用不确定性采样策略。也就是说,未标记的示例会根据当前模型在预测相应标签时的不确定性进行排序。在他们的模型中实现了三种排序方法:最低置信度(LC),最大归一化对数概率(MNLP)和贝叶斯主动学习异议(Bayesian Active Learning by Disagreement)(BALD)。实验结果表明,主动学习算法仅使用英语数据集中的 24.9% 的训练数据和中文数据集中的 30.1% 的训练数据,即可获得在完整数据上训练的最佳深度学习模型的99%的性能。此外,训练数据的 12.0%和 16.9% 足以使深度主动学习模型优于在完整训练数据上学习的浅层模型。
4.4 深度强化学习
强化学习(RL)是受行为主义心理学启发的机器学习的一个分支,它与 agents 如何在环境中采取行动以最大程度地累积一些奖励有关。该想法的核心思想为, agents 通过与环境互动并从行为中获得回报来从环境中学习。
具体而言,RL问题可以表述为:将环境建模为具有输入(来自 agents 的动作)和输出(对 agents 的观察和奖励)的随机有限状态机。它由三个关键部分组成:
- 状态转换功能
- 观察(即输出) 功能
- 奖励功能
agents 还被建模为具有输入(来自环境的观察/奖励)和输出(对环境的作用)的随机有限状态机。它由两个部分组成:
- 状态转换功能和
- 策略/输出功能
agents 的最终目标是通过尝试使累积奖励最大化来学习良好的状态更新功能和策略。
论文(Improving information extraction by acquiring external evidence with reinforcement learning) 将信息提取任务建模为马尔科夫决策过程(MDP)该过程动态的使用了实体预测任务, 并提供了一组自动生成的替代方案中选择下一个 query 的方法. 模型流程包含从 发出搜索查询, 从新来源中提取, 识别获得的特征, 然后重复该过程知道获得足够多的的证据(evidence)为止.
4.5 NER 中的深度对抗学习
对抗学习是在对抗样本上进行学习的模型. 期望模型通过这种方式更加健壮,同时在无干扰时减少测试误差. 对抗网络通过两个网络游戏的形式从训练分布中产生: 一个网络生成候选实例(生成网络), 另一个评估候选(判别网络). 通常情况下, 生成网络学习潜变量空间映射到目标空间的特定数据分布, 而判别网络则在生成模型生成的数据与真实数据之间进行区分.
论文(Datnet: Dual adversarial transfer for low-resource named entity recognition) 提出双重对抗迁移网络(Dual adversarial transfer network, DATNet), 目的是解决在 NER 中的资源匮乏问题. 作者通过在原始样本上加一个小扰动制备对抗样本. 对分类器进行真实样本和对抗样本的混合训练以提高泛化性. 实验结果表明, 将知识从大数据集到小数据集上的有效性.
4.6 Neural Attention
神经网络中的注意力机制大致基于人类发现的视觉注意力机制。 例如,人们通常以“高分辨率”聚焦于图像的某个区域,而以“低分辨率”感知周围的区域。 神经注意机制使神经网络能够专注于其输入的子集。
通过应用注意力机制,NER模型可以捕获输入中信息最多的元素。 特别是前面介绍的 Transformer 体系结构完全依赖于注意力机制来绘制输入和输出之间的全局依赖关系。
论文(Attending to characters in neural sequence labeling models) 应用注意力机制来动态的决定在端到端的 NER 模型中, 需要从字符或者词级别的表示中使用多少信息.
论文(Neural named entity recognition using a selfattention mechanism) 尝试将 self-atention 应用在 NER 中.
论文(Improving clinical named entity recognition with global neural attention) 提出了一种基于注意力的 NER 模型, 该模型从采用注意力的预训练双向语言模型表示的文档内获得文档级的信息.
5. 展望与挑战
5.1 难点
5.1.1 数据标注
主要问题是数据标注的 质量与一致性问题. 如 “帝国州” 和 “帝国州建筑物” 都被标记为 “位置”, 就会导致实体边界混乱.
除此之外 , 实体嵌套(nested)的情况也是广泛存在的. 如 GENIA 语料库中有 17% 的实体被嵌套到另一个实体中. 在 ACE 语料中, 有 30% 的句子包含嵌套的命名实体. 因此需要开发通用的标注方案来处理嵌套实体和 fine-grained 实体(一个命名实体可以被分配多个类型).
5.1.2 非正式文本和新实体
前面总结的评测表现大都是基于正式文档(新闻报道)的, 但在用户生成的文本(如 WUT-17)上, 最佳的 F值仅略高于 0.4 . 非正式文本(如推文, 用户评论, 论坛帖子) 的 NER 由于其内容简短, 噪声大, 因此比正式文本更难处理.
除了文本表达不正式外, 训练集中没有出现过的新实体也是个问题, 尽管深度学习在一定程度上可以处理些没见过的实体, 但面对每天生成的大量新实体, 依旧是一个挑战.
5.2 展望
论文给出了一些探索的方向
- 细粒度的 NER 以及边界检测
- 实体连接和 NER 的联合模型: 实体链接(EL), 也称为命名实体消岐或标准化, 用于确定给定 mention 与知识库中那个实体匹配. 例如, 通用领域的 Wikipedia 和统一医学语言系统(UMLS). 现有的大多数研究都将 NER 和实体链接视为两个独立任务. 我们认为,成功链接的实体(例如,通过知识库中的相关实体)所携带的语义得到了显着丰富。 也就是说,链接的实体有助于成功检测实体边界和正确分类实体类型。 值得探索的方法是联合执行 NER 和 EL , 甚至进行实体边界检测,实体类型分类和实体链接,以便每个子任务都受益于其他子任务的部分输出,并减轻独立做带来的不可避免的错误传播。
- 带有辅助资源的, 基于深度学习的非正式文本 NER
- 模型扩展性: 使神经NER模型更具可扩展性仍然是一个挑战。 此外,仍然需要一种解决方案,以在数据大小增长时优化参数的指数增长. 一些基于DL的NER模型已经以大量计算能力为代价获得了良好的性能。 例如,ELMo表示表示使用3×1024维向量表示每个单词,并且在32个GPU上对模型进行了5周的训练[106]。 Google BERT表示形式已在64个云TPU上进行了训练。 但是,如果最终用户无法访问强大的计算资源,则无法微调这些模型。 开发平衡模型复杂性和可伸缩性的方法将是一个有希望的方向。 另一方面,模型压缩和修剪技术也是减少模型学习所需空间和计算时间的选择。
- 将迁移学习进一步应用到 NER 中
- 基于深度学习的 NER 易用工具包
6. 推荐论文
[1] A survey of named entity recognition and classification
[2] Natural language processing (almost) from scratch
[3] Bidirectional lstm-crf models for sequence tagging
[4] Neural architectures for named entity recognition
[5] Named entity recognition with bidirectional lstm-cnns
[6] Semisupervised sequence tagging with bidirectional language models
[7] Deep active learning for named entity recognition
[8] Toward mention detection robustness with recurrent neural networks
[9] Joint extraction of entities and relations based on a novel tagging scheme
[10] Fast and accurate entity recognition with iterated dilated convolutions
[11] Neural models for sequence chunking
[12] Joint extraction of multiple relations and entities by using a hybrid neural network
[13] End-to-end sequence labeling via bidirectional lstm-cnns-crf
[14] Leveraging linguistic structures for named entity recognition with bidirectional recursive neural networks
[15] Named entity recognition with stack residual lstm and trainable bias decoding
[16] Neural reranking for named entity recognition
[17] Deep contextualized word representations
[18] Attending to characters in neural sequence labeling models
[19] Multi-task cross-lingual sequence tagging from scratch
[20] Robust lexical features for improved neural network named-entity recognition
[21] Disease named entity recognition by combining conditional random fields and bidirectional recurrent
[22] Multi-channel bilstm-crf model for emerging named entity recognition in social media
[23] A multitask approach for named entity recognition in social media data
[24] Bert: Pretraining of deep bidirectional transformers for language understanding
[25] Named entity recognition in chinese clinical text using deep neural network
[26] Semi-supervised multitask learning for sequence labeling
[27] Efficient contextualized representation: Language model pruning for sequence labeling
[28] Empower sequence labeling with task-aware neural language model
[29] Multi-task domain adaptation for sequence tagging
[30] Segment-level sequence modeling using gated recursive semi-markov conditional random fields
[31] Hybrid semi-markov crf for neural sequence labeling
[32] Transfer joint embedding for crossdomain named entity recognition
[33] Transfer learning for sequence tagging with hierarchical recurrent networks
[34] Transfer learning and sentence level features for named entity recognition on tweets
[35] Improve neural entity recognition via multi-task data selection and constrained decoding
[36] Neural named entity recognition using a selfattention mechanism
[37] Improving clinical named entity recognition with global neural attention
参考博客:
【1】http://pelhans.com/2019/09/23/kg_paper-note4/#%E6%8C%87%E9%92%88%E7%BD%91%E7%BB%9C