PyTorch之实现LeNet-5卷积神经网络对mnist手写数字图片进行分类
论文:Gradient-based learning applied to document recognition
-
简单介绍
意义: 对手写数据集进行识别,对后续卷积网络的发展起到了奠基作用
特点:
1)局部感受野(local receptive fields): 基于图像局部相关的原理,保留了图像局部结构,同时减少了网络的权值。
2)权值共享(shared weights): 也是基于图像局部相关的原理,同时减少网络的权值参数。
3)下采样(sub-sampling):对平移和形变更加鲁棒,实现特征的不变性,同时起到了一定的降维的作用。
LeNet-5: 这里的5表示卷积层+全连接层一共为5层 -
网络结构
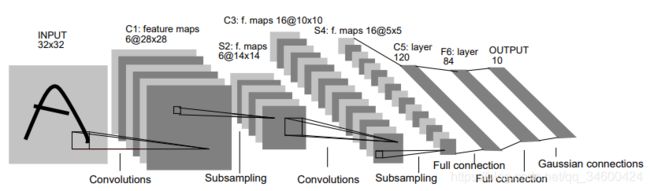
-
代码
1)导入相应的包
import torch
import torch.nn as nn
import torch.utils.data as Data
import torchvision
import os
2)定义超参数
EPOCH = 1
BATCH_SIZE = 10
LR = 0.001
DOWNLOAD_MNIST = False
3)加载数据集,这里使用pytorch中自带的mnist数据集
if not(os.path.exists('./mnist/')) or not os.listdir('./mnist/'):
DOWNLOAD_MNIST = True # 如果没有数据集则进行下载
train_data = torchvision.datasets.MNIST(
root='./mnist/',
train=True, # training data
transform=torchvision.transforms.ToTensor(),
# Converts a PIL.Image or numpy.ndarray to torch.FloatTensor of shape (C x H x W) and normalize in the range [0.0, 1.0]
download=DOWNLOAD_MNIST,
)
train_loader = Data.DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True)
test_data = torchvision.datasets.MNIST(root='./mnist/', train=False, transform=torchvision.transforms.ToTensor()) # 测试数据集
test_loader = Data.DataLoader(dataset=test_data, batch_size=BATCH_SIZE, shuffle=True)
4)定义网络
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__() # 上述是自定义网络的常规写法
self.conv1 = nn.Sequential(
nn.Conv2d(1, 6, 5), # 输入通道,输出通道,卷积核大小
nn.ReLU(),
nn.MaxPool2d(2),
)
self.conv2 = nn.Sequential(
nn.Conv2d(6, 16, 5),
nn.ReLU(),
nn.MaxPool2d(2),
)
self.fc1 = nn.Sequential(
nn.Linear(256, 120), # 输入特征,输出特征
nn.ReLU(),
)
self.fc2 = nn.Sequential(
nn.Linear(120, 84),
nn.ReLU(),
)
self.fc3 = nn.Sequential(
nn.Linear(84, 10),
nn.ReLU(),
)
def forward(self, x):
x1 = self.conv1(x)
x2 = self.conv2(x1)
x2 = x2.view(x.size(0), -1) # 展开成一维向量,方便后面进行全连接
x3 = self.fc1(x2)
x4 = self.fc2(x3)
x5 = self.fc3(x4)
return x5
net = Net()
print(net)

首先输入图像是单通道的28 x 28大小的图像,用矩阵表示就是[Batch,28,28]
第一个卷积层conv1所用的卷积核尺寸为55,滑动步长为1,卷积核数目为6,那么经过该层后图像尺寸变为24,28-5+1=24,输出矩阵为[6,24,24]。
第一个池化层pool核尺寸为22,步长2,这是没有重叠的max pooling,池化操作后,图像尺寸减半,变为12×12,输出矩阵为[6,12,12]。
第二个卷积层conv2的卷积核尺寸为55,步长1,卷积核数目为16,卷积后图像尺寸变为8,这是因为12-5+1=8,输出矩阵为[16,8,8].
第二个池化层pool2核尺寸为22,步长2,这是没有重叠的max pooling,池化操作后,图像尺寸减半,变为4×4,输出矩阵为[16,4,4]。
pool2后面接全连接层fc1,神经元数目为120,再接relu激活函数。
fc1后面接全连接层fc2,神经元数目为84,再接relu激活函数。
再接fc3,神经元个数为10,得到10维的特征向量,用于10个数字的分类训练,送入softmax分类,得到分类结果的概率output。
5)开始训练
loss_func = nn.CrossEntropyLoss() # 损失函数
optimizer = torch.optim.Adam(net.parameters(),lr = LR) # 梯度下降
cuda_gpu = torch.cuda.is_available() # have gpu
for epoch in range(EPOCH):
net.train()
for batch_idx, (data, target) in enumerate(train_loader):
if cuda_gpu:
data, target = data.cuda(), target.cuda()
net.cuda()
output = net(data) # 网络输出结果
loss = loss_func(output, target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (batch_idx+1) % 400 == 0:
#--------------------------test-------------------------
net.eval()
correct = 0
for data, target in test_loader:
if cuda_gpu:
data, target = data.cuda(), target.cuda()
net.cuda()
output = net(data)
pred = output.data.max(1)[1] # get the index of the max log-probability
correct += pred.eq(target.data).cpu().sum()
accuracy = 1. * correct / len(test_loader.dataset)
print('Epoch: ', epoch, '| train loss: %.4f' % loss.data.numpy(), '| test accuracy: %.2f' % accuracy)
完整的代码可参考:LeNet-5