《MATLAB语音信号分析与合成(第二版)》:第10章 语音信号的合成算法
《MATLAB语音信号分析与合成(第二版)》:第10章 语音信号的合成算法
- 前言
- 1. 数据与函数路径设置
- 2. MATLAB仿真一:重叠相加法语音合成
- 3. MATLAB仿真二:重叠存储法语音合成
- 4. MATLAB仿真三:线性比例重叠相加法语音合成
- 5. MATLAB仿真四:频谱参数法语音合成
- 6. MATLAB仿真五:线性预测系数与预测误差法语音合成
- 7. MATLAB仿真六:基音与共振峰语音合成一
- 8. MATLAB仿真七:基音与共振峰语音合成二
- 9. MATLAB仿真八:基音与共振峰语音合成三
- 10. MATLAB仿真九:基音与共振峰语音合成四
- 11. MATLAB仿真十:语音信号的变速
- 12. MATLAB仿真十一:语音信号的变调
- 13. MATLAB仿真十二:语音信号的变速与变调
- 14. MATLAB仿真十三:时域基音同步叠加(TD-PSOLA)语音合成一
- 15. MATLAB仿真十四:时域基音同步叠加(TD-PSOLA)语音合成二
- 小结
前言
《MATLAB语音信号分析与合成(第二版)》是中科院声学所的大佬宋知用老师数十年经验积累下的呕心之作,对于语音信号处理相关感兴趣的同学,日后希望在语音信号分析、处理与合成相关领域进行一定研究的话,可以以此进行入门。
语音信号处理是数字信号处理的一个重要分支。本书含有许多数字信号处理的方法和 MATLAB函数。 全书共10章。第1-4章介绍语音信号处理的一些基本分析方法和手段,以及相应的MATLAB函数;第5-9章介绍语音信号预处理和特征的提取,包括消除趋势项和基本的减噪方法,以及端点检测、基音的提取和共 振峰的提取,并利用语音信号处理的基本方法,给出了多种提取方法和相应的 MATLAB程序;第10章结合 各种参数的检测介绍了语音信号的合成、语音信号的变速和变调处理,还介绍了时域基音同步叠加( TD PSOLA)的语音合成,并给出了相应的MATLAB程序。附录A中给出了调试复杂程序的方法和思路。 本书可作为从事语音信号处理的本科高年级学生、研究生或科研工程技术人员的辅助读物,也可作为从 事信号处理研究与应用的科研工程技术人员的参考用书。
我的研究生导师的主攻方向就是语音信号处理相关,虽然自己研究生期间的大论文方向是数字图像处理,但所谓语音图像不分家,自己在老师的研究生主讲课小波变换上虽然划水,但在后期导师的语音信号处理的课程设计和工程应用上自己在语音上还算入了一点小门道,在结课测试中拿到了小组第一,导师还特地发了三百大洋的伙食经费以资鼓励。
这次重新捡起语音识别,正好入手了宋老师的这本书,算是自己重新复习一遍吧,主要以介绍各章节中源码为主,这是本书的第十章的14个仿真应用实例,话不多说,开始!
1. 数据与函数路径设置
书中经常会调用的一些函数(自编函数或取自其他应用工具箱中的函数)已集中在basic_tbx工具箱中,在运行本书的程序前请把该工具箱设置(用set path设置)在工作路径下;
当要运行EMD处理时,要把emd工具箱设置在工作路径下;
当要运行主体延伸基音检测时,要把Pitch_ztlib工具箱设置在工作路径下;
当要进行时域基音同步叠加语音合成时,要把psola_lib工具箱设置在工作路径下;
当要应用本书提供的语音数据时,最好把speech_signal设置在工作路径下。
本书的所有函数和程序都在MATLAB R2009a版本下调试通过。(我用的是MATLAB2015b,有些函数已经更新,所以我会进行修改,以便调试通过)
路径设置的方法如下:
打开MATLAB,点击“主页”,找到设置路径
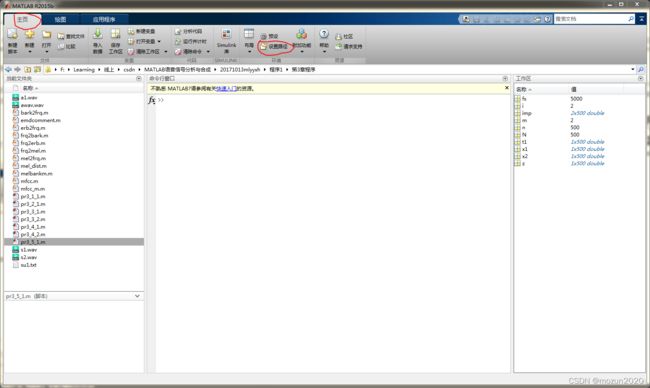
将上述文件夹路径全部添加到MATLAB搜索路径中
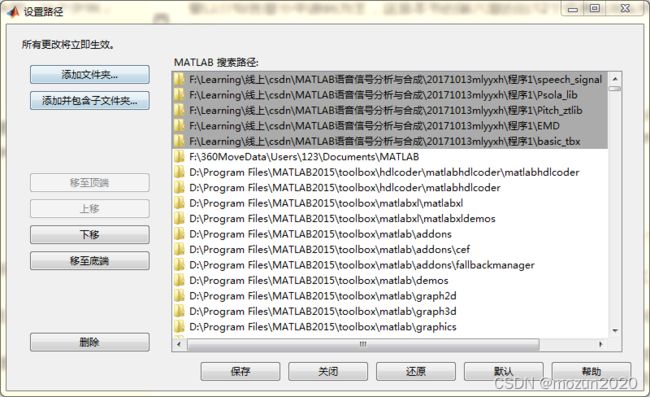
添加完毕,保存,开始仿真。
2. MATLAB仿真一:重叠相加法语音合成
% pr10_1_1
% 把conv与重叠相加卷积conv_ovladd函数做比较
%
clear all; clc; close all;
y=load('data1.txt')'; % 读入数据
M=length(y); % 数据长
t=0:M-1;
h=fir1(100,0.125); % 设计FIR滤波器
x=conv(h,y); % 用conv函数进行数字滤波
x=x(51:1050); % 取无延迟的滤波器输出
z=conv_ovladd1(y,h,256); % 通过重叠相加法计算卷积
% 作图
pos = get(gcf,'Position');
set(gcf,'Position',[pos(1), pos(2)-100,pos(3),(pos(4)-140)]);
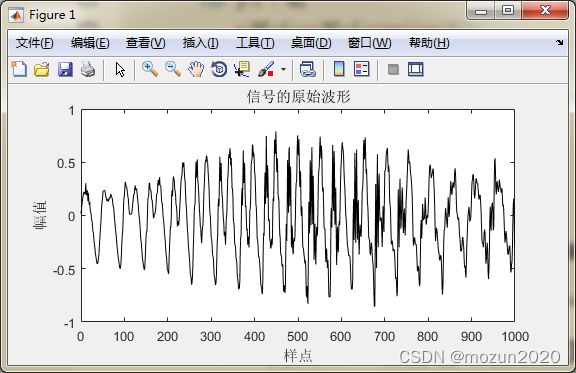
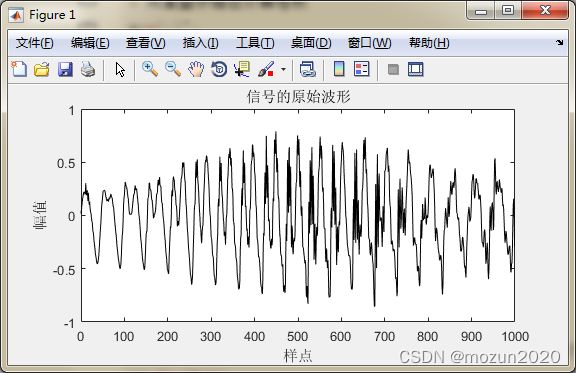
plot(t,y,'k');
title('信号的原始波形')
xlabel('样点'); ylabel('幅值');
%xlabel('n'); ylabel('Am');
figure(2)
pos = get(gcf,'Position');
set(gcf,'Position',[pos(1), pos(2)-100,pos(3),(pos(4)-100)]);
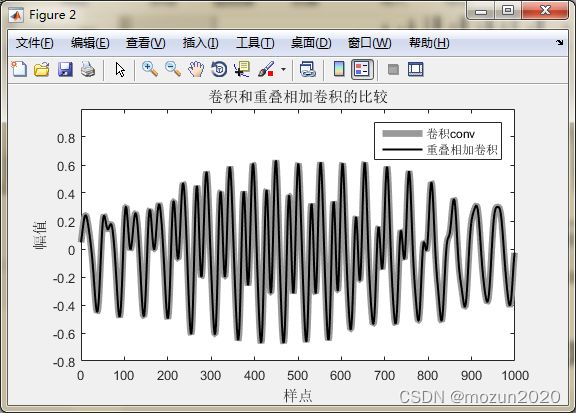
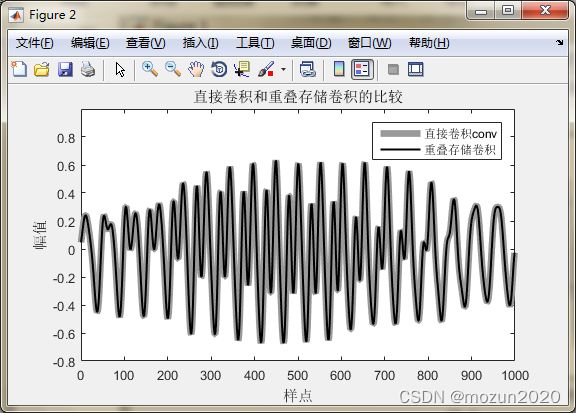
hline1 = plot(t,z,'k','LineWidth',1.5);
hline2 = line(t,x,'LineWidth',5,'Color',[.6 .6 .6]);
set(gca,'Children',[hline1 hline2]);
title('卷积和重叠相加卷积的比较')
xlabel('样点'); ylabel('幅值');
legend('卷积conv','重叠相加卷积',2)
ylim([-0.8 1]);
function z=conv_ovladd1(x,h,L)
% 用重叠相加法计算卷积
x=x(:)'; % 把x转换成一行
NN=length(x); % 计算x长
N=length(h); % 计算h长
N1=L-N+1; % 把x分段的长度
x1=[x zeros(1,L)];
H=fft(h,L); % 求h的FFT为H
J=fix((NN+L)/N1); % 求分块个数
y=zeros(1,NN+2*L); % 初始化
for k=1 : J % 对每段处理
xx=zeros(1,L);
MI=(k-1)*N1; % 第i段在x上的开始位置-1
nn=1:N1;
xx(nn)=x1(nn+MI); % 取一段xi
XX=fft(xx,L); % 做 FFT
YY=XX.*H; % 相乘进行卷积
yy=ifft(YY,L); % 做FFT逆变换求出yi
% 相邻段间重叠相加
if k==1 % 第1块不需要做重叠相加
for j=1 : L
y(j)=y(j)+real(yy(j));
end
elseif k==J % 最后一块只做N1个数据点重叠相加
for j=1 : N1
y(MI+j)=y(MI+j)+real(yy(j));
end
else
for j=1 : L % 从第2块开始每块都要做重叠相加
y(MI+j)=y(MI+j)+real(yy(j));
end
end
end
nn=floor(N/2);
z=y(nn+1:NN+nn); % 忽略延迟量,取输出与输入x等长
3. MATLAB仿真二:重叠存储法语音合成
%
% pr10_1_2
% 把conv与重叠存储法卷积conv_ovlsav1函数做比较
clear all; clc; close all;
y=load('data1.txt'); % 读入数据
M=length(y); % 数据长
t=0:M-1;
h=fir1(100,0.125); % 设计FIR滤波器
x=conv(h,y); % 用conv函数进行数字滤波
x=x(51:1050); % 取无延迟的滤波器输出
z=conv_ovlsav1(y,h,256); % 通过重叠存储法计算卷积
% 作图
pos = get(gcf,'Position');
set(gcf,'Position',[pos(1), pos(2)-100,pos(3),(pos(4)-140)]);
plot(t,y,'k');
title('信号的原始波形')
xlabel('样点'); ylabel('幅值');
figure(2)
pos = get(gcf,'Position');
set(gcf,'Position',[pos(1), pos(2)-100,pos(3),(pos(4)-100)]);
hline1 = plot(t,z,'k','LineWidth',1.5);
hline2 = line(t,x,'LineWidth',5,'Color',[.6 .6 .6]);
set(gca,'Children',[hline1 hline2]);
title('直接卷积和重叠存储卷积的比较')
xlabel('样点'); ylabel('幅值');
legend('直接卷积conv','重叠存储卷积',2)
ylim([-0.8 1]);
function y=conv_ovlsav1(x,h,L)
% 用重叠存储法计算卷积
x=x(:)';
Lenx = length (x); % 计算x长
N=length(h); % 计算h长
N1=N-1;
M=L-N1;
H=fft(h, L); % 求h的FFT为H
x=[zeros(1,N1), x, zeros(1, L-1)]; % 前后补零
K = floor((Lenx+ N1-1)/M); % 求分帧个数
Y=zeros(K+1, L); % 初始化
for k=0 : K % 对每帧处理
Xk=fft(x(k*M+1:k*M+L)); % 做 FFT
Y(k+1,:)=real(ifft(Xk.*H)); % 相乘进行卷积
end
Y=Y(:, N:L)'; % 在每帧中只保留最后的M个数据
nm=fix(N/2);
y=Y(nm+1:nm+Lenx )'; % 忽略延迟量,并把2维变成1维,取输出与输入x等长
4. MATLAB仿真三:线性比例重叠相加法语音合成
%
% pr10_1_3
clear all; clc; close all;
load Labdata1 % 读入实验数据和延伸数据
N=length(xx); % 数据长
time=(0:N-1)/fs; % 时间标度
T=10091-8538+1; % 缺少数据区间的长度
x1=xx(1:8537); % 前段数据
x2=xx(10092:29554); % 后段数据
y1=ydata(:,1); % 延伸数据1
xx1=[x1; y1; x2]; % 以延伸数据1合成
y2=ydata(:,2); % 延伸数据2
xx2=[x1; y2; x2]; % 以延伸数据2合成
% 用延伸数据1和延伸数据2以线性比例重叠相加合成
Wt1=(0:T-1)'/T; % 构成斜三角窗函数w1
Wt2=(T-1:-1:0)'/T; % 构成斜三角窗函数w2
y=y1.*Wt2+y2.*Wt1; % 线性比例重叠相加
xx3=[x1; y; x2]; % 合成数据
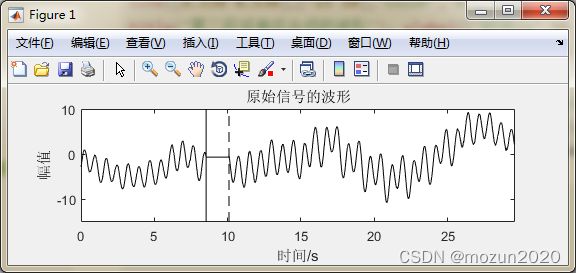
%作图
pos = get(gcf,'Position');
set(gcf,'Position',[pos(1), pos(2)-100,pos(3),pos(4)-240]);
plot(time,xx,'k'); axis([0 29.6 -15 10]);
title('原始信号的波形'); xlabel('时间/s'); ylabel('幅值')
line([8.537 8.537],[-15 10],'color','k','linestyle','-');
line([10.092 10.092],[-15 10],'color','k','linestyle','--');
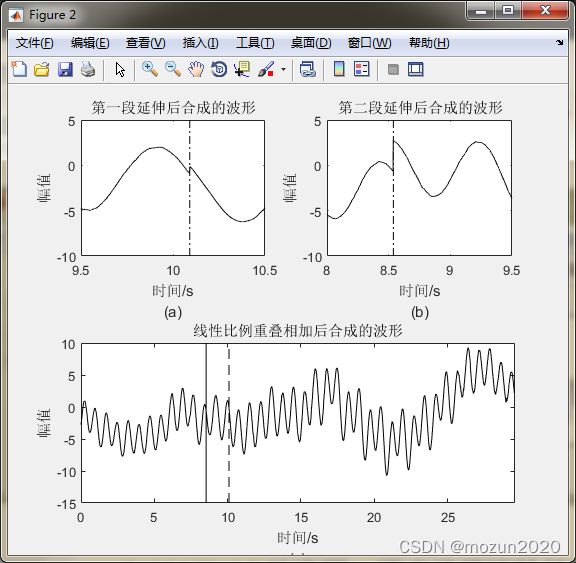
figure(2)
pos = get(gcf,'Position');
set(gcf,'Position',[pos(1), pos(2)-100,pos(3),pos(4)+50]);
subplot 221; plot(time,xx1,'k'); axis([9.5 10.5 -10 5]);
line([10.091 10.091],[-15 10],'color','k','linestyle','-.');
title('第一段延伸后合成的波形'); xlabel(['时间/s' 10 '(a)']); ylabel('幅值')
subplot 222; plot(time,xx2,'k'); axis([8 9.5 -10 5]);
line([8.538 8.538],[-15 10],'color','k','linestyle','-.');
title('第二段延伸后合成的波形'); xlabel(['时间/s' 10 '(b)']); ylabel('幅值')
subplot 212; plot(time,xx3,'k'); axis([0 29.6 -15 10]);
line([8.537 8.537],[-15 10],'color','k','linestyle','-');
line([10.092 10.092],[-15 10],'color','k','linestyle','--');
title('线性比例重叠相加后合成的波形'); xlabel(['时间/s' 10 '(c)']); ylabel('幅值')
5. MATLAB仿真四:频谱参数法语音合成
%
% pr10_3_1
clear all; clc; close all;
filedir=[]; % 设置路径
filename='colorcloud.wav'; % 设置文件名
fle=[filedir filename]; % 构成完整的路径和文件名
% [x, fs, bits] = wavread(fle); % 读入数据文件
[x, fs] = audioread(fle); % 读入数据文件
x=x-mean(x); % 消除直流分量
x=x/max(abs(x)); % 幅值归一
xl=length(x); % 数据长度
time=(0:xl-1)/fs; % 计算出时间刻度
p=12; % LPC的阶数为12
wlen=200; inc=80; % 帧长和帧移
msoverlap = wlen - inc; % 每帧重叠部分的长度
y=enframe(x,wlen,inc)'; % 分帧
fn=size(y,2); % 取帧数
% 语音分析:求每一帧的LPC系数和预测误差
for i=1 : fn
u=y(:,i); % 取来一帧
A=lpc(u,p); % LPC求得系数
aCoeff(:,i)=A; % 存放在aCoeff数组中
errSig = filter(A,1,u); % 计算预测误差序列
resid(:,i) = errSig; % 存放在resid数组中
end
% 语音合成:求每一帧的合成语音叠接成连续语音信号
for i=1:fn
A = aCoeff(:,i); % 取得该帧的预测系数
residFrame = resid(:,i); % 取得该帧的预测误差
synFrame = filter(1, A', residFrame); % 预测误差激励,合成语音
outspeech((i-1)*inc+1:i*inc)=synFrame(1:inc); % 重叠存储法存放数据
% 如果是最后一帧,把inc后的数据补上
if i==fn
outspeech(fn*inc+1:(fn-1)*inc+wlen)=synFrame(inc+1:wlen);
end
end;
ol=length(outspeech);
if ol<xl % 把outspeech补零,使与x等长
outspeech=[outspeech zeros(1,xl-ol)];
end
% 发声
% wavplay(x,fs);
audioplayer(x,fs);
pause(1)
% wavplay(outspeech,fs);
audioplayer(outspeech,fs);
% 作图
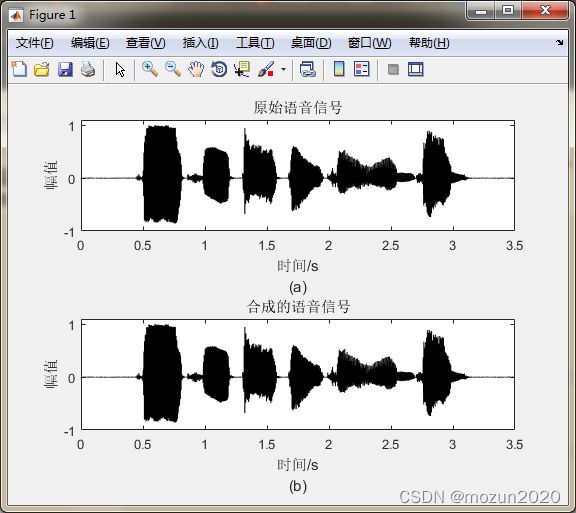
subplot 211; plot(time,x,'k');
xlabel(['时间/s' 10 '(a)']); ylabel('幅值'); ylim([-1 1.1]);
title('原始语音信号')
subplot 212; plot(time,outspeech,'k');
xlabel(['时间/s' 10 '(b)']); ylabel('幅值'); ylim([-1 1.1]);
title('合成的语音信号')
6. MATLAB仿真五:线性预测系数与预测误差法语音合成
%
% pr10_4_1
clear all; clc; close all;
filedir=[]; % 设置数据文件的路径
filename='colorcloud.wav'; % 设置数据文件的名称
fle=[filedir filename] % 构成路径和文件名的字符串
% [xx,fs]=wavread(fle); % 读取文件
[xx,fs]=audioread(fle); % 读取文件
xx=xx-mean(xx); % 去除直流分量
x=xx/max(abs(xx)); % 归一化
N=length(x); % 数据长度
time=(0:N-1)/fs; % 时间刻度
wlen=240; % 帧长
inc=80; % 帧移
overlap=wlen-inc; % 重叠长度
tempr1=(0:overlap-1)'/overlap; % 斜三角窗函数w1
tempr2=(overlap-1:-1:0)'/overlap; % 斜三角窗函数w2
n2=1:wlen/2+1; % 正频率的下标值
wind=hanning(wlen); % 窗函数
X=enframe(x,wind,inc)'; % 分帧
fn=size(X,2); % 帧数
T1=0.1; r2=0.5; % 端点检测参数
miniL=10; % 有话段最短帧数
mnlong=5; % 元音主体最短帧数
ThrC=[10 15]; % 阈值
p=12; % LPC阶次
frameTime=frame2time(fn,wlen,inc,fs); % 计算每帧的时间刻度
for i=1 : fn % 计算每帧的线性预测系数和增益
u=X(:,i);
[ar,g]=lpc(u,p);
AR_coeff(:,i)=ar;
Gain(i)=g;
end
% 基音检测
[Dpitch,Dfreq,Ef,SF,voiceseg,vosl,vseg,vsl,T2]=...
Ext_F0ztms(xx,fs,wlen,inc,T1,r2,miniL,mnlong,ThrC,0);
tal=0; % 初始化前导零点
zint=zeros(p,1);
for i=1:fn;
ai=AR_coeff(:,i); % 获取第i帧的预测系数
sigma_square=Gain(i); % 获取第i帧的增益系数
sigma=sqrt(sigma_square);
if SF(i)==0 % 无话帧
excitation=randn(wlen,1); % 产生白噪声
[synt_frame,zint]=filter(sigma,ai,excitation,zint); % 用白噪声合成语音
else % 有话帧
PT=round(Dpitch(i)); % 取周期值
exc_syn1 =zeros(wlen+tal,1); % 初始化脉冲发生区
exc_syn1(mod(1:tal+wlen,PT)==0) = 1; % 在基音周期的位置产生脉冲,幅值为1
exc_syn2=exc_syn1(tal+1:tal+inc); % 计算帧移inc区间内脉冲个数
index=find(exc_syn2==1);
excitation=exc_syn1(tal+1:tal+wlen);% 这一帧的激励脉冲源
if isempty(index) % 帧移inc区间内没有脉冲
tal=tal+inc; % 计算下一帧的前导零点
else % 帧移inc区间内有脉冲
eal=length(index); % 计算有几个脉冲
tal=inc-index(eal); % 计算下一帧的前导零点
end
gain=sigma/sqrt(1/PT); % 增益
[synt_frame,zint]=filter(gain, ai,excitation,zint); % 用脉冲合成语音
end
if i==1 % 若为第1帧
output=synt_frame; % 不需要重叠相加,保留合成数据
else
M=length(output); % 按线性比例重叠相加处理合成数据
output=[output(1:M-overlap); output(M-overlap+1:M).*tempr2+...
synt_frame(1:overlap).*tempr1; synt_frame(overlap+1:wlen)];
end
end
ol=length(output); % 把输出output延长至与输入信号xx等长
if ol<N
output1=[output; zeros(N-ol,1)];
else
output1=output(1:N);
end
bn=[0.964775 -3.858862 5.788174 -3.858862 0.964775]; % 滤波器系数
an=[1.000000 -3.928040 5.786934 -3.789685 0.930791];
output=filter(bn,an,output1); % 高通滤波
output=output/max(abs(output)); % 幅值归一
% 通过声卡发音,比较原始语音和合成语音
% wavplay(x,fs);
audioplayer(x,fs);
pause(1)
% wavplay(output,fs);
audioplayer(output,fs);
%作图
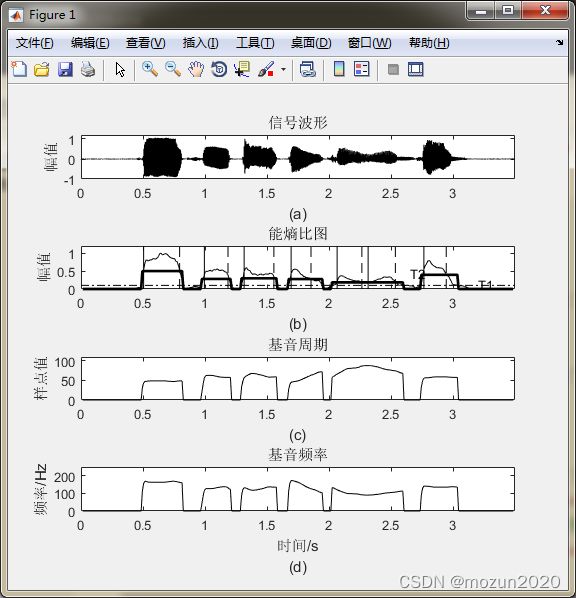
figure(1)
pos = get(gcf,'Position');
set(gcf,'Position',[pos(1), pos(2)-100,pos(3),(pos(4)+85)])
subplot 411; plot(time,xx,'k'); axis([0 max(time) -1 1.2]);
xlabel('(a)');
title('信号波形'); ylabel('幅值')
subplot 412; plot(frameTime,Ef,'k'); hold on
axis([0 max(time) 0 1.2]); plot(frameTime,T2,'k','linewidth',2);
line([0 max(time)],[T1 T1],'color','k','linestyle','-.');
title('能熵比图'); axis([0 max(time) 0 1.2]); ylabel('幅值')
xlabel('(b)');
text(3.2,T1+0.05,'T1');
for k=1 : vsl
line([frameTime(vseg(k).begin) frameTime(vseg(k).begin)],...
[0 1.2],'color','k','Linestyle','-');
line([frameTime(vseg(k).end) frameTime(vseg(k).end)],...
[0 1.2],'color','k','Linestyle','--');
if k==vsl
Tx=T2(floor((vseg(k).begin+vseg(k).end)/2));
end
end
text(2.65,Tx+0.05,'T2');
subplot 413; plot(frameTime,Dpitch,'k');
axis([0 max(time) 0 110]);title('基音周期');ylabel('样点值')
xlabel( '(c)');
subplot 414; plot(frameTime,Dfreq,'k');
axis([0 max(time) 0 250]);title('基音频率');ylabel('频率/Hz')
xlabel(['时间/s' 10 '(d)']);
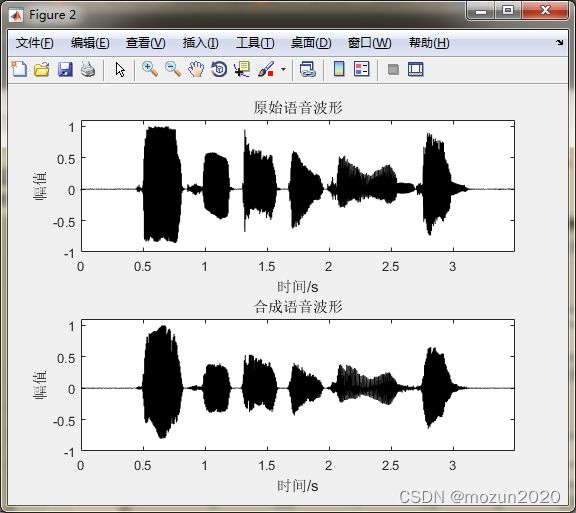
figure(2)
subplot 211; plot(time,x,'k'); title('原始语音波形');
axis([0 max(time) -1 1.1]); xlabel('时间/s'); ylabel('幅值')
subplot 212; plot(time,output,'k'); title('合成语音波形');
axis([0 max(time) -1 1.1]); xlabel('时间/s'); ylabel('幅值')
7. MATLAB仿真六:基音与共振峰语音合成一
%
% pr10_5_1
clear all; clc; close all;
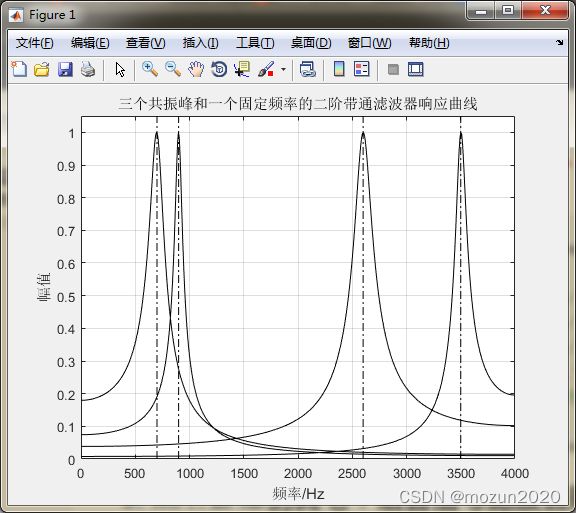
F0 = [700 900 2600];
Bw = [130 70 160];
fs=8000;
[An,Bn]=formant2filter4(F0,Bw,fs); % 调用函数求取滤波器系数
for k=1 : 4 % 对四个二阶带通滤波器做频响曲线
A=An(:,k); % 取得滤波器系数
B=Bn(k);
fprintf('B=%5.6f A=%5.6f %5.6f %5.6f\n',B,A);
[H(:,k),w]=freqz(B,A); % 求得响应曲线
end
freq=w/pi*fs/2; % 频率轴刻度
% 作图
plot(freq,abs(H(:,1)),'k',freq,abs(H(:,2)),'k',freq,abs(H(:,3)),'k',freq,abs(H(:,4)),'k');
axis([0 4000 0 1.05]); grid;
line([F0(1) F0(1)],[0 1.05],'color','k','linestyle','-.');
line([F0(2) F0(2)],[0 1.05],'color','k','linestyle','-.');
line([F0(3) F0(3)],[0 1.05],'color','k','linestyle','-.');
line([3500 3500],[0 1.05],'color','k','linestyle','-.');
title('三个共振峰和一个固定频率的二阶带通滤波器响应曲线')
ylabel('幅值'); xlabel('频率/Hz')
8. MATLAB仿真七:基音与共振峰语音合成二
%
% pr10_5_2
clear all; clc; close all;
Fs=8000; % 采样频率
Fs2=Fs/2;
fp=60; fs=20; % 通带波纹和阻带频率
wp=fp/Fs2; ws=fs/Fs2; % 转换成归一化频率
Rp=1; Rs=40; % 通带和阻带衰减
[n,Wn]=cheb2ord(wp,ws,Rp,Rs); % 计算滤波器阶次
[b1,a1]=cheby2(n,Rs,Wn,'high'); % 计算滤波器系数
fprintf('b=%5.6f %5.6f %5.6f %5.6f %5.6f\n',b1);
fprintf('a=%5.6f %5.6f %5.6f %5.6f %5.6f\n',a1);
fprintf('\n');
[db,mag,pha,grd,w]=freqz_m(b1,a1); % 求出滤波器频率响应
a=[1 -0.99];
db1=freqz_m(1,a); % 计算低通滤波器频率响应
A=conv(a,a1); % 计算串接滤波器系数
B=b1;
db2=freqz_m(B,A);
fprintf('B=%5.6f %5.6f %5.6f %5.6f %5.6f\n',B);
fprintf('A=%5.6f %5.6f %5.6f %5.6f %5.6f %5.6f\n',A);
% 作图
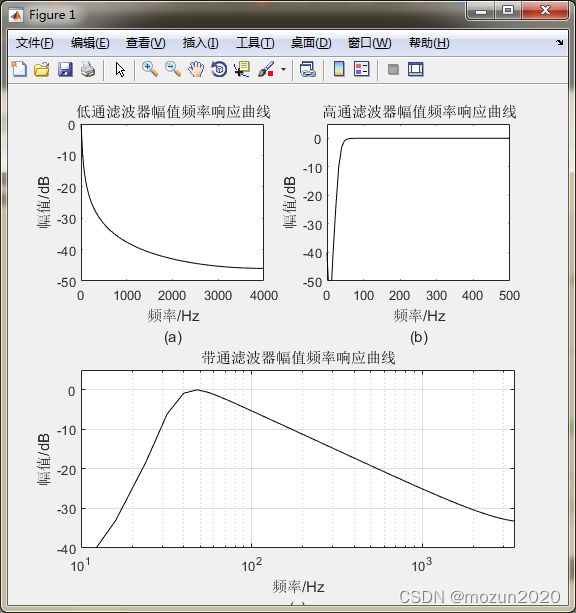
pos = get(gcf,'Position');
set(gcf,'Position',[pos(1), pos(2)-100,pos(3),pos(4)+100]);
subplot 221; plot(w/pi*Fs2,db1,'k');
title('低通滤波器幅值频率响应曲线')
ylim([-50 0]); ylabel('幅值/dB'); xlabel(['频率/Hz' 10 '(a)']);
subplot 222; plot(w/pi*Fs2,db,'k');
title('高通滤波器幅值频率响应曲线')
axis([0 500 -50 5]); ylabel('幅值/dB'); xlabel(['频率/Hz' 10 '(b)']);
subplot 212; semilogx(w/pi*Fs2,db2,'k');
title('带通滤波器幅值频率响应曲线'); ylabel('幅值/dB');
xlabel(['频率/Hz' 10 '(c)']); axis([10 3500 -40 5]); grid
9. MATLAB仿真八:基音与共振峰语音合成三
%
% pr10_5_3
clear all; clc; close all;
filedir=[]; % 设置数据文件的路径
filename='colorcloud.wav'; % 设置数据文件的名称
fle=[filedir filename] % 构成路径和文件名的字符串
% [xx,fs]=wavread(fle); % 读取文件
[xx,fs]=audioread(fle); % 读取文件
xx=xx-mean(xx); % 去除直流分量
x1=xx/max(abs(xx)); % 归一化
x=filter([1 -.99],1,x1); % 预加重
N=length(x); % 数据长度
time=(0:N-1)/fs; % 信号的时间刻度
wlen=240; % 帧长
inc=80; % 帧移
overlap=wlen-inc; % 重叠长度
tempr1=(0:overlap-1)'/overlap; % 斜三角窗函数w1
tempr2=(overlap-1:-1:0)'/overlap; % 斜三角窗函数w2
n2=1:wlen/2+1; % 正频率的下标值
wind=hanning(wlen); % 窗函数
X=enframe(x,wlen,inc)'; % 分帧
fn=size(X,2); % 帧数
Etemp=sum(X.*X); % 计算每帧的能量
Etemp=Etemp/max(Etemp); % 能量归一化
T1=0.1; r2=0.5; % 端点检测参数
miniL=10; % 有话段最短帧数
mnlong=5; % 元音主体最短帧数
ThrC=[10 15]; % 阈值
p=12; % LPC阶次
frameTime=frame2time(fn,wlen,inc,fs); % 每帧对应的时间刻度
Doption=0;
% 用主体-延伸法基音检测
[Dpitch,Dfreq,Ef,SF,voiceseg,vosl,vseg,vsl,T2]=...
Ext_F0ztms(x1,fs,wlen,inc,T1,r2,miniL,mnlong,ThrC,Doption);
%% 共振峰提取
Frmt=Formant_ext2(x,wlen,inc,fs,SF,Doption);
Bwm=[150 200 250]; % 设置固定带宽
Bw=repmat(Bwm',1,fn);
%% 语音合成
zint=zeros(2,4); % 初始化
tal=0;
for i=1 : fn
yf=Frmt(:,i); % 取来i帧的三个共振峰频率和带宽
bw=Bw(:,i);
[an,bn]=formant2filter4(yf,bw,fs); % 转换成四个二阶滤波器系数
synt_frame=zeros(wlen,1);
if SF(i)==0 % 无话帧
excitation=randn(wlen,1); % 产生白噪声
for k=1 : 4 % 对四个滤波器并联输入
An=an(:,k);
Bn=bn(k);
[out(:,k),zint(:,k)]=filter(Bn(1),An,excitation,zint(:,k));
synt_frame=synt_frame+out(:,k); % 四个滤波器输出叠加在一起
end
else % 有话帧
PT=round(Dpitch(i)); % 取周期值
exc_syn1 =zeros(wlen+tal,1); % 初始化脉冲发生区
exc_syn1(mod(1:tal+wlen,PT)==0)=1;% 在基音周期的位置产生脉冲,幅值为1
exc_syn2=exc_syn1(tal+1:tal+inc); % 计算帧移inc区间内的脉冲个数
index=find(exc_syn2==1);
excitation=exc_syn1(tal+1:tal+wlen);% 这一帧的激励脉冲源
if isempty(index) % 帧移inc区间内没有脉冲
tal=tal+inc; % 计算下一帧的前导零点
else % 帧移inc区间内有脉冲
eal=length(index); % 计算有几个脉冲
tal=inc-index(eal); % 计算下一帧的前导零点
end
for k=1 : 4 % 对四个滤波器并联输入
An=an(:,k);
Bn=bn(k);
[out(:,k),zint(:,k)]=filter(Bn(1),An,excitation,zint(:,k));
synt_frame=synt_frame+out(:,k); % 四个滤波器输出叠加在一起
end
end
Et=sum(synt_frame.*synt_frame); % 用能量归正合成语音
rt=Etemp(i)/Et;
synt_frame=sqrt(rt)*synt_frame;
if i==1 % 若为第1帧
output=synt_frame; % 不需要重叠相加,保留合成数据
else
M=length(output); % 按线性比例重叠相加处理合成数据
output=[output(1:M-overlap); output(M-overlap+1:M).*tempr2+...
synt_frame(1:overlap).*tempr1; synt_frame(overlap+1:wlen)];
end
end
ol=length(output); % 把输出output延长至与输入信号xx等长
if ol<N
output=[output; zeros(N-ol,1)];
end
% 合成语音通过带通滤波器
out1=output;
out2=filter(1,[1 -0.99],out1);
b=[0.964775 -3.858862 5.788174 -3.858862 0.964775];
a=[1.000000 -3.928040 5.786934 -3.789685 0.930791];
output=filter(b,a,out2);
output=output/max(abs(output));
% 通过声卡发音,比较原始语音和合成语音
% wavplay(xx,fs);
audioplayer(xx,fs);
pause(1)
% wavplay(output,fs);
audioplayer(output,fs);
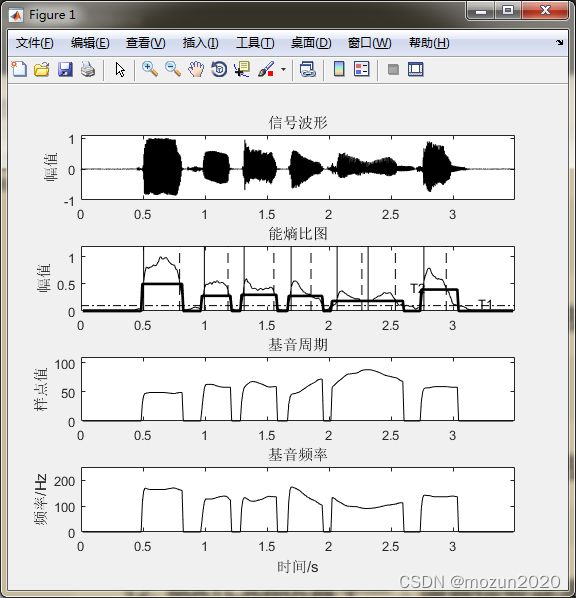
%% 作图
figure(1)
figure(1)
pos = get(gcf,'Position');
set(gcf,'Position',[pos(1), pos(2)-100,pos(3),(pos(4)+85)])
subplot 411; plot(time,x1,'k'); axis([0 max(time) -1 1.1]);
title('信号波形'); ylabel('幅值')
subplot 412; plot(frameTime,Ef,'k'); hold on
axis([0 max(time) 0 1.2]); plot(frameTime,T2,'k','linewidth',2);
line([0 max(time)],[T1 T1],'color','k','linestyle','-.');
title('能熵比图'); axis([0 max(time) 0 1.2]); ylabel('幅值')
text(3.2,T1+0.05,'T1');
for k=1 : vsl
line([frameTime(vseg(k).begin) frameTime(vseg(k).begin)],...
[0 1.2],'color','k','Linestyle','-');
line([frameTime(vseg(k).end) frameTime(vseg(k).end)],...
[0 1.2],'color','k','Linestyle','--');
if k==vsl
Tx=T2(floor((vseg(k).begin+vseg(k).end)/2));
end
end
text(2.65,Tx+0.05,'T2');
subplot 413; plot(frameTime,Dpitch,'k');
axis([0 max(time) 0 110]);title('基音周期'); ylabel('样点值')
subplot 414; plot(frameTime,Dfreq,'k');
axis([0 max(time) 0 250]);title('基音频率'); ylabel('频率/Hz')
xlabel('时间/s');
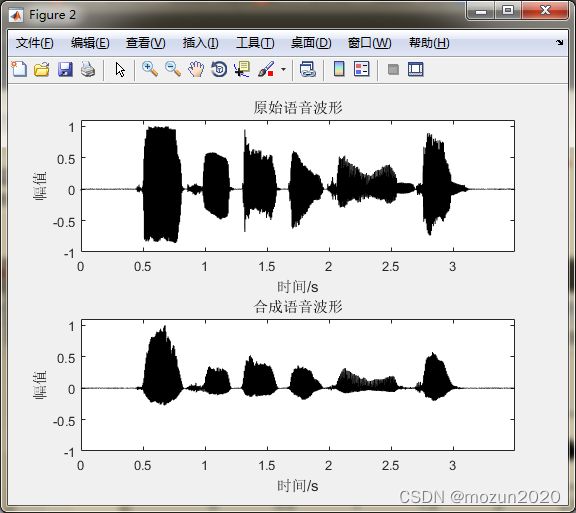
figure(2)
subplot 211; plot(time,x1,'k'); title('原始语音波形');
axis([0 max(time) -1 1.1]); xlabel('时间/s'); ylabel('幅值')
subplot 212; plot(time,output,'k'); title('合成语音波形');
axis([0 max(time) -1 1.1]); xlabel('时间/s'); ylabel('幅值')
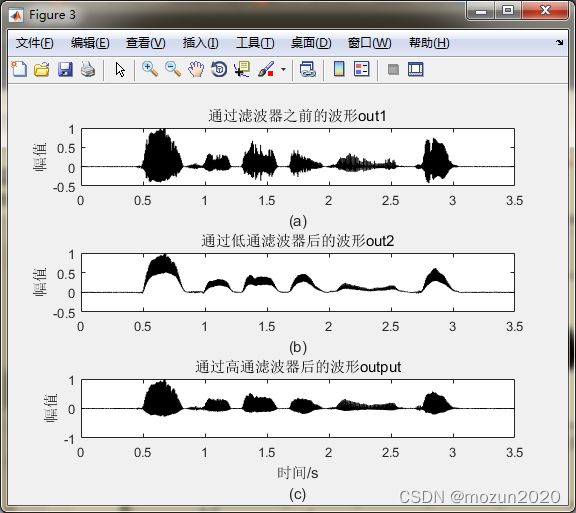
figure(3)
out1=out1/max(out1);
subplot 311; plot(time,out1,'k');
title('通过滤波器之前的波形out1')
ylabel('幅值'); ylim([-0.5 1]); xlabel('(a)');
out2=out2/max(out2);
subplot 312; plot(time,out2,'k');
title('通过低通滤波器后的波形out2')
ylabel('幅值'); ylim([-0.5 1]); xlabel('(b)');
subplot 313; plot(time,output,'k');
title('通过高通滤波器后的波形output')
xlabel(['时间/s' 10 '(c)']); ylabel('幅值')
10. MATLAB仿真九:基音与共振峰语音合成四
%
% pr10_5_4
clear all; clc; close all;
filedir=[]; % 设置数据文件的路径
filename='colorcloud.wav'; % 设置数据文件的名称
fle=[filedir filename] % 构成路径和文件名的字符串
% [xx,fs]=wavread(fle); % 读取文件
[xx,fs]=audioread(fle); % 读取文件
xx=xx-mean(xx); % 去除直流分量
x1=xx/max(abs(xx)); % 归一化
x=filter([1 -.99],1,x1); % 预加重
N=length(x); % 数据长度
time=(0:N-1)/fs; % 信号的时间刻度
wlen=240; % 帧长
inc=80; % 帧移
overlap=wlen-inc; % 重叠长度
tempr1=(0:overlap-1)'/overlap; % 斜三角窗函数w1
tempr2=(overlap-1:-1:0)'/overlap; % 斜三角窗函数w2
n2=1:wlen/2+1; % 正频率的下标值
wind=hanning(wlen); % 窗函数
X=enframe(x,wlen,inc)'; % 分帧
fn=size(X,2); % 帧数
Etemp=sum(X.*X); % 计算每帧能量
Etemp=Etemp/max(Etemp); % 能量归一化
T1=0.1; r2=0.5; % 端点检测参数
miniL=10; % 有话段最短帧数
mnlong=5; % 元音主体最短帧数
ThrC=[10 12]; % 阈值
p=12; % LPC阶次
frameTime=frame2time(fn,wlen,inc,fs); % 每帧对应的时间刻度
% 基音检测
[Dpitch,Dfreq,Ef,SF,voiceseg,vosl,vseg,vsl,T2]=...
Ext_F0ztms(xx,fs,wlen,inc,T1,r2,miniL,mnlong,ThrC,0);
const=fs/(2*pi); % 常数
Frmt=ones(3,fn)*nan; % 初始化
Bw=ones(3,fn)*nan;
zint=zeros(2,4); % 初始化
tal=0;
cepstL=6; % 倒频率上窗函数的宽度
wlen2=wlen/2; % 取帧长一半
df=fs/wlen; % 计算频域的频率刻度
for i=1 : fn
%% 共振峰和带宽的提取
u=X(:,i); % 取一帧数据
u2=u.*wind; % 信号加窗函数
U=fft(u2); % 按式(10-5-6)计算FFT
U2=abs(U(1:wlen2)).^2; % 计算功率谱
U_abs=log(U2); % 按式(10-5-7)计算对数
Cepst=ifft(U_abs); % 按式(10-5-8)计算IDFT
cepst=zeros(1,wlen2);
cepst(1:cepstL)=Cepst(1:cepstL); % 按式(10-5-9)乘窗函数
cepst(end-cepstL+2:end)=Cepst(end-cepstL+2:end);
spect=real(fft(cepst)); % 按式(10-5-10)计算DFT
[Loc,Val]=findpeaks(spect); % 寻找峰值
Spe=exp(spect); % 按式(10-5-11)计算线性功率谱值
ll=min(3,length(Loc));
for k=1 : ll
m=Loc(k); % 设置m-1,m和m+1
m1=m-1; m2=m+1;
pp=Spe(m); % 设置P(m-1),P(m)和P(m+1)
pp1=Spe(m1); pp2=Spe(m2);
aa=(pp1+pp2)/2-pp; % 按式(10-5-13)计算
bb=(pp2-pp1)/2;
cc=pp;
dm=-bb/2/aa;
Pp=-bb*bb/4/aa+cc; % 按式(10-5-14)计算
m_new=m+dm;
bf=-sqrt(bb*bb-4*aa*(cc-Pp/2))/aa;
F(k)=(m_new-1)*df; % 按式(10-5-12)计算共振峰频率
bw(k)=bf*df; % 按式(10-5-12)计算共振峰带宽
end
Frmt(:,i)=F; % 把共振峰频率存放在Frmt中
Bw(:,i)=bw; % 把带宽存放在Bw中
end
%% 语音合成
for i=1 : fn
yf=Frmt(:,i); % 取来i帧的三个共振峰频率和带宽
bw=Bw(:,i);
[an,bn]=formant2filter4(yf,bw,fs); % 转换成四个二阶滤波器系数
synt_frame=zeros(wlen,1);
if SF(i)==0 % 无话帧
excitation=randn(wlen,1); % 产生白噪声
for k=1 : 4 % 对四个滤波器并联输入
An=an(:,k);
Bn=bn(k);
[out(:,k),zint(:,k)]=filter(Bn(1),An,excitation,zint(:,k));
synt_frame=synt_frame+out(:,k); % 四个滤波器输出叠加在一起
end
else % 有话帧
PT=round(Dpitch(i)); % 取周期值
exc_syn1 =zeros(wlen+tal,1); % 初始化脉冲发生区
exc_syn1(mod(1:tal+wlen,PT)==0)=1; % 在基音周期的位置产生脉冲,幅值为1
exc_syn2=exc_syn1(tal+1:tal+inc); % 计算帧移inc区间内的脉冲个数
index=find(exc_syn2==1);
excitation=exc_syn1(tal+1:tal+wlen);% 这一帧的激励脉冲源
if isempty(index) % 帧移inc区间内没有脉冲
tal=tal+inc; % 计算下一帧的前导零点
else % 帧移inc区间内有脉冲
eal=length(index); % 计算有几个脉冲
tal=inc-index(eal); % 计算下一帧的前导零点
end
for k=1 : 4 % 对四个滤波器并联输入
An=an(:,k);
Bn=bn(k);
[out(:,k),zint(:,k)]=filter(Bn(1),An,excitation,zint(:,k));
synt_frame=synt_frame+out(:,k); % 四个滤波器输出叠加在一起
end
end
Et=sum(synt_frame.*synt_frame); % 用能量归正合成语音
rt=Etemp(i)/Et;
synt_frame=sqrt(rt)*synt_frame;
synt_speech_HF(:,i)=synt_frame;
if i==1 % 若为第1帧
output=synt_frame; % 不需要重叠相加,保留合成数据
else
M=length(output); % 按线性比例重叠相加处理合成数据
output=[output(1:M-overlap); output(M-overlap+1:M).*tempr2+...
synt_frame(1:overlap).*tempr1; synt_frame(overlap+1:wlen)];
end
end
ol=length(output); % 把输出output延长至与输入信号xx等长
if ol<N
output=[output; zeros(N-ol,1)];
end
out1=output;
b=[0.964775 -3.858862 5.788174 -3.858862 0.964775]; % 滤波器系数
a=[1.000000 -4.918040 9.675693 -9.518749 4.682579 -0.921483];
output=filter(b,a,out1); % 通过低通和高通串接的滤波器
output=output/max(abs(output)); % 幅值归一化
% 通过声卡发音,比较原始语音和合成语音
% wavplay(xx,fs);
audioplayer(xx,fs);
pause(1)
% wavplay(output,fs);
audioplayer(output,fs);
%% 作图
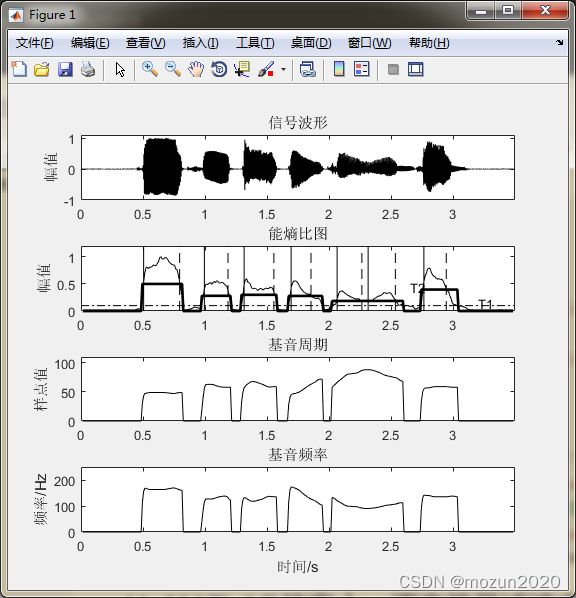
figure(1)
pos = get(gcf,'Position');
set(gcf,'Position',[pos(1), pos(2)-100,pos(3),(pos(4)+85)])
subplot 411; plot(time,x1,'k'); axis([0 max(time) -1 1.1]);
title('信号波形'); ylabel('幅值');
subplot 412; plot(frameTime,Ef,'k'); hold on
axis([0 max(time) 0 1.2]); plot(frameTime,T2,'k','linewidth',2);
line([0 max(time)],[T1 T1],'color','k','linestyle','-.');
title('能熵比图'); axis([0 max(time) 0 1.2]); ylabel('幅值');
text(3.2,T1+0.05,'T1');
for k=1 : vsl
line([frameTime(vseg(k).begin) frameTime(vseg(k).begin)],...
[0 1.2],'color','k','Linestyle','-');
line([frameTime(vseg(k).end) frameTime(vseg(k).end)],...
[0 1.2],'color','k','Linestyle','--');
if k==vsl
Tx=T2(floor((vseg(k).begin+vseg(k).end)/2));
end
end
text(2.65,Tx+0.05,'T2');
subplot 413; plot(frameTime,Dpitch,'k');
axis([0 max(time) 0 110]);title('基音周期'); ylabel('样点值');
subplot 414; plot(frameTime,Dfreq,'k');
axis([0 max(time) 0 250]);title('基音频率'); ylabel('频率/Hz');
xlabel('时间/s');
figure(2)
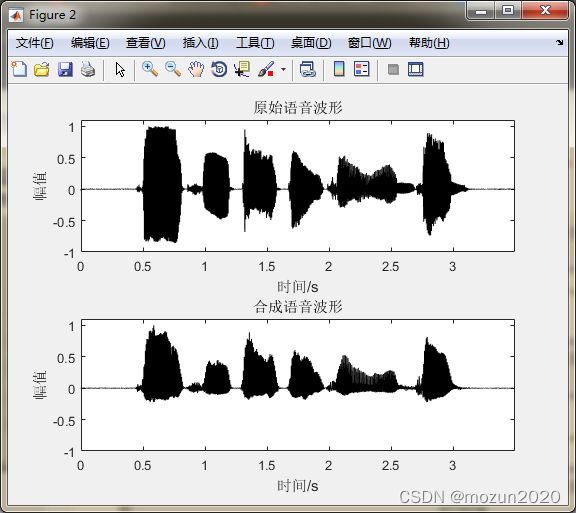
subplot 211; plot(time,x1,'k'); title('原始语音波形');
axis([0 max(time) -1 1.1]); xlabel('时间/s'); ylabel('幅值')
subplot 212; plot(time,output,'k'); title('合成语音波形');
axis([0 max(time) -1 1.1]); xlabel('时间/s'); ylabel('幅值')
11. MATLAB仿真十:语音信号的变速
%
% pr10_6_1
clear all; clc; close all;
filedir=[]; % 设置数据文件的路径
filename='colorcloud.wav'; % 设置数据文件的名称
fle=[filedir filename] % 构成路径和文件名的字符串
% [xx,fs]=wavread(fle); % 读取文件
[xx,fs]=audioread(fle); % 读取文件
xx=xx-mean(xx); % 去除直流分量
x=xx/max(abs(xx)); % 归一化
N=length(x); % 数据长度
time=(0:N-1)/fs; % 信号的时间刻度
wlen=240; % 帧长
inc=80; % 帧移
overlap=wlen-inc; % 重叠长度
tempr1=(0:overlap-1)'/overlap; % 斜三角窗函数w1
tempr2=(overlap-1:-1:0)'/overlap; % 斜三角窗函数w2
n2=1:wlen/2+1; % 正频率的下标值
X=enframe(x,wlen,inc)'; % 分帧
fn=size(X,2); % 帧数
T1=0.1; r2=0.5; % 端点检测参数
miniL=10; % 有话段最短帧数
mnlong=5; % 元音主体最短帧数
ThrC=[10 15]; % 阈值
p=12; % LPC阶次
frameTime=frame2time(fn,wlen,inc,fs); % 计算每帧的时间刻度
in=input('请输入伸缩语音的时间长度是原语音时间长度的倍数:','s');%输入伸缩长度比例
rate=str2num(in);
for i=1 : fn % 求取每帧的预测系数和增益
u=X(:,i);
[ar,g]=lpc(u,p);
AR_coeff(:,i)=ar;
Gain(i)=g;
end
% 基音检测
[Dpitch,Dfreq,Ef,SF,voiceseg,vosl,vseg,vsl,T2]=...
Ext_F0ztms(x,fs,wlen,inc,T1,r2,miniL,mnlong,ThrC,0);
tal=0; % 初始化
zint=zeros(p,1);
%% LSP参数的提取
for i=1 : fn
a2=AR_coeff(:,i); % 取来本帧的预测系数
lsf=ar2lsf(a2); % 调用ar2lsf函数求出lsf
Glsf(:,i)=lsf; % 把lsf存储在Glsf数组中
end
% 通过内插把相应数组缩短或伸长
fn1=floor(rate*fn); % 设置新的总帧数fn1
Glsfm=interp1((1:fn),Glsf',linspace(1,fn,fn1))';% 把LSF系数内插
Dpitchm=interp1(1:fn,Dpitch,linspace(1,fn,fn1));% 把基音周期内插
Gm=interp1((1:fn),Gain,linspace(1,fn,fn1));%把增益系数内插
SFm=interp1((1:fn),SF,linspace(1,fn,fn1)); %把SF系数内插
%% 语音合成
for i=1:fn1;
lsf=Glsfm(:,i); % 获取本帧的lsf参数
ai=lsf2ar(lsf); % 调用lsf2ar函数把lsf转换成预测系数ar
sigma=sqrt(Gm(i));
if SFm(i)==0 % 无话帧
excitation=randn(wlen,1); % 产生白噪声
[synt_frame,zint]=filter(sigma,ai,excitation,zint);
else % 有话帧
PT=round(Dpitchm(i)); % 取周期值
exc_syn1 =zeros(wlen+tal,1); % 初始化脉冲发生区
exc_syn1(mod(1:tal+wlen,PT)==0)=1;% 在基音周期的位置产生脉冲,幅值为1
exc_syn2=exc_syn1(tal+1:tal+inc); % 计算帧移inc区间内的脉冲个数
index=find(exc_syn2==1);
excitation=exc_syn1(tal+1:tal+wlen);% 这一帧的激励脉冲源
if isempty(index) % 帧移inc区间内没有脉冲
tal=tal+inc; % 计算下一帧的前导零点
else % 帧移inc区间内有脉冲
eal=length(index); % 计算有几个脉冲
tal=inc-index(eal); % 计算下一帧的前导零点
end
gain=sigma/sqrt(1/PT); % 增益
[synt_frame,zint]=filter(gain,ai,excitation,zint);%用激励脉冲合成语音
end
if i==1 % 若为第1帧
output=synt_frame; % 不需要重叠相加,保留合成数据
else
M=length(output); % 重叠部分的处理
output=[output(1:M-overlap); output(M-overlap+1:M).*tempr2+...
synt_frame(1:overlap).*tempr1; synt_frame(overlap+1:wlen)];
end
end
output(find(isnan(output)))=0;
bn=[0.964775 -3.858862 5.788174 -3.858862 0.964775]; % 滤波器系数
an=[1.000000 -3.928040 5.786934 -3.789685 0.930791];
output=filter(bn,an,output); % 高通滤波
output=output/max(abs(output)); % 幅值归一化
% 通过声卡发音,比较原始语音和合成语音
% wavplay(x,fs);
audioplayer(x,fs);
pause(1)
% wavplay(output,fs);
audioplayer(output,fs);
%% 作图
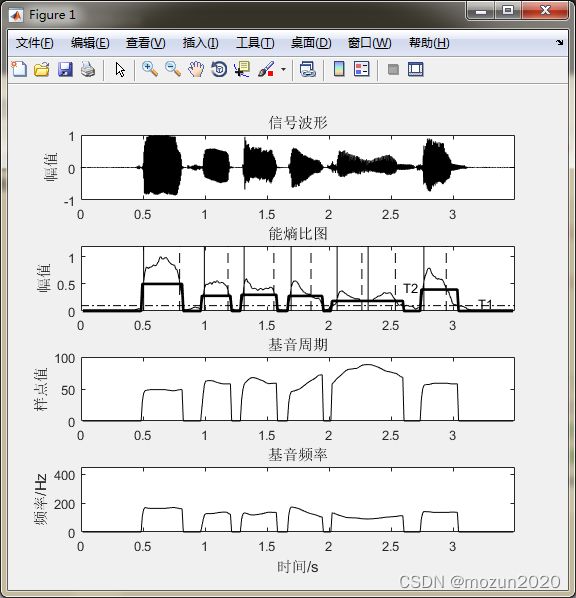
figure(1)
ol=length(output); % 输出数据长度
time1=(0:ol-1)/fs; % 求出输出序列的时间序列
pos = get(gcf,'Position');
set(gcf,'Position',[pos(1), pos(2)-100,pos(3),(pos(4)+85)])
subplot 411; plot(time,x,'k'); xlim([0 max(time)]);
title('信号波形'); ylabel('幅值');
subplot 412; plot(frameTime,Ef,'k'); hold on
axis([0 max(time) 0 1.2]); plot(frameTime,T2,'k','linewidth',2);
line([0 max(time)],[T1 T1],'color','k','linestyle','-.');
title('能熵比图'); axis([0 max(time) 0 1.2]); ylabel('幅值');
text(3.2,T1+0.05,'T1');
for k=1 : vsl
line([frameTime(vseg(k).begin) frameTime(vseg(k).begin)],...
[0 1.2],'color','k','Linestyle','-');
line([frameTime(vseg(k).end) frameTime(vseg(k).end)],...
[0 1.2],'color','k','Linestyle','--');
if k==vsl
Tx=T2(floor((vseg(k).begin+vseg(k).end)/2));
end
end
text(2.6,Tx+0.05,'T2');
subplot 413; plot(frameTime,Dpitch,'k');
axis([0 max(time) 0 100]);title('基音周期'); ylabel('样点值');
subplot 414; plot(frameTime,Dfreq,'k');
axis([0 max(time) 0 450]);title('基音频率'); ylabel('频率/Hz');
xlabel('时间/s');
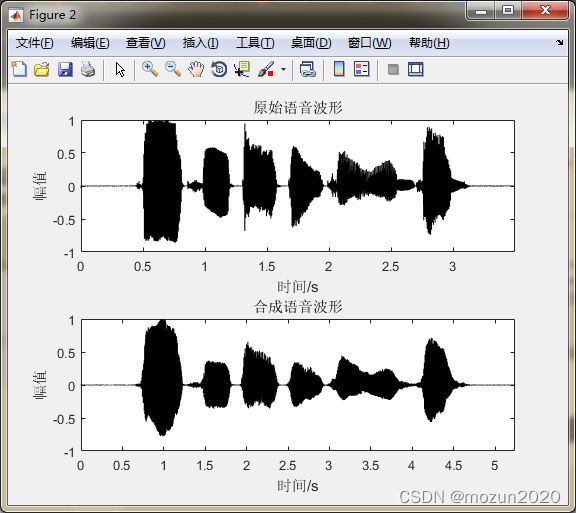
figure(2)
subplot 211; plot(time,x,'k'); title('原始语音波形');
axis([0 max(time) -1 1]); xlabel('时间/s'); ylabel('幅值')
subplot 212; plot(time1,output,'k'); title('合成语音波形');
xlim([0 max(time1)]); xlabel('时间/s'); ylabel('幅值')
fle =
colorcloud.wav
请输入伸缩语音的时间长度是原语音时间长度的倍数:1.5
12. MATLAB仿真十一:语音信号的变调
%
% pr10_6_2
clear all; clc; close all;
filedir=[]; % 设置数据文件的路径
filename='colorcloud.wav'; % 设置数据文件的名称
fle=[filedir filename] % 构成路径和文件名的字符串
% [xx,fs]=wavread(fle); % 读取文件
[xx,fs]=audioread(fle); % 读取文件
xx=xx-mean(xx); % 去除直流分量
x=xx/max(abs(xx)); % 幅值归一化
lx=length(x); % 数据长度
time=(0:lx-1)/fs; % 求出对应的时间序列
wlen=240; % 设定帧长
inc=80; % 设定帧移的长度
overlap=wlen-inc; % 重叠长度
tempr1=(0:overlap-1)'/overlap; % 斜三角窗函数w1
tempr2=(overlap-1:-1:0)'/overlap; % 斜三角窗函数w2
n2=1:wlen/2+1; % 正频率的下标值
X=enframe(x,wlen,inc)'; % 按照参数进行分帧
fn=size(X,2); % 总帧数
T1=0.1; r2=0.5; % 端点检测参数
miniL=10; % 有话段最短帧数
mnlong=5; % 元音主体最短帧数
ThrC=[10 15]; % 阈值
p=12; % LPC阶次
frameTime=frame2time(fn,wlen,inc,fs); % 每帧对应的时间刻度
in=input('请输入基音频率升降的倍数:','s'); % 输入基音频率增降比例
rate=str2num(in);
for i=1 : fn % 求取每帧的预测系数和增益
u=X(:,i);
[ar,g]=lpc(u,p);
AR_coeff(:,i)=ar;
Gain(i)=g;
end
% 基音检测
[Dpitch,Dfreq,Ef,SF,voiceseg,vosl,vseg,vsl,T2]=...
Ext_F0ztms(x,fs,wlen,inc,T1,r2,miniL,mnlong,ThrC,0);
if rate>1, sign=1; else sign=-1; end
lmin=floor(fs/450); % 基音周期的最小值
lmax=floor(fs/60); % 基音周期的最大值
deltaOMG = sign*100*2*pi/fs; % 根值顺时针或逆时针旋转量dθ
Dpitchm=Dpitch/rate; % 增减后的基音周期
Dfreqm=Dfreq*rate; % 增减后的基音频率
tal=0; % 初始化
zint=zeros(p,1);
for i=1 : fn
a=AR_coeff(:,i); % 取得本帧的AR系数
sigma=sqrt(Gain(i)); % 取得本帧的增益系数
if SF(i)==0 % 无话帧
excitation=randn(wlen,1); % 产生白噪声
[synt_frame,zint]=filter(sigma,a,excitation,zint);
else % 有话帧
PT=floor(Dpitchm(i)); % 把周期值变为整数
if PT<lmin, PT=lmin; end % 判断修改后的周期值有否超限
if PT>lmax, PT=lmax; end
ft=roots(a); % 对预测系数求根
ft1=ft;
%增减共振峰频率,求出新的根值
for k=1 : p
if imag(ft(k))>0,
ft1(k) = ft(k)*exp(1j*deltaOMG);
elseif imag(ft(k))<0
ft1(k) = ft(k)*exp(-1j*deltaOMG);
end
end
ai=poly(ft1); % 由新的根值重新组成预测系数
exc_syn1 =zeros(wlen+tal,1); % 初始化脉冲发生区
exc_syn1(mod(1:tal+wlen,PT)==0)=1;% 在基音周期的位置产生脉冲,幅值为1
exc_syn2=exc_syn1(tal+1:tal+inc); % 计算帧移inc区间内的脉冲个数
index=find(exc_syn2==1);
excitation=exc_syn1(tal+1:tal+wlen);% 这一帧的激励脉冲源
if isempty(index) % 帧移inc区间内没有脉冲
tal=tal+inc; % 计算下一帧的前导零点
else % 帧移inc区间内有脉冲
eal=length(index); % 计算脉冲个数
tal=inc-index(eal); % 计算下一帧的前导零点
end
gain=sigma/sqrt(1/PT); % 增益
[synt_frame,zint]=filter(gain,ai,excitation,zint);%用激励脉冲合成语音
end
if i==1 % 若为第1帧
output=synt_frame; % 不需要重叠相加,保留合成数据
else
M=length(output); % 重叠部分的处理
output=[output(1:M-overlap); output(M-overlap+1:M).*tempr2+...
synt_frame(1:overlap).*tempr1; synt_frame(overlap+1:wlen)];
end
end
output(find(isnan(output)))=0;
ol=length(output); % 把输出output延长至与输入信号xx等长
if ol<lx
output1=[output; zeros(lx-ol,1)];
else
output1=output(1:lx);
end
bn=[0.964775 -3.858862 5.788174 -3.858862 0.964775]; % 滤波器系数
an=[1.000000 -3.928040 5.786934 -3.789685 0.930791];
output=filter(bn,an,output1); % 高通滤波
output=output/max(abs(output)); % 幅值归一化
% 通过声卡发音,比较原始语音和合成语音
% wavplay(x,fs);
audioplayer(x,fs);
pause(1)
% wavplay(output,fs);
audioplayer(output,fs);
%% 作图
figure(1)
pos = get(gcf,'Position');
set(gcf,'Position',[pos(1), pos(2)-150,pos(3),(pos(4)+100)])
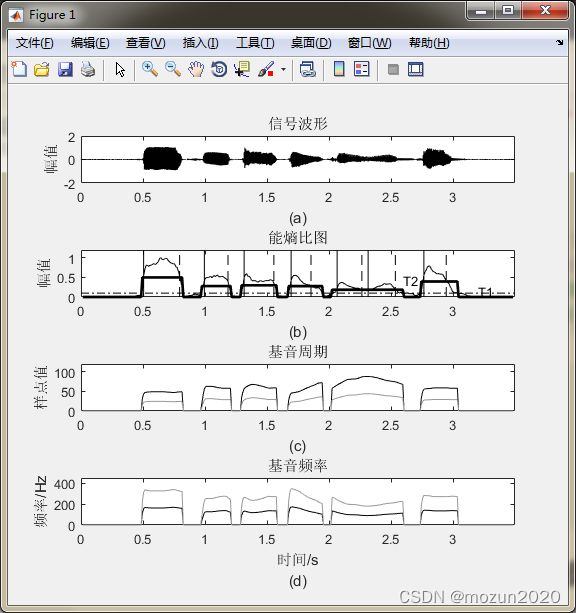
subplot 411; plot(time,xx,'k'); xlim([0 max(time)]);
title('信号波形'); ylabel('幅值'); xlabel('(a)');
subplot 412; plot(frameTime,Ef,'k'); hold on; xlabel('(b)')
axis([0 max(time) 0 1.2]); plot(frameTime,T2,'k','linewidth',2);
line([0 max(time)],[T1 T1],'color','k','linestyle','-.');
title('能熵比图'); axis([0 max(time) 0 1.2]); ylabel('幅值');
text(3.2,T1+0.05,'T1');
for k=1 : vsl
line([frameTime(vseg(k).begin) frameTime(vseg(k).begin)],...
[0 1.2],'color','k','Linestyle','-');
line([frameTime(vseg(k).end) frameTime(vseg(k).end)],...
[0 1.2],'color','k','Linestyle','--');
if k==vsl
Tx=T2(floor((vseg(k).begin+vseg(k).end)/2));
end
end
text(2.6,Tx+0.05,'T2');
subplot 413; plot(frameTime,Dpitch,'k'); hold on; xlabel('(c)')
line(frameTime,Dpitchm,'color',[.6 .6 .6]);
axis([0 max(time) 0 120]); title('基音周期'); ylabel('样点值');
subplot 414; plot(frameTime,Dfreq,'k'); hold on
line(frameTime,Dfreqm,'color',[.6 .6 .6]);
axis([0 max(time) 0 450]); title('基音频率'); ylabel('频率/Hz');
xlabel(['时间/s' 10 '(d)']);
figure(2)
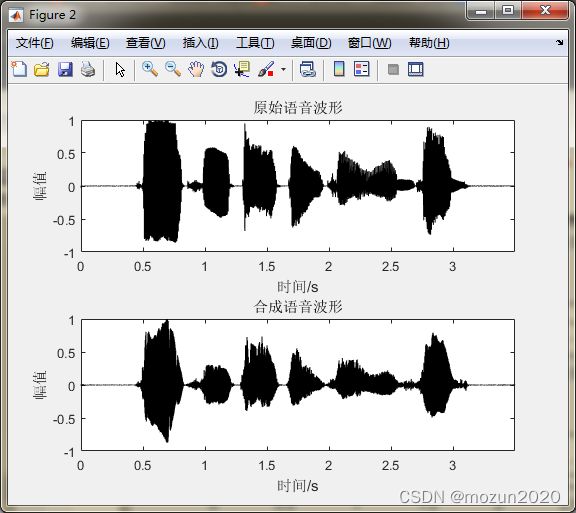
subplot 211; plot(time,x,'k'); title('原始语音波形');
axis([0 max(time) -1 1]); xlabel('时间/s'); ylabel('幅值')
subplot 212; plot(time,output,'k'); title('合成语音波形');
xlim([0 max(time)]); xlabel('时间/s'); ylabel('幅值')
fle =
colorcloud.wav
请输入基音频率升降的倍数:2
13. MATLAB仿真十二:语音信号的变速与变调
%
% pr10_6_3
clear all; clc; close all;
filedir=[]; % 设置数据文件的路径
filename='colorcloud.wav'; % 设置数据文件的名称
fle=[filedir filename] % 构成路径和文件名的字符串
% [xx,fs,nbits]=wavread(fle); % 读取文件
[xx,fs]=audioread(fle); % 读取文件
xx=xx-mean(xx); % 去除直流分量
x=xx/max(abs(xx)); % 幅值归一化
lx=length(x); % 数据长度
time=(0:lx-1)/fs; % 求出对应的时间序列
wlen=320; % 设定帧长
inc=80; % 设定帧移的长度
overlap=wlen-inc; % 重叠长度
tempr1=(0:overlap-1)'/overlap; % 斜三角窗函数w1
tempr2=(overlap-1:-1:0)'/overlap; % 斜三角窗函数w2
n2=1:wlen/2+1; % 正频率的下标值
X=enframe(x,wlen,inc)'; % 按照参数进行分帧
fn=size(X,2); % 总帧数
T1=0.1; r2=0.5; % 端点检测参数
miniL=10; % 有话段最短帧数
mnlong=5; % 元音主体最短帧数
ThrC=[10 15]; % 阈值
p=12; % LPC阶次
frameTime=frame2time(fn,wlen,inc,fs); % 每帧对应的时间刻度
in=input('请输入伸缩语音的时间长度是原语音时间长度的倍数:','s');%输入伸缩长度比例
rate=str2num(in);
in=input('请输入基音频率升降的倍数:','s'); % 输入基音频率增降比例
rate1=1/str2num(in);
Dpitch=zeros(1,fn); Dfreq=zeros(1,fn);
for i=1 : fn % 求取每帧的预测系数和增益
u=X(:,i);
[ar,g]=lpc(u,p);
AR_coeff(:,i)=ar;
Gain(i)=g;
end
% 基音检测
[Dpitch,Dfreq,Ef,SF,voiceseg,vosl,vseg,vsl,T2]=...
Ext_F0ztms(xx,fs,wlen,inc,T1,r2,miniL,mnlong,ThrC,0);
Dpitchm=Dpitch*rate1;
if rate1==1, sign=0; elseif rate1>1, sign=1; else sign=-1; end
lmin=floor(fs/450); % 基音周期的最小值
lmax=floor(fs/60); % 基音周期的最大值
deltaOMG = sign*100*2*pi/fs; % 极点左旋或右旋的dθ
tal=0; % 初始化
zint=zeros(p,1);
for i=1 : fn
a2=AR_coeff(:,i); % 取来本帧的预测系数
lsf=ar2lsf(a2); % 调用ar2lsf函数求出lsf
Glsf(:,i)=lsf; % 把lsf存储在Glsf数组中
end
% 通过内插把相应数组缩短或伸长
fn1=floor(rate*fn); % 设置新的总帧数fn1
Glsfm=interp1((1:fn)',Glsf',linspace(1,fn,fn1)')'; %把LSF系数内插
Dpitchm=interp1(1:fn,Dpitchm,linspace(1,fn,fn1)); %把基音周期内插
Gm=interp1((1:fn),Gain,linspace(1,fn,fn1)); %把增益系数内插
SFm=interp1((1:fn),SF,linspace(1,fn,fn1)); %把SF系数内插
for i=1:fn1;
lsf=Glsfm(:,i); % 获取本帧的lsf参数
a=lsf2ar(lsf); % 调用lsf2ar函数把lsf转换成预测系数ar
sigma=sqrt(Gm(i));
if SFm(i)==0 % 无话帧
excitation=randn(wlen,1); % 产生白噪声
[synt_frame,zint]=filter(sigma,a,excitation,zint);
else % 有话帧
PT=floor(Dpitchm(i)); % 把周期值变为整数
if PT<lmin, PT=lmin; end
if PT>lmax, PT=lmax; end
ft=roots(a);
ft1=ft;
%增减共振峰频率
for k=1 : p
if imag(ft(k))>0,
ft1(k) = ft(k)*exp(1j*deltaOMG);
elseif imag(ft(k))<0
ft1(k) = ft(k)*exp(-1j*deltaOMG);
end
end
ai=poly(ft1); % 由新的根值重组成AR系数
exc_syn1 =zeros(wlen+tal,1); % 初始化脉冲发生区
exc_syn1(mod(1:tal+wlen,PT)==0) = 1; % 在基音周期的位置产生脉冲,幅值为1
exc_syn2=exc_syn1(tal+1:tal+inc); % 计算帧移inc区间内的脉冲个数
index=find(exc_syn2==1);
excitation=exc_syn1(tal+1:tal+wlen);% 这一帧的激励脉冲源
if isempty(index) % 帧移inc区间内没有脉冲
tal=tal+inc; % 计算下一帧的前导零点
else % 帧移inc区间内有脉冲
eal=length(index); % 计算脉冲个数
tal=inc-index(eal); % 计算下一帧的前导零点
end
gain=sigma/sqrt(1/PT); % 增益
[synt_frame,zint]=filter(gain, ai,excitation,zint); % 用激冲合成语音
end
if i==1 % 若为第1帧
output=synt_frame; % 不需要重叠相加,保留合成数据
else
M=length(output); % 重叠部分的处理
output=[output(1:M-overlap); output(M-overlap+1:M).*tempr2+...
synt_frame(1:overlap).*tempr1; synt_frame(overlap+1:wlen)];
end
end
output(find(isnan(output)))=0;
ol=length(output); % 输出数据长度
time1=(0:ol-1)/fs; % 求出输出序列的时间序列
bn=[0.964775 -3.858862 5.788174 -3.858862 0.964775]; % 滤波器系数
an=[1.000000 -3.928040 5.786934 -3.789685 0.930791];
output=filter(bn,an,output); % 高通滤波
output=output/max(abs(output)); % 幅值归一化
% wavplay(x,fs);
audioplayer(x,fs);
pause(1)
% wavplay(output,fs);
audioplayer(output,fs);
%% 作图
figure(1)
figure(1)
pos = get(gcf,'Position');
set(gcf,'Position',[pos(1), pos(2)-100,pos(3),(pos(4)+85)])
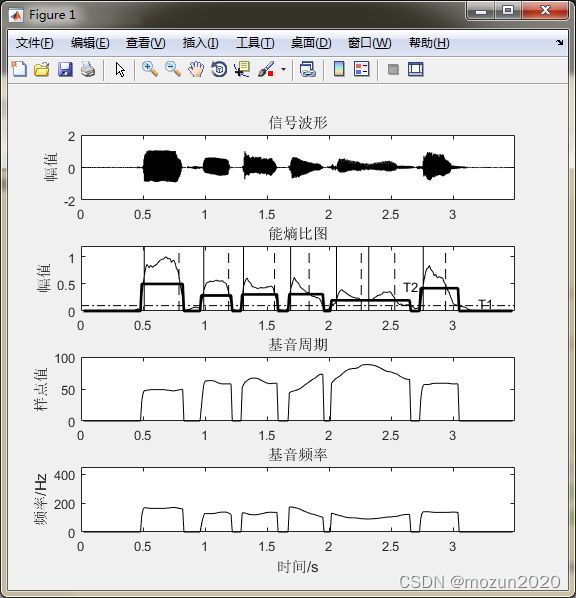
subplot 411; plot(time,xx,'k'); xlim([0 max(time)]);
title('信号波形'); ylabel('幅值');
subplot 412; plot(frameTime,Ef,'k'); hold on;
axis([0 max(time) 0 1.2]); plot(frameTime,T2,'k','linewidth',2);
line([0 max(time)],[T1 T1],'color','k','linestyle','-.');
title('能熵比图'); axis([0 max(time) 0 1.2]); ylabel('幅值');
text(3.2,T1+0.05,'T1');
for k=1 : vsl
line([frameTime(vseg(k).begin) frameTime(vseg(k).begin)],...
[0 1.2],'color','k','Linestyle','-');
line([frameTime(vseg(k).end) frameTime(vseg(k).end)],...
[0 1.2],'color','k','Linestyle','--');
if k==vsl
Tx=T2(floor((vseg(k).begin+vseg(k).end)/2));
end
end
text(2.6,Tx+0.05,'T2');
subplot 413; plot(frameTime,Dpitch,'k');
axis([0 max(time) 0 100]);title('基音周期'); ylabel('样点值');
subplot 414; plot(frameTime,Dfreq,'k');
axis([0 max(time) 0 450]);title('基音频率'); ylabel('频率/Hz');
xlabel('时间/s');
figure(2)
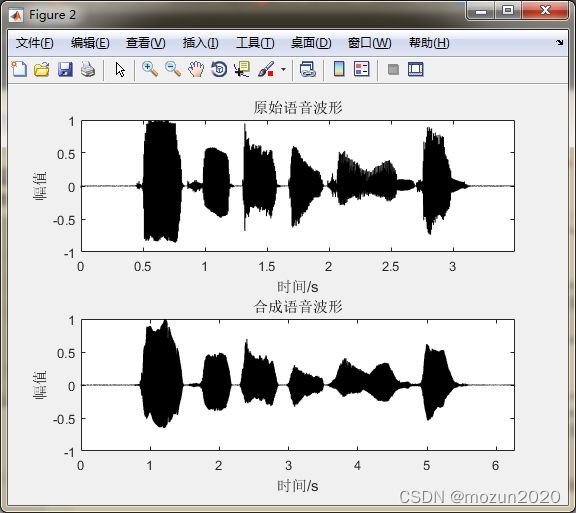
subplot 211; plot(time,x,'k'); title('原始语音波形');
axis([0 max(time) -1 1]); xlabel('时间/s'); ylabel('幅值')
subplot 212; plot(time1,output,'k'); title('合成语音波形');
xlim([0 max(time1)]); xlabel('时间/s'); ylabel('幅值')
fle =
colorcloud.wav
请输入伸缩语音的时间长度是原语音时间长度的倍数:1.8
请输入基音频率升降的倍数:1.6
14. MATLAB仿真十三:时域基音同步叠加(TD-PSOLA)语音合成一
%
% pr10_7_1
clear all; clc; close all;
filedir=[]; % 设置数据文件的路径
filename='bluesky3.wav'; % 设置数据文件的名称
fle=[filedir filename] % 构成路径和文件名的字符串
% [xx,fs]=wavread(fle); % 读取文件
[xx,fs]=audioread(fle); % 读取文件
xx=xx-mean(xx); % 去除直流分量
x=xx/max(abs(xx)); % 归一化
N=length(x); % 数据长度
time=(0:N-1)/fs; % 求出对应的时间序列
[LowPass] = LowPassFilter(x, fs, 500); % 低通滤波
p = PitchEstimation(LowPass, fs); % 计算基音频率
[u, v] = UVSplit(p); % 求出有话段和无话段信息
lu=size(u,1); lv=size(v,1); % 初始化
pm = [];
ca = [];
for i = 1 : length(v(:,1))
range = (v(i, 1) : v(i, 2)); % 取一个有话段信息
in = x(range); % 取有话段数据
% 对一个有话段寻找基音脉冲标注
[marks, cans] = VoicedSegmentMarking(in, p(range), fs);
pm = [pm (marks + range(1))]; % 保存基音脉冲标注位置
ca = [ca; (cans + range(1))]; % 保存基音脉冲标注候选名单
end
% 作图
figure(1)
pos = get(gcf,'Position');
set(gcf,'Position',[pos(1), pos(2)-150,pos(3),pos(4)+100]);
subplot 211; plot(time,x,'k'); axis([0 max(time) -1 1.2]);
for k=1 : lv
line([time(v(k,1)) time(v(k,1))],[-1 1.2 ],'color','k','linestyle','-')
line([time(v(k,2)) time(v(k,2))],[-1 1.2 ],'color','k','linestyle','--')
end
title('语音信号波形和端点检测');
xlabel(['时间/s' 10 '(a)']); ylabel('幅值');
%figure(2)
%pos = get(gcf,'Position');
%set(gcf,'Position',[pos(1), pos(2)-100,pos(3),(pos(4)-160)]);
subplot 212; plot(x,'k'); axis([0 N -1 0.8]);
line([0 N],[0 0],'color','k')
lpm=length(pm);
for k=1 : lpm
line([pm(k) pm(k)],[0 0.8],'color','k','linestyle','-.')
end
xlim([3000 4000]);
title('部分语音信号波形和相应基音脉冲标注');
xlabel(['样点' 10 '(b)']); ylabel('幅值');
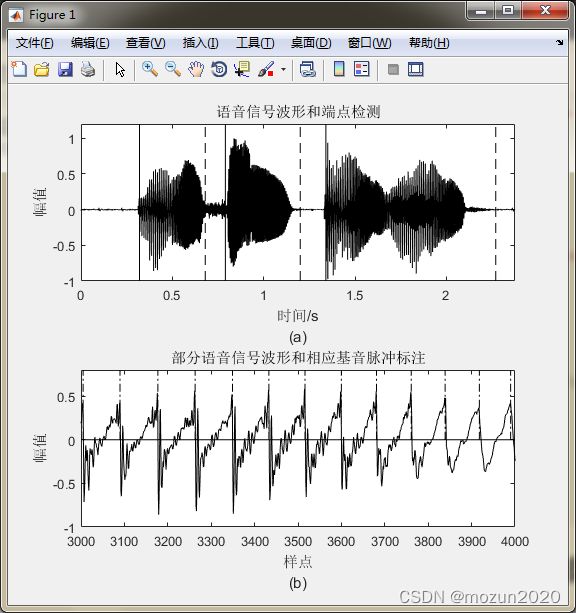
15. MATLAB仿真十四:时域基音同步叠加(TD-PSOLA)语音合成二
%
% pr10_7_2
clear all; clc; close all;
global config; % 全局变量config
config.pitchScale = 2.0; % 设置基频修改因子
config.timeScale = 1.5; % 设置时长修改因子
config.resamplingScale = 1; % 重采样
config.reconstruct = 0; % 如果为真进行低通谱重构
config.cutOffFreq = 500; % 低通滤波器的截止频率
global data; % 全局变量data,先初始化
data.waveOut = []; % 按基频修改因子和时长修改因子调整后的合成语音输出
data.pitchMarks = []; % 输入语音信号的基音脉冲标注
data.Candidates = []; % 输入语音信号基音脉冲标注的候选名单
filedir=[]; % 设置数据文件的路径
filename='colorcloud.wav'; % 设置数据文件的名称
fle=[filedir filename] % 构成路径和文件名的字符串
% [xx,fs]=wavread(fle); % 读取文件
[xx,fs]=audioread(fle); % 读取文件
xx=xx-mean(xx); % 去除直流分量
WaveIn=xx/max(abs(xx)); % 归一化
N=length(WaveIn); % 数据长度
time=(0:N-1)/fs; % 求出对应的时间序列
[LowPass] = LowPassFilter(WaveIn, fs, config.cutOffFreq); % 对信号进行低通滤波
PitchContour = PitchEstimation(LowPass, fs);% 求出语音信号的基音轨迹
PitchMarking1(WaveIn, PitchContour, fs); % 进行基音脉冲标注和PSOLA合成
output=data.waveOut;
N1=length(output); % 输出数据长度
time1=(0:N1-1)/fs; % 求出输出序列的时间序列
% wavplay(xx,fs);
audioplayer(xx,fs);
pause(1)
% wavplay(output,fs)
audioplayer(output,fs)
% 作图
subplot 211; plot(time,xx,'k');
xlabel('时间/s'); ylabel('幅值');
axis([0 max(time) -1 1.2 ]); title('原始语音')
subplot 212; plot(time1,output,'k');
xlabel('时间/s'); ylabel('幅值');
axis([0 max(time1) -1 1.5 ]); title('PSOLA合成语音')
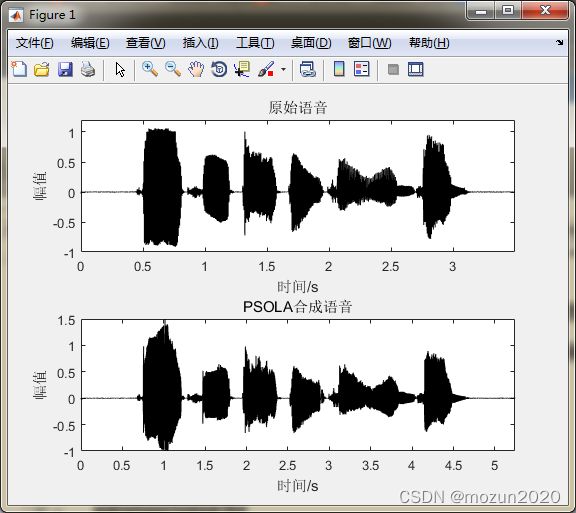
小结
语音信号的合成是目前应用比较广泛的一种语音信号处理技术,现在许多的音频软件或者视频剪辑中出现了很多经过语音合成的非人工的视频配音与音频,目前来说,在语句上完全达到与人声无异还有一定的距离。因为人声自然状态下不同的语句在不同场景的语调和情感都是不一样的,这一难关还有一段路程需要走。
对本章内容感兴趣或者想充分学习了解的,建议去研习书中第十章节的内容。后期会对其中一些知识点在自己理解的基础上进行讨论补充,欢迎大家一起学习交流。
关于宋老师:宋知用——默默传授MATLAB与信号处理知识的老人家
本系列文章列表如下:
《MATLAB语音信号分析与合成(第二版)》:第2章 语音信号的时域、频域特性和短时分析技术
《MATLAB语音信号分析与合成(第二版)》:第3章 语音信号在其他变换域中的分析技术和特性
《MATLAB语音信号分析与合成(第二版)》:第4章 语音信号的线性预测分析
《MATLAB语音信号分析与合成(第二版)》:第5章 带噪语音和预处理
《MATLAB语音信号分析与合成(第二版)》:第6章 语音端点的检测(1)
《MATLAB语音信号分析与合成(第二版)》:第6章 语音端点的检测(2)
《MATLAB语音信号分析与合成(第二版)》:第7章 语音信号的减噪
《MATLAB语音信号分析与合成(第二版)》:第8章 基音周期的估算方法
《MATLAB语音信号分析与合成(第二版)》:第9章 共振峰的估算方法
《MATLAB语音信号分析与合成(第二版)》:第10章 语音信号的合成算法