【研一小白论文速览2】
Evolving Losses for Unsupervised Video Representation Learning
这篇论文把非监督学习定义成一个多模态,多任务的学习,希望结合不同非监督学习的学习方法来综合学习到一个好的特征。
Intuition
如何构造定义这个unsupervised learning这样一个问题,以及为了达成这样的任务,中间解决了哪些问题?
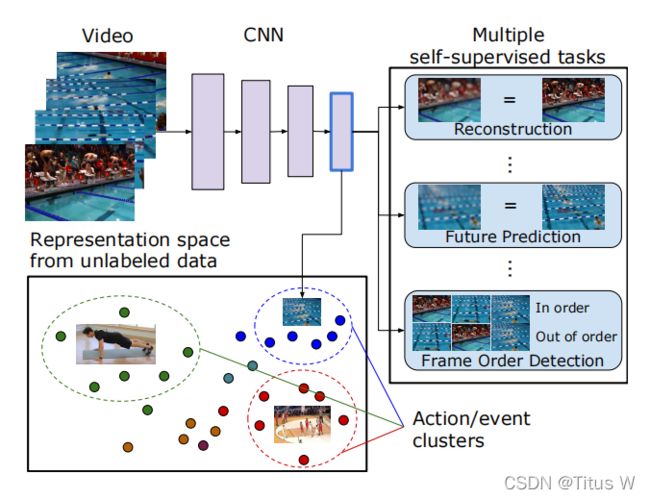
首先本文想要学习到一个好的video representation,那什么样的represention是一个好的video representation呢?这里作者把他定义成了一个Multi modality 和multi tasks这样的任务。其实这是很好理解的,我们人单看这个画面,就可以知道这是一个体育场馆比赛游泳,我们通过这个画面也能自动脑补出会场的声音,以及下几秒伴随着游泳枪响运动员们开始有用,所以这些模态信息,我们人只需要看到一副图片是都可以脑补推导出来的。那么作者就像我能不能训练一个网络,像人一样只需要看到一张图就能想到这么多东西,可以包括未来声音的representation,下一帧图片等等,这样子就能学到一个好的representation,用来解决后续动作识别等等这样的问题。
所以作者把这个问题定义成了molti-modality,比如声音,RGB彩色图像,光流,灰色图像等等等等不同形式。但是这样又会带来另一个问题,那就是我们如果把self-supervised或者说unsupervised这些loss都加到最后一个大的loss function中,对于超参数的调整来说,将是一个灾难:

这里对于每一个modality,每一个task,都需要给他分配一个hyperparameyer来调整这个loss在整个loss function中的权重,这是一个非常闹心的任务,那么于此同时,作者还希望从一帧图像中解出这些所有的信息,我们把从其他网络,从声音网络,从灰度网络,从光流网络,他们这些网络中的这些embedding,这些representation都集成到RGB网络中,其实这是相当于蒸馏的过程。那么这同样也是一堆loss,一堆hyperparameters,那么为了调试这些这么多的hyperparameters,作者就想到能不能使用Evolving loss使用最优化手段,来让计算机帮我们搜寻出一个好的combination来把这些loss组合起来,这个想法是很自然的,但是我们又如何来评估我们得到这个loss的质量呢?当然我们想到的最好的方法是拿这个loss function去训练一个模型,然后再去测试集测试后面的表现不就可以估计出这个loss function的质量了吗?但是我们再学习过程中是不能使用task先验,就是我在学习过程中必须自己能够找到一种方法来评价我当前的模型质量,那么这个也是本文的贡献之一,就是**Evaluate fitness,**解决了这个问题之后,这篇论文的逻辑的链条就串起来了。
就是我在拿到许多视频之后,我们把它变成Multi modality,然后进行multi tasks的unsupervised的,那么这个学习的重点就是找到一个好的loss function,为了找到一个好的loss function,它的本质就是找到一个修改不同hyperparameters来得到这个loss function的fitness,来评价这个loss function的好坏,使其不断进化出一个好的loss fuction。最后拿出最好最后进化的loss function去训练大的模型,训练这个multi-modality,multi tasks这样一个模型。从而获得最终的latent representation。

那么这张流程图呢就是反映了本文定义的multi modality,multi task这样一个任务的过程。如图使用的光流,RGB,视频的声音,把这些不同的modality送到encoder里面,然后使用encoder学到的representation去执行不同的任务,同时呢我们把光流和声音网络学到的信息通过蒸馏的方式蒸馏到中间的RGB的网络中,最终我们就会得到一个强的latent representation而且还包含着其他网络的信息,这个信息就是一个非常强的能够帮助我们进行动作识别的representation。
Self-supervised tasks
Self-supervised tasks包含了哪些任务呢?
Reconstruction and prediction tasks
1.Reconstruc input frame比如我们训练VAE或者Auto-Encoder的时候,输入一个图像然后把它重建出来。
2.Rredict the next N frames given T frames还有就是Prediction,输入T张图像之后使它预测未来的N张图像,这就要求我们的latent representation必须足够抽象,也能够学到视频在时间序列上的相关信息。
3.Cross-modality transfer tasks比如灰度图变彩色图,光流图变彩色图这样的任务。
![]()
以上三个或者总之与Reconstruction and prediction tasks的任务我们都可以使用reconstruct frame与ground truth之间的L2loss,来训练self-supervised task。
Temporal ordering
1.Binary classification of ordered frames and shuffled frames拿出一些帧让网络判断这些frames是否是按照时间序列发展的,这是一个二分类问题。
2.Binary classification of forward and backward videos判断视频是正向播放还是反向播放,那么这也是一个二分类问题。
![]()
第二大任务就是时序上的排序,对于这种二分类问题,我们使用二分类的Cross entropy就可以定义它的loss function。
Multi-modal contrasive loss
1.Different modalities v.s. Different video
在同一视频同一个时刻的modality,他们的latent representation应该尽量接近,对于同一视频不同时刻甚至不同视频他们的latent representation相互远离。
Multi-modal alignment
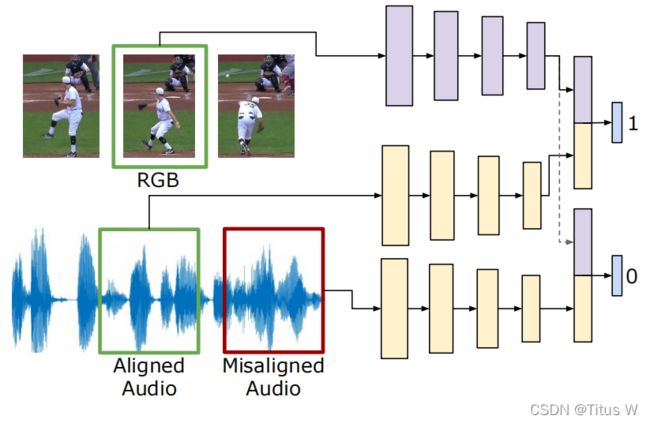
最后一个任务如图,在不同的modality中,我们先采取一段他们在时序上是对齐的样本,同时也采用没有对齐的样本,我们同样的也定义一个二分类问题。
实际上作者在训练中使用了四种modality,分别是RGB,Audio,Flow,Grey。
7种任务,分别是:Shuffle判断input frame是否是按照正常的时序,Colorize就是从RGB modality变到Grey modality,Audio align,Future Prediction,backward detection,distill,embed(相同时刻的embedding相互接近不同时刻的embedding相互远离)。
那么最后经过这些modality和task相互组合,这里作者一共得到了39个self-supervised的任务。
这张图演示了这39个loss,他们的权重,他们的hyperparameters是如何随着进化的次数来逐渐迭代的。
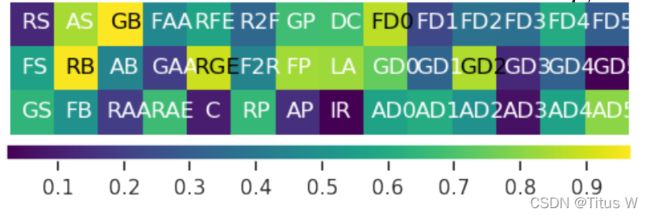
这张图就是作者最后得到的最好的loss function的集合,但是奇怪的是作者列出了42种self-supervised task,多了DC,LA,IR,这个论文种并没有相关的说明。
Evolving loss
那么再解决完self0supervised task之后呢,最后形成的大的loss function,如何来评价这个loss function。这里作者就借用了一个先验知识,他观察所有的数据库,他发现数据库种样本的数量和样本的label其实满足zip distribution,zip distribution简单来讲就是一个类别的数量跟这个类别样本数量的排序rank值成反比,其实就是八二定律,就是最常见的action的samples占了样本中绝大多数samples的数量,剩下的一些不常见的action他们的samples的数量就小很多,那么在知道这样一个先验知识之后呢。如果我们对latent representation进行聚类,对聚类后的每个类别的样本数量做出distribution来,那么这个distribution和zip distribution是非常接近的,那么作者就使用了K-means来找到K个centroids(聚类中心),因为K-maens可以被认定为是混合高斯模型,所以每一个视频属于相应聚类中心的概率就是高斯分布:

根据贝叶斯原理:

每一类的方差都是相同的,这里作者为了简便把他们都设置成1。同时作者假设每一个class的probility都是相等的,也就是这里的pcj,这里通过贝叶斯原理我们就得到了一个形如softmax的probility,都可以通过观测到的样本来推测出采样出来的数据集中每一个class的概率,也就是pci,这个pci在理论上应该同zipf distribution是接近的。那么如何衡量两个distribution的相似度呢?很自然我们就想到KL divergence,也就是说作者最后使用了这么一个KLdivergence就可以描述出latent representation是不是一个好的latent representatuion,进而决定我们选择loss function,当前loss function 的hyperparameter的组合是不是一个好的组合。
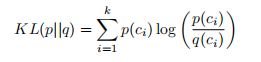
那么得到最后的组合如何进行优化呢?

这里作者列举了像随机搜索啊,网格搜索啊,最后作者发现了CMA-ES,中文名叫协方差矩阵自适应进化策略,这个策略效果是最好的。
Results
这篇论文在三个数据集上分别做了评测,作者设置了三种评价的方法:
1.k-means clustering of therepresentations得到kmeans中心之后呢,使用最近邻就能得到新样本所属 的class。
2.fixing the weights of the network andtraining a single,fully-connected layerfor classification第二种就是固定住前面的latent representation,加一层linear layer,来测试latent representation的表现。
3.fine-tuning the entire network在现在的latent representation上再加linear layer之后再fine-turn网络,那么很显然这三种评价方法是一种比一种效果要好的。

我们看这里对比了一些有监督无监督的一些方法,本文的方法对比其他的unsupervised方法是有大幅度的提高的。
但是作者还介绍了另一种配置,Evolved Loss-E LO-weak计算kmeans一些有标记的样本,这些样本可以帮助我们确定每一个???对于哪一个具体的class,这样呢我们算出来的KLdivergence应该是最准确的KLdivergence,即使没有这样的label,作者提出的方法也能实现与之相称的效果。

本文提出的方法与supervied方法相接近,远超于之前所有unsupervised方法。

那么这里作者还使用多少有label的数据可以达到supervied的结果,那大概接近一半的有label’的数据之后,本文提出的这种unsupervised方法就能够逼近supervised方法。也证明本文提出的方法在data efficiency上还是比较不错的。
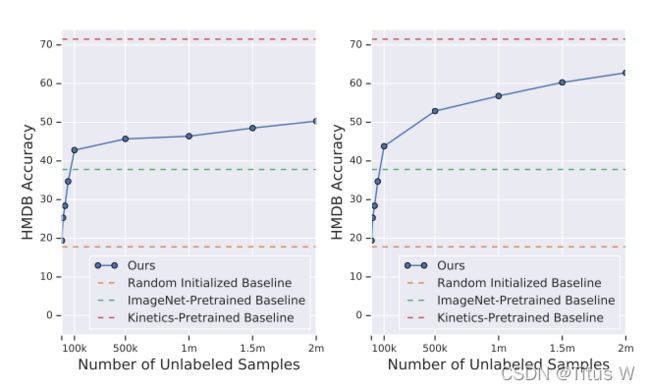
同样作者还做了实验说不同unsipervised data哪怕没有标记的数据只要向里加入无监督的样本,哪怕训练时间固定,那么它依然能获得更好的结果。
Conclusions
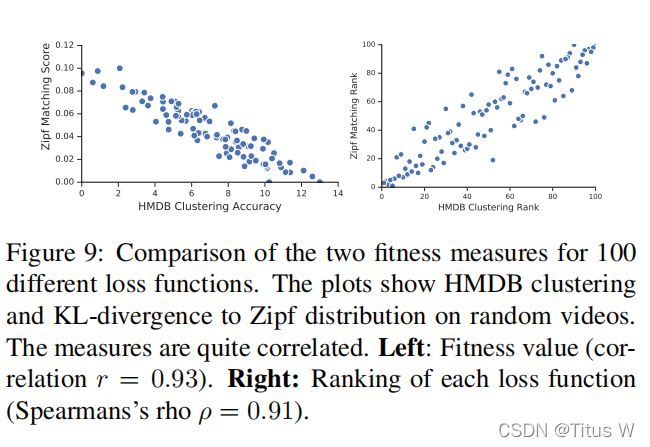
那么除去评价之前的latent representation,作者还想知道我们提出的这个Zipf distribution,KLdivergence这一套东西是不是一个好的评价标准可以用来指导我们的loss function的进化,显然结果是可以的,为了更显示的证明,作者这里对比了100种loss function,使用HMDB这样的有label的数据和Zipf distribution的KLdivergence做对比,发现这两种的fitness value皮尔逊相关系数达到了0.91,说明是一个好的评价方法。
本文有三个创新点:
1.把self-supervised learning或者unsupervised learning定义转换成了一个multimodal,multi-task learning加上network distillntion这样一个问题。
2.为了解决这样的问题,作者使用了Loss function evolution的策略来进化loss function,使解决这个问题变成可能。
3.为了实现这样一个进化,我们使用一个好的evaluation metric,那么这里就是作者提出的计算当前的distribution和Zipf distribution他们之间的KLdivergence来评价lossfunction。
With a Little Help from My Friends: Nearest-Neighbor Contrastive Learning of Visual Representations
首先这篇论文是一个idea非常简单,实验非常充分的一篇论文
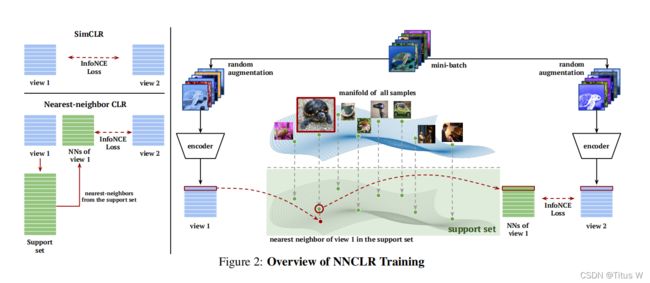
本文的核心思想其实非常简单,就是一个SimClr,一个图像进来,不同的random augmentation,做完之后得到两个view,送进encoder得到representation,然后做contrastive learning。虽然是两个view,但是他们来自同一种图,他们代表的语义信息应该是一样的,所以他们在latent space里面应该是完全相近的,本文用的loss呢是InfoNCE。
本文的核心在于random augmentation弱爆了,直接对比view呢不够给力,建立一个内存区域support set,比如得到一个view1之后,到support set里面去查,哪一个跟现在这个图像最为接近,找到一个最为接近的图像和另一个view2做InfoNCE,这样来构成一个loss,当然这次view1训练玩的representation不要扔,放进这个support set里面,相当于更新一些这个support set,就这样不断更新下去,非常简单的思想。
NNCLR
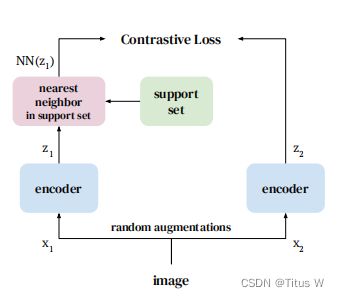
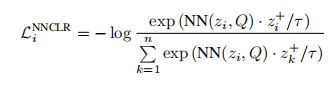
本质上是InfoNCE,但是分子上用的是最近邻,上面的zi就是左边的z1,Q是support set。

那最近邻怎么求呢?其实就是两个representation在latent space里面过normalization,他们都是单位向量,然后L2distance就可以了,关于supportset Q呢这里补充一点细节:
1.FIFO是一个先进先出的
2.用一个随机矩阵初始化
3.supportset Q用在一个encoder还是用在两个encoder上改善效果不是特别明显。
但是有个问题就是最近邻是不可差分的,既然不可差分,是不能训练的。因为我知道传统的SimCLR两边的encoder权重是shared的,也就是说只要有一边的encoder能把梯度传下去,另一边的也是可以得到训练的,所以这个设计其实挺巧妙的。
Results
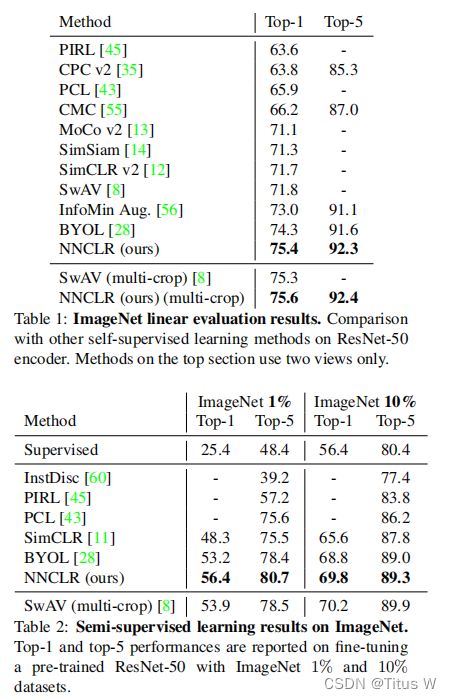
其实supportset和momentum encoder作用差不多的。