基于深度学习的推荐系统(二)itemCF实现过程
本文主要介绍基于物品的协同过滤算法实现。
用于找到相似的20部电影 为目标用户推荐10部。
数据收集
用到的movielens数据集,下载地址:movielens数据集。各种数据大小的都有,我下载的是ml-latest-small.zip
数据集中包含links、movies、ratings、tags、readme文件。
 这里主要用到movies与ratings文件。
这里主要用到movies与ratings文件。
数据处理
将数据分为训练集与测试集。
在读取文件时报错:
OSError: [Errno 22] Invalid argument: 'D:\\pycharm\x08y_coding\recommend\\ml-latest-small\ratings.csv'
读取文件地址出错,改为:
rating_file = r'D:\pycharm\by_coding\recommend\ml-latest-small\ratings.csv'
r’file‘:意思是指为了避免\xx是一个转义字符而导致的错误,也就是说加上r之后,引号里不再出现转义字符,而是纯的文件地址。
读取文件的每一行
def load_file(self,filename):
with open(filename,'r') as f:
for i, line in enumerate(f):
if i==0:
continue
yield line.strip('\r\n')
print("%s数据读取成功!"%filename)
划分训练集与测试集
这里采用随机数来分割训练集与测试集(3:1)。
def get_dataset(self,filename,pivot = 0.75):
trainSet_len = 0
testSet_len = 0
for line in self.load_file(filename):
#依次读取每一行 按逗号分隔开
user,movie,rating,timestamp = line.split(',')
if(random.random()<pivot):
#<0.75则放入训练集
self.trainSet.setdefault(user,{})
self.trainSet[user][movie] = rating
trainSet_len += 1
else:
self.testSet.setdefault(user,{})
self.testSet[user][movie] = rating
testSet_len += 1
print("训练集长度:%s" % trainSet_len)
print("测试集长度:%s" % testSet_len)
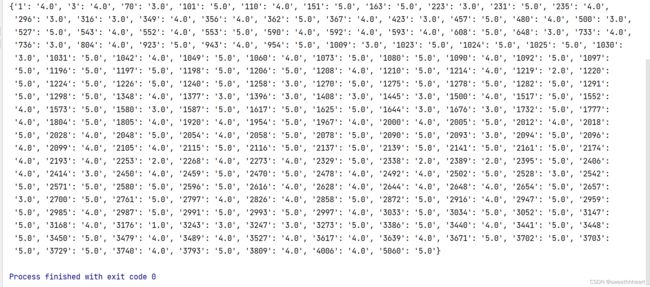
这时输出trainSet['1'] 得到(user=1 评分的所有电影id和rating评分值):
计算电影之间的相似度
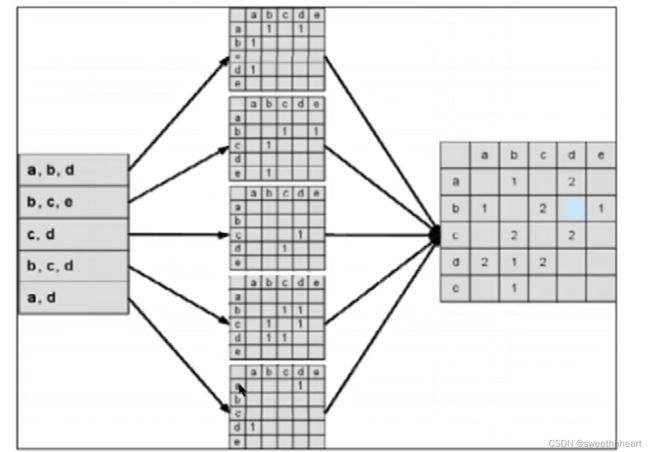
建立同现矩阵
同现矩阵就是物品与物品间的关联度,这个关联度由所有用户对所有物品的评分决定。
同现矩阵用于计算物品间的相似度,是协同过滤算法关键的一步。
# 遍历训练数据 建立物品-物品同现矩阵
for user,movies in self.trainSet.items():
# 遍历两次movies集合 创建相似度矩阵
for movie1 in movies:
for movie2 in movies:
# 如果该项是当前物品,则跳过
if movie1==movie2:
continue
self.movie_sim_matrix.setdefault(movie1,{})
self.movie_sim_matrix[movie1].setdefault(movie2,0)
# 遍历到其他物品+1
self.movie_sim_matrix[movie1][movie2] +=1
print("同现矩阵创建成功!")
计算相似度矩阵
这里利用两个向量夹角的余弦值计算相似度,公式如下:
分母是看movie1电影的用户向量平方*看movie2电影的用户向量平方。

这里的余弦相似度是根据同现矩阵中两个movie的关联程度值计算的,原理同上。
self.movie_sim_matrix[movie1][movie2] = count/math.sqrt(self.movie_popular[movie1] * self.movie_popular[movie2])
给用户做推荐
推荐依据:推荐电影与已看电影相似度(累计)*用户对已看电影的评分。
实现思路:遍历该与user所有已看电影,对每个已看电影求出最相似的k个电影,用相似度矩阵中的值 * user对已看电影的评分,再相加,最后返回给用户推荐的前n个。
# 给用户做推荐
def recommand(self,user):
#推荐电影10
n = self.n_rec_movie
#找出相似的20
k = self.n_sim_movie
rank = {}
# 获取训练集中该user看过的movie
watched_movies = self.trainSet[user]
for movie,rating in watched_movies.items():
# 按第二个元素rating进行排序 取前k个
for related_movies,w in sorted(self.movie_sim_matrix[movie].items(),key = itemgetter(1),reverse=True)[:k]:
if related_movies in watched_movies:
continue
rank.setdefault(related_movies,0)
# 排名依据:推荐电影与已看电影相似度(累计)*用户对已看电影的评分
rank[related_movies] += w * float(rating)
return sorted(rank.items(),key=itemgetter(1),reverse=True)[:n]
模型的评价指标
精确率:推荐正确的结果/分类器给出的所有结果。
召回率:推荐正确的结果/总的正确结果。
覆盖率:推荐给出的物品/全部物品。
# 对每个训练集中的user进行遍历
for i,user in enumerate(self.trainSet):
test_movies = self.testSet.get(user,{})
rec_movies = self.recommand(user)
# 遍历模型中取到的给user推荐的10个相似电影 如果出现在test中 说明预测对了
for movie,w in rec_movies:
if movie in test_movies:
hit+=1
all_rec_movies.add(movie)
# 记录所有推荐电影的数目
rec_count += n
test_count += len(test_movies)
precision = hit/(1.0*rec_count)
recall = hit/(1.0*test_count)
coverage = len(all_rec_movies)/(1.0*self.movie_count)
print("推荐准确率是%.3f,召回率是%.3f,覆盖率是%.3f" % (precision,recall,coverage))
完整代码
#基于物品的协同过滤算法
import math
import random
from operator import itemgetter
class ItemBasedCF():
#初始化参数
def __init__(self):
#找到相似的20部电影 为目标用户推荐10部
self.n_sim_movie = 20
self.n_rec_movie = 10
#将数据集划分为训练集与测试集
self.trainSet = {}
self.testSet = {}
#用户相似度矩阵
self.movie_sim_matrix = {}
#记录电影被评分的次数
self.movie_popular = {}
self.movie_count = 0
print("similar movie number(相似电影个数) = %d" % self.n_sim_movie)
print("recommended movie number = %d(推荐电影个数)" % self.n_rec_movie)
def load_file(self,filename):
with open(filename,'r') as f:
for i, line in enumerate(f):
if i==0:
continue
yield line.strip('\r\n')
print("%s数据读取成功!"%filename)
def get_dataset(self,filename,pivot = 0.75):
trainSet_len = 0
testSet_len = 0
for line in self.load_file(filename):
#依次读取每一行 按逗号分隔开
user,movie,rating,timestamp = line.split(',')
if(random.random()<pivot):
#<0.75则放入训练集
self.trainSet.setdefault(user,{})
self.trainSet[user][movie] = rating
trainSet_len += 1
else:
self.testSet.setdefault(user,{})
self.testSet[user][movie] = rating
testSet_len += 1
print("训练集长度:%s" % trainSet_len)
print("测试集长度:%s" % testSet_len)
print(self.trainSet['1'])
# 计算电影的相似度
def calcu_movie_sim(self):
# 先统计每个电影被评分的个数
for user,movies in self.trainSet.items():
for movie in movies:
#movie_popular记录电影被评分的次数
if movie not in self.movie_popular:
#如果未被看过 赋初值0
self.movie_popular[movie] = 0
self.movie_popular[movie]+=1
# 被评分的电影总数
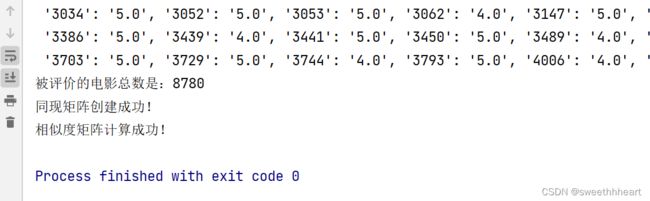
self.movie_count = len(self.movie_popular)
print("被评价的电影总数是:%d" % self.movie_count)
# 遍历训练数据 建立物品-物品同现矩阵
for user,movies in self.trainSet.items():
# 遍历两次movies集合 创建相似度矩阵
for movie1 in movies:
for movie2 in movies:
# 如果该项是当前物品,则跳过
if movie1==movie2:
continue
self.movie_sim_matrix.setdefault(movie1,{})
self.movie_sim_matrix[movie1].setdefault(movie2,0)
# 遍历到其他物品+1
self.movie_sim_matrix[movie1][movie2] +=1
print("同现矩阵创建成功!")
# 根据同现矩阵计算电影的相似度
# 迭代字典中的键与值
for movie1,related_movies in self.movie_sim_matrix.items():
# count为movie1与movie2的关联程度
for movie2,count in related_movies.items():
# 当扫描到某电影的评分用户数为0时 要注意对0向量的处理
# 要满足用户看过movie1与movie2两个电影
if self.movie_popular[movie1] == 0 or self.movie_popular[movie2] == 0:
self.movie_sim_matrix[movie1][movie2] = 0
else:
# count是被评分的电影总数
self.movie_sim_matrix[movie1][movie2] = count/math.sqrt(self.movie_popular[movie1] * self.movie_popular[movie2])
print("相似度矩阵计算成功!")
# 给用户做推荐
def recommand(self,user):
#推荐电影10
n = self.n_rec_movie
#找出相似的20
k = self.n_sim_movie
rank = {}
# 获取训练集中该user看过的movie
watched_movies = self.trainSet[user]
for movie,rating in watched_movies.items():
# 按第二个元素rating进行排序 取前k个
for related_movies,w in sorted(self.movie_sim_matrix[movie].items(),key = itemgetter(1),reverse=True)[:k]:
if related_movies in watched_movies:
continue
rank.setdefault(related_movies,0)
# 排名依据:推荐电影与已看电影相似度(累计)*用户对已看电影的评分
rank[related_movies] += w * float(rating)
return sorted(rank.items(),key=itemgetter(1),reverse=True)[:n]
# 产生推荐列表 通过准确率、召回率与覆盖率进行评估
def evaluate(self):
print("开始评估:")
n = self.n_rec_movie
#准确率与召回率
hit = 0
rec_count = 0
test_count = 0
# 覆盖率 去掉重复的电影
all_rec_movies = set()
# 对每个训练集中的user进行遍历
for i,user in enumerate(self.trainSet):
test_movies = self.testSet.get(user,{})
rec_movies = self.recommand(user)
# 遍历模型中取到的给user推荐的10个相似电影 如果出现在test中 说明预测对了
for movie,w in rec_movies:
if movie in test_movies:
hit+=1
all_rec_movies.add(movie)
# 记录所有推荐电影的数目
rec_count += n
test_count += len(test_movies)
precision = hit/(1.0*rec_count)
recall = hit/(1.0*test_count)
coverage = len(all_rec_movies)/(1.0*self.movie_count)
print("推荐准确率是%.3f,召回率是%.3f,覆盖率是%.3f" % (precision,recall,coverage))
if __name__ == '__main__':
rating_file = r'D:\pycharm\by_coding\recommend\ml-latest-small\ratings.csv'
itemCF = ItemBasedCF()
itemCF.get_dataset(rating_file)
itemCF.calcu_movie_sim()
itemCF.evaluate()