Pyflink系列之使用pyflink实现flink大数据引挚的经典案例wordcount
Pyflink系列之使用pyflink实现flink大数据引挚的经典案例wordcount
谈到大数据,也是数据,在专业的概念上来讲,其具备三大特征。
1、数据量足够大,也就是Volume值相当特别地多。
2、数据访问并发量足够高并且实时,可以用Velocity一词反映快速和实时。
3、数据的类型越来越多,可以用Variety一词来反映数据的多样性。
对于大数据的处理思路,普遍都是建立在通过把数据进行分区分片,并分布到各个横向扩展节点,并由调度节点进行统一管理计算。每一次你执行查询的时候,该查询会被分解为多个子查询并交付给每一个计算节点去做并行的查询。
大数据最关键的技术难题在于计算问题,在计算引挚方面大数据经历了四代的计算引挚演化。
一、 计算引挚的演化
1、 第一代计算引挚MapReduce.
MapReduce计算引挚阶段,使用场景用于离线计算。MapReduce处理数据主要分为两个阶段:map和reduce。
Map阶段的任务包括文件的加载、切分等;对切片数据调用用户实现的map函数方法进行处理,每个map都有一个环形缓冲区,用于存储map的输出。这个环形缓冲区的默认大小为100MB,一旦数据达到设定的阈值,一般80%,会有一个后台线程将内容溢写到磁盘的指定目录一个新建的文件中。这里的输出内容被溢写出去后形成一个个文件,首先将这些文件进行分区排序形成排序后的文件,再为每个不同的分区进行简单的combiner聚合操作。具体流程如下图所示。
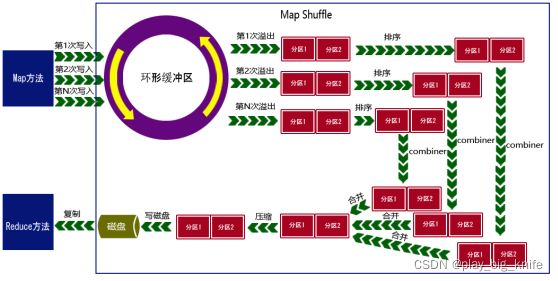
Reduce阶段是从Map阶段输出的结果文件中拉取属于自己要处理的数据,针对属于自己的那一片数据,如果大小超过一定的阀值,则写到磁盘上,否则直接放在内存中。根椐key对这些数据进行分组排序,根据每一组的kv值来调用用户实现的reduce方法进行处现的reduce方法进行处理,将结果输出到磁盘上。如下图所示。
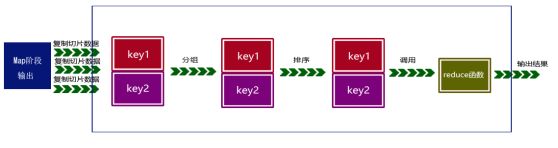
在Map和reduce阶段,涉及到数据缓存、分区、排序、分发存储等过程称之为shuffle。
MapReduce虽然解决了大数据可以计算的问题,但它的速度不够快,一个MapReduce任务通常需要秒级别甚至分钟级别才能跑完。这个速度对于离线计算场景还能接受,但对于目前市场的变化,实时计算的需求场景来说显然太慢了。
第二代:任务的DAG(Tez, Oozie)
第二代计算引擎其实还是个MapReduce,只不过对MapReduce的任务调度过程进行了优化。
对于复杂算法来说,通过一个MapReduce过程无法实现,需要拆分成多个Job串联运行。在MR框架里,Job是最小的调度单位,不同Job彼此独立运行。后一个Job必须等前一个Job跑完才能开始。单个Job本身运行就慢,多个Job串联跑完就更慢了。这种开发效率很难被接受。
三、第三代Spark
第三代spark在计算方面,Spark不需要将计算的中间结果写入磁盘,这得益于Spark的RDD(弹性分布式数据集)和DAG(有向无环图),前者是Spark中引入的一种只读的、可扩展的数据结构,后者则记录了job的stage以及在job执行过程中父RDD和子RDD之间的依赖关系。
同时在任务调度方面,Hadoop的MapReduce是针对大文件的批处理而设计的,延迟较高;Hadoop的MapReduce的Map Task和Reduce Task都是进程级别的,而Spark Task则是基于线程模型的;Spark通过复用线程池中的线程来减少启动、关闭task所需要的开销。
在数据格式和内存布局方面,Spark RDD能支持粗粒度写操作,对于读操作则可以精确到每条record,因此RDD可以用来作为分布式索引。
在执行策略方面,Spark和MapReduce的shuffle过程也有很大差异,Spark在shuffle时只有部分场景才需要排序,支持基于Hash的分布式聚合,更加省时。
第三代spark具备了流批处理的能力,不过其流处理的能力可以概括为微批处理,spark 引擎会定期检查是否有新数据到达,然后开启一个新的批次进行处理。Spark微批理的时间是500ms,并没有真正意义上实现了实时的流处理,而且这种微批处理的时间也存在着延迟,一般处理12:00的数据有可能延迟2小时后才能进行分析,没有达到真正意义上的实时。
第四代flink
Flink是面向连续流设计的计算引擎。在Flink中,一切都是流,数据流是Flink基本处理模型。Flink从设计之初秉持了一个观点:批是流的特例(批是一种有边界的数据流),它的批处理也是通过流来模拟实现的。
Flink的强悍之处,阿里屡试不爽。阿里当时的实时计算峰值达到了破纪录的每秒40亿条记录,数据量也达到了惊人的7TB每秒,相当于一秒钟需要读完500万本《新华字典》
Flink真正意义实现了大数据处理的流批统一模式。如下图所示。
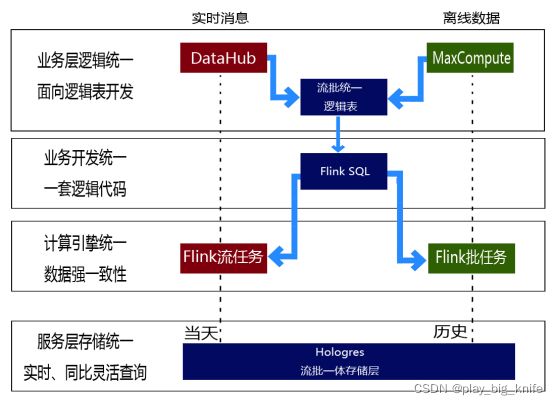
在Flink的流执行模式中,事件在一个节点上处理后的输出可以发送到下一个节点进行即时处理,这样,执行引擎就不会有任何的延迟。相应地,所有的节点都需要同时运行。
二、为什么要使用fink
Flink实现了真正意义上的流批统一。
Flink的流处理,延迟到了毫秒级,而之前的spark在流处理上只是微批,延迟在秒级。
Flink可以处理事件时间,而之前的spark在streaming方面因为延迟,只能处理机器时间,无法保证时间语义的正确性。
Flink的检查点算法比Spark streaming更加灵活,性能更高。Spark streaming的检查点算法是每个stage结束之后,才会保存检查点。
Flink更易实现端到端的一致性。
三、python搭建pyflink环境
入门flink最简单的语言是python,这里使用python来搭建pyflink环境,pyflink是处理大数据flink程序的模块。
1、安装jdk
现在JDK10都出来了,所以我们也要紧跟着技术的潮流走,JDK8现在肯定已经比以前成熟很多了,所有我们在这里采用的就是JDK8。首先我们得在官网上面先下载JDK8。如下图所示。
找到jdk8压缩包下载后,进行解压命令,将压缩包进行解压,解压命令如下:
tar zxvf 压缩包名称
例如:
tar zxvf jdk-8u152-linux-x64.tar.gz
也可以将压缩包压缩到指定的文件夹下。如
tar zxvf 压缩包名称 -C 文件路径
例如:
tar zxvf jdk-8u152-linux-x64.tar.gz –C /usr/java
完成之后,可以执行删除命令删除压缩包。删除命令如下。
rm -f 压缩包名称
例如
rm -f jdk-8u152-linux-x64.tar.gz
现在进行最重要的一步了,成不成功就看这一步了!
要进行环境配置了,编辑命令:
vi /etc/profile
在执行完上方命令之后点击i键位让文件可以修改,进行文件编写。
修改内容如下。
export JAVA_HOME=/usr/java/jdk1.8.0_152
export PATH=$PATH:$JAVA_HOME/bin
对于/etc/profile编写完成之后是不够的,还需要最后一个步骤,就是让刚刚我们修改的文件变成有效起来,所以我们再输入一个命令,让修改生效。
生效命令。
source /etc/profile
2、安装MAVEN
在Centos中没有自带安装Maven,需要手动安装Maven。直接使用如下指令下载maven即可,下载位置为当前目录:
wget https://archive.apache.org/dist/maven/maven-3/3.2.5/binaries/apache-maven-3.2.5bin.tar.gz
下载完成之后,解压并安装:
tar zxvf apache-maven-3.2.5-bin.tar.gz
修改文件名:
sudo mv apache-maven-3.2.5 maven
配置环境变量:
vim /etc/profile
将下面代码加入到profile中:
export MAVEN_HOME=/usr/local/maven
export PATH=$JAVA_HOME/bin:$MAVEN_HOME/bin:$PATH
加入代码后,仍然需要重新加载系统配置文件:
source /etc/profile
3、安装flink
首先需要下载源代码:
git clone https://github.com/apache/flink.git
接着拉取1.10的分支:
cd flink/
git fetch origin release-1.10 && git checkout -b release-1.10 origin/release-1.10
修改maven settings的配置,输入以下指令进入setting.xml:
cd /usr/local/maven/conf/
vim settings.xml
进入到setting.xml后,修改镜像配置:
nexus-aliyun
*,!jeecg,!jeecg-snapshots,!mapr-releases
Nexus aliyun
http://maven.aliyun.com/nexus/content/groups/public
mapr-public
mapr-releases
mapr-releases
https://maven.aliyun.com/repository/mapr-public
此处是使用了aliyun提供的镜像仓库。
编译Flink代码。
mvn clean install -DskipTests -Drat.skip=true -Dcheckstyle.skip=true
编译也可以采用。
Mvn clean package –DskipTests=true
这个编译的时间可能会长一些
编译过程中可能会出现下列问题:
如:
[ERROR] Failed to execute goal on project flink-avro-confluent-registry: Could not resolve dependencies for project org.apache.flink:flink-avro-confluent-registry:jar:1.9-SNAPSHOT: Failure to find io.confluent:kafka-schema-registry-client:jar:3.3.1 in http://maven.aliyun.com/nexus/content/groups/public was cached in the local repository, resolution will not be reattempted until the update interval of nexus-aliyun has elapsed or updates are forced -> [Help 1]
解决方案:
下载上述错误提示缺少某个jar包,此时我们使用wget 进行下载:
wget http://packages.confluent.io/maven/io/confluent/kafka-schema-registry-client/3.3.1/kafka-schema-registry-client-3.3.1.jar
下载完成后在你的当前目录会出现一个jar包:

安装这个jar包:
mvn install:install-file -DgroupId=io.confluent -DartifactId=kafka-schema-registry-client -Dversion=3.3.1 -Dpackaging=jar -Dfile=/usr/local/kafka-schema-registry-client-3.3.1.jar
注:这里的/usr/local是我的jar包所在的目录,使用时需要将其改成你的jar包所在的目录,如果安装不成功,重启终端再次安装。
在整个编译过程中,当某些项目编译失败时,可能会是网络问题,再重新编译一次即可。
最终编译成功的界面如下图所示:
如下图所示,编译成功后会在你的目录中出现一个build-target文件:

四、安装pyflink模块
使用python来进行flink的大数据分析,需要命名用到pyflink模块,使用如下指令Java 包囊括进来,再把自己 PyFlink 本身模块的一些 Java 的包和 Python 包打包成一起。命令如下。
cd flink-python
python3 setup.py sdist
注:当python3 setup.py sdist这段命令无法执行时,重启终端再次执行即可。
然后执行下列指令:
cd dist/
如下图所示,此时我们可以看到dist文件夹下有一个可以用于 pip install 的 PyFlink 包:

接下来我们首先检查命令的正确性,在执行之前,我们用 pip3 检查一下 list,命令如下。
pip3 list
其主要是查看一下pyflink模块是否被成功安装。如下图所示。

如图所示,这里并没有apache-flink的包,此时我们要使用如下命令进行安装:
pip install dist/*.tar.gz
注:执行这条指令的时候要退回到上一次文件夹中,不要在dist文件夹中执行这条指令。
执行结果如下图所示:
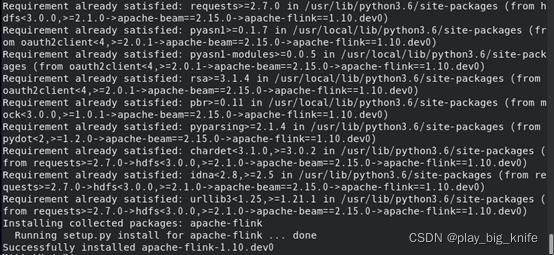
此时再次执行pip3 list的命令,我们就可以发现apache-flink包已经包含在里面了:

安装成功后,就可以使用pyflink进行flink技术实现大数据的分析。
五、pyflink实现wordcount的精典程序
Wordcount程序是大数据中最精典的程序。
其思路如下图所示。

程序思想将输入的input文本,通过map阶段一行一行读取,第一步split按照空格进行单词拆分,通过用户组织的map方法组装(k1,v1)这样的数据形式,shuffle过程按键名进行排序,组合,生成新的(k2,v2)数据形式,最后通过用户组织的reduce方法将集合中的数字相加,得到输出结果。
这样的思路用pyflink模块组织写成的代码如下所示。
from pyflink.table import BatchTableEnvironment, EnvironmentSettings
from pyflink.table import DataTypes
from pyflink.table.descriptors import Schema, OldCsv, FileSystem
env_settings = EnvironmentSettings.new_instance().in_batch_mode().use_blink_planner().build()
t_env = BatchTableEnvironment.create(environment_settings=env_settings)
t_env.connect(FileSystem().path('/tmp/input')) \
.with_format(OldCsv()
.field('word', DataTypes.STRING())) \
.with_schema(Schema()
.field('word', DataTypes.STRING())) \
.create_temporary_table('mySource')
t_env.connect(FileSystem().path('/tmp/output')) \
.with_format(OldCsv()
.field_delimiter('\t')
.field('word', DataTypes.STRING())
.field('count', DataTypes.BIGINT())) \
.with_schema(Schema()
.field('word', DataTypes.STRING())
.field('count', DataTypes.BIGINT())) \
.create_temporary_table('mySink')
t_env.scan('mySource') \
.group_by('word') \
.select('word, count(1)') \
.insert_into('mySink')
t_env.execute("python_job")
程序初始的时候,通过EnvironmentSettings获取flink运行环境的设置,newinstace()方法是设置的一个实例,调用inbatch_mode() 方法进行批处理模式, useblinkplanner()就是使用blink做到了真正的统一,即将批处理来看成特殊的流处理,把处理批的API和处理流的API做成了一样的。build()方法就是flink环境的建立。
接下来使用BatchTableEnvironment类的create()方法来实现flink批处理环境设置的加载。
紧接着connect方法连接文件,文件是使用实例化文件系统FileSystem类后path方法来加载需要进行wordcount统计的文件。由于读取的文件是文本文件,使用withformat初始化文件格式为csv文件,OldCsv().field方法指定输入input方法中的字段格式,由于文件文件中每行只有一个单词,也就是只有一个字段,field指定一个字段'word',并且指定其类型DataTypes.STRING(),也就是STRING类型。再根据字段名称来定义文件schema结构,withschema方法中同样指定field方法,也使用'word'来定义其字段。createtemporarytable('mySource')建立输入文件的模板名称。
定义好输入文件,再定义好输出文件。使用与输入文件一样的思路和方法,将输出结果存到/tmp/output文件中。输出结果中包括两个字段field,'word'和'count'分别表示字母和个数。
当输入和输出都已经定义结束后,scan()方法扫描输入文件 ,模板名称“mySource”,通过groupby方法对输入文件中的word进行分组,分组后通过select方法把单词word通过count计数函数进行统计求和,这类似于flink sql的相关算法,最后通过insertinto输出到输出文件,模板名称“mySink”。
程序最后通过execute执行flink的job任务。
程序设计结束后,就需要启动python语言的flink程序。
首先需要启动flink程序,在编译过的目录下,有一个build-target目录下,再进行bin目录中,就可以启动start-cluster.sh方法。
具体指令如下图。

Fink程序启动后,就可以运行python的flink程序wordcount,具体指令如下:
./flink run –m localhost:8081 –py python的flink程序
执行过程如下图所示。

程序运行结束后,在tmp的output文件中,显示内容如下图所示。

在客户端计算机中,也可以使用web方法查看flink的job执行情况。客户机访问web的地址是:http://192.168.1.108:8081。
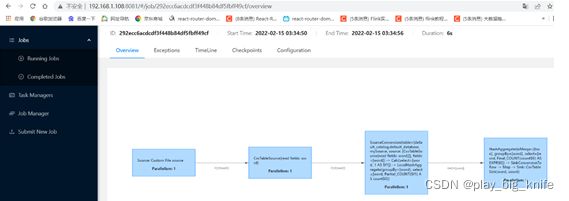
具体执行情况如图所示。

图中flink Dashboard中显示的Available Task slots的任务显示了1个。具体执行情况可以点击左栏的Completed Jobs,可以查看具体的执行情况。

图中显示了处理文件中处理的4步过程。具体过程点击蓝色和黑色的”4”显示如下图所示。
针对于具体的分析过程在后续进行分析,欢迎关注。