目标检测的衡量标准
参考内容:
1.如何解释召回率与精确率? - 知乎
2. 谈谈召回率(R值),准确率(P值)及F值 - 知乎
3. 如何解释召回率与精确率? - 知乎
4 .https://zhuanlan.zhihu.com/p/91206205
5.TP、TN、FP、FN超级详细解析_奋斗の博客-CSDN博客
6.目标检测中的AP,mAP - 知乎
7.目标检测之IoU、precision、recall、AP、mAP详解_钱彬 (Qian Bin)的博客-CSDN博客_目标检测ap
8.https://blog.csdn.net/ThomasCai001/article/details/120097650
9.https://blog.csdn.net/Lawrence_Cj/article/details/108467430
目录
一、准确率、精确率、召回率、误检率、漏检率
二、IoU(Intersection over union)
三、以检测来说明上述参数
四、PR(Precision-recall)曲线
五、AP、MAP
六、实际计算需注意的点
本文主要记录目标检测中的一些衡量标准,以备搞不清楚时随时查阅。
目标检测可以简单的理解为用个框把物体框出来并告诉我这个框里是什么。
一、准确率、精确率、召回率、误检率、漏检率

(上图来源看水印,放于此处为便于理解,如有侵权,联系删除)
准确率accuracy=预测对的/所有=(TP+TN)/(TP+FN+FP+TN)
精确率Precision=True positives/predicted as positives=TP/(TP+FP),预测出的真正正例(TP)占预测出来的所有正例(TP+FP)的比例,即预测结果中,正例被预测正确的概率。当Precision=100%时,表示没有误检,也就是FP=0,则FP/(FP+TN)=0即没有真实情况是反例的被预测为正例,也就相当于没有非目标的被当成目标检出。
召回率Recall=True positives/actual positives=TP/(TP+FN),预测出的真正正例(TP)占真实情况所有正例(TP+FN)的比例,即真实值中,正例被预测正确的概率。当Recall=100%时,表示没有漏检,也就是FN=0,则即FN/(TP+FN)=0,没有真实情况是正例的被检测为反例,也就相当于没有本身是目标的未检出。
误检率fp rate=False positives/actual negatives=FP/(FP+TN),预测为正例但真实情况不是正例的(FP)占真实情况的所有反例(FP+TN)的比例。
漏检率miss rate=False negatives/actual positives=FN/(TP+FN),预测为负例但真实情况是正例的(FN)占真实情况所有正例(TP+FN)的比例。
从上可以看出召回率+漏检率=1;
根据以上这些内容,我们就能根据不同的任务来对应提高Precision或者Recall值,一般来说,提高一个,另一个的值则会降低。
用到目标检测领域,假设我们有一组图片,里面有若干待检测的目标,Precision就代表我们模型检测出来的目标有多大比例是真正的目标物体,Recall就代表所有真实的目标有多大比例被我们的模型正确检测出来了。
二、IoU(Intersection over union)
交并比IoU衡量的是两个区域的重叠程度,是两个区域重叠部分面积占二者总面积(重叠部分只计算一次)的比例。如下图,两个矩形框的IoU是交叉面积(中间图片红色部分)与合并面积(右图红色部分)面积之比。(下图来源于链接6,放于此处便于理解,如有侵权,联系删除)

在目标检测任务中,如果我们模型输出的矩形框与我们人工标注的矩形框的IoU值大于某个阈值时(通常为0.5)即认为我们的模型输出了正确的。
三、以检测来说明上述参数
以检测狗为例:(该例子摘自参考链接7)
TP含义:预测框中检测出狗(GroundTruth),并且IoU值大于阈值(一般阈值取0.5),说明检测对了。
FP含义:预测框中检测出狗(GroundTruth),但是IoU值小于阈值,说明检测错了。
FN含义:预测框中检测该框只含背景,但是实际该框中含有狗(GroundTruth),说明检测错了,漏检了。
TN含义:预测框中检测该框只含背景,实际该框也是如此,说明检测对了。这个框中确实没有狗,检测正确。实际目标检测中我们不会去检测背景(因为我们不会去为背景画个框),因此一般不会去计算TN这个值。
之后可以根据这些值计算precision和recall
precison=TP/(TP+FP) :检测器检测出是狗并且确实是狗的部分占所有检测器认为是狗的比例
recall=TP/(TP+FN):检测器检测出是狗并且确实是狗的部分占所有确实是狗的比例
四、PR(Precision-recall)曲线
我们当然希望检测的结果P越高越好,R也越高越好,但事实上这两者在某些情况下是矛盾的。比如极端情况下,我们只检测出了一个结果,且是准确的,那么Precision就是100%,但是Recall就很低;而如果我们把所有结果都返回,那么必然Recall必然很大,但是Precision很低。
从上一个环节,我们知道在计算precision以及recall的时候,先计算TP、FP和FN,需要计算每个检测框和真值框的IoU,再根据设定的阈值threshold来计算这三个值,阈值的选择会直接影响TP、FP和FN的结果,也就是precision和recall会随着阈值threshold的不同而不同。
在不同的场合中需要自己判断希望P比较高还是R比较高。如果是做实验研究,可以绘制Precision-Recall曲线来帮助分析。 Recall值为横轴,Precision值为纵轴,我们就可以得到PR曲线。 (下图来源链接7)
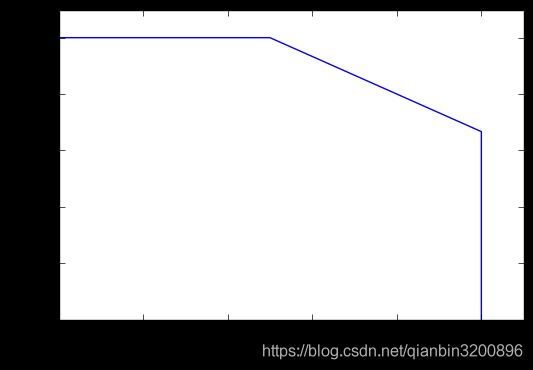
本质上希望我们的算法不仅检测精度高,同时召回率也高,这在曲线上反映出来的效果就是这个曲线尽可能的往右上角拉伸,即固定recall值时,precision越大越好(对应往上拉伸);同理固定precision时,recall越大越好(对应往右拉伸)。往右上角拉伸,在数值上体现是要该曲线下方的面积越大越好。所以对比那种算法的检测效果更好,可以通过计算两个算法对应PR曲线下方的面积,面积越大说明该曲线对应的检测算法效果较好。
五、AP、AR、mAP、mAR
链接6给出了AP的数学计算公式,如果对此感兴趣,可以去学习。
AP (Average precision):PR曲线下方的面积就是AP。是主流的目标检测模型的评价指标。
注意到我们只检测了1类我们就得到了1根PR曲线,如果检测多类,那么每一类我们均可以得到一根PR曲线,也就是每类都会有1个AP值。
mAP,上面所诉表示对于每一类计算的AP值,如果你有检测多个类别,比如猫,狗等,那么再取个mean,就得到mAP。
一般论文中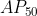 是指IOU阈值为0.5时的AP测量值,
是指IOU阈值为0.5时的AP测量值,![]() 是IoU阈值为0.75时的测量值。
是IoU阈值为0.75时的测量值。
AR(average recall):即平均召回率,对于不同的iou取最大的召回率再求平均值。
mAR:mAR为对所有类别的每一类的AR值求平均值。
六、实际计算需注意的点
(此部分主要摘自链接7)
在深度学习检测得到每个检测框时,还会同步给出该检测框属于某个类别的概率,举个例子(如果在图像中某个区域检测出狗,一般会同步的给出该区域属于狗的概率)。所以实际中计算
mAP时一般采用下面的步骤(以单张图片、单个类别为例):
(1) 过滤置信度低的预测框
首先遍历图片中每个真值框对象,然后读取我们通过算法检测器检测出的这种类别的检测框,接着过滤掉置信度分数低于置信度阈值的框(一般取0.5);
(2)计算IoU
将剩下的检测框按置信度分数从高到低排序,最先判断置信度分数最高的检测框与真值框的IoU是否大于IoU阈值,若IoU大于设定的IoU阈值即判断为TP,将此真值框标记为已检测(后续的同一个真值框的多余检测框都视为FP,这就是为什么先要按照置信度分数从高到低排序,置信度分数最高的检测框最先去与IoU阈值比较,若大于IoU阈值,视为TP,后续的同一个真值框对象的检测框都视为FP),IoU小于阈值的,直接判定为FP。
(3)计算AP
根据(2)中获得的TP、FP计算AP。
七、COCO评价指标
参考链接8、9
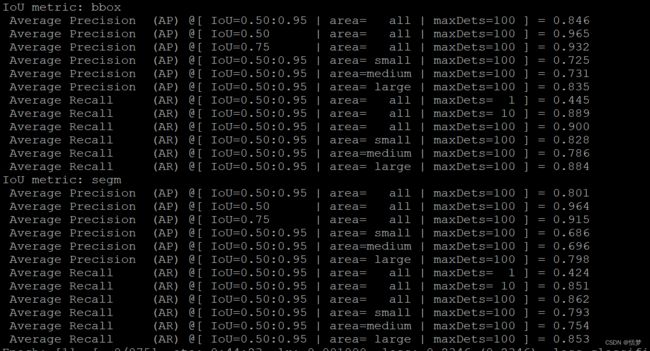
上图中的AP都是mAP;AR都是mAR。所以图中的AP、AR本质上都是mAP,mAR。
1.第一个值
将IOU值大于0.5的AP,以0.05的增量增到0.95,也就是以(0.5,0.55,0.6,0.65,0.7,0.75,0.8,0.85,0.9,0.95)IOU值得AP的平均值当成( IoU=0.50:0.95)。这样IOU增量平均的考虑可能是:只以0.5IOU为阀值的时候不一定就是更好的模型,可能仅仅在0.5阀值表现的很好,在0.6,0.7…阀值表现的很差,为了更好地评估整体模型的准确度,从而计算一个模型在各个IOU值的AP(mAP),取平均值。
2.第二个值
iou取0.5的mAP值,是voc的评判标准;
3.第三个值
评判较为严格的mAP值,可以反应算法框的位置精准程度;

4. 第4、5、6 个值分别为area= small,area=medium,area=large不同物体大小的mAP 值。

5.第7、8、9个值,分别表示一张图有一个检测、10个检测、100个检测的mAR值。

对比一下maxDets=10以及maxDets=100的mAR值,反应检出率,如果两者接近,说明对于这个数据集来说,不用检测出100个框,可以提高性能。
6.第10、11、12个值分别为area= small,area=medium,area=large不同物体大小的mAP 值。

文中若有错误及不妥指出,还望指出!