Deep Learning with Pytorch 中文简明笔记 第三章 It starts with a tensor
Deep Learning with Pytorch 中文简明笔记 第三章 Tensor
Pytorch作为深度学习框架的后起之秀,凭借其简单的API和简洁的文档,收到了越来越多人的关注和喜爱。本文主要总结了 Deep Learning with Pytorch 一书第三章[It starts with a tensor]的主要内容,并加以简单明了的解释,作为自己的学习记录,也供大家学习和参考。
文章目录
- Deep Learning with Pytorch 中文简明笔记 第三章 Tensor
- 1. 主要内容
- 2. 多维向量Tensor
- 3. Tensor的索引操作
- 4. Tensor维度命名
- 5. Tensor元素的数据类型
- 6. Tensor的API
- 7. Tensor的存储机制
- 8. Tensor与Numpy的交互性
- 9. Tensor的序列化操作
1. 主要内容
本章内容主要包括
- Pytorch中最基本的数据结构Tensor
- Tensor的索引操作
- 和numpy多维向量交互
- 将Tensor放入GPU中以加速运算
2. 多维向量Tensor
# In[1]:
a = [1.0, 2.0, 1.0]
# In[2]:
a[0]
# Out[2]:
1.0
# In[3]:
a[2] = 3.0
# Out[3]:
[1.0, 2.0, 3.0]
# In[4]:
import torch
a = torch.ones(3)
# Out[4]:
tensor([1., 1., 1.])
# In[5]:
a[1]
# Out[5]:
tensor(1.)
# In[6]:
float(a[1])
# Out[6]:
1.0
# In[7]:
a[2] = 2.0
a
# Out[7]:
tensor([1., 1., 2.])
在Pytorch中,可以直接使用Python原生的list直接构建Tensor对象。但是对于Python的list是对list所包含对象的收集,这些对象在内存中可能不是连续的(一般情况下均不连续)。但是Pytorch中的Tensor或者numpy则是内存中连续分配的C语言被解包的数字类型,外加一些元数据(如矩阵的维度,数据类型等信息)

# In[12]:
points.shape
# Out[12]:
torch.Size([3, 2])
# In[13]:
points = torch.zeros(3, 2)
points
# Out[13]:
tensor([[0., 0.], [0., 0.], [0., 0.]])
通过shape来访问Tensor的形状,通过zeros或者ones来初始化指定大小的Tensor
3. Tensor的索引操作
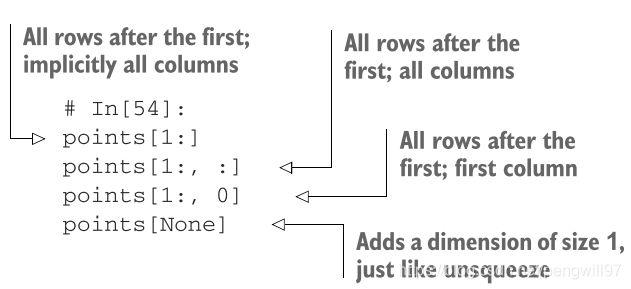
值得注意的是,points[None]会在最后增加一个维度
import torch
a = torch.tensor(1)
print(a.shape)
a = a[None]
print(a.shape)
a = a[None]
print(a.shape)
输出为
torch.Size([])
torch.Size([1])
torch.Size([1, 1])
4. Tensor维度命名
通常来讲,对于多维张量来说,每个维度都有其含义,如图片的RBG通道,图片的高宽或者是mini batch的size。Pytorch支持为张量的不同维度命名,一方面使代码更可读,另一方面减少出错的可能性。
# In[2]:
img_t = torch.randn(3, 5, 5) # shape [channels, rows, columns]
weights = torch.tensor([0.2126, 0.7152, 0.0722])
# In[3]:
batch_t = torch.randn(2, 3, 5, 5) # shape [batch, channels, rows, columns]
# In[4]:
img_gray_naive = img_t.mean(-3) # 表示对倒数第3个维度进行规约平均
batch_gray_naive = batch_t.mean(-3)
img_gray_naive.shape, batch_gray_naive.shape
# Out[4]:
(torch.Size([5, 5]), torch.Size([2, 5, 5]))
在创建Tensor的时候,可以使用names属性进行命名
# In[7]:
weights_named = torch.tensor([0.2126, 0.7152, 0.0722], names=['channels'])
weights_named
# Out[7]:
tensor([0.2126, 0.7152, 0.0722], names=('channels',))
或者对Tensor使用refine_names方法进行命名
# In[8]:
img_named = img_t.refine_names(..., 'channels', 'rows', 'columns')
batch_named = batch_t.refine_names(..., 'channels', 'rows', 'columns')
print("img named:", img_named.shape, img_named.names)
print("batch named:", batch_named.shape, batch_named.names)
# Out[8]:
img named: torch.Size([3, 5, 5]) ('channels', 'rows', 'columns')
batch named: torch.Size([2, 3, 5, 5]) (None, 'channels', 'rows', 'columns')
其中的…代表忽略前面的维度,仅对倒数后3个维度命名
对于sum或者mean的方法,除了传递维度的index以外,也支持传递维度的name
# In[9]:
weights_aligned = weights_named.align_as(img_named)
weights_aligned.shape, weights_aligned.names
# Out[9]:
(torch.Size([3, 1, 1]), ('channels', 'rows', 'columns'))
# In[10]:
gray_named = (img_named * weights_aligned).sum('channels') # 对channels进行规约求和
gray_named.shape, gray_named.names
# Out[10]:
(torch.Size([5, 5]), ('rows', 'columns'))
如果需要删除name,可以使用Tensor的rename方法
# In[12]:
gray_plain = gray_named.rename(None)
gray_plain.shape, gray_plain.names
# Out[12]:
(torch.Size([5, 5]), (None, None))
5. Tensor元素的数据类型
- torch.float32或torch.float, 32位浮点数
- torch.float64或torch.double, 64位浮点数
- torch.float16或torch.half,16位浮点数
- torch.int8,8位整数
- torch.uint8,8位无符号整数
- torch.int16或torch.short,16位整数
- torch.int32或torch.int,32位整数
- torch.int64或torch.long,64位整数
- torch.bool,布尔类型
Pytorch希望所有的index为64位整数,或者为32位的浮点数,所以绝大多数情况均在使用int64或者float32。对于一些条件判断,如points > 1.0,返回的Tensor类型为torch.bool,为1表示满足条件,0表示不满足。(书中没有阐述torch.bool类型所占比特数)
可以在创建Tensor时,可以使用dtype属性指定数据类型
# In[47]:
double_points = torch.ones(10, 2, dtype=torch.double)
short_points = torch.tensor([[1, 2], [3, 4]], dtype=torch.short)
对于已经创建的Tensor,可以使用内置方法进行类型转换
# In[49]:
double_points = torch.zeros(10, 2).double()
short_points = torch.ones(10, 2).short()
# In[50]:
double_points = torch.zeros(10, 2).to(torch.double)
short_points = torch.ones(10, 2).to(dtype=torch.short)
to()方法会首先检查转换的必要性,如必要则会按照传入参数转换,to()方法也支持其他属性,会在后面的章节提到。
当不同数据类型的Tensor进行预算时,Pytorch会自动向高类型看齐
# In[51]:
points_64 = torch.rand(5, dtype=torch.double)
points_short = points_64.to(torch.short)
points_64 * points_short # works from PyTorch 1.3 onwards
# Out[51]:
tensor([0., 0., 0., 0., 0.], dtype=torch.float64)
6. Tensor的API
Pytorch封装了许多关于Tensor的API,方便我们对Tensor进行操作,大致分为以下几种类型
- 创建运算,如ones()和from_numpy()
- 索引运算、切片运算、连接运算和转变运算,用于改变Tensor的shape和stride,和其他Tensor连接,如转置transpose()
- 数学运算
- 单点运算,用于单个Tensor并生成新的Tensor,如abs()和cos()
- 规约运算,用于计算规约,如mean(),std(),norm()
- 比较运算,如equal和max
- 频谱运算,在频率上使用较多的运算,如stft()和hamming_window()
- 其他运算,一些特殊的运算,如cross()和trace()
- 随机运算,如randn()和normal()
- 序列化,用于存储和加载Tensor,如save(),load()
- 并行化,用于CPU并行计算,如set_num_threads()
具体更详细API说明和使用可以参见官方文档。
7. Tensor的存储机制
Tensor中的数据在内存中均以Tensor.Storage连续的方式按指定数据类型大小在内存存储,内存是线性的,但是我们存储的数据是多维的,实际上Pytorch的Tensor是Storage的一个视图。
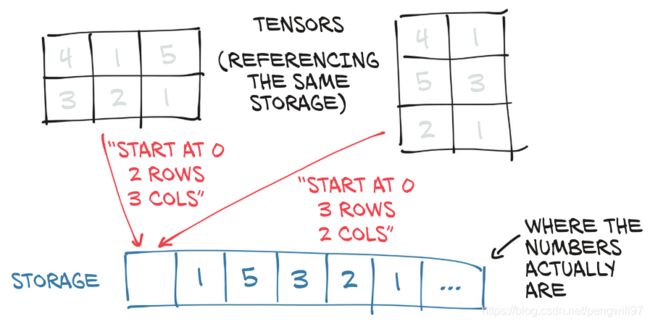
如图的两个矩阵,实际上都是同一块内存区域(Storage)的不同视图。
可以通过Tensor的storage()方法查看实际存储的数据
# In[17]:
points = torch.tensor([[4.0, 1.0], [5.0, 3.0], [2.0, 1.0]])
points.storage()
# Out[17]:
4.0
1.0
5.0
3.0
2.0
1.0
[torch.FloatStorage of size 6]
storage支持索引访问
# In[18]:
points_storage = points.storage()
points_storage[0]
# Out[18]:
4.0
# In[19]:
points.storage()[1]
# Out[19]:
1.0
storage()也支持左值运算,一旦修改,Tensor中的内容也会发生相应的变化
# In[20]:
points = torch.tensor([[4.0, 1.0], [5.0, 3.0], [2.0, 1.0]])
points_storage = points.storage()
points_storage[0] = 2.0
points
# Out[20]:
tensor([[2., 1.], [5., 3.], [2., 1.]])
Pytorch也有直接替换Tensor的方法,这种方法一般以下划线结尾,表示in place
# In[73]:
a = torch.ones(3, 2)
# In[74]:
a.zero_()
a
# Out[74]:
tensor([[0., 0.], [0., 0.], [0., 0.]])
由于Tensor是Storage的视图,Tensor通过一些元数据来访问同一片数据的不同形式(如进行转置操作,数据本身不发生变化,只修改Tensor的元数据)。这样进行的消耗微乎其微,大大提高许多矩阵操作的效率。
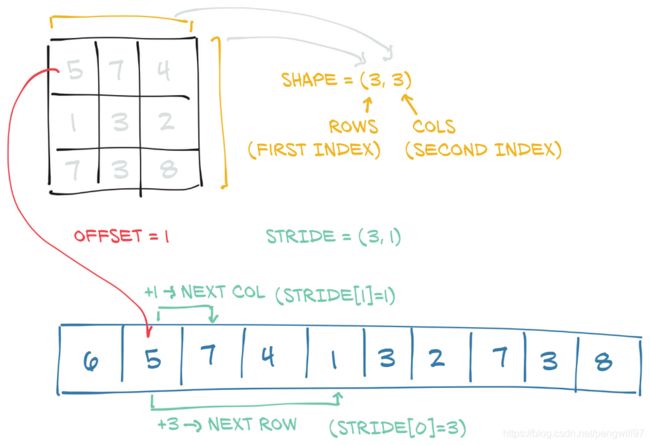
主要的元数据有offset和stride。offset表示从存储数据开始的偏移,一般的操作offset均为0,当对原张量进行slice操作后,offset便不为0。stride表示当前Tensor下一行的元素或者下一列的元素需要在storage的基础上跨过多少元素,stride和Tensor的shape维度相同。
通过Tensor的storage_offset()方法可以查看offset,stirde()方法查看stride()
# In[21]:
points = torch.tensor([[4.0, 1.0], [5.0, 3.0], [2.0, 1.0]])
second_point = points[1]
second_point.storage_offset()
# Out[21]:
2
# In[22]:
second_point.size()
# Out[22]:
torch.Size([2])
# In[23]:
second_point.shape
# Out[23]:
torch.Size([2])
# In[24]:
points.stride()
# Out[24]:
(2, 1)
由于Tensor仅是storage的一个视图,所以任何修改均会影响到storage,即使是对Tensor的一个子Tensor修改。
# In[28]:
points = torch.tensor([[4.0, 1.0], [5.0, 3.0], [2.0, 1.0]])
second_point = points[1]
second_point[0] = 10.0
points
# Out[28]:
tensor([[ 4., 1.], [10., 3.], [ 2., 1.]])
如果不需要使用这个特性,使用clone()方法对数据和视图进行拷贝,得到一个备份,之后在修改。
# In[29]:
points = torch.tensor([[4.0, 1.0], [5.0, 3.0], [2.0, 1.0]])
second_point = points[1].clone()
second_point[0] = 10.0
points
# Out[29]:
tensor([[4., 1.], [5., 3.], [2., 1.]])
刚才说到,这样好处是,对于一些矩阵操作,可以仅仅修改Tensor的视图部分,而不必对数据进行修改,如转置操作。从下面的代码可以看出,使用的是同一片内存。
# In[30]:
points = torch.tensor([[4.0, 1.0], [5.0, 3.0], [2.0, 1.0]])
points
# Out[30]:
tensor([[4., 1.], [5., 3.], [2., 1.]])
# In[31]:
points_t = points.t()
points_t
# Out[31]:
tensor([[4., 5., 2.], [1., 3., 1.]])
# In[32]:
id(points.storage()) == id(points_t.storage())
# Out[32]:
True
此外,可以通过is_contiguous()方法来判断Tensor对Storage的访问是否是连续的
# In[39]:
points.is_contiguous()
# Out[39]:
True
# In[40]:
points_t.is_contiguous()
# Out[40]:
False
对于不连续的Tensor,可以使用contiguous()方法将其转变为连续的,其操作为改变数据的storage和stride,以达到目的
# In[41]:
points = torch.tensor([[4.0, 1.0], [5.0, 3.0], [2.0, 1.0]])
points_t = points.t()
points_t
# Out[41]:
tensor([[4., 5., 2.], [1., 3., 1.]])
# In[42]:
points_t.storage()
# Out[42]:
4.0
1.0
5.0
3.0
2.0
1.0
[torch.FloatStorage of size 6]
# In[43]:
points_t.stride()
# Out[43]:
(1, 2)
# In[44]:
points_t_cont = points_t.contiguous()
points_t_cont
# Out[44]:
tensor([[4., 5., 2.], [1., 3., 1.]])
# In[45]:
points_t_cont.stride()
# Out[45]:
(3, 1)
此处我有一个疑问,如果我们执行以下代码
a = torch.tensor([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
b = a[:2, :2]
c = b.t()
c = c.contiguous()
那么是否会改变a的storage呢?根据刚才的介绍,Tensor仅是视图,但是contiguous()会改变storage,在c变为顺序访问后,应该也会改变storage,由于c和a共使用一个storage,所以a也应该会改变。但是据我测试,a和c还是同一个storage(使用id进行判断),但是c的storage的size会变为4,即1,4,2,5(之前为9,即1,2,3,4,5,6,7,8,9),a的storage不发生改变。同时若继续对c中元素修改,a不受影响,但如果查看contiguous()前a的id和改变后a的id,会发现不同(换做c也一样),但是a和c的id是始终相同的。所以猜测此处a和c受一个storage管理(底层的同一个对象),但是实际上是不同的内存区域。书中此处仅简单介绍了storage的管理方法,没有深层讲解,如需理解还需要看源代码。
如果我们需要在GPU中创建Tensor,可以使用device属性,或者在to()方法中加入device属性。
# In[64]:
points_gpu = torch.tensor([[4.0, 1.0], [5.0, 3.0], [2.0, 1.0]], device='cuda')
# In[65]:
points_gpu = points.to(device='cuda')
如果有多个GPU,可以使用序号指定
# In[66]:
points_gpu = points.to(device='cuda:0')
若在运算中包含GPU中的数据,也包含CPU中的数据,会首先将CPU中数据拷贝到GPU,然后通过GPU进行运算,之后除非手动将数据移至CPU或者打印访问数据,数据并不流经CPU,而且是全部在CPU运算。
也可以使用device属性将Tensor移至CPU,或者使用他们的快捷方法。
# In[69]:
points_cpu = points_gpu.to(device='cpu')
# In[70]:
points_gpu = points.cuda()
points_gpu = points.cuda(0)
points_cpu = points_gpu.cpu()
8. Tensor与Numpy的交互性
使用方法numpy()来将Tensor转换为numpy的array
# In[55]:
points = torch.ones(3, 4)
points_np = points.numpy()
points_np
# Out[55]:
array([[1., 1., 1., 1.], [1., 1., 1., 1.], [1., 1., 1., 1.]], dtype=float32)
需要注意的是,如果Tensor被分配在GPU中,会在CPU中生成一份数据的拷贝,将其转换为numpy格式。
也可以通过from_numpy()将numpy的array转换为Tensor
# In[56]:
points = torch.from_numpy(points_np)
9. Tensor的序列化操作
使用Tensor的save()和load()方法可以方便的进行序列化操作
# In[57]:
torch.save(points, '../data/p1ch3/ourpoints.t')
# In[59]:
points = torch.load('../data/p1ch3/ourpoints.t')
或者通过文件句柄进行存储和读取
# In[58]:
with open('../data/p1ch3/ourpoints.t','wb') as f:
torch.save(points, f)
# In[60]:
with open('../data/p1ch3/ourpoints.t','rb') as f:
points = torch.load(f)