Hive数据倾斜常见场景及解决方案(超全!!!)
Hive数据倾斜常见问题和解决方案
文章目录
- 前言、
- 一、Explain
- 二、数据倾斜(常见优化)
前言
Hive数据倾斜是面试中常问的问题,这里我们需要很熟练地能举出常见的数据倾斜的例子并且给出解决方案。
一、Explain
我们可以通过sql语句前面加expalin来具体查看这条语句的执行计划 通过观察它的一些参数来辅助调优
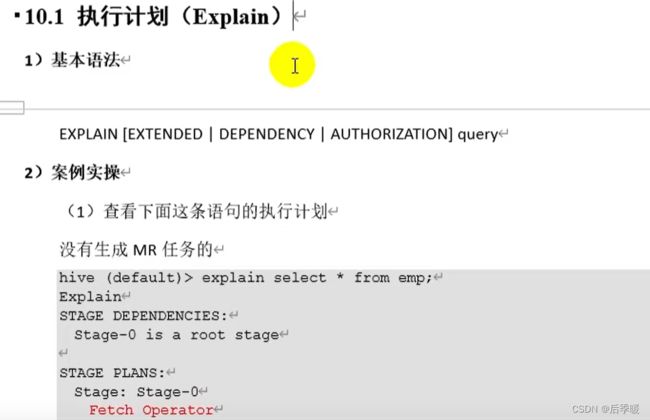
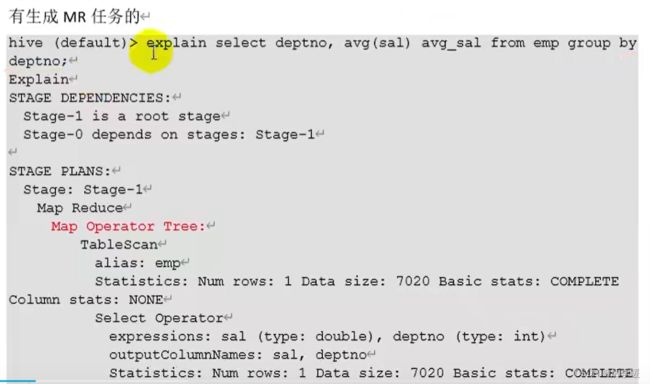
二、数据倾斜
1.什么是数据倾斜?它的主要表现?
数据倾斜是由于数据分布不均匀,造成数据大量的集中到一点,造成数据热点的现象。
主要表现:任务进度长时间维持在 99%或者 100%的附近,查看任务监控页面,发现只有少量 reduce 子任务未完成,因为其处理的数据量和其他的 reduce 差异过大。 单一 reduce 处理的记录数和平均记录数相差太大,通常达到好几倍之多,最长时间远大 于平均时长。
2.产生数据倾斜的常见原因
一.join时:首先是大表关联小表,容易发生数据倾斜
这里Hive自动帮我们把小表放到缓存当中了。也就是我们所熟知的mapjoin,在学习Hadoop中就已经使用过。
以前需要我们手动调:set hive.auto.convert.join=true
一般小表的大小是25M左右,想要改变其大小只需set hive.mapjoin.smalltable.filesize=25000000
以前join的时候小表必须在左边,现在底层优化了,无所谓放到左边右边了。
二.join时:空key过多,或者相同key过多
空key可能是异常数据,两个表联接时,联接的字段作为key,可能有很多null值,也可能集中出现在某个值上。这样就导致了他们经过计算得出的哈希值都一样,然后把它们都放到一个reduce里面,导致这几个reduce的压力过大,其他reduce很轻松的场面,也就是我们所谓的数据倾斜。
这里我们有两种常用的解决办法:第一种是将两表联接之前就去掉这些null值,然后再union all加上是空值的全部数据。比如要联接user和log:
select * from log a join user b on a.userid is not null and a.userid=b.userid union all select * from log c where c.userid is null;
第二种办法就是赋予空值新的key值,通过随机数将他们赋给不同的reduce:
这里什么意思呢?就是null现在通过计算不都是一个哈希值嘛,那就给他们赋随机数,这样通过计算就会分配到不同的分区了。
select * from log a left join user b on case when a.userid is null then concat('hive',rand()) else a.userid end =b.userid;
三.join时:不同数据类型关联产生数据倾斜
比如两个表联接,联接的字段是userid,一个表的userid是string类型,一个表的是int类型,那这样默认按照int来计算哈希的话,那么string类型的都会被分到同一组,易发生数据倾斜。
解决办法就是把数字类型 id 转换成 string 类型的 id,或者统一即可。
四.join时:大表和不大不小的表联接
如果此时的小表不大不小,不能发生mapjoin,有什么优化方法呢?假如联接的字段是userid,这里如果这个“大表”或者“小表”有比较多重复的userid,那么我们也可以优化。
我们这里假设大表有较多重复的userid,解决方案就是就是先给“大表”的userid去重然后再联接另一个表,此时去重后大表可能会变成小表,这样又可以mapjoin,查询完以后再右连接原先的这个大表。比如这时的log表是大表,有很多重复的userid,users表是小表,但也超过了25M。
select from log a left join (select d* from (select distinct userid from log)c join users d on c.userid=d.userid)x on a.userid=x.userid
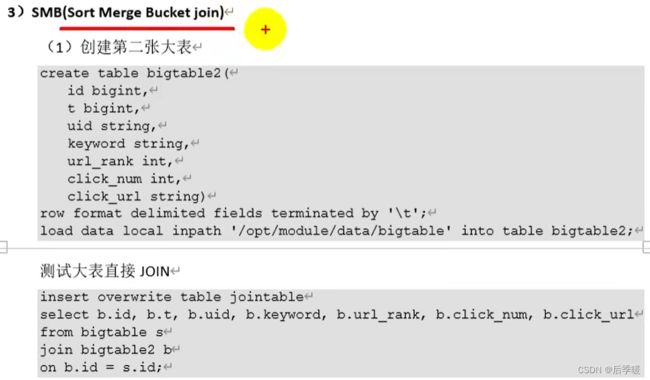
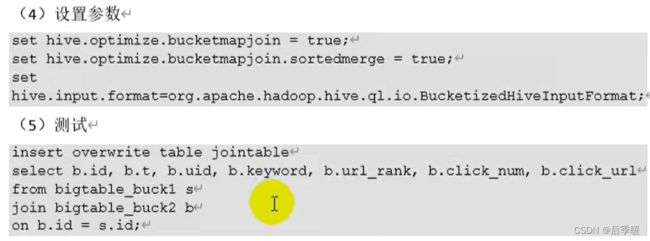
五.join时:大表联接大表
两个大表联查,分桶优化,根据id分桶,id是字符型数值,通过计算哈希值会计算出自己在第几桶,所以一个桶对应一个桶就行,这样效率提高很多。
一个桶对应一个桶,0桶对应0桶联查,1桶对应1桶联查...(因为一样的id肯定在一个对应的桶里)
代码演示:


六. 没有join时:group by发生的数据倾斜
group by引起的倾斜主要是输入数据行按照group by列分布不均匀引起的。
比如,有个key值有100W个a,此时直接做分组的话,这100W个a将会分到同一个reduce中,这一个节点处理的数据远大于其他节点处理的数据,造成数据倾斜,跑不出数据。其原因就是有大量的key集中分配到了同一个reduce,那么我们的解决思路就是将这些key值打散,使起分散到多个reduce节点处理即可,达到负载均衡的效果。解决办法:(2)可以不动

七.没有join时:count distinct优化
在Hive开发过程中,应该小心使用count distinct,因为很容易引起性能问题,比如下面的SQL:
select count(distinct userid) from t1;
由于必须去重,因此Hive将会把Map阶段的输出全部分布到一个Reduce Task上,此时很容易引起性能问题。对于这种情况,可以通过先group by再count的方式来优化,优化后的SQL如下:
select count(*) from (select user from t1 group by userid) a;
其原理为:利用group by去重,再统计group by的行数目(不过这种方式需要注意数据倾斜的问题)。
八.行列过滤 优化
谓词下推 用在SQL优化上来说 就是先过滤再做聚合等操作
因为两个表的关联字段是id 想要在关联以后在用where过滤 实际上底层已经优化了 关联之前就将两个表过滤了 但有时候sql写的长的时候 谓词下推会失效 所以有点不靠谱的
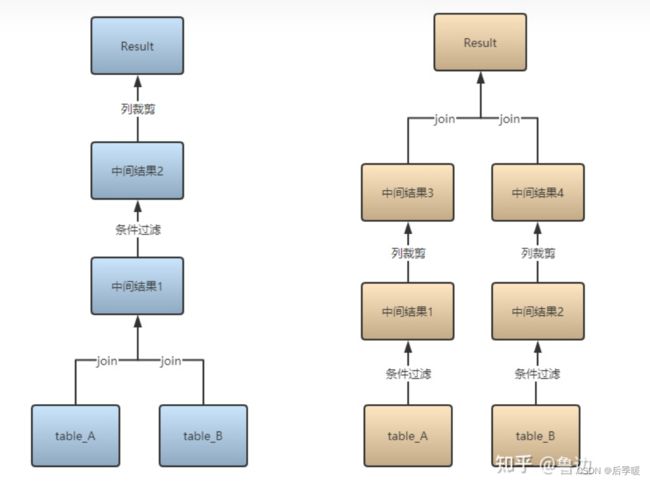
(该图来自知乎)