DiSAN: Directional Self-Attention Network forRNN/CNN-Free Language Understanding 笔记
目录
Abstract
Introduction
Background
2.1 Sentence Encoding
2.2 Attention
2.3 Self-Attention
3 Two Proposed Attention Mechanisms
3.1 Multi-dimensional Attention
3.2 Two types of Multi-dimensional Self-attention
3.3 Directional Self-Attention
4 Directional Self-Attention Network
论文地址:https://arxiv.org/abs/1709.04696
github大神开源地址:GitHub - taoshen58/DiSAN: Code of Directional Self-Attention Network (DiSAN)
Abstract
RNN 和 CNN 被广泛应用于NLP任务中,分别用于捕获长期依赖和局部依赖。注意机制由于其高度并行的计算、显著减少的训练时间和建模依赖的灵活性,最近引起了人们极大的兴趣。文中提出了一种新的注意机制(Directional Self-Attention Network (DiSAN)),其中来自输入序列的元素之间的注意是方向性的和多维的(即特征方面的)(the attention between elements from input sequence(s) is directional and multi-dimensional (i.e., feature-wise))。DiSAN学习句子embedding,网络仅基于该注意力机制,没有任何RNN/CNN结构。DiSAN仅由时间顺序编码的定向自我注意,然后是将序列压缩为向量表示的多维注意组成(DiSAN is only composed of a directional self-attention with temporal order encoded, followed by a multi-dimensional attention that compresses the sequence into a vector representation.)。尽管形式简单,但DiSAN在预测质量和时间效率方面都优于复杂的RNN模型。它在所有句子编码方法中取得了最佳的测试精度,在Stanford Natural Language Inference(SNLI)数据集上将最近的最佳结果提高了1.02%,并在Stanford Sentiment Treebank(SST)、Multi-Genre natural language inference(MultiNLI)、Sentences Involving Compositional Knowledge (SICK)、客户评论、MPQA、,TREC问题类型分类和Subjectivity(SUBJ)数据集。
Introduction
上下文依赖在语言理解中起着重要作用,为自然语言处理任务提供了重要信息。对于不同的任务和数据,研究人员经常在两种类型的深层神经网络(DNN)之间切换:具有序列结构的递归神经网络(RNN),捕捉长期依赖性(例如,LSTM、GRU),以及卷积神经网络(CNN)其层次结构善于提取局部或位置不变特征。然而,在实践中选择哪种网络是一个开放性的问题,而选择在很大程度上依赖于经验知识。
最近的研究发现,为RNN或CNN配备注意机制可以在大量NLP任务上实现最先进的性能,包括neural machine translation (Bahdanau, Cho, and Bengio 2015; Luong, Pham, and Manning 2015), natural language inference (Liu et al. 2016), conversation generation (Shang, Lu, and Li 2015), question answering (Hermann et al. 2015; Sukhbaatar et al. 2015), machine reading comprehension (Seo et al. 2017), and sentiment analysis (Kokkinos and Potamianos 2017).。attention通过一个隐层计算输入序列中每个元素的分类分布来反映他们的重要性(The attention uses a hidden layer to compute a categorical distribution over elements from the input sequence to reflect their importance weights)。让RNN、CNN达到可变长度的记忆,这样可以通过重要性/相关性选择输入序列中的元素,合并到输出中。与RNN和CNN不同的是,注意力机制被训练来捕获对任务有重要贡献的依赖性,无论序列中元素之间的距离如何。因此,它可以为RNN/CNN建模的距离感知依赖提供补充信息。此外,计算注意力只需要矩阵乘法,与RNN的顺序计算相比,矩阵乘法具有高度的并行性。
与RNN/CNN相比,注意机制在序列长度上具有更大的灵活性,并且在建模依赖关系时更为任务/数据驱动。与顺序模型不同,它的计算可以通过现有的分布式/并行计算方案轻松而显著地加速。然而,据我们所知,除了NMT之外,还没有为其他NLP任务设计完全基于注意力的神经网络,尤其是那些不能转换成seq2seq问题的任务。与RNN相比,大多数注意机制的缺点是丢失了时间顺序信息,但这可能对任务很重要。这解释了为什么在Transformer中的注意力处理之前,位置编码会应用于序列。如何在注意中建模顺序信息仍然是一个开放性的问题。
本文的目标是开发一个统一的、不使用RNN/CNN的attention网络,该网络可用于为不同NLP任务的句子编码并应用于natural language inference, sentiment analysis, sentence classification and semantic relatedness等不同NLP任务。我们关注sentence encoding模型,因为它是NLP文献中使用的大多数DNN的基本模块。
我们提出了一种新的注意机制,不同于以往的注意机制。1)多维的:来自源的每对元素是一个向量,其中每个条目是对每个特征计算的注意;2)方向性:它使用一个或多个位置masks来建模两个元素之间的不对称注意。我们计算特征方面的attention,因为序列中的每个元素通常由一个向量表示,例如word/character embedding(Kim et al.2016),不同特征上的atention可以包含不同的依赖性信息,从而处理同一单词周围上下文的变化。我们将位置掩码应用于注意分布,因为它们可以很容易地编码先验结构知识,如时序和依赖解析。这种设计缓解了在建模序信息时注意力机制不足的缺点,并充分利用了并行计算。
在DiSAN中,输入序列由 directional(向前和向后)self-attentions模块处理,以建立上下文依赖关系模型,并为所有tokens生成上下文感知表示。然后,多维注意力计算整个序列的向量表示,该向量表示可以传递到分类/回归模块,以计算特定任务的最终预测。与Transformer不同,不需要堆叠注意块,也不需要编码器-解码器结构。DiSAN结构简单,参数少,计算量少,易于并行化。
In experiments1, we compare DiSAN with the currently popular methods on various NLP tasks, e.g., natural language inference, sentiment analysis, sentence classification, etc. DiSAN achieves the highest test accuracy on the Stanford Natural Language Inference (SNLI) dataset among sentence-encoding models and improves the currently best result by 1.02%. It also shows the state-of-the-art performance on the Stanford Sentiment Treebank (SST), MultiGenre natural language inference (MultiNLI), SICK, Customer Review, MPQA, SUBJ and TREC question-type classification datasets. 同时,它表现优于诸如LSTM和基于树等的模型(如)相比,且它的参数更少,计算效率更高。
Background
2.1 Sentence Encoding
在NLP任务管道中,一个句子由一系列离散标记(例如单词或字符)表示:![]() ,
, 可以是one-hot向量,其维度是distinct tokens的个数N。用预训练的token embedding(例如 word2vec、GloVe)将
可以是one-hot向量,其维度是distinct tokens的个数N。用预训练的token embedding(例如 word2vec、GloVe)将![]() 由离散的tokens预处理成低维稠密的向量表示:
由离散的tokens预处理成低维稠密的向量表示:![\textbf{\textit{x}}=[x_{1}, x_{2}, \cdots, x_{n}]](http://img.e-com-net.com/image/info8/87dab681d68643f3bf5741f9c4c7d141.gif) ,其中
,其中![]() ,这一过程可以看成:
,这一过程可以看成: ![]() ,其中
,其中![]() 。
。
大多数用于NLP任务的DNN句子编码模型都以![]() 为输入,并通过上下文融合为每个
为输入,并通过上下文融合为每个 生成向量表示
生成向量表示 。然后序列
。然后序列![]() 映射成单一向量
映射成单一向量![]() ,该向量即是句子向量,在NLP任务中被用作整个句子的compact embedding。
,该向量即是句子向量,在NLP任务中被用作整个句子的compact embedding。
2.2 Attention
注意力机制用于计算两个源中元素的对齐分数。特别的,给定源序列的token embeddings 以及 query 的 向量表示q。注意力机制通过函数![]() 来计算和
来计算和 的分数。对这n个得分使用softmax函数,将其转换成概率分布
的分数。对这n个得分使用softmax函数,将其转换成概率分布![]() ,这里的
,这里的 可以用来表示
可以用来表示![]() 的各token在该任务下对q的贡献度。大的
的各token在该任务下对q的贡献度。大的![]() 表示对更重要。上述过程用公式表示为:
表示对更重要。上述过程用公式表示为:
![]()
写成一个公式:
![]()
该注意力机制的输出是![]() 中所有tokens 的 embeddings的加权和,权重由
中所有tokens 的 embeddings的加权和,权重由![]() 给出。在对q重要的token上给出大的权重。并且可以理解为根据token重要性采样的期望:
给出。在对q重要的token上给出大的权重。并且可以理解为根据token重要性采样的期望:

其中![]() 可以看成
可以看成![]() 的句子编码。
的句子编码。
Additive attention (or multi-layer perceptron attention) and multiplicative attention是两种最常用的注意机制。其区别在函数![]() 上。
上。
加法注意力机制Additive attention:
![]()
其中![]() 是激活函数,
是激活函数,![]() 。
。
乘法注意使用内积或余弦相似性作为函数![]()

在实际应用中,加法注意力机制在预测质量上往往优于乘法注意力机制,但后者由于优化了矩阵乘法,速度更快,存储效率更高。
2.3 Self-Attention
self-attention是上述注意机制的一个特例。它用从源输入token 的embedding  的替换q。它通过计算每对token 和 之间的attention,将单个序列中不同位置的元素关联起来。对于长期依赖和局部依赖,它都非常有表现力和灵活性,过去分别由RNN和CNN建模这些依赖。此外,它比RNN具有更快的计算速度和更少的参数。在最近的工作中,我们已经见证了其在各种NLP任务中的成功,如reading comprehension 和 neural machine translation。
的替换q。它通过计算每对token 和 之间的attention,将单个序列中不同位置的元素关联起来。对于长期依赖和局部依赖,它都非常有表现力和灵活性,过去分别由RNN和CNN建模这些依赖。此外,它比RNN具有更快的计算速度和更少的参数。在最近的工作中,我们已经见证了其在各种NLP任务中的成功,如reading comprehension 和 neural machine translation。
3 Two Proposed Attention Mechanisms
在本节中,我们介绍两种新的注意机制,第3.1节中的多维注意力机制multi-dimensional attention(第3.2节中有两种self-attention的扩展)和第3.3节中的directional self-attention。它们是DiSAN的主要组成部分。
3.1 Multi-dimensional Attention
Multi-dimensional attention是对加法注意力机制(或MLP attention)的一种自然而然的延伸。将公式5中为每一个token计算一个标量分数替换成了计算向量分数,将5中的向量 替换成矩阵
替换成矩阵![]() 就ok啦。
就ok啦。
![]()
其中,![]() 是与维度相同的向量,所有矩阵的维度均一致
是与维度相同的向量,所有矩阵的维度均一致![]() 。
。![]() 是激活函数。然后我们再加上偏置:
是激活函数。然后我们再加上偏置:
![]()
对这n个tokens的每个维度![]() 计算一个分布分布
计算一个分布分布![]() ,大的
,大的![]() 表示token i 的第k个维度对更重要。
表示token i 的第k个维度对更重要。
对![]() 的
的![]() 维使用公式(1)-(3),对于每个维度
维使用公式(1)-(3),对于每个维度![]() ,将
,将![]() 替换为
替换为![]() ,以及将替换为
,以及将替换为 ,对于token i的每个维度k有重要性
,对于token i的每个维度k有重要性![]() ,则输出s表示如下:
,则输出s表示如下:
![s = [\sum_{i=1}^{n}P_{ki}\textit{\textbf{x}}_{ki}]_{k=1}^{d_{e}}=[\mathbb{E}_{i \sim p(z_{k}|\textbf{\textit{x}},q)}(\textit{\textbf{x}}_{ki})]_{k=1}^{d_{e}} \ \ \ \ \ \ (9)](http://img.e-com-net.com/image/info8/ec2087579d7d43aeaef996739b948220.gif)
我们在图1中举例说明了traditional attention和 Multi-dimensional attention。在其余部分中,如果不存在混淆,将忽略索引特征维度的下标k,以进行简化。因此,输出s可以写为element-wise product: 
注:word embedding在自然语言中通常存在多义现象。由于传统的注意力机制基于单词嵌入计算每个单词的单一重要性分数,因此无法区分同一单词在不同上下文中的含义。然而,多维注意力为每个单词的每个特征计算分数,因此它可以选择在任何给定上下文中最能描述单词特定含义的特征,并将此信息包含在句子编码输出中( Multi-dimensional attention, however, computes a score for each feature of each word, so it can select the features that can best describe the word’s specific meaning in any given context, and include this information in the sentence encoding output s)。

3.2 Two types of Multi-dimensional Self-attention
第一个是 multi-dimensional “token2token” self-attention,探索来自同一源![]() 的和之间的依赖关系,并为每个元素生成上下文感知编码。将公式8中的q替换成
的和之间的依赖关系,并为每个元素生成上下文感知编码。将公式8中的q替换成
![]()
与普通多维注意力机制中的P相似,我们计算了一个概率矩阵![]() ,对于每一个有
,对于每一个有![]() ,则对于的输出
,则对于的输出

![]() 中的所有token的multi-dimensional “token2token” self-attention输出是,
中的所有token的multi-dimensional “token2token” self-attention输出是,![]()
第二种是,multi-dimensional “source2token” selfattention,探索与整个序列![]() 之间的依赖关系,并将序列
之间的依赖关系,并将序列![]() 压缩为向量。将公式8中的q移除:
压缩为向量。将公式8中的q移除:
![]()
概率矩阵![]() ,计算方法与普通多维注意力机制中的P相同,输出表示也一样,
,计算方法与普通多维注意力机制中的P相同,输出表示也一样,
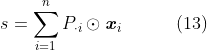
我们将在句子编码模型DiSAN的不同部分使用这两种类型(即token2token和source2token)的multi-dimensional self-attention。
3.3 Directional Self-Attention
Directional self-attention (DiSA) (DiSA)由一个全连接组成,该层的输入是token的embedding矩阵![]() ,一个“masked”的multi-dimensional token2token self-attention 块,用于探索依赖性和时序,以及一个融合门,用于组合attention的输出和输入。其结构如图2所示。它既可以用作神经网络,也可以用作组成大型网络的模块。
,一个“masked”的multi-dimensional token2token self-attention 块,用于探索依赖性和时序,以及一个融合门,用于组合attention的输出和输入。其结构如图2所示。它既可以用作神经网络,也可以用作组成大型网络的模块。
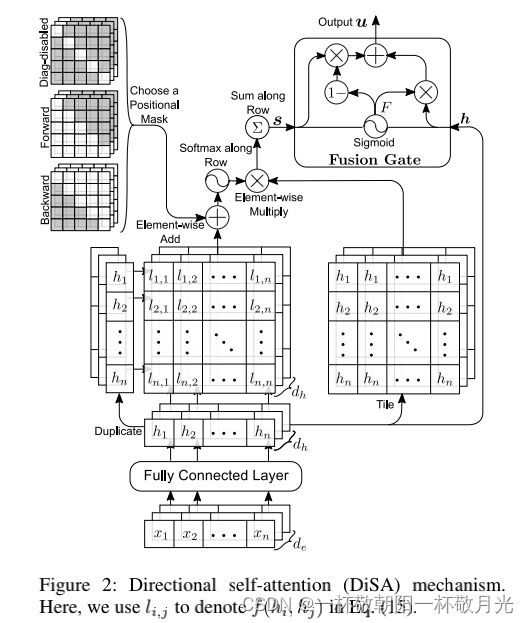
在DiSA中先将输入序列过全连接层转换成序列![]()
![]()
其中![]() 均是可学习的,
均是可学习的,![]() 是激活函数。
是激活函数。
然后,我们将multi-dimensional token2token self-attention应用于![]() ,并为输入序列中的所有元素生成上下文感知向量表示
,并为输入序列中的所有元素生成上下文感知向量表示![]() 。我们对公式(10)进行了两处改动,以减少参数的数量并使注意力具有方向性。
。我们对公式(10)进行了两处改动,以减少参数的数量并使注意力具有方向性。
首先,将公式10的![]() 矩阵替换成标量
矩阵替换成标量 ,并在激活函数
,并在激活函数 内部除以,激活函数使用双曲正切
内部除以,激活函数使用双曲正切![]() ,以减少参数的数量。在实验中,设置
,以减少参数的数量。在实验中,设置![]() 并获得了稳定的输出。
并获得了稳定的输出。
第二,向公式10引入 positional mask,这样,两个元素之间的attention可以是非对称的。给定mask  ,设置b是常量向量
,设置b是常量向量![]() ,
,![]() 表示元素全为1的向量。
表示元素全为1的向量。
经两处改动后,公式10变成
![]()
为什么masked可以编码方向信息,我们考虑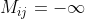 和
和![]() ,这会使得
,这会使得![]() ,且不改变
,且不改变![]() ,且套上一层softmax得到概率
,且套上一层softmax得到概率![]() ,
,![]() 过softmax会有
过softmax会有![]() ,这意味着和的第k维没有注意力得分。相反,我们有
,这意味着和的第k维没有注意力得分。相反,我们有![]() ,这意味着和的第k维存在注意力得分。因此,时间顺序和依赖关系等先验结构知识可以很容易地通过掩码(mask)进行编码,并在生成句子编码时进行探索。这是DiSA的一个重要特征,是以前的注意机制所没有的。
,这意味着和的第k维存在注意力得分。因此,时间顺序和依赖关系等先验结构知识可以很容易地通过掩码(mask)进行编码,并在生成句子编码时进行探索。这是DiSA的一个重要特征,是以前的注意机制所没有的。
对于self-attention,我们通常需要禁用每个token对自身的注意力得分。可以用下面的掩码矩阵,对角线元素是负无穷,其余均为0,经过softmax,对角线分数为0(即每个token对自身的注意力得分为0),非对角线分数>0。
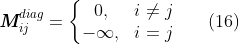
此外,我们可以使用掩码将时序信息编码。在本文中,我们使用了两个掩码,前向掩码![]() ,后向掩码
,后向掩码![]()
![]()
![]()
在前向掩码![]() 中,后面的token j只关注早期的token i,后向掩码则相反。我们在图3中显示了这三个位置掩码。
中,后面的token j只关注早期的token i,后向掩码则相反。我们在图3中显示了这三个位置掩码。

给定输入序列![]() 和掩码
和掩码![]() ,就可以按公式15计算啦。按照multi-dimensional “token2token” self-attention为每个
,就可以按公式15计算啦。按照multi-dimensional “token2token” self-attention为每个![]() 计算概率
计算概率![]() ,按照公式11计算
,按照公式11计算![]() 中的每一个
中的每一个 。
。
DiSA的最终输出![]() 是masked multi-dimensional token2token self-attention 网络的输入
是masked multi-dimensional token2token self-attention 网络的输入![]() 和输出
和输出![]() 的组合。这将为每个元素/标记生成时序编码和上下文感知的向量表示。这种组合是通过一个按元素的融合门来完成的,即:
的组合。这将为每个元素/标记生成时序编码和上下文感知的向量表示。这种组合是通过一个按元素的融合门来完成的,即:
其中![]() ,
,![]()
4 Directional Self-Attention Network
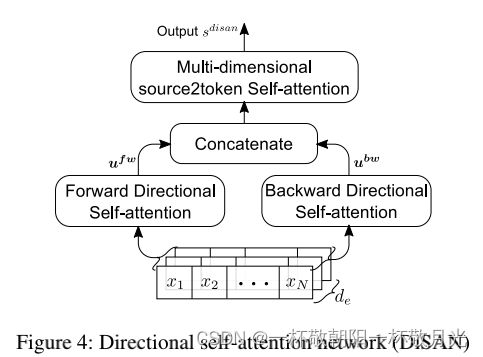
DiSAN的结构如图4。
给定token embedding的输入序列![]() ,DiSAN首先应用两个参数联合DiSA块,分别使用前向掩码矩阵
,DiSAN首先应用两个参数联合DiSA块,分别使用前向掩码矩阵![]() 和后向掩码矩阵
和后向掩码矩阵![]() ,使用到公式14、15、19、20。输出用
,使用到公式14、15、19、20。输出用![]() 表示。将他俩拼接成
表示。将他俩拼接成![]() ,将拼接后的向量作为multi-dimensional “source2token” selfattention的输入,由公式12和公式13得到最终的句子编码
,将拼接后的向量作为multi-dimensional “source2token” selfattention的输入,由公式12和公式13得到最终的句子编码 。
。
注:在DiSAN中,前向/后向DiSA块用作上下文融合层。multi-dimensional “source2token” selfattention将序列压缩为一个向量。双向LSTM启发了同时使用前向和后向注意的想法,其中前向和后向LSTM用于编码来自不同方向的长期依赖性。在Bi-LSTM中,LSTM将上下文感知输出与多门输入相结合(combines the context-aware output with the input by multi-gate)。DiSA中使用的融合门具有类似的动机。然而,DiSAN具有参数少、结构简单、效率高等优点。