OpenCV-Python学习—基础知识
(一)OpenCV-Python学习—基础知识
原文:https://www.cnblogs.com/silence-cho/p/10926248.html
opencv是一个强大的图像处理和计算机视觉库,实现了很多实用算法,值得学习和深究下。
1.opencv包安装
· 这里直接安装opencv-python包(非官方): pip install opencv-python
官方文档:https://opencv-python-tutroals.readthedocs.io/en/latest/
2. opencv简单图像处理
2.1 图像像素存储形式
首先得了解下图像在计算机中存储形式:(为了方便画图,每列像素值都写一样了)
对于只有黑白颜色的灰度图,为单通道,一个像素块对应矩阵中一个数字,数值为0到255, 其中0表示最暗(黑色) ,255表示最亮(白色)

对于采用RGB模式的彩色图片,为三通道图,Red、Green、Blue三原色,按不同比例相加,一个像素块对应矩阵中的一个向量, 如[24,180, 50],分别表示三种颜色的比列, 即对应深度上的数字,如下图所示:

需要注意的是,由于历史遗留问题,opencv采用BGR模式,而不是RGB
2.2 图像读取和写入
cv2.imread()
imread(img_path,flag) 读取图片,返回图片对象
img_path: 图片的路径,即使路径错误也不会报错,但打印返回的图片对象为None
flag:cv2.IMREAD_COLOR,读取彩色图片,图片透明性会被忽略,为默认参数,也可以传入1
cv2.IMREAD_GRAYSCALE,按灰度模式读取图像,也可以传入0
cv2.IMREAD_UNCHANGED,读取图像,包括其alpha通道,也可以传入-1cv2.imshow()

imshow(window_name,img):显示图片,窗口自适应图片大小
window_name: 指定窗口的名字
img:显示的图片对象
可以指定多个窗口名称,显示多个图片
waitKey(millseconds) 键盘绑定事件,阻塞监听键盘按键,返回一个数字(不同按键对应的数字不同)
millseconds: 传入时间毫秒数,在该时间内等待键盘事件;传入0时,会一直等待键盘事件
destroyAllWindows(window_name)
window_name: 需要关闭的窗口名字,不传入时关闭所有窗口
cv2.imwrite()
imwrite(img_path_name,img)
img_path_name:保存的文件名
img:文件对象使用示例:
 View Code
View Code
2.3 图像像素获取和编辑
像素值获取:
img = cv2.imread(r"C:\Users\Administrator\Desktop\roi.jpg")
#获取和设置
pixel = img[100,100] #[57 63 68],获取(100,100)处的像素值
img[100,100]=[57,63,99] #设置像素值
b = img[100,100,0] #57, 获取(100,100)处,blue通道像素值
g = img[100,100,1] #63
r = img[100,100,2] #68
r = img[100,100,2]=99 #设置red通道值
#获取和设置
piexl = img.item(100,100,2)
img.itemset((100,100,2),99)
图片性质
import cv2
img = cv2.imread(r"C:\Users\Administrator\Desktop\roi.jpg")
#rows,cols,channels
img.shape #返回(280, 450, 3), 宽280(rows),长450(cols),3通道(channels)
#size
img.size #返回378000,所有像素数量,=280*450*3
#type
img.dtype #dtype('uint8')
ROI截取(Range of Interest)
#ROI,Range of instrest
roi = img[100:200,300:400] #截取100行到200行,列为300到400列的整块区域
img[50:150,200:300] = roi #将截取的roi移动到该区域 (50到100行,200到300列)
b = img[:,:,0] #截取整个蓝色通道
b,g,r = cv2.split(img) #截取三个通道,比较耗时
img = cv2.merge((b,g,r))
2.4 添加边界(padding)
cv2.copyMakeBorder()
参数:
img:图像对象
top,bottom,left,right: 上下左右边界宽度,单位为像素值
borderType:
cv2.BORDER_CONSTANT, 带颜色的边界,需要传入另外一个颜色值
cv2.BORDER_REFLECT, 边缘元素的镜像反射做为边界
cv2.BORDER_REFLECT_101/cv2.BORDER_DEFAULT
cv2.BORDER_REPLICATE, 边缘元素的复制做为边界
CV2.BORDER_WRAP
value: borderType为cv2.BORDER_CONSTANT时,传入的边界颜色值,如[0,255,0]
使用示例:
View Code

2.5 像素算术运算
cv2.add() 相加的两个图片,应该有相同的大小和通道
cv2.add()
参数:
img1:图片对象1
img2:图片对象2
mask:None (掩膜,一般用灰度图做掩膜,img1和img2相加后,和掩膜与运算,从而达到掩盖部分区域的目的)
dtype:-1
注意:图像相加时应该用cv2.add(img1,img2)代替img1+img2
>>> x = np.uint8([250])
>>> y = np.uint8([10])
>>> print cv2.add(x,y) # 250+10 = 260 => 255 #相加,opencv超过255的截取为255
[[255]]
>>> print x+y # 250+10 = 260 % 256 = 4 #相加,np超过255的会取模运算 (uint8只能表示0-255,所以取模)
[4]
使用示例:图一无掩膜,图二有掩膜
View Code


cv.addWeight(): 两张图片相加,分别给予不同权重,实现图片融合和透明背景等效果
cv2.addWeighted() 两张图片相加,分别给予不同权重,实现图片融合和透明背景等效果
参数:
img1:图片对象1
alpha:img1的权重
img2:图片对象2
beta:img1的权重
gamma:常量值,图像相加后再加上常量值
dtype:返回图像的数据类型,默认为-1,和img1一样
(img1*alpha+img2*beta+gamma)
使用示例:
View Code

2.6 图像位运算
btwise_and(), bitwise_or(), bitwise_not(), bitwise_xor()
cv2.btwise_and(): 与运算
参数:
img1:图片对象1
img2:图片对象2
mask:掩膜
cv2.bitwise_or():或运算
参数:
img1:图片对象1
img2:图片对象2
mask:掩膜
cv2.bitwise_not(): 非运算
img1:图片对象1
mask:掩膜
cv2.bitwise_xor():异或运算,相同为1,不同为0(1^1=0,1^0=1)
img1:图片对象1
img2:图片对象2
mask:掩膜
使用示例:将logo图片移动到足球图片中,需要截取logo图片的前景和足球图片ROI的背景,然后叠加,效果如下:
View Code

2.7 图像颜色空间转换
cv2.cvtColor()
cv2.cvtColor()
参数:
img: 图像对象
code:
cv2.COLOR_RGB2GRAY: RGB转换到灰度模式
cv2.COLOR_RGB2HSV: RGB转换到HSV模式(hue,saturation,Value)
cv2.inRange()
参数:
img: 图像对象/array
lowerb: 低边界array, 如lower_blue = np.array([110,50,50])
upperb:高边界array, 如 upper_blue = np.array([130,255,255])
mask = cv2.inRange(hsv, lower_green, upper_green)
2.8 性能评价
cv2.getTickCount(): 获得时钟次数
cv2.getTickFrequency():获得时钟频率 (每秒振动次数)
img1 = cv2.imread('messi5.jpg')
e1 = cv2.getTickCount()
for i in xrange(5,49,2):
img1 = cv2.medianBlur(img1,i)
e2 = cv2.getTickCount()
t = (e2 - e1)/cv2.getTickFrequency()
print t
2.9 绑定trackbar到图像
cv2.createTrackbar()
cv2.getTrackbarPos()
cv2.createTrackbar() 为窗口添加trackbar
参数:
trackbarname: trackbar的名字
winname: 窗口的名字
value: trackbar创建时的值
count:trackbar能设置的最大值,最小值总为0
onChange:trackbar值发生变化时的回调函数,trackbar的值作为参数传给onchange
cv2.getTrackbarPos() 获取某个窗口中trackbar的值
参数:
trackbarname: trackbar的名字
winname: 窗口的名字
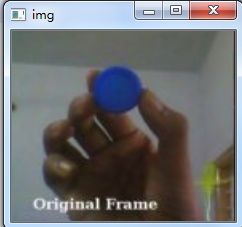
使用示例:通过改变trackbar的值,来寻找最优的mask范围,从而识别出图片中蓝色的瓶盖

#coding:utf-8
import cv2 as cv
import numpy as np
def nothing(args):
pass
img = cv.imread(r"C:\Users\Administrator\Desktop\frame.png")
img_hsv = cv.cvtColor(img,cv.COLOR_BGR2HSV)
cv.namedWindow('tracks')
cv.createTrackbar("LH","tracks",0,255,nothing)
cv.createTrackbar("LS","tracks",0,255,nothing)
cv.createTrackbar("LV","tracks",0,255,nothing)
cv.createTrackbar("UH","tracks",255,255,nothing)
cv.createTrackbar("US","tracks",255,255,nothing)
cv.createTrackbar("UV","tracks",255,255,nothing)
# switch = "0:OFF \n1:ON"
# cv.createTrackbar(switch,"tracks",0,1,nothing)
while(1):
l_h = cv.getTrackbarPos("LH","tracks")
l_s = cv.getTrackbarPos("LS","tracks")
l_v = cv.getTrackbarPos("LV","tracks")
u_h = cv.getTrackbarPos("UH","tracks")
u_s = cv.getTrackbarPos("US","tracks")
u_v = cv.getTrackbarPos("UV","tracks")
lower_b = np.array([l_h,l_s,l_v])
upper_b = np.array([u_h,u_s,u_v])
mask = cv.inRange(img_hsv,lower_b,upper_b)
res = cv.add(img,img,mask=mask)
cv.imshow("img",img)
cv.imshow("mask",mask)
cv.imshow("res",res)
k = cv.waitKey(1)
if k==27:
break
# print(r,g,b)
# if s==0:
# img[:]=0
# else:
# img[:]=
cv.destroyAllWindows()

3. 图像阈值化
cv2.threshold()
cv2.adaptiveThreshold()
cv2.threshold():
参数:
img:图像对象,必须是灰度图
thresh:阈值
maxval:最大值
type:
cv2.THRESH_BINARY: 小于阈值的像素置为0,大于阈值的置为maxval
cv2.THRESH_BINARY_INV: 小于阈值的像素置为maxval,大于阈值的置为0
cv2.THRESH_TRUNC: 小于阈值的像素不变,大于阈值的置为thresh
cv2.THRESH_TOZERO 小于阈值的像素置0,大于阈值的不变
cv2.THRESH_TOZERO_INV 小于阈值的不变,大于阈值的像素置0
返回两个值
ret:阈值
img:阈值化处理后的图像
cv2.adaptiveThreshold() 自适应阈值处理,图像不同部位采用不同的阈值进行处理
参数:
img: 图像对象,8-bit单通道图
maxValue:最大值
adaptiveMethod: 自适应方法
cv2.ADAPTIVE_THRESH_MEAN_C :阈值为周围像素的平均值
cv2.ADAPTIVE_THRESH_GAUSSIAN_C : 阈值为周围像素的高斯均值(按权重)
threshType:
cv2.THRESH_BINARY: 小于阈值的像素置为0,大于阈值的置为maxValuel
cv2.THRESH_BINARY_INV: 小于阈值的像素置为maxValue,大于阈值的置为0
blocksize: 计算阈值时,自适应的窗口大小,必须为奇数 (如3:表示附近3个像素范围内的像素点,进行计算阈值)
C: 常数值,通过自适应方法计算的值,减去该常数值
(mean value of the blocksize*blocksize neighborhood of (x, y) minus C)
使用示例:
View Code

奥斯二值化(Otsu's Binarization)
对于一些双峰图像,奥斯二值化能找到两峰之间的像素值作为阈值,并将其返回。适用于双峰图像的阈值化,或者通过去噪而产生的双峰图像。
官网使用示例:
View Code 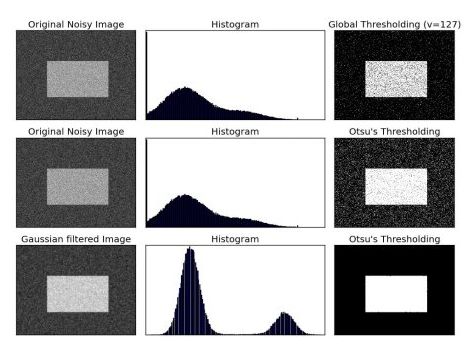
4. 图像形状变换
4.1 cv2.resize() 图像缩放
cv2.resize() 放大和缩小图像
参数:
src: 输入图像对象
dsize:输出矩阵/图像的大小,为0时计算方式如下:dsize = Size(round(fx*src.cols),round(fy*src.rows))
fx: 水平轴的缩放因子,为0时计算方式: (double)dsize.width/src.cols
fy: 垂直轴的缩放因子,为0时计算方式: (double)dsize.heigh/src.rows
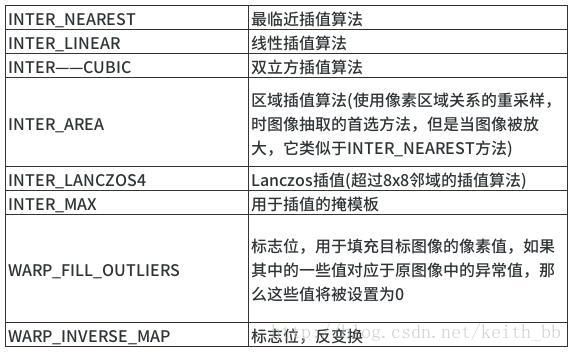
interpolation:插值算法
cv2.INTER_NEAREST : 最近邻插值法
cv2.INTER_LINEAR 默认值,双线性插值法
cv2.INTER_AREA 基于局部像素的重采样(resampling using pixel area relation)。对于图像抽取(image decimation)来说,这可能是一个更好的方法。但如果是放大图像时,它和最近邻法的效果类似。
cv2.INTER_CUBIC 基于4x4像素邻域的3次插值法
cv2.INTER_LANCZOS4 基于8x8像素邻域的Lanczos插值
cv2.INTER_AREA 适合于图像缩小, cv2.INTER_CUBIC (slow) & cv2.INTER_LINEAR 适合于图像放大
官网示例:
图像放大两倍
4.2 cv2.warpAffine() 仿射变换
仿射变换(从二维坐标到二维坐标之间的线性变换,且保持二维图形的“平直性”和“平行性”。仿射变换可以通过一系列的原子变换的复合来实现,包括平移,缩放,翻转,旋转和剪切)
cv2.warpAffine() 仿射变换(从二维坐标到二维坐标之间的线性变换,且保持二维图形的“平直性”和“平行性”。仿射变换可以通过一系列的原子变换的复合来实现,包括平移,缩放,翻转,旋转和剪切)
参数:
img: 图像对象
M:2*3 transformation matrix (转变矩阵)
dsize:输出矩阵的大小,注意格式为(cols,rows) 即width对应cols,height对应rows
flags:可选,插值算法标识符,有默认值INTER_LINEAR,
如果插值算法为WARP_INVERSE_MAP, warpAffine函数使用如下矩阵进行图像转dst(x,y)=src(M11*x+M12*y+M13,M21*x+M22*y+M23)
borderMode:可选, 边界像素模式,有默认值BORDER_CONSTANT
borderValue:可选,边界取值,有默认值Scalar()即0
常用插值算法:
仿射变换的本质:即一个矩阵A和向量B共同组成的转变矩阵,和原图像坐标相乘来得到新图像的坐标,从而实现图像移动,旋转等。如下矩阵A和向量B组成的转变矩阵M,用来对原图像的坐标(x,y)进行转变,得到新的坐标向量T
矩阵A和向量B
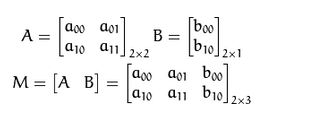
仿射变换(矩阵计算):变换前坐标(x,y)
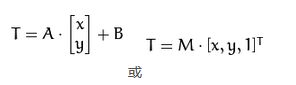
变换结果:变换后坐标(a00*x+a01 *y+b00, a10*x+a11*y+b10)

4.2.1 平移变换
了解了仿射变换的概念,平移变换只是采用了一个如下的转变矩阵(transformation matrix): 从(x,y)平移到(x+tx, y+ty)

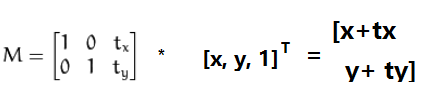
官网使用示例:向左平移100,向下平移50
View Code
4.2.2 放大和缩小
放大和缩小指相对于原坐标(x,y),变换为了(a*x, b*y),即水平方向放大了a倍,水平方向放大了b倍,其对应的转变矩阵如下:

4.2.3 旋转变换
将(x,y),以坐标原点为中心,顺时针方向旋转α得到(x1,y1), 有如下关系x1 = xcosα-ysinα, y1 =xsinα+ycosα; 因此可以构建对应的转变矩阵如下: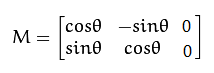
opencv将其扩展到,任意点center为中心进行顺时针旋转α,放大scale倍的,转变矩阵如下:

通过getRotationMatrix2D()能得到转变矩阵
cv2.getRotationMatrix2D() 返回2*3的转变矩阵(浮点型)
参数:
center:旋转的中心点坐标
angle:旋转角度,单位为度数,证书表示逆时针旋转
scale:同方向的放大倍数4.2.4 仿射变换矩阵的计算
通过上述的平移,缩放,旋转的组合变换即实现了仿射变换,上述多个变换的变换矩阵相乘即能得到组合变换的变换矩阵。同时该变换矩阵中涉及到六个未知数(2*3的矩阵),通过变换前后对应三组坐标,也可以求出变换矩阵,opencv提供了函数getAffineTransform()来计算变化矩阵
1> 矩阵相乘:将平移,旋转和缩放的变换矩阵相乘,最后即为仿射变换矩阵
2> getAffineTransform():根据变换前后三组坐标计算变换矩阵
cv2.getAffineTransform() 返回2*3的转变矩阵
参数:
src:原图像中的三组坐标,如np.float32([[50,50],[200,50],[50,200]])
dst: 转换后的对应三组坐标,如np.float32([[10,100],[200,50],[100,250]])官网使用示例:
View Code
4.3 透视变换(persperctive transformation)
仿射变换都是在二维空间的变换,透视变换(投影变换)是在三维空间中发生了旋转。需要前后四组坐标来计算对应的转变矩阵,opencv提供了函数getPerspectiveTransform()来计算转变矩阵,cv2.wrapPerspective()函数来进行透视变换。其对应参数如下:
cv2.getPerspectiveTransform() 返回3*3的转变矩阵
参数:
src:原图像中的四组坐标,如 np.float32([[56,65],[368,52],[28,387],[389,390]])
dst: 转换后的对应四组坐标,如np.float32([[0,0],[300,0],[0,300],[300,300]])
cv2.wrapPerspective()
参数:
src: 图像对象
M:3*3 transformation matrix (转变矩阵)
dsize:输出矩阵的大小,注意格式为(cols,rows) 即width对应cols,height对应rows
flags:可选,插值算法标识符,有默认值INTER_LINEAR,
如果插值算法为WARP_INVERSE_MAP, warpAffine函数使用如下矩阵进行图像转dst(x,y)=src(M11*x+M12*y+M13,M21*x+M22*y+M23)
borderMode:可选, 边界像素模式,有默认值BORDER_CONSTANT
borderValue:可选,边界取值,有默认值Scalar()即0
官网使用示例:
View Code
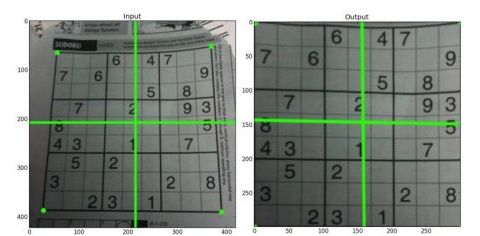
从上图中可以透视变换的一个应用,如果能找到原图中纸张的四个顶点,将其转换到新图中纸张的四个顶点,能将歪斜的roi区域转正,并进行放大;如在书籍,名片拍照上传后进行识别时,是一个很好的图片预处理方法。
官方文档:https://docs.opencv.org/3.0-beta/modules/imgproc/doc/miscellaneous_transformations.html?highlight=adaptivethreshold#cv2.adaptiveThreshold
Tutorial:https://opencv-python-tutroals.readthedocs.io/en/latest/py_tutorials/py_gui/py_trackbar/py_trackbar.html#trackbar