炼丹-深度学习-《Aggregated Residual Transformations for Deep Neural Networks》
Aggregated Residual Transformations for Deep Neural Networks
原文地址:Aggregated Residual Transformations for Deep Neural Networks
文章目录
- Aggregated Residual Transformations for Deep Neural Networks
-
- 生词:
- Abstract
- Introduction
- Related Work
-
- Multi-branch convolutional networks
- Group convolutions
- Compressing convolutional networks
- Ensembling
- Method
-
- Template
- Revisiting Simple Neurons
- Aggregated Transformations
-
- 相比较于Inception-ResNet
- 相比较于Grouped Convolutions
- Model Capacity
- Implementation details
- Experiments
-
- Experiments on ImageNet-1K
-
- Notations
- Cardinality vs. Width
- Increasing Cardinality vs. Deeper/Wider
- Residual connections
- Performance
- Comparisons with state-of-the-art results
- Experiments on ImageNet-5K
生词:
| 单词 | 释义 |
|---|---|
| topology | 拓扑 |
| aggregate | 聚合 |
| cardinality | 基数 |
| minimal | 最小的;极简主义 |
| compelling | 引人入胜的,难以抗拒的 |
| concrete | 具体的,有形的,钢筋混 |
| decomposition | 分解;腐烂 |
| harnesses | 挽具,马具,保护带 |
| recast | 重新安排,重新浇铸 |
| succinct | 简洁的 |
| proportional | 成比例的 |
Abstract
Resnext的网络结构聚合了一系列的block,这些block都是基于同样的拓扑结构的。按照这个思路,模型的机构是一个同质、多分枝的网络结构,并且只有很少的参数需要去设置。branch个数的作为一个新的维度,我们成为cardinality,中文基数。
实验表明,即使是在限制了复杂度的情况下,增加cardinality也可以增加分类的准确率。更确切的说,增加cardinality比加深或者加宽模型深度更加有效。
Introduction
计算机视觉的任务已经从"feature engineering"转向"network engineering"。初期的时候网络结构不会太深,所以特征的学习需要极少的人工干预,现在随着网络层数的增多,各类超参的数量爆炸式的增长,所以网络结构的设计变得越来越难。
我们都知道vgg通过堆叠简单的、具有相同尺寸的building-block来构建更深的网络,ResNet也继承了vgg的工作,采用相同的堆叠方式来构建模型,这一简单的规则带来一个问题:超参数选择的自由度减少了,并且深度变成了神经网络中的一个essential dimension。但是,作者认为这种简单的规则是可以降低超参数过度自适应数据集的风险的。
不同于vgg网络,Inception系列的模型已经证明了,经过精心设计的拓扑结构可以在很低复杂度的情况下依旧达到很好的效果。虽然Inception模型已经升级换代了好几次,但是最基本的策略依旧是:split-transform-merge。这个策略首先将input通过1x1的卷积映射到不同的低维embedding,最后通过一些3x3或者5x5的卷积核来改变形状,然后通过concatenation来merge。可以被证明这种结构的解空间是单独层(例如5x5的卷积核)在高维空间操作的解空间的子空间。这种做法当然是有弊端的,由于有过多复杂的参数,例如filter的个数,size等,对于每一种transformation都需要定做,虽然仔细的组合对于特定数据集能产生很好的效果,但是对于新的数据集却需要重新调整超参数。
在本文中,作者两种结构都用,既用了VGG/ResNets’中的简单堆叠,又探索了split-transform-merge策略的更加简单的使用方式。和Inception不通,每一个module里面的transformations不需要逐个精细的设计,而是统一采用一样的拓扑结构,这样的话就可以直接拓展到任何数量的transformations而不需要额外的特殊设计。具体见下图,右边就是文章中的一个module结构
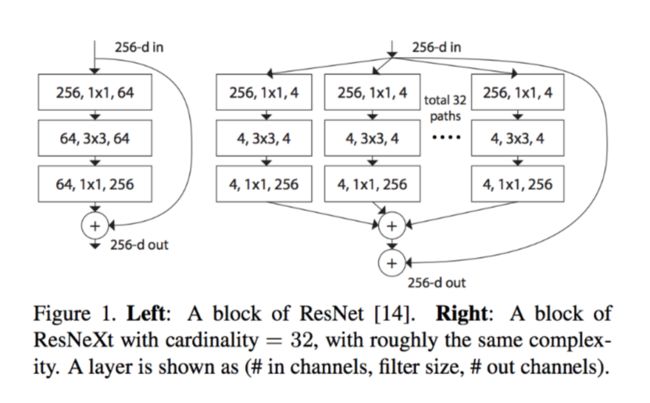
下面是作者提出的三种resnext block的等价形式:
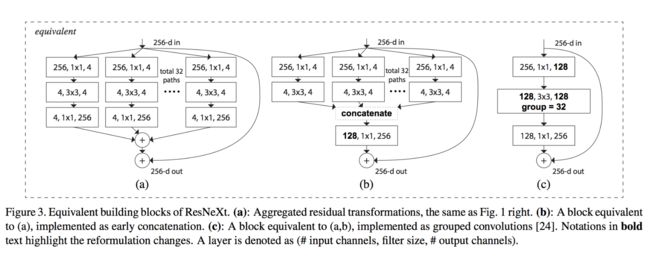
3(a)是最初始的形式,3(b)是resnet-inception的类似形式,对所有的transications进行concatenate后再进行卷积,和Inception不同的是所有的path都是一样的shape。3©是简要格式,中间层采用了组卷积。
作者通过实验证明,cardinality这个参数在提升准确率的性价比上高于增加模型的宽度和深度。
在成果上,resnext比resnet-101/152,ResNet-200,Inception-v3和Inception-ResNet-v2的表现都更加优异。实验中,一个101-layer的ResNeXt就比200层的ResNet效果好,并且复杂度只有其50%。作者用ResNeXt在ILSVRC 2016的图像分类任务上拿到了第二名。并在ImageNet-5K数据集上和COCO物体检测任务上拿到了比ResNet更好的成绩。
Related Work
Multi-branch convolutional networks
Inception系列的模型有很多成功的多分枝网络。ResNet也可以堪称一个简单的二分支网络,其中一个分支是identity mapping。Deep neural decision forests是一个树形的多分枝网络。
Group convolutions
最早的组卷积应该是AlexNet中提出的,但是这篇文章提出组卷积的目的在于把模型分布运行在两个GPU上。就目前而言,有很少的迹象表明组卷积有提升模型准确率的优点。一个比较特殊的例子就是channel-wise convolutions。
Compressing convolutional networks
Decomposition:在空间或者通道上对网络进行分解,是一个减少网络复杂度的有效手段。
Ensembling
将一系列独立的模型进行平均是用来提升准确率的有效手段,这种方式被广泛的应用于竞赛。我们的模型中虽然聚合了一堆transformations,但是不能称为ensemble,因为各个模块不是独立训练而是联合训练的。
Method
Template
网络是通过堆叠一系列的residual-block组成的。这些blocks有相同的拓扑结构,并且满足下面两个简单的原则:
- (i) 如果产生相同size的map,那么这些blocks的超参数相同,例如宽高度,卷积核个数。
- (ii) 每次spatial map以2为倍数下采样,blocks的宽度就增加一倍。这条规则是为了确保计算复杂度相同。这里的block的宽度指的是block-neck中,把原始输入做降维时卷积核的个数。
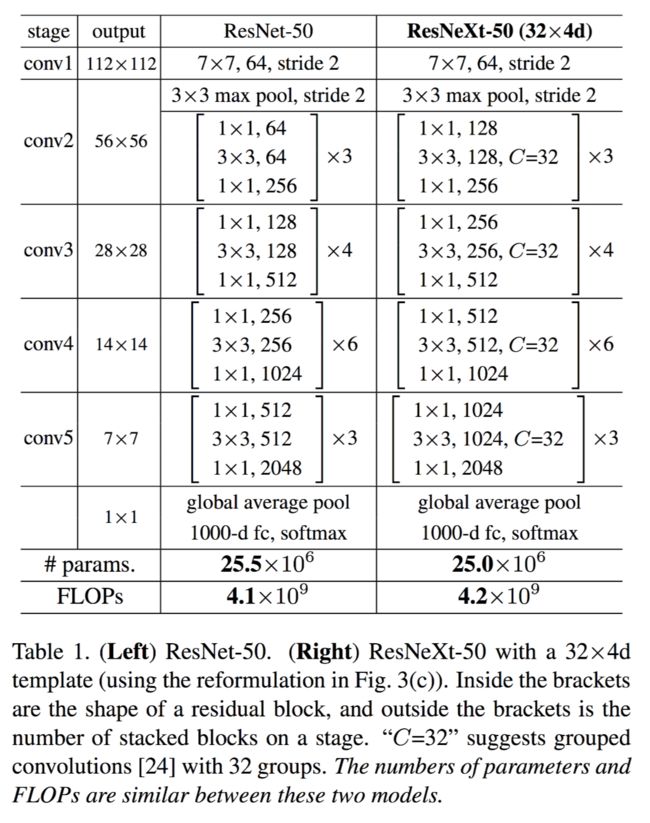
根据这两个原则,我们只需要设计一个template module,那么整个网络就可以被确定下来。这两个原则极大的缩小了网络的搜索空间,让设计网络的人只需要关注极少的几个变量,下面事物网络结构和resnet的对比图,两者的FLOPS基本相当。
Revisiting Simple Neurons
我们以最简单的线性神经元为例,这种split-transform-merge方法我们可以拆分成split,transforming和aggregating。
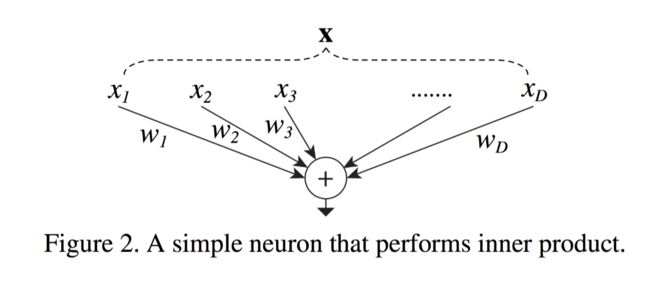
- split:就是把x拆分成一个个独立的xi
- transforming:把拆分后的低纬表示进行转换。在这里就是wixi。
- aggregating:把所有的transformations都aggregate,这里就是加和操作。
Aggregated Transformations
根据上述对于线性网络的分析,我们再来看wixi,假如我们把它看成一个更加抽象的方程,那么是不是就可以看成为Network-in-Neuron,这个说法是相当于Network-in-Network而言的,Network-in-Network主要指depth这个维度,而Network-in-Neuron主要是指cardinality这个维度。
把transformations看成一般式的话,那这个aggregated transformations就可以表达成如下的公式:
F ( x ) = ∑ i = 1 C T i ( x ) F(x)=\sum_{i=1}^{C}T_{i}(x) F(x)=i=1∑CTi(x)
其中 T i ( x ) T_i(x) Ti(x)可以看成是任意的方程,其目的是把x映射到一个相对低维的空间并做转换,也就是split和transformations。
其中C代表transformations的个数,也就是上文中的cardinality。等价于在linear function中的D。
在本文中,从cardinality角度出发,所有的 T i T_i Ti都设计为相同的拓扑结构,从depth角度出发,和VGG一样,网络通过简单堆叠在增加网络的深度。这个策略的好处就是既减少了超参的个数,也拓展到可以设计任意数量的transformations。在本文中,所有的 T i T_i Ti采用了bottle-neck的结构。
在上述公式的基础上,如果加入残差操作,那么式子就会变成如下的形式:
y = x + ∑ i = 1 C T i ( x ) y=x+\sum_{i=1}^{C}T_i(x) y=x+i=1∑CTi(x)
除了最初的式子,还有两种等价的形式见下图:
相比较于Inception-ResNet
(a)中的操作可以等价于(b),b中采用了early concatenation策略,这和Inception-ResNet的策略是一致的,和Inception-ResNet不同的是,所有的transformation都是相同的拓扑结构。
其实假如没有激活函数的话,(a)和(b)是等价的,但是引入激活函数之后会不一样点。文中的证明是考虑了卷积核不带非线性激活的,带非线性激活会有些不太一样,可以自己证明一下:
相比较于Grouped Convolutions
采用了grouped convolutions后,整个block会更加简洁,如©所示。在原来的形式(a)下,256通道的输入分别被32组4个的卷积核映射到了32组4通道的low-dimensional embeddings,在©中,直接替换成了一个单独的1x1x128的卷积核。其实两者是等价的,可以这样考虑:对于每一个输出通道上的单个值,计作 y d , i , j = y_{d,i,j}= yd,i,j=,表示在输出在d通道上,i行j列的值,在(b)的形式下:
y d , i , j = σ ( ∑ c = 1 256 x c , i , j ∗ w m ) y_{d,i,j}=\sigma(\sum_{c=1}^{256}x_{c,i,j}*w_{m}) yd,i,j=σ(c=1∑256xc,i,j∗wm)
可以看出输出通道的每个值的计算是与其他的输出完全无关的,所以把(b)中的32组卷积核堆叠起来,就等价于一个单一的1x1x128的卷积核,计算方式完全没有差别。
第二部组卷积相当于输入channel为4,输出channel也为4,所以和(a),(b)中的第二步也无异,主要看第三步,组卷积的结果类似于(b)中的堆叠,所以(b)和©是等价的,上一节讨论时说到(a)和(b)只有在线性组合的情况下是等价的,所以(b)和©是等价的,(a)和©在线性情况下等价。
Model Capacity
这篇文章的实验证明了,在相同的模型复杂度和参数数量下,resNeXt的准确率提升最大。这不仅在生产实践中有用,同时,模型复杂度和参数数量代表着模型的容量,所以被认为时深度网络的基本属性。
为了在保证模型复杂度的情况下,评估不同的cardinality,也就是基数这个超参数对模型性能的影响,我们需要修改其他超参数以保证模型的复杂度。为了简化以及最小化模型修改的工作量,文章选择了bottle-neck结构中,bottle的宽度来作为保持模型复杂度不变的控制参数,bottle的宽度在上面的图的例子的就是4,也就是input在映射到低维空间时的channel数量。这种修改策略对网络的修改非常小,可以让实验专注于cardinality对网络性能的影响。
根据上面这张图我们分别来计算一下resNet的block和resNeXt的block的复杂度:
(1) resNet:
256 ∗ 64 + 64 ∗ 3 ∗ 3 ∗ 64 + 64 ∗ 256 = 70 k 256*64+64*3*3*64+64*256 = 70k 256∗64+64∗3∗3∗64+64∗256=70k
(2) resNeXr
C ∗ ( 256 ∗ d + d ∗ 3 ∗ 3 ∗ d + d ∗ 256 ) = 512 ∗ C ∗ d + 9 ∗ C ∗ d 2 C*(256*d+d*3*3*d+d*256) = 512*C*d + 9*C*d^2 C∗(256∗d+d∗3∗3∗d+d∗256)=512∗C∗d+9∗C∗d2
Implementation details
Experiments
Experiments on ImageNet-1K
作者在1000-class的ImageNet数据集上做了消融学习实验,主要基于两个网络结构:50-layer和101-layer的残差网络,resNeXt的实验是简单的把里面的block换成文章提出的block。
上面的表格结构展示了ResNet-50和ResNeXt-50的区别。
Notations
回顾一下上文提到的两个原则:
- (i) 如果产生相同size的map,那么这些blocks的超参数相同,例如宽高度,卷积核个数。
- (ii) 每次spatial map以2为倍数下采样,blocks的宽度就增加一倍。这条规则是为了确保计算复杂度相同。这里的block的宽度指的是block-neck中,把原始输入做降维时卷积核的个数。
在conv2中,由于cardinality=32,block-neck的wdith=4,所以这个网络称为ResNeXt-50(32x4d),实际上,随着网络的深度加深,在下采样的过程中,由于feature map的宽度和高度在成倍的减少,为了保证复杂度和原来的resNet一致,在cardinality不变的情况下,每次feature map的宽度、高度减半,block-neck的宽度就加倍(也就是在做第一步的1x1卷积时,卷积核的个数翻倍,例如在conv2是1x1x4的卷积核,在conv3中就是1x1x8的卷积核)。
Cardinality vs. Width
作者在保持模型复杂度的情况下,比较了不同cardinality和bottleneck宽度的实验结果,其中cardinality和bottleneck宽度的设置如下:
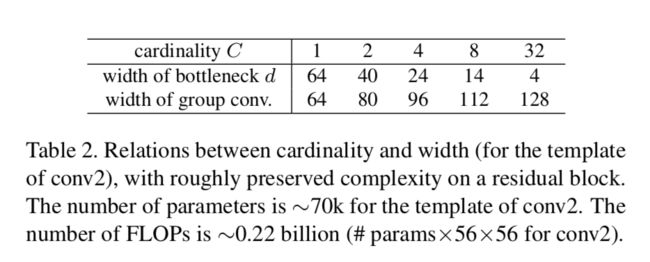
之所以是这样的设置没可以根据前面的复杂度计算公式而来:
(1) resNet:
256 ∗ 64 + 64 ∗ 3 ∗ 3 ∗ 64 + 64 ∗ 256 = 70 k 256*64+64*3*3*64+64*256 = 70k 256∗64+64∗3∗3∗64+64∗256=70k
(2) resNeXr
C ∗ ( 256 ∗ d + d ∗ 3 ∗ 3 ∗ d + d ∗ 256 ) = 512 ∗ C ∗ d + 9 ∗ C ∗ d 2 C*(256*d+d*3*3*d+d*256) = 512*C*d + 9*C*d^2 C∗(256∗d+d∗3∗3∗d+d∗256)=512∗C∗d+9∗C∗d2
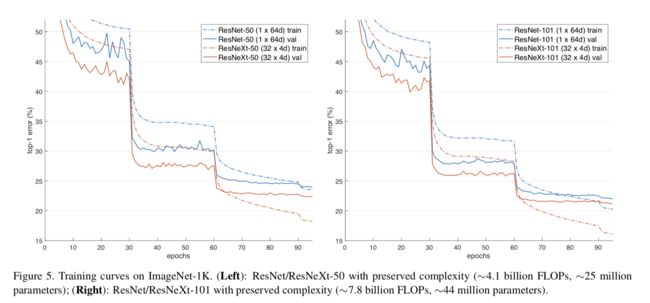
下面的表格和曲线分别代表了实验的结果和训练中epochs vs error曲线。从表中可以看出,随着cardinality增加,在复杂度不变的情况下,模型的错误率一直下降到了22.2%。从左边一张曲线可以看出,模型不仅仅在最终的测试结果上有良好的性能,在训练集和验证集上也表现的比baseline的resNet好,说明resNeXt比resNet有更好的特征抽取能力,这个收益不是来自正则化的。
从右边的曲线可以看出,在101-layer的实验上,虽然验证集的收益是低于50-layer的实验的,101-layer的实验加上32c,4d后只减少了0.8%的错误率而50-layer的实验加上后减少了1.7%的错误率,但是在训练集的增益上确实相当的。

Increasing Cardinality vs. Deeper/Wider
在这一部分,作者主要是想比较哪种增加模型复杂度的方式,对模型性能的提升最有帮助。简单来说就是,通过一些操作,使得101-layer baseline的resNet的FLOPs变成原来的两边,这些操作包括
- (i) 增加模型深度,变成resNet-200
- (ii) 增加bottleneck的宽度
- (iii) 翻倍cardinality
下面的表格展示了上面实验的结果:
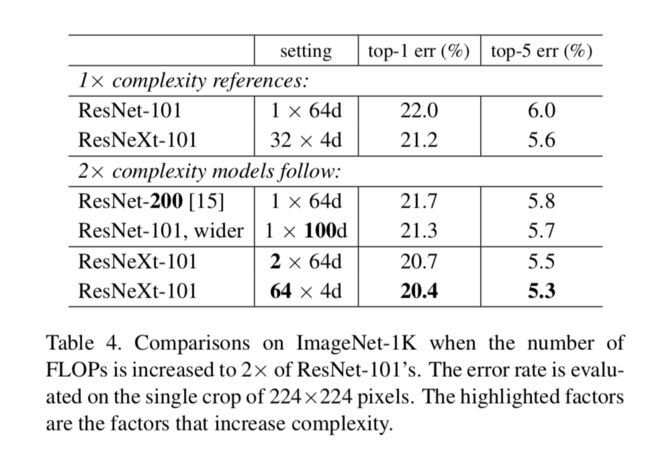
从上面表格中,很明显可以看出来这几点:
- 增加深度的收益和增加bottleneck宽度的收益只有0.3%和0.7%。而翻倍1x64d的cardinality和翻倍32x4d的cardinality的收益却分别有1.3%和1.6%。
- 同时,resNeXt-101 32x4d网络在只有ResNet-200和ResNet-101,wider两个网络一半复杂度的情况下,依然能比他们的性能好,这部分实验充分说明了cardinality这个参数的优越性。
Residual connections
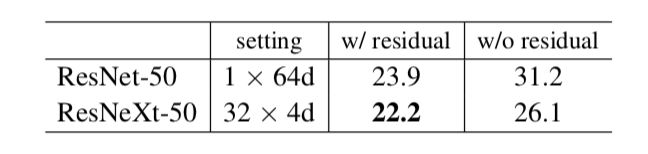
上面表格展示的是用到残差结构和不用到残差结构的实验结果对比,很明显用残差会好非常多。
Performance
虽然在理论计算上,计算的复杂度resNet和ResNeXt是相等的,但是实际用torch实现时,一个batch的ResNet-50是0.95s,一个batch的ResNeXt时0.7s。这个误差可能是由于过于高级和暴力的torch实现接口导致的,可能底层的编程会更加有效率。
Comparisons with state-of-the-art results
在测试集single-crop下的结果如下表:
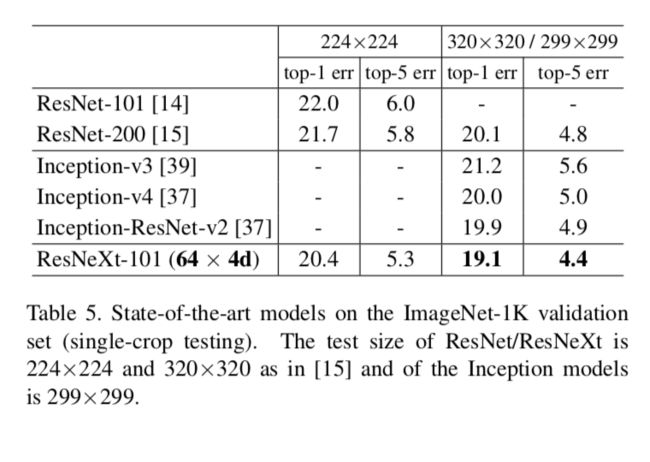
在单个模型下,如果用到了multi-scale和multi-crop的testing设置,可以达到3.03%的top5error。是2016ILSVRC比赛的第二名。
Experiments on ImageNet-5K
从1K的实验来看,结果已经趋于饱和了,作者认为这并不是因为网络的容量达到了饱和,而是因为模型的复杂度达到了饱和,所以作者在ImageNet-5K上再做了一个实验来评估。
作者的实验设置是这样的:模型是在5K的数据集上训练的,训练了一个5K分类的模型,然后评估只在1K的验证集上进行,评估的方式分为两种:
- 直接作为一个5k分类问题,分到非验证集1k类的类别就视为错误。
- 在softmax只在其中1k类上进行。
下面的曲线和表格是实验的结果
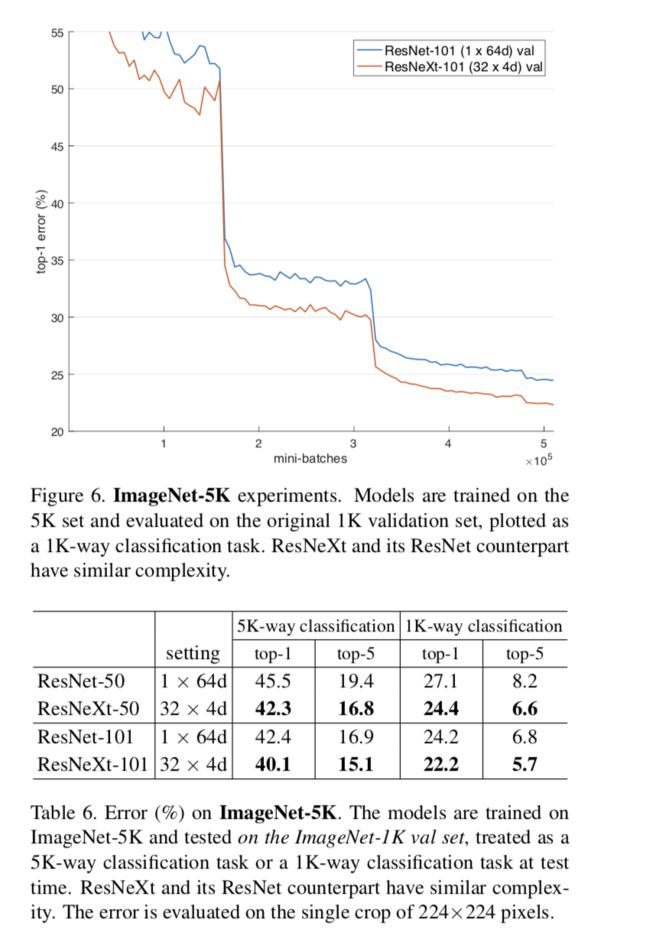
发现模型在训练5k任务的时候,虽然在1k的评估上有所下降,但下降不多,说明模型的表示能力很强。