毕业设计 : 基于Spark的海量新闻文本聚类 - Spark 新闻分类 文本分类新闻聚类
文章目录
- 0 前言
- 1 项目介绍
- 2 实现流程
- 3 开发环境
- 4 java目录功能介绍
- 5 scala目录功能介绍
-
- 5.1 求TF-IDF
- 5.2 调用K-means模型
- 5.3 评价方式
- 6 聚类结果
- 7 最后
0 前言
Hi,这里是丹成学长,今天学长带大家实现一个大数据项目
**基于Spark的海量新闻文本聚类 **
1 项目介绍
在大数据开发领域,Spark的大名如雷贯耳,其RDD(弹性分布式数据集)/DataFrame的内存数据结构,在机器学习“迭代”算法的场景下,速度明显优于Hadoop磁盘落地的方式,此外,Spark丰富的生态圈也使得使用它为核心能够构建一整套大数据开发系统。
今天学长将采用Spark,利用tf-idf作为文本特征,k-means算法进行聚类。
各工具版本信息如下:
- Spark 2.0.0
- scala 2.11.8
- java 1.8
- hanlp 1.5.3
2 实现流程
所采用的数据集是已经预处理过的,每个类别的文件都按照1,2,3这样的数据开头,这里的1,2,3就代表类别1,类别2,类别3.这样会遇到一个问题,也是该博客实现过程中的一个bug,类别10的开头第一个字母也是‘1’,导致类别1的判定是存在争议的。但为了省事,笔者这里就只用其中的9类文本作为聚类文本,由已知标签,从而判断聚类效果。
参考中的博客采用的Spark版本偏老,为Spark1.6,现在Spark的版本已经迈进了2代,很多使用方法都不建议了,比如SQLContext,HiveContext和java2scala的一些数据结构转换。本文立足2.0版本的spark,将其中过时的地方代替,更加适合新手入门上手。
3 开发环境
开发环境采用idea+maven(虽然SBT在spark业界更加流行)
下面是学长的maven配置,放在pom.xml文件中:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>HanLP</groupId>
<artifactId>myHanLP</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<spark.version>2.0.0</spark.version>
<scala.version>2.11</scala.version>
</properties>
<dependencies>
<!-- scala环境,有了spark denpendencies后可以省略 -->
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>2.11.8</version>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-compiler</artifactId>
<version>2.11.8</version>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-reflect</artifactId>
<version>2.11.8</version>
</dependency>
<!-- 日志框架 -->
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.12</version>
</dependency>
<!-- 中文分词框架 -->
<dependency>
<groupId>com.hankcs</groupId>
<artifactId>hanlp</artifactId>
<version>portable-1.5.3</version>
</dependency>
<!-- Spark dependencies -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<version>2.15.2</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.6.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.19</version>
<configuration>
<skip>true</skip>
</configuration>
</plugin>
</plugins>
</build>
</project>
其中需要注意的有两个地方,第一个地方是scala.version,不要具体写到2.11.8,这样的话是找不到合适的spark依赖的,直接写2.11就好。第二个地方是maven-scala-plugin,这个地方主要是为了使得项目中java代码和scala代码共存的,毕竟它们俩是不一样的语言,虽然都能在jvm中跑,但编译器不一样呀…所以这个地方非常重要.
4 java目录功能介绍
java目录下的文件主要有两个功能:
- 测试Hanlp
- 转换编码、合并文件
测试hanlp工具,这是个开源的java版本分词工具,文件中分别测试了不同的分词功能。另一个是将所有文件从GBK编码模式转换成UTF-8,再将这些小文件写到一个大文件中。转换编码是为了文件读取顺利不报编码的错误。大文件是为了提高Spark或Hadoop这类工具的效率,这里涉及到它们的一些实现原理,简单来说,文件输入到Spark中还会有分块、切片的操作,大文件在这些操作时,效率更高。
5 scala目录功能介绍
scala目录下总共有4个子目录,分别是用来测试scala编译运行是否成功,调用Spark MLlib计算tf-idf,计算TF-IDF再利用K-means聚类,工具类。这里的工具类是原博客作者设计的,设计的目的是确定Spark是在本地测试,还是在集群上火力全来跑,并且适用于Window系统。因为我去掉了其封装的SQLContext(已不建议使用),所以这个工具类在我Linux操作系统下意义也不是很大…
5.1 求TF-IDF
求TF-IDF采用SparkSession替代SparkContext,如下:
package test_tfidf
import org.apache.spark.ml.feature.{HashingTF, IDF, Tokenizer}
import org.apache.spark.sql.SparkSession
//import utils.SparkUtils
/**
*测试Spark MLlib的tf-idf
* Created by zcy on 18-1-4.
*/
object TFIDFDemo {
def main(args: Array[String]) {
val spark_session = SparkSession.builder().appName("tf-idf").master("local[4]").getOrCreate()
import spark_session.implicits._ // 隐式转换
val sentenceData = spark_session.createDataFrame(Seq(
(0, "Hi I heard about Spark"),
(0, "I wish Java could use case classes"),
(1, "Logistic regression models are neat")
)).toDF("label", "sentence")
// 分词
val tokenizer = new Tokenizer().setInputCol("sentence").setOutputCol("words")
println("wordsData----------------")
val wordsData = tokenizer.transform(sentenceData)
wordsData.show(3)
// 求TF
println("featurizedData----------------")
val hashingTF = new HashingTF()
.setInputCol("words").setOutputCol("rawFeatures").setNumFeatures(2000) // 设置哈希表的桶数为2000,即特征维度
val featurizedData = hashingTF.transform(wordsData)
featurizedData.show(3)
// 求IDF
println("recaledData----------------")
val idf = new IDF().setInputCol("rawFeatures").setOutputCol("features")
val idfModel = idf.fit(featurizedData)
val rescaledData = idfModel.transform(featurizedData)
rescaledData.show(3)
println("----------------")
rescaledData.select("features", "label").take(3).foreach(println)
}
}
上面TF转换特征向量的代码设置了桶数,即特征向量的维度,这里将每个文本用2000个特征向量表示。
5.2 调用K-means模型
// Trains a k-means model.
println("creating kmeans model ...")
val kmeans = new KMeans().setK(k).setSeed(1L)
val model = kmeans.fit(rescaledData)
// Evaluate clustering by computing Within Set Sum of Squared Errors.
println("calculating wssse ...")
val WSSSE = model.computeCost(rescaledData)
println(s"Within Set Sum of Squared Errors = $WSSSE")
5.3 评价方式
假设最终得到的文件和预测结果如下:
val t = List(
("121.txt",0),("122.txt",0),("123.txt",3),("124.txt",0),("125.txt",0),("126.txt",1),
("221.txt",3),("222.txt",4),("223.txt",3),("224.txt",3),("225.txt",3),("226.txt",1),
("421.txt",4),("422.txt",4),("4.txt",3),("41.txt",3),("43.txt",4),("426.txt",1)
文件名的第一个字符是否和聚类类别一致,统计结果来判断,是否聚类成功,最终得到整体的聚类准确率,这里提供demo例子如下:
package test_scala
import org.apache.spark.Partitioner
import utils.SparkUtils
/**
* Created by zcy on 18-1-4.
*/
object TestPartition {
def main(args: Array[String]): Unit ={
val t = List(
("121.txt",0),("122.txt",0),("123.txt",3),("124.txt",0),("125.txt",0),("126.txt",1),
("221.txt",3),("222.txt",4),("223.txt",3),("224.txt",3),("225.txt",3),("226.txt",1),
("421.txt",4),("422.txt",4),("4.txt",3),("41.txt",3),("43.txt",4),("426.txt",1)
) // 文档开头代表类别,后一个数字代表预测类型
val sc = SparkUtils.getSparkContext("test partitioner",true) //本地测试:true
val data = sc.parallelize(t)
val file_index = data.map(_._1.charAt(0)).distinct.zipWithIndex().collect().toMap
println("file_index: " + file_index) // key:begin of txt, value:index
val partitionData = data.partitionBy(MyPartitioner(file_index))
val tt = partitionData.mapPartitionsWithIndex((index: Int, it: Iterator[(String,Int)]) => it.toList.map(x => (index,x)).toIterator)
println("map partitions with index:")
tt.collect().foreach(println(_)) // like this: (0,(421.txt,4))
// firstCharInFileName , firstCharInFileName - predictType
val combined = partitionData.map(x =>( (x._1.charAt(0), Integer.parseInt(x._1.charAt(0)+"") - x._2),1) )
.mapPartitions{f => var aMap = Map[(Char,Int),Int]();
for(t <- f){
if (aMap.contains(t._1)){
aMap = aMap.updated(t._1,aMap.getOrElse(t._1,0)+1)
}else{
aMap = aMap + t
}
}
val aList = aMap.toList
val total= aList.map(_._2).sum
val total_right = aList.map(_._2).max
List((aList.head._1._1,total,total_right)).toIterator
// aMap.toIterator //打印各个partition的总结
}
val result = combined.collect()
println("results: ")
result.foreach(println(_)) // (4,6,3) 类别4,总共6个,3个正确
for(re <- result ){
println("文档"+re._1+"开头的 文档总数:"+ re._2+",分类正确的有:"+re._3+",分类正确率是:"+(re._3*100.0/re._2)+"%")
}
val averageRate = result.map(_._3).sum *100.0 / result.map(_._2).sum
println("平均正确率为:"+averageRate+"%")
sc.stop()
}
}
case class MyPartitioner(file_index:Map[Char,Long]) extends Partitioner{
override def getPartition(key: Any): Int = key match {
case _ => file_index.getOrElse(key.toString.charAt(0),0L).toInt //将value转换成int
}
override def numPartitions: Int = file_index.size
}
6 聚类结果
最终,在学长本地Spark伪集群环境下,用4个进程模拟4台主机,输出结果如下:
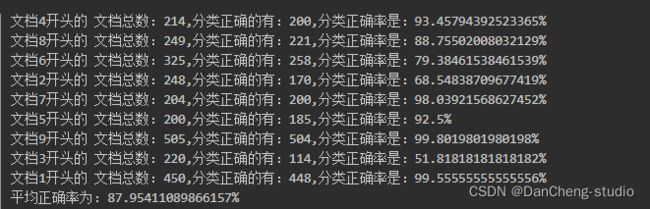
从整个运行结果来看,正确率还是很高的,值得信赖,但和参考大佬的论文比,某些类别还是不够准确,毕竟k-means算法有一定的随机性,这种误差我们还是可以接受的。并且从整体运行时间上来说,真的非常快(估计在十几秒),这个时间还包括了启动Spark,初始化等等过程,和python处理相比,不仅高效,还更加可靠。强推…