| [转]支持向量机学习笔记 |
| 支持向量机学习笔记 呕心沥血整理的SVM学习笔记,完整总结了SVM的思想和整个求解过程,里面有诸多本人在学习过程中的想法,希望对初学者有帮助! pdf下载地址:
http://download.csdn.net/detail/u013337691/9771283
链接:http://pan.baidu.com/s/1gfOKhrX 密码:12l9 
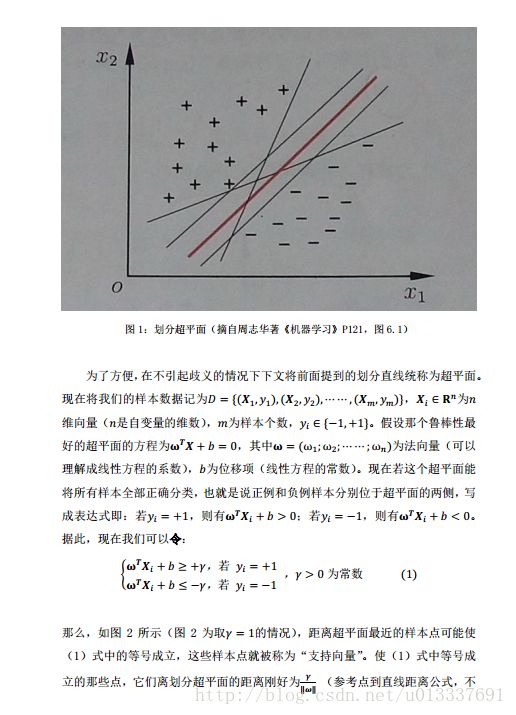






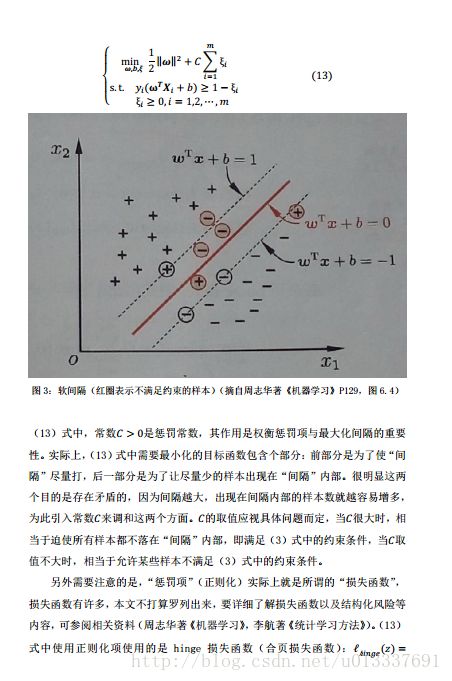


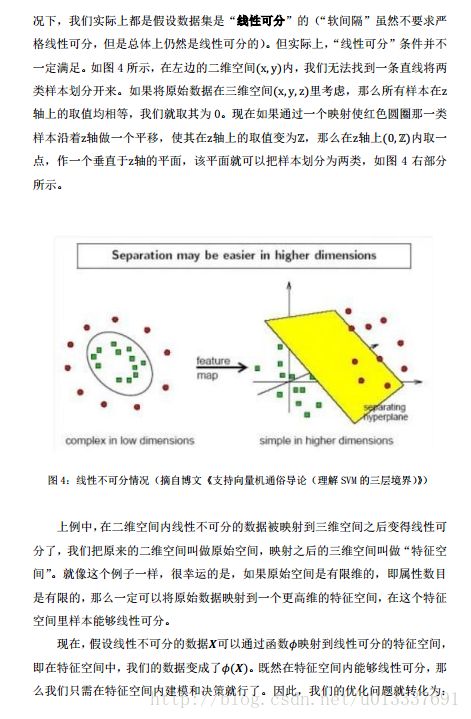







作者:u013337691 发表于2017/3/5 23:31:26 原文链接
阅读:85 评论:0 查看评论
|
| |
| [原]混合灰狼优化(HGWO,DE-GWO)算法matlab源码 |
| 说明:博主所有博文及源码中示例所用的支持向量机算法均使用faruto改进的LIBSVM工具箱3.1版本,详细可参见faruto博客http://blog.sina.com.cn/u/1291365075以及http://www.matlabsky.com/thread-17936-1-1.html。 今天学习一个比较新的优化算法,用差分进化(DE)改进原始的灰狼优化(GWO)得到的HGWO(也可以叫DE-GWO)算法。仍然以优化SVR参数为例,需要的同学可以根据需要自己修改源码。 完整程序和示例文件地址:http://download.csdn.net/detail/u013337691/9675376
百度云链接: http://pan.baidu.com/s/1qYvVguS 密码: i7ie function [bestc,bestg,test_pre]=my_HGWO_SVR(para,input_train,output_train,input_test,output_test)
[input_train,rule1]=mapminmax(input_train');
[output_train,rule2]=mapminmax(output_train');
input_test=mapminmax('apply',input_test',rule1);
output_test=mapminmax('apply',output_test',rule2);
input_train=input_train';
output_train=output_train';
input_test=input_test';
output_test=output_test';
nPop=para(1);
MaxIt=para(2);
nVar=2;
VarSize=[1,nVar];
beta_min=para(3);
beta_max=para(4);
pCR=para(5);
lb=[0.01,0.01];
ub=[100,100];
parent_Position=init_individual(lb,ub,nVar,nPop);
parent_Val=zeros(nPop,1);
for i=1:nPop
parent_Val(i)=fobj(parent_Position(i,:),input_train,output_train,input_test,output_test);
end
mutant_Position=init_individual(lb,ub,nVar,nPop);
mutant_Val=zeros(nPop,1);
for i=1:nPop
mutant_Val(i)=fobj(mutant_Position(i,:),input_train,output_train,input_test,output_test);
end
child_Position=init_individual(lb,ub,nVar,nPop);
child_Val=zeros(nPop,1);
for i=1:nPop
child_Val(i)=fobj(child_Position(i,:),input_train,output_train,input_test,output_test);
end
[~,sort_index]=sort(parent_Val);
parent_Alpha_Position=parent_Position(sort_index(1),:);
parent_Alpha_Val=parent_Val(sort_index(1));
parent_Beta_Position=parent_Position(sort_index(2),:);
parent_Delta_Position=parent_Position(sort_index(3),:);
BestCost=zeros(1,MaxIt);
BestCost(1)=parent_Alpha_Val;
for it=1:MaxIt
a=2-it*((2)/MaxIt);
for par=1:nPop
for var=1:nVar
r1=rand();
r2=rand();
A1=2*a*r1-a;
C1=2*r2;
D_alpha=abs(C1*parent_Alpha_Position(var)-parent_Position(par,var));
X1=parent_Alpha_Position(var)-A1*D_alpha;
r1=rand();
r2=rand();
A2=2*a*r1-a;
C2=2*r2;
D_beta=abs(C2*parent_Beta_Position(var)-parent_Position(par,var));
X2=parent_Beta_Position(var)-A2*D_beta;
r1=rand();
r2=rand();
A3=2*a*r1-a;
C3=2*r2;
D_delta=abs(C3*parent_Delta_Position(var)-parent_Position(par,var));
X3=parent_Delta_Position(var)-A3*D_delta;
X=(X1+X2+X3)/3;
X=max(X,lb(var));
X=min(X,ub(var));
parent_Position(par,var)=X;
end
parent_Val(par)=fobj(parent_Position(par,:),input_train,output_train,input_test,output_test);
end
for mut=1:nPop
A=randperm(nPop);
A(A==i)=[];
a=A(1);
b=A(2);
c=A(3);
beta=unifrnd(beta_min,beta_max,VarSize);
y=parent_Position(a)+beta.*(parent_Position(b)-parent_Position(c));
y=max(y,lb);
y=min(y,ub);
mutant_Position(mut,:)=y;
end
for child=1:nPop
x=parent_Position(child,:);
y=mutant_Position(child,:);
z=zeros(size(x));
j0=randi([1,numel(x)]);
for var=1:numel(x)
if var==j0 || rand<=pCR
z(var)=y(var);
else
z(var)=x(var);
end
end
child_Position(child,:)=z;
child_Val(child)=fobj(z,input_train,output_train,input_test,output_test);
end
for par=1:nPop
if child_Val(par)
function x=init_individual(xlb,xub,dim,sizepop)
xRange=repmat((xub-xlb),[sizepop,1]);
xLower=repmat(xlb,[sizepop,1]);
x=rand(sizepop,dim).*xRange+xLower;
%% SVR_fitness -- objective function
function fitness=fobj(cv,input_train,output_train,input_test,output_test)
% cv为长度为2的横向量,即SVR中参数c和v的值
cmd = ['-s 3 -t 2',' -c ',num2str(cv(1)),' -g ',num2str(cv(2))];
model=svmtrain(output_train,input_train,cmd); % SVM模型训练
[~,fitness]=svmpredict(output_test,input_test,model); % SVM模型预测及其精度
fitness=fitness(2); % 以平均均方误差MSE作为优化的目标函数值
clear
clc
close all
load wndspd
input_train(1,:)=wndspd(1:97);
input_train(2,:)=wndspd(2:98);
input_train(3,:)=wndspd(3:99);
output_train=[wndspd(4:100)]';
input_test(1,:)=wndspd(101:end-3);
input_test(2,:)=wndspd(102:end-2);
input_test(3,:)=wndspd(103:end-1);
output_test=(wndspd(104:end))';
para=[30,500,0.2,0.8,0.2];
[bestc,bestg,test_pre]=my_HGWO_SVR(para,input_train',output_train',input_test',output_test');
err_pre=output_test'-test_pre;
figure('Name','测试数据残差图')
set(gcf,'unit','centimeters','position',[0.5,5,30,5])
plot(err_pre,'*-');
figure('Name','原始-预测图')
plot(test_pre,'*r-');hold on;plot(output_test,'bo-');
legend('预测','原始',0)
set(gcf,'unit','centimeters','position',[0.5,13,30,5])
toc
参考文章:Aijun Zhu, Chuanpei Xu, Zhi Li, Jun Wu, and Zhenbing Liu. Hybridizing grey wolf optimization with differential evolution for global optimization and test scheduling for 3D stacked SoC. Journal of Systems Engineering and Electronics Vol. 26, No. 2, April 2015, pp.317–328.
文章地址:http://ieeexplore.ieee.org/document/7111168/ (广告)欢迎扫描关注微信公众号:Genlovhyy的数据小站(Gnelovy212) 
作者:u013337691 发表于2016/11/7 17:00:40 原文链接
阅读:970 评论:2 查看评论
|
| |
| [原]DE(差分进化)优化算法MATLAB源码详细中文注解 |
| 以优化SVR算法的参数c和g为例,对DE(差分进化)算法MATLAB源码进行了详细中文注解。
完整程序和示例文件地址:http://download.csdn.net/detail/u013337691/9671714
百度云链接: http://pan.baidu.com/s/1dEYAHS9 密码: 6xw5 function [bestc,bestg,test_pre]=my_DE_SVR(para,input_train,output_train,input_test,output_test)
[input_train,rule1]=mapminmax(input_train');
[output_train,rule2]=mapminmax(output_train');
input_test=mapminmax('apply',input_test',rule1);
output_test=mapminmax('apply',output_test',rule2);
input_train=input_train';
output_train=output_train';
input_test=input_test';
output_test=output_test';
nPop=para(1);
MaxIt=para(2);
nVar=2;
VarSize=[1,nVar];
beta_min=para(3);
beta_max=para(4);
pCR=para(5);
lb=[0.01,0.01];
ub=[100,100];
empty_individual.Position=[];
empty_individual.Cost=[];
BestSol.Cost=inf;
pop=repmat(empty_individual,nPop,1);
for i=1:nPop
pop(i).Position=init_individual(lb,ub,nVar,1);
pop(i).Cost=fobj(pop(i).Position,input_train,output_train,input_test,output_test);
if pop(i).Cost<BestSol.Cost
BestSol=pop(i);
end
end
BestCost=zeros(MaxIt,1);
for it=1:MaxIt
for i=1:nPop
x=pop(i).Position;
A=randperm(nPop);
A(A==i)=[];
a=A(1);
b=A(2);
c=A(3);
beta=unifrnd(beta_min,beta_max,VarSize);
y=pop(a).Position+beta.*(pop(b).Position-pop(c).Position);
y=max(y,lb);
y=min(y,ub);
z=zeros(size(x));
j0=randi([1,numel(x)]);
for j=1:numel(x)
if j==j0 || rand<=pCR
z(j)=y(j);
else
z(j)=x(j);
end
end
NewSol.Position=z;
NewSol.Cost=fobj(NewSol.Position,input_train,output_train,input_test,output_test);
if NewSol.Costi).Cost
pop(i)=NewSol;
if pop(i).Cost<BestSol.Cost
BestSol=pop(i);
end
end
end
BestCost(it)=BestSol.Cost;
end
bestc=BestSol.Position(1,1);
bestg=BestSol.Position(1,2);
plot(BestCost);
xlabel('Iteration');
ylabel('Best Val');
grid on;
cmd_cs_svr=['-s 3 -t 2',' -c ',num2str(bestc),' -g ',num2str(bestg)];
model_cs_svr=svmtrain(output_train,input_train,cmd_cs_svr);
[output_test_pre,~]=svmpredict(output_test,input_test,model_cs_svr);
test_pre=mapminmax('reverse',output_test_pre',rule2);
test_pre = test_pre';
%% SVR_fitness -- objective function
function fitness=fobj(cv,input_train,output_train,input_test,output_test)
% cv为长度为2的横向量,即SVR中参数c和v的值
cmd = ['-s 3 -t 2',' -c ',num2str(cv(1)),' -g ',num2str(cv(2))];
model=svmtrain(output_train,input_train,cmd); % SVM模型训练
[~,fitness]=svmpredict(output_test,input_test,model); % SVM模型预测及其精度
fitness=fitness(2); % 以平均均方误差MSE作为优化的目标函数值
function x=init_individual(xlb,xub,dim,sizepop)
xRange=repmat((xub-xlb),[sizepop,1]);
xLower=repmat(xlb,[sizepop,1]);
x=rand(sizepop,dim).*xRange+xLower;
clear
clc
close all
load wndspd % 示例数据为风速(时间序列)数据,共144个样本
%% PSO-SVR
% 训练/测试数据准备(用前3天预测后一天),用前100天做训练数据
input_train(1,:)=wndspd(1:97);
input_train(2,:)=wndspd(2:98);
input_train(3,:)=wndspd(3:99);
output_train=[wndspd(4:100)]';
input_test(1,:)=wndspd(101:end-3);
input_test(2,:)=wndspd(102:end-2);
input_test(3,:)=wndspd(103:end-1);
output_test=[wndspd(104:end)]';
para=[30,200,0.2,0.8,0.2];
[bestc,bestg,test_pre]=my_DE_SVR(para,input_train',output_train',input_test',output_test');
% 预测误差计算
MSE=mymse(output_test',test_pre)
MAE=mymae(output_test',test_pre)
MAPE=mymape(output_test',test_pre)
FVD=myfvd(output_test',test_pre)
CDFR=mycdfr(output_test',test_pre)
%% 预测结果图
err_pre=output_test'-test_pre;
figure('Name','测试数据残差图')
set(gcf,'unit','centimeters','position',[0.5,5,30,5])
plot(err_pre,'*-');
figure('Name','原始-预测图')
plot(test_pre,'*r-');hold on;plot(output_test,'bo-');
legend('预测','原始',0)
set(gcf,'unit','centimeters','position',[0.5,13,30,5])
toc
本文参考:http://cn.mathworks.com/matlabcentral/fileexchange/52897-differential-evolution–de-?s_tid=srchtitle (广告)欢迎扫描关注微信公众号:Genlovhyy的数据小站(Gnelovy212)

作者:u013337691 发表于2016/11/3 10:18:45 原文链接
阅读:1290 评论:0 查看评论
|
| |
| [转]GSA(引力搜索)优化算法MATLAB源码详细中文注解 |
| 以优化SVM算法的参数c和g为例,对GSA(引力搜索)算法MATLAB源码进行了详细中文注解。
完整程序和示例文件地址:http://download.csdn.net/detail/u013337691/9645312 tic % 计时器
%% 清空环境变量
close all
clear
clc
format compact
%% 数据提取
% 载入测试数据wine,其中包含的数据为classnumber = 3,wine:178*13的矩阵,wine_labes:178*1的列向量
load wine.mat
% 选定训练集和测试集
% 将第一类的1-30,第二类的60-95,第三类的131-153做为训练集
train_wine = [wine(1:30,:);wine(60:95,:);wine(131:153,:)];
% 相应的训练集的标签也要分离出来
train_wine_labels = [wine_labels(1:30);wine_labels(60:95);wine_labels(131:153)];
% 将第一类的31-59,第二类的96-130,第三类的154-178做为测试集
test_wine = [wine(31:59,:);wine(96:130,:);wine(154:178,:)];
% 相应的测试集的标签也要分离出来
test_wine_labels = [wine_labels(31:59);wine_labels(96:130);wine_labels(154:178)];
%% 数据预处理
% 数据预处理,将训练集和测试集归一化到[0,1]区间
[mtrain,ntrain] = size(train_wine);
[mtest,ntest] = size(test_wine);
dataset = [train_wine;test_wine];
% mapminmax为MATLAB自带的归一化函数
[dataset_scale,ps] = mapminmax(dataset',0,1);
dataset_scale = dataset_scale';
train_wine = dataset_scale(1:mtrain,:);
test_wine = dataset_scale( (mtrain+1):(mtrain+mtest),: );
%% GSA优化参数
N=20; % 群体规模 Number of agents.
max_it=30; % 最大迭代次数 Maximum number of iterations (T).
ElitistCheck=1; % 如果ElitistCheck=1,则使用文献中的公式21;如果ElitistCheck=0,则用文献中的公式9.
Rpower=1;% 文献中公式7中的R的幂次数 power of 'R' in eq.7.
min_flag=1; % 取1求解极小值问题,取0求解极大值问题 1: minimization, 0: maximization.
objfun=@objfun_svm; % 目标函数
[Fbest,Lbest,BestChart,MeanChart]=GSA_svm(objfun,N,max_it,ElitistCheck,min_flag,Rpower,...
train_wine_labels,train_wine,test_wine_labels,test_wine);
% Fbest: 最优目标值 Best result.
% Lbest: 最优解 Best solution. The location of Fbest in search space.
% BestChart: 最优解变化趋势 The best so far Chart over iterations.
% MeanChart: 平均适应度函数值变化趋势 The average fitnesses Chart over iterations.
%% 打印参数选择结果
bestc=Lbest(1);
bestg=Lbest(2);
disp('打印选择结果');
str=sprintf('Best c = %g,Best g = %g',bestc,bestg);
disp(str)
%% 利用最佳的参数进行SVM网络训练
cmd_gwosvm = ['-c ',num2str(bestc),' -g ',num2str(bestg)];
model_gwosvm = svmtrain(train_wine_labels,train_wine,cmd_gwosvm);
%% SVM网络预测
[predict_label,accuracy] = svmpredict(test_wine_labels,test_wine,model_gwosvm);
% 打印测试集分类准确率
total = length(test_wine_labels);
right = sum(predict_label == test_wine_labels);
disp('打印测试集分类准确率');
str = sprintf( 'Accuracy = %g%% (%d/%d)',accuracy(1),right,total);
disp(str);
%% 结果分析
% 测试集的实际分类和预测分类图
figure;
hold on;
plot(test_wine_labels,'o');
plot(predict_label,'r*');
xlabel('测试集样本','FontSize',12);
ylabel('类别标签','FontSize',12);
legend('实际测试集分类','预测测试集分类');
title('测试集的实际分类和预测分类图','FontSize',12);
grid on
%% 最优适应度变化曲线
figure('Name','最优适应度变化曲线')
plot(BestChart,'--k');
title('最优适应度变化曲线');
xlabel('\fontsize{12}\bf Iteration');ylabel('\fontsize{12}\bf Best-so-far');
legend('\fontsize{10}\bf GSA',1);
%% 显示程序运行时间
toc
function [Fbest,Lbest,BestChart,MeanChart]=GSA_svm(objfun,N,max_it,ElitistCheck,min_flag,Rpower,...
train_wine_labels,train_wine,test_wine_labels,test_wine)
Rnorm=2;
low=0.01;
up=100;
dim=2;
X=initialization(dim,N,up,low);
BestChart=zeros(1,max_it);
MeanChart=zeros(1,max_it);
V=zeros(N,dim);
for iteration=1:max_it
X=space_bound(X,up,low);
fitness=zeros(1,N);
for agent=1:N
fitness(1,agent)=objfun(X(agent,:),train_wine_labels,train_wine,test_wine_labels,test_wine);
end
if min_flag==1
[best,best_X]=min(fitness);
else
[best,best_X]=max(fitness);
end
if iteration==1
Fbest=best;
Lbest=X(best_X,:);
end
if min_flag==1
if best
function X=initialization(dim,N,up,down)
if size(up,2)==1
X=rand(N,dim).*(up-down)+down;
end
if size(up,2)>1
for i=1:dim
high=up(i);
low=down(i);
X(:,i)=rand(N,1).*(high-low)+low;
end
end
function M =massCalculation(fit,min_flag)
Fmax=max(fit);
Fmin=min(fit);
[~,N]=size(fit);
if Fmax==Fmin
M=ones(N,1);
else
if min_flag==1
best=Fmin;
worst=Fmax;
else
best=Fmax;
worst=Fmin;
end
M=(fit-worst)./(best-worst);
end
M=M./sum(M);
% This function calculates Gravitational constant. eq.13.
function G=Gconstant(iteration,max_it)
% here, make your own function of 'G'.
alfa=20;
G0=100;
G=G0*exp(-alfa*iteration/max_it); % eq.28.
function a=Gfield(M,X,G,Rnorm,Rpower,ElitistCheck,iteration,max_it)
[N,dim]=size(X);
final_per=2;
if ElitistCheck==1
kbest=final_per+(1-iteration/max_it)*(100-final_per);
kbest=round(N*kbest/100);
else
kbest=N;
end
[~,ds]=sort(M,'descend');
E=zeros(N,dim);
for i=1:N
E(i,:)=zeros(1,dim);
for ii=1:kbest
j=ds(ii);
if j~=i
R=norm(X(i,:)-X(j,:),Rnorm);
for k=1:dim
E(i,k)=E(i,k)+rand*(M(j))*((X(j,k)-X(i,k))/(R^Rpower+eps));
end
end
end
end
a=E.*G;
function [X,V]=move(X,a,V)
[N,dim]=size(X);
V=rand(N,dim).*V+a;
X=X+V;
function X=space_bound(X,up,low)
[N,dim]=size(X);
for i=1:N
Tp=X(i,:)>up;
Tm=X(i,:)i,:)=(X(i,:).*(~(Tp+Tm)))+((rand(1,dim).*(up-low)+low).*logical((Tp+Tm)));
%% SVM_Objective Function
function f=objfun_svm(cv,train_wine_labels,train_wine,test_wine_labels,test_wine)
% cv为长度为2的横向量,即SVM中参数c和v的值
cmd = [' -c ',num2str(cv(1)),' -g ',num2str(cv(2))];
model=svmtrain(train_wine_labels,train_wine,cmd); % SVM模型训练
[~,fitness]=svmpredict(test_wine_labels,test_wine,model); % SVM模型预测及其精度
f=1-fitness(1)/100; % 以分类预测错误率作为优化的目标函数值
参考文献:E. Rashedi, H. Nezamabadi-pour and S. Saryazdi,
GSA: A Gravitational Search Algorithm,Information sciences, vol. 179,no. 13, pp. 2232-2248, 2009. (广告)欢迎扫描关注微信公众号:Genlovhyy的数据小站(Gnelovy212) 
作者:u013337691 发表于2016/10/4 9:17:38 原文链接
阅读:960 评论:0 查看评论
|
| |
| [原]SA(模拟退火)优化算法MATLAB源码详细中文注解 |
| 以优化SVM算法的参数c和g为例,对SA(模拟退火)算法MATLAB源码进行了逐行中文注解。
完整程序和示例文件地址:http://download.csdn.net/detail/u013337691/9644107
链接:http://pan.baidu.com/s/1i5G0gPB 密码:4ge8
tic
clear
clc
close all
format compact
load wine.mat
train_wine = [wine(1:30,:);wine(60:95,:);wine(131:153,:)];
train_wine_labels = [wine_labels(1:30);wine_labels(60:95);wine_labels(131:153)];
test_wine = [wine(31:59,:);wine(96:130,:);wine(154:178,:)];
test_wine_labels = [wine_labels(31:59);wine_labels(96:130);wine_labels(154:178)];
[mtrain,ntrain] = size(train_wine);
[mtest,ntest] = size(test_wine);
dataset = [train_wine;test_wine];
[dataset_scale,ps] = mapminmax(dataset',0,1);
dataset_scale = dataset_scale';
train_wine = dataset_scale(1:mtrain,:);
test_wine = dataset_scale( (mtrain+1):(mtrain+mtest),: );
lb=[0.01,0.01];
ub=[100,100];
MarkovLength=100;
DecayScale=0.85;
StepFactor=0.2;
Temperature0=8;
Temperatureend=3;
Boltzmann_con=1;
AcceptPoints=0.0;
range=ub-lb;
Par_cur=rand(size(lb)).*range+lb;
Par_best_cur=Par_cur;
Par_best=rand(size(lb)).*range+lb;
t=Temperature0;
itr_num=0;
while t>Temperatureend
itr_num=itr_num+1;
t=DecayScale*t;
for i=1:MarkovLength
p=0;
while p==0
Par_new=Par_cur+StepFactor.*range.*(rand(size(lb))-0.5);
if sum(Par_new>ub)+sum(Par_new0
p=1;
end
end
if (objfun_svm(Par_best,train_wine_labels,train_wine,test_wine_labels,test_wine)>...
objfun_svm(Par_new,train_wine_labels,train_wine,test_wine_labels,test_wine))
Par_best_cur=Par_best;
Par_best=Par_new;
end
if (objfun_svm(Par_cur,train_wine_labels,train_wine,test_wine_labels,test_wine)-...
objfun_svm(Par_new,train_wine_labels,train_wine,test_wine_labels,test_wine)>0)
Par_cur=Par_new;
AcceptPoints=AcceptPoints+1;
else
changer=-1*(objfun_svm(Par_new,train_wine_labels,train_wine,test_wine_labels,test_wine)...
-objfun_svm(Par_cur,train_wine_labels,train_wine,test_wine_labels,test_wine))/Boltzmann_con*Temperature0;
p1=exp(changer);
if p1>rand
Par_cur=Par_new;
AcceptPoints=AcceptPoints+1;
end
end
end
end
disp(['最小值在点:',num2str(Par_best)]);
Objval_best= objfun_svm(Par_best,train_wine_labels,train_wine,test_wine_labels,test_wine);
disp(['最小值为:',num2str(Objval_best)]);
toc
%% SVM_Objective Function
function f=objfun_svm(cv,train_wine_labels,train_wine,test_wine_labels,test_wine)
% cv为长度为2的横向量,即SVM中参数c和v的值
cmd = [' -c ',num2str(cv(1)),' -g ',num2str(cv(2))];
model=svmtrain(train_wine_labels,train_wine,cmd); % SVM模型训练
[~,fitness]=svmpredict(test_wine_labels,test_wine,model); % SVM模型预测及其精度
f=1-fitness(1)/100; % 以分类预测错误率作为优化的目标函数值
(广告)欢迎扫描关注微信公众号:Genlovhyy的数据小站(Gnelovy212) 
作者:u013337691 发表于2016/9/30 16:24:18 原文链接
阅读:164 评论:0 查看评论
|
| |
| [原]FA(萤火虫算法)MATLAB源码详细中文注解 |
| 以优化SVM算法的参数c和g为例,对FA(萤火虫算法)MATLAB源码进行了逐行中文注解。
完整程序和示例文件地址:http://download.csdn.net/detail/u013337691/9626263
链接:http://pan.baidu.com/s/1kVbd5cV 密码:7ym8 tic % 计时器
%% 清空环境变量
close all
clear
clc
format compact
%% 数据提取
% 载入测试数据wine,其中包含的数据为classnumber = 3,wine:178*13的矩阵,wine_labes:178*1的列向量
load wine.mat
% 选定训练集和测试集
% 将第一类的1-30,第二类的60-95,第三类的131-153做为训练集
train_wine = [wine(1:30,:);wine(60:95,:);wine(131:153,:)];
% 相应的训练集的标签也要分离出来
train_wine_labels = [wine_labels(1:30);wine_labels(60:95);wine_labels(131:153)];
% 将第一类的31-59,第二类的96-130,第三类的154-178做为测试集
test_wine = [wine(31:59,:);wine(96:130,:);wine(154:178,:)];
% 相应的测试集的标签也要分离出来
test_wine_labels = [wine_labels(31:59);wine_labels(96:130);wine_labels(154:178)];
%% 数据预处理
% 数据预处理,将训练集和测试集归一化到[0,1]区间
[mtrain,ntrain] = size(train_wine);
[mtest,ntest] = size(test_wine);
dataset = [train_wine;test_wine];
% mapminmax为MATLAB自带的归一化函数
[dataset_scale,ps] = mapminmax(dataset',0,1);
dataset_scale = dataset_scale';
train_wine = dataset_scale(1:mtrain,:);
test_wine = dataset_scale( (mtrain+1):(mtrain+mtest),: );
%% FA优化参数
% 参数向量 parameters [n N_iteration alpha betamin gamma]
% n为种群规模,N_iteration为迭代次数
para=[10,50,0.5,0.2,1];
% 待优化参数上下界 Simple bounds/limits for d-dimensional problems
d=2; % 待优化参数个数
Lb=[0.01,0.01]; % 下界
Ub=[100,100]; % 上界
% 参数初始化 Initial random guess
u0=Lb+(Ub-Lb).*rand(1,d);
% 迭代寻优 Display results
[bestsolutio,bestojb]=ffa_mincon_svm(@objfun_svm,u0,Lb,Ub,para,train_wine_labels,train_wine,test_wine_labels,test_wine);
%% 打印参数选择结果
bestc=bestsolutio(1);
bestg=bestsolutio(2);
disp('打印选择结果');
str=sprintf('Best c = %g,Best g = %g',bestc,bestg);
disp(str)
%% 利用最佳的参数进行SVM网络训练
cmd_gwosvm = ['-c ',num2str(bestc),' -g ',num2str(bestg)];
model_gwosvm = svmtrain(train_wine_labels,train_wine,cmd_gwosvm);
%% SVM网络预测
[predict_label,accuracy] = svmpredict(test_wine_labels,test_wine,model_gwosvm);
% 打印测试集分类准确率
total = length(test_wine_labels);
right = sum(predict_label == test_wine_labels);
disp('打印测试集分类准确率');
str = sprintf( 'Accuracy = %g%% (%d/%d)',accuracy(1),right,total);
disp(str);
%% 结果分析
% 测试集的实际分类和预测分类图
figure;
hold on;
plot(test_wine_labels,'o');
plot(predict_label,'r*');
xlabel('测试集样本','FontSize',12);
ylabel('类别标签','FontSize',12);
legend('实际测试集分类','预测测试集分类');
title('测试集的实际分类和预测分类图','FontSize',12);
grid on
%% 显示程序运行时间
toc
function [nbest,fbest]=ffa_mincon_svm(costfhandle,u0, Lb, Ub, para,train_wine_labels,train_wine,test_wine_labels,test_wine)
if nargin<5
para=[20 100 0.25 0.20 1];
end
if nargin<4
Ub=[];
end
if nargin<3
Lb=[];
end
if nargin<2
disp('Usuage: FA_mincon(@cost,u0,Lb,Ub,para)');
end
n=para(1);
MaxGeneration=para(2);
alpha=para(3);
betamin=para(4);
gamma=para(5);
if length(Lb) ~=length(Ub)
disp('Simple bounds/limits are improper!')
return
end
d=length(u0);
zn=ones(n,1)*10^100;
[ns,Lightn]=init_ffa(n,d,Lb,Ub,u0);
for k=1:MaxGeneration
alpha=alpha_new(alpha,MaxGeneration);
for i=1:n
zn(i)=costfhandle(ns(i,:),train_wine_labels,train_wine,test_wine_labels,test_wine);
Lightn(i)=zn(i);
end
[Lightn,Index]=sort(zn);
ns_tmp=ns;
for i=1:n
ns(i,:)=ns_tmp(Index(i),:);
end
nso=ns;
Lighto=Lightn;
nbest=ns(1,:);
Lightbest=Lightn(1);
fbest=Lightbest;
[ns]=ffa_move(n,d,ns,Lightn,nso,Lighto,alpha,betamin,gamma,Lb,Ub);
end
function [ns,Lightn]=init_ffa(n,d,Lb,Ub,u0)
ns=zeros(n,d);
if ~isempty(Lb)
for i=1:n
ns(i,:)=Lb+(Ub-Lb).*rand(1,d);
end
else
for i=1:n
ns(i,:)=u0+randn(1,d);
end
end
Lightn=ones(n,1)*10^100;
function [ns]=ffa_move(n,d,ns,Lightn,nso,Lighto,alpha,betamin,gamma,Lb,Ub)
scale=abs(Ub-Lb);
for i=1:n
for j=1:n
r=sqrt(sum((ns(i,:)-ns(j,:)).^2));
if Lightn(i)>Lighto(j)
beta0=1;
beta=(beta0-betamin)*exp(-gamma*r.^2)+betamin;
tmpf=alpha.*(rand(1,d)-0.5).*scale;
ns(i,:)=ns(i,:).*(1-beta)+nso(j,:).*beta+tmpf;
end
end
end
[ns]=findlimits(n,ns,Lb,Ub);
function alpha=alpha_new(alpha,NGen)
delta=1-(10^(-4)/0.9)^(1/NGen);
alpha=(1-delta)*alpha;
function [ns]=findlimits(n,ns,Lb,Ub)
for i=1:n
ns_tmp=ns(i,:);
I=ns_tmp
%% SVM_Objective Function
function f=objfun_svm(cv,train_wine_labels,train_wine,test_wine_labels,test_wine)
% cv为长度为2的横向量,即SVM中参数c和v的值
cmd = [' -c ',num2str(cv(1)),' -g ',num2str(cv(2))];
model=svmtrain(train_wine_labels,train_wine,cmd); % SVM模型训练
[~,fitness]=svmpredict(test_wine_labels,test_wine,model); % SVM模型预测及其精度
f=1-fitness(1)/100; % 以分类预测错误率作为优化的目标函数值
(广告)欢迎扫描关注微信公众号:Genlovhyy的数据小站(Gnelovy212) 
作者:u013337691 发表于2016/9/9 15:13:27 原文链接
阅读:330 评论:0 查看评论
|
| |
| [原]GWO(灰狼优化)算法MATLAB源码逐行中文注解 |
| 以优化SVM算法的参数c和g为例,对GWO算法MATLAB源码进行了逐行中文注解。
完整程序和示例文件地址:http://download.csdn.net/detail/u013337691/9624866
链接:http://pan.baidu.com/s/1hrCheBE 密码:4p6m tic
close all
clear
clc
format compact
load wine.mat
train_wine = [wine(1:30,:);wine(60:95,:);wine(131:153,:)];
train_wine_labels = [wine_labels(1:30);wine_labels(60:95);wine_labels(131:153)];
test_wine = [wine(31:59,:);wine(96:130,:);wine(154:178,:)];
test_wine_labels = [wine_labels(31:59);wine_labels(96:130);wine_labels(154:178)];
[mtrain,ntrain] = size(train_wine);
[mtest,ntest] = size(test_wine);
dataset = [train_wine;test_wine];
[dataset_scale,ps] = mapminmax(dataset',0,1);
dataset_scale = dataset_scale';
train_wine = dataset_scale(1:mtrain,:);
test_wine = dataset_scale( (mtrain+1):(mtrain+mtest),: );
SearchAgents_no=10;
Max_iteration=10;
dim=2;
lb=[0.01,0.01];
ub=[100,100];
Alpha_pos=zeros(1,dim);
Alpha_score=inf;
Beta_pos=zeros(1,dim);
Beta_score=inf;
Delta_pos=zeros(1,dim);
Delta_score=inf;
Positions=initialization(SearchAgents_no,dim,ub,lb);
Convergence_curve=zeros(1,Max_iteration);
l=0;
while l
% This function initialize the first population of search agents
function Positions=initialization(SearchAgents_no,dim,ub,lb)
Boundary_no= size(ub,2); % numnber of boundaries
% If the boundaries of all variables are equal and user enter a signle
% number for both ub and lb
if Boundary_no==1
Positions=rand(SearchAgents_no,dim).*(ub-lb)+lb;
end
% If each variable has a different lb and ub
if Boundary_no>1
for i=1:dim
ub_i=ub(i);
lb_i=lb(i);
Positions(:,i)=rand(SearchAgents_no,1).*(ub_i-lb_i)+lb_i;
end
end
(广告)欢迎扫描关注微信公众号:Genlovhyy的数据小站(Gnelovy212) 
作者:u013337691 发表于2016/9/8 10:26:19 原文链接
阅读:764 评论:2 查看评论
|
| |
| [原]CS(布谷鸟搜索)算法MATLAB源码逐行中文注解 |
| 以优化SVM算法的参数c和g为例,对CS算法MATLAB源码进行了逐行中文注解。
完整程序和示例文件地址:http://download.csdn.net/detail/u013337691/9622335
链接:http://pan.baidu.com/s/1sl2BzKL 密码:pkdn tic % 计时
%% 清空环境导入数据
clear
clc
close all
load wndspd % 示例数据为风速(时间序列)数据,共144个样本
% 训练/测试数据准备(用前3天预测后一天),用前100天做测试数据
train_input(1,:)=wndspd(1:97);
train_input(2,:)=wndspd(2:98);
train_input(3,:)=wndspd(3:99);
train_output=[wndspd(4:100)]';
test_input(1,:)=wndspd(101:end-3);
test_input(2,:)=wndspd(102:end-2);
test_input(3,:)=wndspd(103:end-1);
test_output=[wndspd(104:end)]';
[input_train,rule1]=mapminmax(train_input);
[output_train,rule2]=mapminmax(train_output);
input_test=mapminmax('apply',test_input,rule1);
output_test=mapminmax('apply',test_output,rule2);
%% CS-SVR
time=20;
n=20; % n为巢穴数量
pa=0.25; % 被宿主发现的概率
dim = 2; % 需要寻优的参数个数
Lb=[0.01,0.01]; % 设置参数下界
Ub=[100,100]; % 设置参数上界
% 随机初始化巢穴
nest=zeros(n,dim);
for i=1:n % 遍历每个巢穴
nest(i,:)=Lb+(Ub-Lb).*rand(size(Lb)); % 对每个巢穴,随机初始化参数
end
fitness=ones(1,n); % 目标函数值初始化
[fmin,bestnest,nest,fitness]=get_best_nest(nest,nest,fitness,input_train,output_train,input_test,output_test); % 找出当前最佳巢穴和参数
%% 迭代开始
for t=1:time
new_nest=get_cuckoos(nest,bestnest,Lb,Ub); % 保留当前最优解,寻找新巢穴
[~,~,nest,fitness]=get_best_nest(nest,new_nest,fitness,input_train,output_train,input_test,output_test); % 找出当前最佳巢穴和参数
new_nest=empty_nests(nest,Lb,Ub,pa); % 发现并更新劣质巢穴
% 找出当前最佳巢穴和参数
[fnew,best,nest,fitness]=get_best_nest(nest,new_nest,fitness,input_train,output_train,input_test,output_test);
if fnewend
end
%% 打印参数选择结果
bestobjfun=fmin;
bestc=bestnest(1);
bestg=bestnest(2);
disp('打印参数选择结果');
str=sprintf('Best c = %g,Best g = %g',bestc,bestg);
disp(str)
%% 利用回归预测分析最佳的参数进行SVM网络训练
cmd_cs_svr=['-s 3 -t 2',' -c ',num2str(bestnest(1)),' -g ',num2str(bestnest(2))];
model_cs_svr=svmtrain(output_train',input_train',cmd_cs_svr); % SVM模型训练
%% SVM网络回归预测
[output_test_pre,acc]=svmpredict(output_test',input_test',model_cs_svr); % SVM模型预测及其精度
test_pre=mapminmax('reverse',output_test_pre',rule2);
test_pre = test_pre';
err_pre=wndspd(104:end)-test_pre;
figure('Name','测试数据残差图')
set(gcf,'unit','centimeters','position',[0.5,5,30,5])
plot(err_pre,'*-');
figure('Name','原始-预测图')
plot(test_pre,'*r-');hold on;plot(wndspd(104:end),'bo-');
legend('预测','原始')
set(gcf,'unit','centimeters','position',[0.5,13,30,5])
result=[wndspd(104:end),test_pre];
MAE=mymae(wndspd(104:end),test_pre)
MSE=mymse(wndspd(104:end),test_pre)
MAPE=mymape(wndspd(104:end),test_pre)
%% 显示程序运行时间
toc
(广告)欢迎扫描关注微信公众号:Genlovhyy的数据小站(Gnelovy212)

作者:u013337691 发表于2016/9/5 18:53:51 原文链接
阅读:347 评论:1 查看评论
|
| |
| [原]ABC(智能蜂群算法)优化SVM_源码逐行中文注解 |
| 最近发现要彻底、快速地弄懂一个算法,最好的办法就是找源码来,静下心,一行一行的学习。所以我把ABC算法的源码找来逐行做了中文注释,并以优化SVM参数为例,进行学习。 废话不多说,直接上MATLAB代码(ABC-SVR): tic % 计时
%% 清空环境,准备数据
clear
clc
close all
load wndspd % 示例数据为风速(时间序列)数据,共144个样本
% 训练/测试数据准备(用前3天预测后一天),用前100天的数据做训练
train_input(1,:)=wndspd(1:97);
train_input(2,:)=wndspd(2:98);
train_input(3,:)=wndspd(3:99);
train_output=[wndspd(4:100)]';
test_input(1,:)=wndspd(101:end-3);
test_input(2,:)=wndspd(102:end-2);
test_input(3,:)=wndspd(103:end-1);
test_output=[wndspd(104:end)]';
% 数据归一化处理
[input_train,rule1]=mapminmax(train_input);
[output_train,rule2]=mapminmax(train_output);
input_test=mapminmax('apply',test_input,rule1);
output_test=mapminmax('apply',test_output,rule2);
%% %%%%%%%%%%%%%用ABC算法优化SVR中的参数c和g开始%%%%%%%%%%%%%%%%%%%%
%% 参数初始化
NP=20; % 蜂群规模
FoodNumber=NP/2; % 蜜源(解)数量
limit=100; % 当有蜜源连续没被更新的次数超过limit时,该蜜源将被重新初始化
maxCycle=10; % 最大迭代次数
% 待优化参数信息
D=2; % 待优化参数个数,次数为c和g两个
ub=ones(1,D)*100; % 参数取值上界,此处将c和g的上界设为100
lb=ones(1,D)*(0.01); % 参数取值下界,此处将c和g的下界设为0.01
runtime=2; % 可用于设置多次运行(让ABC算法运行runtime次)以考察程序的稳健性
BestGlobalMins=ones(1,runtime); % 全局最小值初始化,这里的优化目标为SVR预测结果中的平均平方误差(MSE),初始化为最差值1
BestGlobalParams=zeros(runtime,D); % 用于存放ABC算法优化得到的最优参数
for r=1:runtime % 运行ABC算法runtime次
% 初始化蜜源
Range = repmat((ub-lb),[FoodNumber 1]);
Lower = repmat(lb, [FoodNumber 1]);
Foods = rand(FoodNumber,D) .* Range + Lower;
% 计算每个蜜源(解)得目标函数值,fobj为计算SVR预测的平均平方误差(MSE)的函数,根据自己的实际问题变异目标函数即可
ObjVal=ones(1,FoodNumber);
for k = 1:FoodNumber
ObjVal(k) = fobj(Foods(k,:),input_train,output_train,input_test,output_test);
end
Fitness=calculateFitness(ObjVal); % 计算适应度函数值
trial=zeros(1,FoodNumber); % 用于记录第i个蜜源有连续trail(i)次没被更新过
% 标记最优蜜源(解)
BestInd=find(ObjVal==min(ObjVal));
BestInd=BestInd(end);
GlobalMin=ObjVal(BestInd); % 更新全局最优目标函数值
GlobalParams=Foods(BestInd,:); % 更新全局最优参数为最优蜜源
iter=1; % 迭代开始
while ((iter <= maxCycle)) % 循环条件
%%%%%%%%%%%%%%%%%%%%%引领蜂搜索解的过程%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
for i=1:(FoodNumber) % 遍历每个蜜源(解)
Param2Change=fix(rand*D)+1; % 随机选择需要变异的参数
neighbour=fix(rand*(FoodNumber))+1; % 随机选择相邻蜜源(解)以准备变异
% 需要保证选择的相邻蜜源不是当前蜜源(i)
while(neighbour==i)
neighbour=fix(rand*(FoodNumber))+1;
end
sol=Foods(i,:); % 提取当前蜜源(解)对应的的参数
% 参数变异得到新的蜜源:v_{ij}=x_{ij}+\phi_{ij}*(x_{kj}-x_{ij})
sol(Param2Change)=Foods(i,Param2Change)+(Foods(i,Param2Change)-Foods(neighbour,Param2Change))*(rand-0.5)*2;
% 确保参数取值范围不越界
ind=find(solub);
sol(ind)=ub(ind);
% 计算变异后蜜源的目标函数值和适应度函数值
ObjValSol=fobj(sol,input_train,output_train,input_test,output_test);
FitnessSol=calculateFitness(ObjValSol);
% 更新当前蜜源的相关信息
if (FitnessSol>Fitness(i))
Foods(i,:)=sol;
Fitness(i)=FitnessSol;
ObjVal(i)=ObjValSol;
trial(i)=0; % 如果当前蜜源被更新了,则对应的trial归零
else
trial(i)=trial(i)+1; % 如果当前蜜源没有被更新,则trial(i)加1
end
end
%%%%%%%%%%%%%%%%%%%%%%%% 跟随蜂搜索解的过程 %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% 计算解(蜜源)的概率
prob=(0.9.*Fitness./max(Fitness))+0.1;
% 循环初始化
i=1;
t=0;
while(t<FoodNumber) % 循环条件
if(rand1; % 循环计数器加1
Param2Change=fix(rand*D)+1; % 随机确定需要变异的参数
neighbour=fix(rand*(FoodNumber))+1; % 随机选择相邻蜜源(解)
% 需要保证选择的相邻蜜源不是当前蜜源(i)
while(neighbour==i)
neighbour=fix(rand*(FoodNumber))+1;
end
sol=Foods(i,:); % 提取当前蜜源i(解)对应的的参数
% 参数变异得到新的蜜源:v_{ij}=x_{ij}+\phi_{ij}*(x_{kj}-x_{ij})
sol(Param2Change)=Foods(i,Param2Change)+(Foods(i,Param2Change)-Foods(neighbour,Param2Change))*(rand-0.5)*2;
% 防止参数越界
ind=find(solub);
sol(ind)=ub(ind);
% 计算变异后蜜源的目标函数值和适应度函数值
ObjValSol=fobj(sol,input_train,output_train,input_test,output_test);
FitnessSol=calculateFitness(ObjValSol);
% 更新当前蜜源的相关信息
if (FitnessSol>Fitness(i))
Foods(i,:)=sol;
Fitness(i)=FitnessSol;
ObjVal(i)=ObjValSol;
trial(i)=0; % 如果当前蜜源被更新了,则对应的trial归零
else
trial(i)=trial(i)+1; % 如果当前蜜源没有被更新,则trial(i)加1
end
end
i=i+1; % 更新i
if (i==(FoodNumber)+1) % 若值超过蜜源数量,则i重新初始化
i=1;
end
end
% 记住最优蜜源
ind=find(ObjVal==min(ObjVal));
ind=ind(end);
if (ObjVal(ind)<GlobalMin)
GlobalMin=ObjVal(ind);
GlobalParams=Foods(ind,:);
end
%%%%%%%%%%%% 侦查蜂搜索解的过程 %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% 找出连续最多次都没有被更新的蜜源
ind=find(trial==max(trial));
ind=ind(end);
% 如果连续没有更新的次数大于限定次数,则由侦查蜂重新初始化该蜜源
if (trial(ind)>limit)
Bas(ind)=0;
sol=(ub-lb).*rand(1,D)+lb;
ObjValSol=fobj(sol,input_train,output_train,input_test,output_test);
FitnessSol=calculateFitness(ObjValSol);
Foods(ind,:)=sol;
Fitness(ind)=FitnessSol;
ObjVal(ind)=ObjValSol;
end
iter=iter+1;
end % 一次ABC算法完结
BestGlobalMins(r)=GlobalMin; % 记录本次ABC算法的最优目标函数值
BestGlobalParams(r,:)=GlobalParams; % 记录本次ABC算法的最优参数
end % end of runs
%% %%%%%%%%%%%%%用ABC算法优化SVR中的参数c和g结束%%%%%%%%%%%%%%%%%%%%
%% 打印参数选择结果,这里输出的是最后一次ABC算法寻优得到的参数
bestc=GlobalParams(1);
bestg=GlobalParams(2);
disp('打印选择结果');
str=sprintf('Best c = %g,Best g = %g',bestc,bestg);
disp(str)
%% 利用回归预测分析最佳的参数进行SVM网络训练
cmd_cs_svr=['-s 3 -t 2',' -c ',num2str(bestc),' -g ',num2str(bestg)];
model_cs_svr=svmtrain(output_train',input_train',cmd_cs_svr); % SVM模型训练
%% SVM网络回归预测
[output_test_pre,acc]=svmpredict(output_test',input_test',model_cs_svr); % SVM模型预测及其精度
test_pre=mapminmax('reverse',output_test_pre',rule2);
test_pre = test_pre';
err_pre=wndspd(104:end)-test_pre;
figure('Name','测试数据残差图')
set(gcf,'unit','centimeters','position',[0.5,5,30,5])
plot(err_pre,'*-');legend('预测残差:实际-预测',0);
figure('Name','原始-预测图')
plot(test_pre,'*r-');hold on;plot(wndspd(104:end),'bo-');
legend('预测','原始')
set(gcf,'unit','centimeters','position',[0.5,13,30,5])
result=[wndspd(104:end),test_pre];
MAE=mymae(wndspd(104:end),test_pre)
MSE=mymse(wndspd(104:end),test_pre)
MAPE=mymape(wndspd(104:end),test_pre)
%% 显示程序运行时间
toc
完整程序和示例数据文件下载地址:http://download.csdn.net/detail/u013337691/9621448 (广告)欢迎扫描关注微信公众号:Genlovhyy的数据小站(Gnelovy212)

作者:u013337691 发表于2016/9/4 17:22:57 原文链接
阅读:334 评论:0 查看评论
|
| |
| [原]用基于信息熵的topsis方法实现学生成绩的综合排名 |
| TOPSIS方法排序的基本思路是首先定义决策问题的正理想解(即最好的)和负理想解(即最坏的),然后把实际可行解(样本)和正理想解与负理想解作比较。通过计算实际可行解与正理想解和负理想解的加权欧氏距离,得出实际可行解与正理想解的接近程度,以此作为排序的依据。若某个可行解(样本)最靠近理想解,同时又最远离负理想解,则此解排序最靠前。
通常,当排序时有多个指标需要考虑时,常用“专家打分法”来确定各个指标的权重,这容易造成评价结果可能由于人的主观因素而形成较大偏差。熵值法能较客观地反映数据本身信息的有序性,它通过评价指标值构成的判断矩阵来确定指标的权重,这样能尽量消除各因素权重的主观性,使评价结果更符合实际。
下面通过MATLAB实现基于信息熵的topsis方法,学习代码的同时也就弄清楚topsis方法的原理了: %% 熵topsis方法的MATLAB实现,以“兰州大学数学与统计学院2015年应用统计硕士研究生复试分数”为例
%% 清空环境,导入数据
clear
clc
close all
% 兰州大学数学与统计学院2015年应用统计硕士研究生复试分数
% 成绩包括:初试总分X1、复试笔试成绩X2、复试专业面试成绩X3、复试外语笔试成绩X4、复试外语口语及听力测试成绩X5,共五个科目
% 原始排名计算方法:总分=(X1/5)*0.5+X2*0.2+(((X4+X5)/2)*0.2+X3*0.8)*0.3
load score
data=score(:,2:end);
%% 数据归一化处理
[n,m]=size(data);
maxdata=repmat(max(data),n,1);
mindata=repmat(min(data),n,1);
max_min=maxdata-mindata;
stddata=(data-mindata)./max_min;
%% 利用信息熵计算不同科目的权重
f=(1+stddata)./repmat(sum(1+stddata),n,1);
e=-1/log(n)*sum(f.*log(f));
d=1-e;
w=d/sum(d); % 权重向量
%% 计算加权决策矩阵,确定正理想解和负理想解
normdata=repmat(w,n,1).*stddata; % 加权决策矩阵
posideal=max(normdata); % 正理想解
negideal=min(normdata); % 负理想解
%% 计算加权后的决策数据与正负理想解的欧式距离
dtopos=sqrt(sum((normdata-repmat(posideal,n,1)).^2,2));
dtoneg=sqrt(sum((normdata-repmat(negideal,n,1)).^2,2));
%% 计算各样本与理想解得接近程度并得到排序结果
d=dtoneg./(dtoneg+dtopos);
[dscore,index]=sort(d,'descend');
%% 结果对比
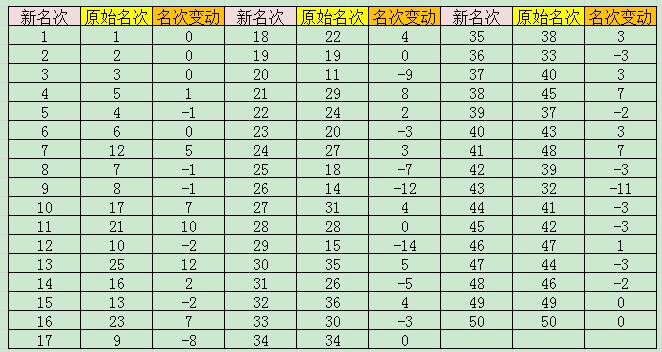
result=[{'新名次'},{'原名次'},{'名次变化'};num2cell(score(:,1)), num2cell(index),num2cell(index-score(:,1))]
程序运行结果如下:
作者:u013337691 发表于2016/8/8 14:20:48 原文链接
阅读:247 评论:0 查看评论
|
| |
| [原]Python爬虫实践:从中文歌词库抓取歌词 |
| 利用BeautifulSoup库构建一个简单的网络爬虫,从中文歌词库网站抓取凤凰传奇所有曲目的歌词(http://www.cnlyric.com/geshou/1927.html)。 from urllib.request import urlopen
from bs4 import BeautifulSoup
import re
import numpy
import csv
starturl="http://www.cnlyric.com/geshou/1927.html"
def findnextlinks(starturl,nextlinks):
""" 该函数用于从starturl页面开始,递归找出所有“下一页”的链接地址
要求nextlinks为一个空的列表"""
try:
html=urlopen(starturl)
bsobj=BeautifulSoup(html,"lxml")
nextpagelink=bsobj.find("div",{"class":"PageList"}).input.\
previous_sibling.previous_sibling.attrs["href"]
nextlink="http://www.cnlyric.com/geshou/"+nextpagelink
nextlinks.append(nextlink)
findnextlinks(nextlink,nextlinks)
except:
print("\n所有“下一页”的链接寻找完毕")
return nextlinks
nextlinks=[]
nextlinks=findnextlinks(starturl,nextlinks)
def findlrclinks(urllists):
""" 该函数用于找出列表urllists中的链接页面上存放歌词的链接 """
Sites=[]
for urllist in urllists:
html=urlopen(urllist)
bsobj=BeautifulSoup(html,"lxml")
for link in bsobj.findAll(href=re.compile("^(../LrcXML/)")):
site="http://www.cnlyric.com"+link.attrs["href"].lstrip("..")
Sites.append(site)
return Sites
nextlinks.insert(0,starturl)
Sites=findlrclinks(nextlinks)
print("\n所有曲目歌词所在的xml文件链接寻找完毕")
def getlrc(lrclink):
""" 该函数用于找出歌词链接lrclink中的歌词,并以列表形式保存 """
LRC=[]
html=urlopen(lrclink)
bsobj=BeautifulSoup(html,"lxml")
lrcpre=bsobj.findAll("lrc")
for lrclabel in lrcpre:
lrc=lrclabel.get_text()
LRC.append(lrc)
return LRC
csvfile=open("凤凰传奇歌词集.csv","w+")
try:
writer=csv.writer(csvfile)
rowindex=1
for lrcurl in Sites:
LRC=getlrc(lrcurl)
LRC.insert(0,str(rowindex).zfill(3))
writer.writerow(LRC)
rowindex+=1
finally:
csvfile.close()
运行结果: 
参考资料:Ryan Mitchell著,陶俊杰,陈小莉译《Python网络数据采集》
作者:u013337691 发表于2016/7/19 13:39:39 原文链接
阅读:1021 评论:0 查看评论
|
| |
| [原]Python爬虫实践:获取空气质量历史数据 |
| 利用BeautifulSoup库构建一个简单的网络爬虫,从天气后报网站抓取兰州空气质量历史数据(http://www.tianqihoubao.com/aqi/lanzhou.html)。 from urllib.request import urlopen
from bs4 import BeautifulSoup
import re
import numpy
import csv
def getdatawithtablehead(url):
""" 该函数用于获取带表头的数据 """
html=urlopen(url)
bsobj=BeautifulSoup(html,"lxml")
tablelist=bsobj.findAll("tr")
Dataset=[]
tablehead=tablelist[0].get_text().strip("\n").split("\n\n")
Dataset.append(tablehead)
for datalist in tablelist[1:]:
data=datalist.get_text().replace(" ","").replace("\n\r","").\
strip("\n").split("\n")
Dataset.append(data)
return Dataset
def getdata(url):
""" 该函数用于获取不带表头的数据 """
html=urlopen(url)
bsobj=BeautifulSoup(html,"lxml")
tablelist=bsobj.findAll("tr")
dataset=[]
for datalist in tablelist[1:]:
data=datalist.get_text().replace(" ","").replace("\n\r","").\
strip("\n").split("\n")
dataset.append(data)
return dataset
starturl="http://www.tianqihoubao.com/aqi/lanzhou.html"
html=urlopen(starturl)
bsobj=BeautifulSoup(html,"lxml")
Sites=[]
for link in bsobj.findAll(href=re.compile("^(/aqi/lanzhou-)")):
site="http://www.tianqihoubao.com"+link.attrs['href']
Sites.append(site)
Sites.reverse()
Dataset=getdatawithtablehead(Sites[0])
for url in Sites[1:]:
dataset=getdata(url)
Dataset=numpy.row_stack((Dataset,dataset))
csvfile=open("Dataset.csv","w+")
try:
writer=csv.writer(csvfile)
for i in range(numpy.shape(Dataset)[0]):
writer.writerow((Dataset[i,:]))
finally:
csvfile.close()
运行结果: 
参考资料:Ryan Mitchell著,陶俊杰,陈小莉译《Python网络数据采集》
作者:u013337691 发表于2016/7/13 8:38:40 原文链接
阅读:209 评论:0 查看评论
|
| |
| [原]k近邻(kNN)算法的Python实现(基于欧氏距离) |
| k近邻算法是机器学习中原理最简单的算法之一,其思想为:给定测试样本,计算出距离其最近的k个训练样本,将这k个样本中出现类别最多的标记作为该测试样本的预测标记。
k近邻算法虽然原理简单,但是其泛华错误率却不超过贝叶斯最有分类器错误率的两倍。所以实际应用中,k近邻算法是一个“性价比”很高的分类工具。
基于欧式距离,用Python3.5实现kNN算法: 主程序: from numpy import*
import operator
def myED(testdata,traindata):
""" 计算欧式距离,要求测试样本和训练样本以array([ [],[],...[] ])的形式组织,
每行表示一个样本,一列表示一个属性"""
size_train=traindata.shape[0]
size_test=testdata.shape[0]
XX=traindata**2
sumXX=XX.sum(axis=1)
YY=testdata**2
sumYY=YY.sum(axis=1)
Xpw2_plus_Ypw2=tile(mat(sumXX).T,[1,size_test])+\
tile(mat(sumYY),[size_train,1])
EDsq=Xpw2_plus_Ypw2-2*(mat(traindata)*mat(testdata).T)
distances=array(EDsq)**0.5
return distances
def mykNN(testdata,traindata,labels,k):
""" kNN算法主函数,labels组织成列表形式 """
size_test=testdata.shape[0]
D=myED(testdata,traindata)
Dsortindex=D.argsort(axis=0)
nearest_k=Dsortindex[0:k,:]
label_nearest_k=array(labels)[nearest_k]
label_test=[]
if k==1:
label_test=label_nearest_k
else:
for smp in range(size_test):
classcount={}
labelset=set(label_nearest_k[:,smp])
for label in labelset:
classcount[label]=list(label_nearest_k[:,smp]).count(label)
sortedclasscount=sorted(classcount.items(),\
key=operator.itemgetter(1),reverse=True)
label_test.append(sortedclasscount[0][0])
return label_test,D
示例: # 以下示例数据摘自周志华《机器学习》P202表9.1
labels=[1,1,1,1,1,1,1,1,0,0,0,0,0,0,0,0,0]
traindata=array([[0.6970,0.4600],[0.7740,0.3760],[0.6340,0.2640],\
[0.6080,0.3180],[0.5560,0.2150],[0.4030,0.2370],[0.4810,0.1490],\
[0.4370,0.2110],[0.6660,0.0910],[0.2430,0.2670],[0.2450,0.0570],\
[0.3430,0.0990],[0.6390,0.1610],[0.6570,0.1980],[0.3600,0.3700],\
[0.5930,0.0420],[0.7190,0.1030]])
testdata=array([[0.3590,0.1880],[0.3390,0.2410],[0.2820,0.2570],\
[0.7480,0.2320],[0.7140,0.3460],[0.4830,0.3120],[0.4780,0.4370],\
[0.5250,0.3690],[0.7510,0.4890],[0.5320,0.4720],[0.4730,0.3760],\
[0.7250,0.4450],[0.4460,0.4590]])
k=5
label_test,distances=mykNN(testdata,traindata,labels,k)
print('\n')
print(label_test)
示例结果: >>[1, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1]
作者:u013337691 发表于2016/7/11 20:15:18 原文链接
阅读:90 评论:0 查看评论
|
| |
| [原]梯度下降法实现softmax回归MATLAB程序 |
梯度下降法实现softmax回归MATLAB程序 版权声明:本文原创,转载须注明来源。 解决二分类问题时我们通常用Logistic回归,而解决多分类问题时若果用Logistic回归,则需要设计多个分类器,这是相当麻烦的事情。softmax回归可以看做是Logistic回归的普遍推广(Logistic回归可看成softmax回归在类别数为2时的特殊情况),在多分类问题上softmax回归是一个有效的工具。 关于softmax回归算法的理论知识可参考这两篇博文:http://deeplearning.stanford.edu/wiki/index.php/Softmax%E5%9B%9E%E5%BD%92 ;
http://blog.csdn.net/acdreamers/article/details/44663305 。 本文自编mysoftmax_gd函数用于实现梯度下降softmax回归,代码如下(链接:http://pan.baidu.com/s/1geF2WMJ 密码:9x3x): MATLAB程序代码: function [theta,test_pre,rate] = mysoftmax_gd(X_test,X,label,lambda,alpha,MAX_ITR,varargin)
Nin=length(varargin);
if Nin>1
error('输入太多参数')
end
[m,p] = size(X);
numClasses = length(unique(label));
if Nin==0
theta = 0.005*randn(p,numClasses);
else
theta=varargin{1};
end
cost=zeros(MAX_ITR,1);
for k=1:MAX_ITR
[cost(k),grad] = softmax_cost_grad(X,label,lambda,theta);
theta=theta-alpha*grad;
end
[~,~,Probit] = softmax_cost_grad(X,label,lambda,theta);
[~,label_pre] = max(Probit,[],2);
index = find(label==label_pre);
rate = length(index)/m;
figure('Name','代价函数值变化图');
plot(0:MAX_ITR-1,cost)
xlabel('迭代次数'); ylabel('代价函数值')
title('代价函数值变化图');
[mt,pt] = size(X_test);
Probit_t = zeros(mt,length(unique(label)));
for smpt = 1:mt
Probit_t(smpt,:) = exp(X_test(smpt,:)*theta)/sum(exp(X_test(smpt,:)*theta));
end
[~,test_pre] = max(Probit_t,[],2);
function [cost,thetagrad,P] = softmax_cost_grad(X,label,lambda,theta)
m = size(X,1);
label_extend = [full(sparse(label,1:length(label),1))]';
P = zeros(m,size(label_extend,2));
for smp = 1:m
P(smp,:) = exp(X(smp,:)*theta)/sum(exp(X(smp,:)*theta));
end
cost = -1/m*[label_extend(:)]'*log(P(:))+lambda/2*sum(theta(:).^2);
thetagrad = -1/m*X'*(label_extend-P)+lambda*theta;
clear
clc
close all
load fisheriris
index_train = [1:40,51:90,101:140];
index_test = [41:50,91:100,141:150];
species_train = species(index_train);
X=[ones(length(species_train),1),meas(index_train,:)];
label = zeros(size(species_train));
label(strcmp('setosa',species_train)) = 1;
label(strcmp('versicolor',species_train)) = 2;
label(strcmp('virginica',species_train)) = 3;
species_test = species(index_test);
X_test = [ones(length(species_test),1),meas(index_test,:)];
lambda = 0.004;
alpha = 0.1;
MAX_ITR=500;
[theta,test_pre,rate] = mysoftmax_gd(X_test,X,label,lambda,alpha,MAX_ITR)
clear
clc
close all
load MNISTdata
label = labels(1:9000);
X = [ones(length(label),1),[inputData(:,1:9000)]'];
label_test = labels(9001:end);
X_test = [ones(length(label_test),1),[inputData(:,9001:end)]'];
lambda = 0.004;
alpha = 0.1;
MAX_ITR=100;
[theta,test_pre,rate] = mysoftmax_gd(X_test,X,label,lambda,alpha,MAX_ITR)
index_t = find(label_test==test_pre);
rate_test = length(index_t)/length(label_test);
水平有限,敬请指正交流。[email protected] 。 参考资料:
【1】:http://deeplearning.stanford.edu/wiki/index.php/Softmax%E5%9B%9E%E5%BD%92
【2】:http://blog.csdn.net/acdreamers/article/details/44663305 |