从零开始的机器学习之SVM一个简单的实现案例——鸢尾花分类
本文利用SVM对UCI的IRIS数据进行了分类预测。
参考博客链接:点击打开链接
实验环境是Pycharm python3。
实验中出现的调试问题见最后。
1.获取数据
首先是数据集,采用UCI的鸢尾花数据集,网址链接:点击打开链接。
编辑
我们点击Data Folder,显示如下
编辑
这个iris.data就是我们需要的数据了。点击进去,会在网页中显示数据。数据长这个样子。

编辑
我们将数据复制下来,保存成一个txt文件。
2.编写代码
在有了数据之后我们就可以开始我们的svm实现了。
首先我们建一个py文件,在文件的开始导入我们接下了要用的包;
from sklearn import svm # svm函数需要的
import numpy as np # numpy科学计算库
from sklearn import model_selection
import matplotlib.pyplot as plt # 画图的库
复制代码再导入数据之前我们需要先观察数据,对数据做一个处理;
数据每一行一个鸢尾花的观察结果,前四个数据代表鸢尾花的生物属性比如大小等,具体的含义可以查看UCI的官方网站的解释。最后一个数据是鸢尾花的类别,共三类。主要是对最后这个类别进行处理。
我们定义一个函数,将不同类别与数字相对应。
def iris_type(s):
it = {b'Iris-setosa': 0, b'Iris-versicolor': 1, b'Iris-virginica': 2}
return it[s]
复制代码现在我们可以导入数据了。
path ='C:/Users/Yesterday/Desktop/irisdata.txt' # 之前保存的文件路径
data = np.loadtxt(path, # 路径
dtype=float, # 数据类型
delimiter=',', # 数据以什么分割符号分割数据
converters={4: iris_type}) # 对某一列数据(第四列)进行某种类型的转换()
复制代码这时的数据长这样:
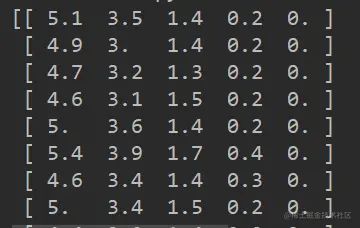
编辑
我们将原始数据分成训练集和测试集:
X, y = np.split(data, (4,), axis=1)
x = X[:, 0:2]
x_train, x_test, y_train, y_test = model_selection.train_test_split(x, y, random_state=1, test_size=0.3)
复制代码np.split按照列(axis=1)进行分割,从第四列开始往后的作y数据,之前作为X数据。
在X中我们取前两列作为特征(为了后面的可视化)。
用train_test_split将数据分为训练集和测试集,测试集占总数据的30%(test_size=0.3),random_state是随机数种子(随机数种子:其实就是该组随机数的编号,在需要重复试验的时候,保证得到一组一样的随机数。比如你每次都填1,其他参数一样的情况下你得到的随机数组是一样的。但填0或不填,每次都会不一样。随机数的产生取决于种子,随机数和种子之间的关系遵从以下两个规则:种子不同,产生不同的随机数;种子相同,即使实例不同也产生相同的随机数。)
接下来是搭建模型
clf = svm.SVC(kernel='rbf', # 核函数
gamma=0.1,
decision_function_shape='ovo', # one vs one 分类问题
C=0.8)
clf.fit(x_train, y_train) # 训练
复制代码print(clf.score(x_train, y_train)) # 输出训练集的准确率
复制代码由于准确率表现不直观,我们可以通过其他方式观察结果。
首先我们将原始结果与训练集预测结果进行对比。
y_train_hat=clf.predict(x_train)
y_train_1d=y_train.reshape((-1))
comp=zip(y_train_1d,y_train_hat)
print(list(comp))
复制代码用zip把原始结果和预测结果放在一起。显示如下:
![]()
编辑
同样的我们可以用训练好的模型对测试集的数据进行预测的。
print(clf.score(x_test,y_test))
y_test_hat=clf.predict(x_test)
y_test_1d=y_test.reshape((-1))
comp=zip(y_test_1d,y_test_hat)
print(list(comp))
复制代码还可以通过图像进行可视化
plt.figure()
plt.subplot(121)
plt.scatter(x_train[:, 0], x_train[:, 1], c=y_train.reshape((-1)), edgecolors='k',s=50)
plt.subplot(122)
plt.scatter(x_train[:, 0], x_train[:, 1], c=y_train_hat.reshape((-1)), edgecolors='k',s=50)
plt.show()
复制代码plt.figure()用于画图,plt.subplot()用于在一个图形窗口中画多副图(121,12表示子图的要按一行两列排列,最后的1表示这是第一幅子图)。plt.scatter()用于画散点图(参数c表示要按照y_train中的类别对散点进行上色,edgecolor表示散点的边的颜色,可省略,s表示散点的大小,可省略)
结果如图:
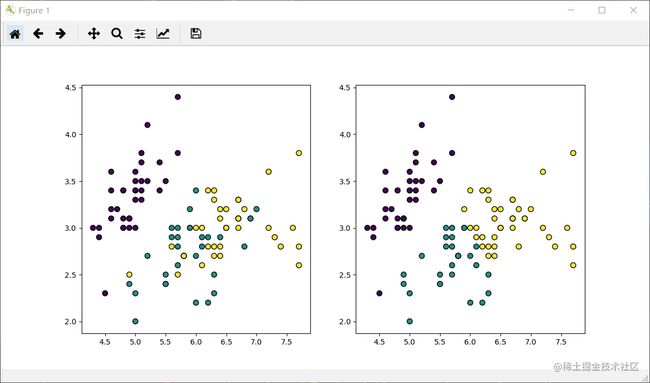
编辑
左图为训练数据,右图为对训练数据的预测。
本文中的参数并不是最合适的,如果想要好的结果需要进行参数的调整,同时选取的用于训练的参数也可以增加到四个(本文用了前两个)。最合适的参数大家自己发掘吧。
3.常见调试问题
实验中可能出现的调试问题:
1.在path报错,出现的报错信息为"\u202A",这个由于粘贴复制时复制了特殊字符。解决方案:手动输入path路径。
2.在loadtxt报错,提示converters转换错误(KeyError: b'Iris-setosa')。本文的代码是正确的不需要修改。但是如果是按照本文提到的参考博客所示,则会出现报错。解决方案:将iris_type函数中字典的key值前面都想加上小写字母b(由'Iris-setosa'变为b'Iris-setosa')
3.报错:DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().y = column_or_1d(y, warn=True)。当出现这个warning不影响程序正常运行可不修改。如果想去掉这个warning可以通过reshape函数将y的shape改变。解决方法:y=y.reshape((-1))。-1表示自动适应y的长度把y变成一维的list。