python机器学习前戏 ——特征工程应用
机器学习笔记——特征工程应用
- 机器学习为什么需要特征工程
- 什么是特征工程
- 特征工程的实现
目录
- 机器学习笔记——特征工程应用
- 机器学习——特征工程应用
-
- 机器学习为什么需要特征工程
- 什么是特征工程
- sklearn 工具特征抽取应用
-
- 字典特征抽取
-
-
- OneHot编码(上图中矩阵中01就是该编码)
-
- 文本特征抽取
- 特征预处理(数值型)
- 特征选择
-
-
- 特征选择:从特征中选择出有意义对模型有帮助的特征作为最终的机器学习输入的数据!
-
机器学习——特征工程应用
机器学习为什么需要特征工程
- 样本数据中的特征有可能会存在缺失值,重复值,异常值等等,那么我们是需要对特征中的相关的噪点数据进行处理的,那么处理的目的就是为了营造出一个更纯净的样本集,让模型基于这组数据可以有更好的预测能力。当然特征工程不是单单只是处理上述操作!
什么是特征工程
- 特征工程是将原始数据转换成更好的预测模型的潜在问题的特征的过程,从而提升对为主数据预测的准确性
- 举个例子(AIphaGO的机器学习中只会有相关棋谱的数据集,不会有其他类型的数据集影响程序判断。)
- 特征工程将直接影响预测结果
- 特征工程的实现工具
*sklearn工具
sklearn 工具特征抽取应用
- 目的:机器学习学习的数据如果不是数值型的数据,电脑是识别不了的,所以需要将其他类型的数据通过特征抽取转换成电脑可以识别的数据进而帮助实现预测过程。
效果演示
from sklearn.feature_extraction.text import CountVectorizer
vector = CountVectorizer()
res = vector.fit_transform(['lift is short,i love python','lift is too long,i hate python'])
print(res.toarray())
结果:
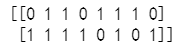
- 这个过程就是对文本进行了特征值化的过程。为了让计算机更好的理解数据。
字典特征抽取
–模块导入
- from sklearn.feature_extraction import DictVectorizer
- fit_transform(X):X为字典或者包含字典的迭代器,返回值为sparse矩阵
- fit_transform(X):X为字典或者包含字典的迭代器,返回值为sparse矩阵
- inverse_transform(X):X为sparse矩阵或者array数组,返回值为转换之前的数据格式
- transform(X):按照原先的标准转换
- get_feature_names():返回类别名称
from sklearn.feature_extraction import DictVectorizer
alist = [
{'city':'BeiJing','temp':33},
{'city':'GZ','temp':42},
{'city':'SH','temp':40}
]
#实例化一个工具类对象
d = DictVectorizer()
#返回的是一个sparse矩阵(存储的就是特征值化之后的结果)
feature = d.fit_transform(alist)
print(feature)
返回结果:
- 什么是sparse矩阵如何理解?
- 在DictVectorizer类的构造方法中中默认设定sparse=False,其返回的是一个数组。
- get_feature_names():返回类别名称
- sparse矩阵是一个变相的数组或者列表,目的是为了节省内存
- 在DictVectorizer类的构造方法中中默认设定sparse=False,其返回的是一个数组。
from sklearn.feature_extraction import DictVectorizer
alist = [{'city':'BeiJing','temp':33},{'city':'GZ','temp':42},{'city':'SH','temp':40}]
d = DictVectorizer(sparse=False)#sparse=False
#返回的是一个二维列表
feature = d.fit_transform(alist)
print(d.get_feature_names())
print(feature)
#输出结果:1为是,0为不是
输出的结果是:

OneHot编码(上图中矩阵中01就是该编码)
- 为什么使用OneHot编码?
为了避免序列化导致数据优先级和权重的影响。
文本特征抽取
- 作用:对文本数据进行特征值化
- from sklearn.feature_extraction.text import CountVectorizer
- fit_transform(X):X为文本或者包含文本字符串的可迭代对象,返回sparse矩阵
- inverse_transform(X):X为array数组或者sparse矩阵,返回转换之前的格式数据
- get_feature_names()
- toarray():将sparse矩阵换成数组
from sklearn.feature_extraction.text import CountVectorizer
vector = CountVectorizer()
res = vector.fit_transform(['left is is short,i love python','left is too long,i hate python'])
# print(res) #sparse矩阵
print(vector.get_feature_names())
print(res.toarray()) #将sparse矩阵转换成数组
#注意:单字母不统计(因为单个字母代表不了实际含义),然后每个数字表示的是单词出现的次数
结果:
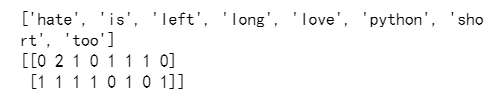
特征预处理(数值型)
- 无量纲化:
- 在机器学习算法实践中,我们往往有着将不同规格的数据转换到同一规格,或不同分布的数据转换到某个特定分布 的需求这种需求统称为将数据“无量纲化”譬如梯度和矩阵为核心的算法中,譬如逻辑回归,支持向量机,神经 网络,无量纲化可以加快求解速度;而在距离类模型,譬如K近邻,K-Means聚类中,无量纲化可以帮我们提升模 型精度,避免某一个取值范围特别大的特征对距离计算造成影响。(一个特例是决策树和树的集成算法们,对决策 树我们不需要无量纲化,决策树可以把任意数据都处理得很好。)
- 那么预处理就是用来实现无量纲化的方式。
- 含义:特征抽取后我们就可以获取对应的数值型的样本数据啦,然后就可以进行数据处理了。
- 概念:通过特定的统计方法(数学方法),将数据转换成算法要求的数据
- 方式:
- 归一化
- 标准化
from sklearn.preprocessing import MinMaxScaler
mm = MinMaxScaler(feature_range=(0,1))#:每个特征缩放的范围
data = [[90,2,10,40],[60,5,15,45],[73,3,13,45]]
data = mm.fit_transform(data)#:X需要归一化的特征
print(data)
结果:

- 问题:如果数据中存在的异常值比较多,会对结果造成什么样的影响?
- 结合着归一化计算的公式可知,异常值对原始特征中的最大值和最小值的影响很大,因此也会影响对归一化之后的值。这个也是归一化的一个弊端,无法很好的处理异常值。
- 归一化总结:
- 在特定场景下最大值和最小值是变化的,另外最大最小值很容易受到异常值的影响,所以这种归一化的方式具有一定的局限性。因此引出了一种更好的方式叫做:标准化!!!
- 归一化和标准化总结:
- 对于归一化来说,如果出现了异常值则会响应特征的最大最小值,那么最终结果会受到比较大影响
- 对于标准化来说,如果出现异常点,由于具有一定的数据量,少量的异常点对于平均值的影响并不大,从而标准差改变比较少。
- API
- 处理后,每列所有的数据都聚集在均值为0,标准差为1范围附近
- 标准化API:from sklearn.preprocessing import StandardScaler
- fit_transform(X):对X进行标准化
- mean_:均值
- var_:方差
特征选择
特征选择:从特征中选择出有意义对模型有帮助的特征作为最终的机器学习输入的数据!
- 工具:
- Filter(过滤式)【主要讲解】
- Embedded(嵌入式):决策树模型会自己选择出对其重要的特征。【后期在讲解模型的时候在补充】
- PCA降维
- Filter过滤式(方差过滤):
- 原理:这是通过特征本身的方差来筛选特征的类。比如一个特征本身的方差很小,就表示样本在这个特征上基本没有差 异,可能特征中的大多数值都一样,甚至整个特征的取值都相同,那这个特征对于样本区分没有什么作用。所以无 论接下来的特征工程要做什么,都要优先消除方差为0或者方差极低的特征。
- API:from sklearn.feature_selection import VarianceThreshold
- VarianceThreshold(threshold=x)threshold方差的值,删除所有方差低于x的特征,默认值为0表示保留所有方差为非0的特征
- fit_transform(X)#:X为特征
from sklearn.feature_selection import VarianceThreshold
#threshold方差的值,删除所有方差低于x的特征,默认值为0表示保留所有方差为非0的特征
v = VarianceThreshold(threshold=1)
v.fit_transform([[0,2,4,3],[0,3,7,3],[0,9,6,3]])#:X为特征
结果:

- 如果将方差为0或者方差极低的特征去除后,剩余特征还有很多且模型的效果没有显著提升则方差也可以帮助我们将特征选择【一步到位】。留下一半的 特征,那可以设定一个让特征总数减半的方差阈值,只要找到特征方差的中位数,再将这个中位数作为参数 threshold的值输入就好了。
- VarianceThreshold(np.median(X.var().values)).fit_transform(X)
- X为样本数据中的特征列
- VarianceThreshold(np.median(X.var().values)).fit_transform(X)
- 【注意】
- 方差过滤主要服务的对象是:需要遍历特征的算法模型。而过滤法的主要目的是:在维持算法表现的前提下,帮 助算法们降低计算成本。