Python+大数据-数据分析与处理(六)-综合案例
Python+大数据-数据分析与处理(六)-综合案例
案例一:Appstore数据分析
-
学习目标
-
掌握描述性数据分析流程
-
能够使用pandas、seaborn进行数据分析和可视化
1.案例介绍
案例背景:
- 对 App 下载和评分数据分析,帮助 App 开发者获取和留存用户
- 通过对应用商店的数据分析为开发人员提供可操作的意见
分析需求:
- 免费和收费的 App 都集中在哪些类别
- 收费 App 的价格是如何分布的,不同类别的价格分布怎样
- App文件的大小和价格以及用户评分之间是否有关
分析流程:
1)数据概况分析
- 数据行/列数量
- 缺失值分布
2)单变量分析
- 数字型变量的描述指标(平均值,最小值,最大值,标准差等)
- 类别型变量(多少个分类,各自占比)
3)多变量分析
- 按类别交叉对比
- 变量之间的相关性分析
4)可视化分析
- 分布趋势(直方图)
- 不同组差异(柱状图)
- 相关性(散点图/热力图)
数据集说明:
本案例使用 applestore.csv 数据集,其数据字段如下:
| 字段 | 说明 |
|---|---|
id |
App ID:每个 App 唯一标识 |
track_name |
App 的名称 |
size_bytes |
以 bytes 为单位的 App 大小 |
price |
定价(美元) |
rating_count_tot |
App 所有版本的用户评分数量 |
rating_count_ver |
App 当前版本的用户评分数量 |
prime_genre |
App 的类别 |
user_rating |
App 所有版本的用户评分 |
sup_devices.num |
支持的 iOS 设备数量 |
ipadSc_urls.num |
App 提供的截屏展示数量 |
lang.num |
支持的语言数量 |
2. 数据清洗
# 加载数据
import pandas as pd
app = pd.read_csv('./data/applestore.csv',index_col=0)
app

# 查看数据集的字段信息
app.info()

# 查看数据集的各个字段统计值
app.describe()

# 查看是否有缺失值
app.shape
(7197, 10)
# 将sizebytes 大小变成mb ,新增size_mb列
app['size_mb'] = app['size_bytes']/(1024*1024)
app
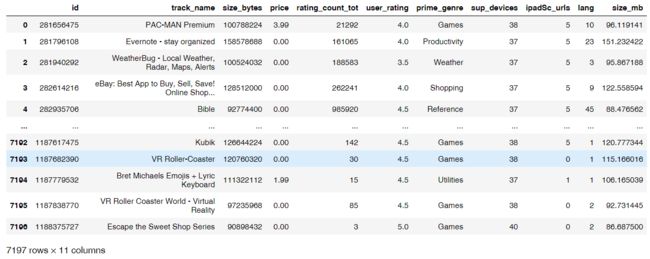
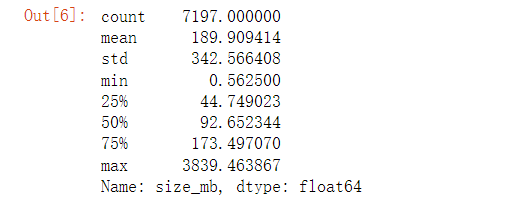
# 查看size_mb 列的统计值
app.size_mb.describe()
# 根据价格新增是否免费paid列 判断免费为0 不免费为1
app['paid'] = app['price'].apply(lambda x : 1 if x>0 else 0)
app

# 查看paid列统计信息
#s.value_counts()`统计 Series 数据中不同元素的个数
app['paid'].value_counts()

3.单变量分析
# 查看app 的结果是如何分布的
app.price.value_counts()

# 将按照价格app数据进行分组
# pandas.cut()函数可以将数据进行分类成不同的区间值
bins = [0,2,10,30]
labels=['<2','<10','<30']
# 分组 bins代表分组区间,默认是左开右闭 左闭右开 right=False labels 显示区间
app['price_new'] = pd.cut(app.price,bins ,right=False,labels=labels)
app.head(20)

# 分组后查看数据分布情况
# `df.groupby(列标签, ...).列标签.聚合函数()`按指定列分组,并对分组 数据的相应列进行相应的 聚合操作
app.groupby('price_new')['price'].describe()

# 查看不同类别app价格如何分布的
app.groupby('prime_genre')['price'].describe()
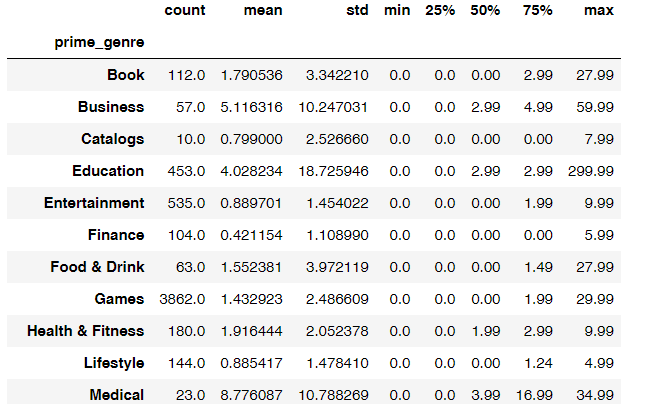
# 删除价格大于49.99的app数据
app = app[app['price']<= 49.99]
app.head()

# 利用app所有版本的评分数量对数据进行分组
app.rating_count_tot.describe()
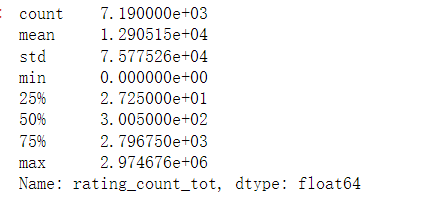
4.业务数据可视化
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
# app 评分关系
# height:关键字来控制图片高度
# aspect:控制宽高比例
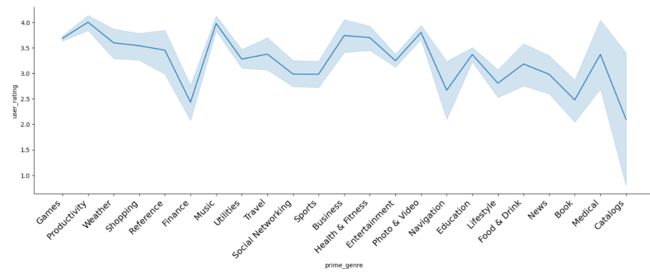
sns.relplot(x='prime_genre', y='user_rating', kind='line', data=app, height=5, aspect=3)
# 将 x 轴文字旋转45度
plt.xticks(
rotation=45,
horizontalalignment='right',
fontweight='light',
fontsize='x-large'
)
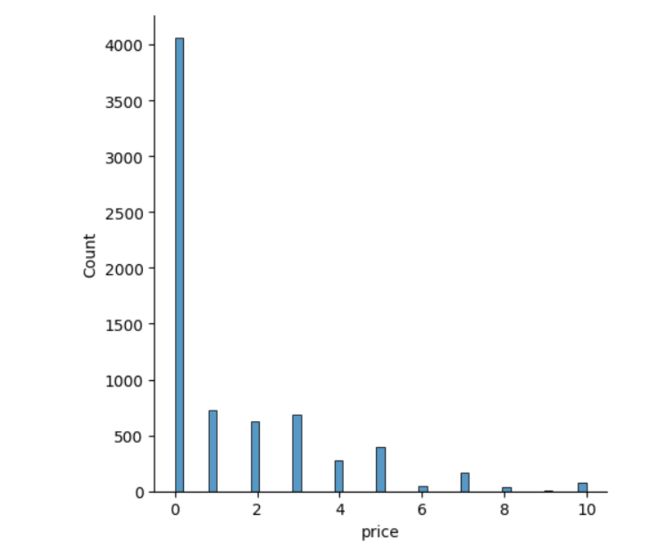
# c查看价格小于9.99元的app价格分布
plt.figure(figsize=(20,8))
#筛选出price<=9.99的app数据
app_result = app[app['price']<=9.99]
sns.displot(app_result['price'])
# 查看不同类别的收费APP的价格分布
plt.figure(figsize=(20, 8))
sns.boxplot(x='price', y='prime_genre', data=app[app['paid']==1])
plt.yticks(fontweight='light', fontsize='x-large')

# 查看数量最多的前 5 个类别收费 App 的价格分布
# 筛选出数量最多的前 5 类 App 的数据
top5 = app.groupby('prime_genre')['price'].count().sort_values(ascending=False).head()
app5 = app[app.prime_genre.isin(top5.index)]
# 绘制箱线图
plt.figure(figsize=(20, 8))
sns.boxplot(x='price', y='prime_genre', data=app5[app5['paid']==1])

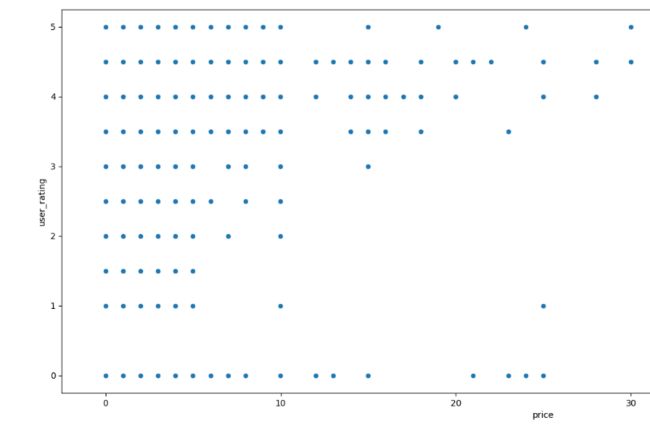
# 查看 App 数据中价格和用户评分的关系,绘制散点图
plt.figure(figsize=(20, 8))
sns.scatterplot(x='price', y='user_rating', data=app)
# 同一类别,将免费和付费的评分进行对比
plt.figure(figsize=(20, 8))
sns.barplot(x='prime_genre', y='user_rating', data=app5, hue='paid')

5.业务解读
-
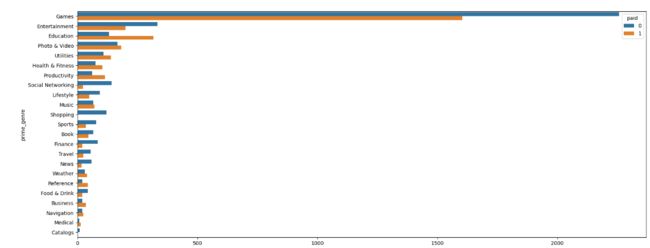
业务问题1:免费或收费 App 集中在哪些类别?
#第一步:将数据统计出每个类别有多少个app
#第二步:从高到低进行排列
#第三步:将数据进行可视化
plt.figure(figsize=(20,8))
#参数 order指定数据显示的顺序
sns.countplot(y='prime_genre',data=app,
order=app['prime_genre'].value_counts().index,hue='paid')
-
业务问题2:免费与收费的 App 在不同评分区间的分布?
#将评分进行分箱,查看落入不同箱中应用的数量
bins =[0,0.5,2.5,4.5,5.1]
app['rating_level'] = pd.cut(app.user_rating,bins,right=False)
app.groupby('rating_level')['user_rating'].describe()

py# 数据可视化
plt.figure(figsize=(20,8))
sns.countplot(x='paid',data=app,hue='rating_level')

-
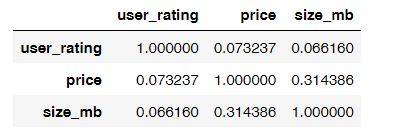
业务问题3:APP的价格、大小和用户评分之间有关系吗?
# 通过corr计算APP的价格,大小和用户评价之间的关系
app[['user_rating','price','size_mb']].corr()
# 通过热力图来查看变量之间两两的相关系数
plt.figure(figsize=(20,8))
sns.heatmap(app[['user_rating','price','size_mb']].corr())

案例二: 优衣库销售数据分析
-
学习目标
- 掌握描述性数据分析流程
- 能够使用pandas、seaborn进行数据分析和可视化
1.案例介绍
案例背景:
- 数据集中包含了不同城市优衣库门店的销售记录
- 通过对销售数据的分析,为运营提供一些有益信息
分析需求:
- 不同产品的销售情况,顾客喜欢的购买方式
- 销售额和成本之间的关系
- 购买时间偏好
数据集说明:
本案例使用 uniqlo.csv 数据集,其数据字段如下:
| 字段 | 说明 |
|---|---|
store_id |
门店随机id |
city |
城市 |
channel |
销售渠道:网购自提、门店购买 |
gender_group |
客户性别:男、女 |
age_group |
客户年龄段 |
wkd_ind |
购买发生的时间:周末、周间 |
product |
产品类别 |
customer |
客户数量 |
revenue |
销售金额 |
order |
订单数量 |
quant |
购买产品的数量 |
unit_cost |
成本(制作+运营) |
2.加载数据
# 加载数据
#不同产品的销售情况,顾客喜欢的购买方式
#销售额和成本之间的关系
#购买时间偏好
import pandas as pd
uniqlo = pd.read_csv('./data/uniqlo.csv')
uniqlo
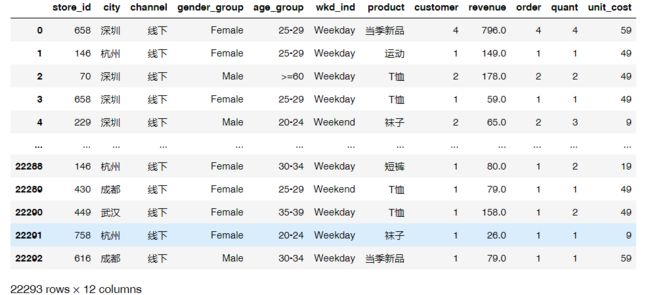
# 查看数据的字段信息
uniqlo.info()

#查看非空
uniqlo.shape
(22293, 12)
# 查看数据字段的统计信息
uniqlo.describe()

# 查看销售金额小于1的数据信息
uniqlo[uniqlo.revenue<1]

# 查看销售金额大于5000的数据信息
uniqlo[uniqlo.revenue>5000]

3. 业务解读
-
不同产品的销售情况
# 统计不同种类产品的订单情况
uniqlo.groupby('product')['order'].sum().sort_values(ascending=False)

# 统计不同种类产品的销量
uniqlo.groupby('product')['quant'].sum().sort_values(ascending=False)

py# 进一步拆解,按城市拆解销量
uniqlo.pivot_table(values='quant',
index='product',
columns='city',
aggfunc='sum').sort_values('上海',ascending=False)

# 对城市拆解后,在进一步按下上线拆解
uniqlo.pivot_table(values='quant',
index='product',
columns=['city','channel'],
aggfunc='sum')

-
用户习惯使用哪种方式进行消费
# 使用不同消费方式的订单数量
uniqlo.groupby('channel').order.sum()

y#进一步按城市拆解
uniqlo.pivot_table(index='city',columns='channel',
values='order',aggfunc='sum').sort_values('线上',ascending=False)

# 进一步统计线上线下销售额
uniqlo.pivot_table(values='quant',index='city',
columns='channel',aggfunc='sum')

-
用户消费习惯(周间还是周末)
#统计用户周间,周末消费的整体情况
uniqlo.wkd_ind.value_counts()

# 通过数据透视表,查看不同城市周间,周末销售情况
wkd_sales = uniqlo.pivot_table(values='quant',index='wkd_ind',
columns='city',aggfunc='sum')
wkd_sales

# 添加字段,计算每天的销售额
wkd_sales.loc['weekday_avg',:]= wkd_sales.loc['Weekday',:] /5
wkd_sales.loc['weekend_avg',:]= wkd_sales.loc['Weekend',:] /2
wkd_sales

-
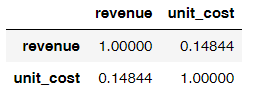
销售额和成本之间的关系
# 计算销售额和成本之间的相关系数
uniqlo[['revenue','unit_cost']].corr()
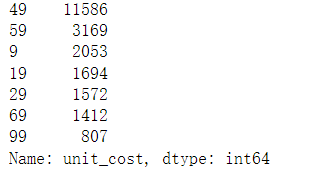
y# 进一步查看unit_cost
uniqlo.unit_cost.value_counts()
#筛选出销售额大于1的销售额
uniqlo2 = uniqlo[uniqlo.revenue>1]
uniqlo2.head()

# 添加单件收入列,并计算单件收入和单位成本计算相似度
uniqlo2['rev_per_goods'] = uniqlo2['revenue'] / uniqlo2['quant']
uniqlo2[['rev_per_goods','unit_cost']].corr()

p# 绘制热力图
sns.heatmap(uniqlo2[['rev_per_goods', 'unit_cost']].corr())
