文本对比学习综述
我是目录
- 摘要
- CERT,2020
- CLEAR,2020
- DeCLUTR,2021 ACL
- ConSERT:ACL 2021
- Self-Guided Contrastive Learning for BERT Sentence Representations, ACL 2021
- SimCSE:EMNLP2021
- Pairwise Supervised Contrastive Learning of Sentence Representations,EMNLP 2021
- ESimCSE, arxiv2021
- DiffCSE,NAACL2021
- PromptBERT,arxiv2022
- SNCSE,arxiv2022
摘要
对比学习(Contrastive Learning)的思想最开始产生于CV领域,其主要的思路是,给定一个样本,对其进行数据增强,将增强的结果视为正例;然后,其他所有的样本视为负例。通过拉近正样本、拉远负样本之间的距离,对比学习能够在无监督(自监督)情境下学习更稳定的样本表征,并方便于下游任务的迁移。
对比学习的经典方法包括Moco以及SimCLR,大概代表了对比学习的两种不同的思路。Moco主要在内存中维护一个全局的队列(memory bank)以存储所有样本的当前表示,当一个mini-batch的样本进行学习时,只需将最上层的相应batch size的数据出队,即可进行相应的样本匹配,并采用Momentum Contrast技术对队列中的样本进行更新。
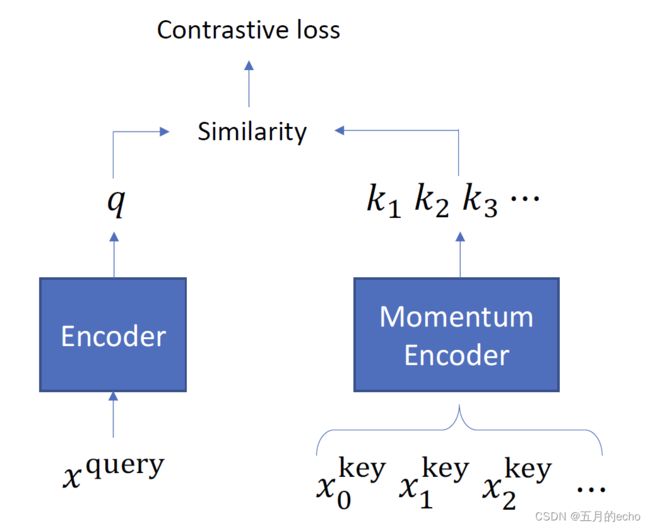
而SimCLR则是将同一个mini-batch中的所有其他样本视为负例,然后进行对比。因此,尽管SimCLR简单易行,但是为了提升模型对负样本的普适性,一般都需要一个非常大的batch(4096这种级别的),因此咱们平头百姓是有点玩不起的。后续文本表示中的对比学习也是基于这两个分支来阐述的,因此先进行个预热(详细CV对比学习综述请移步李沫老师的视频)。
而文本上的对比学习似乎一直存在着局限性,因为相比于图片的翻转、平移之类的增强,文本的增强似乎更加费力。因此,狭义(承袭Moco或是SimCLR这种CV的对比学习方法)的文本对比学习工作并不是很多。因此,本文旨在为NLP中的对比学习给出一个简要的总结。
CERT,2020
Code:【https://github.com/UCSD-AI4H/CERT】

本文是我找到的比较早的语言模型对比学习的文章之一,不过现在似乎还挂在arxiv上(我不理解)。本文给出了对比学习在NLP中的一个非常明确的优势描述:预训练语言模型的重点是放在token级别的任务上,因此对相应的句子级别的表征没有一个良好的学习。因此,本文采用了Moco的框架进行句子级别的对比学习,而增强的技术则采用了最常用的回译(back translation)。其执行流程也很好理解:
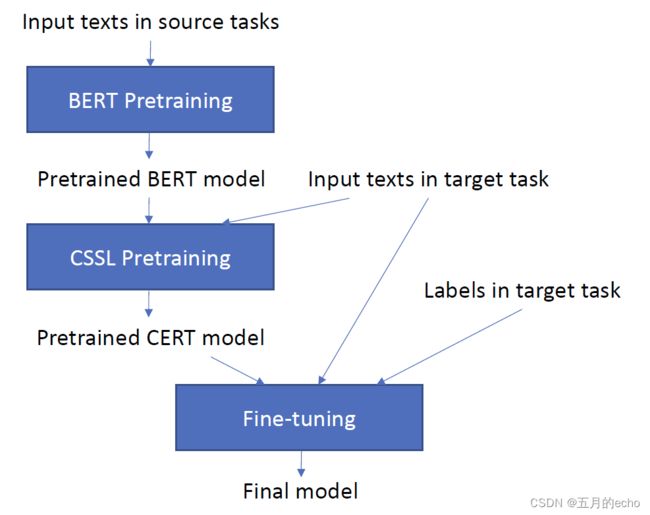
首先,在源域进行预训练,并在目标域文本上进行CSSL(对比自监督学习)的优化,此步骤得到的结果被称为CERT。之后,对带有标签的目标域任务执行微调,得到最终调优的模型。
CLEAR,2020

同样,本文依旧将目光放在句子级别的任务上,但是和CERT稍微不同的是,采用了SimCLR的框架来执行对比学习,并探讨了不同的数据增广策略,包括:random-words-deletion, spans-deletion, synonym-substitution, and reordering。并且,模型的流程也稍有不同,CLEAR将MLM以及CL进行联合训练,对上游的语言模型进行预训练,然后再在下游任务做微调。模型的主要架构如下:

s 1 ~ \tilde{s_1} s1~, s 2 ~ \tilde{s_2} s2~分别表示相同的增广策略对同一个样本产生的两个不同的增广样本,然后它们分别喂给同一个BERT,并得到两种不同的表示。因此对于一个batch size为 N N N的输入,最终产生 2 N 2N 2N个样本。之后, g ( ) g() g()就是完全参考SimCLR了,因为SimCLR原文中增加一个a nonlinear projection head可以提升性能(说不出理由,就是实验结果会提升),因此本文也效仿,在输出之后增加了相应的投影。损失函数是对比学习常用的损失:

CL整体对比学习损失定义为小批量中所有正对损失的总和:

那最终语言模型的优化目标为:

具体的实验细节以及结果就不展开说啦。
DeCLUTR,2021 ACL
Code:【https://github.com/JohnGiorgi/DeCLUTR】

后续的工作就都是采用SimCLR的框架执行了,而不同之处主要在于采样的方式。DeCLUTR则是从样本中根据beta分布采样一段长度不固定的子句,然后以这个子句作为增强之后的范例:

同样的,总体的损失是对比的损失以及MLM的损失的和:

ConSERT:ACL 2021
Code:【https://github.com/yym6472/ConSERT】

总体来说,与以往和后续的工作没有多大差别,提出了基于BERT的对比学习框架如下:
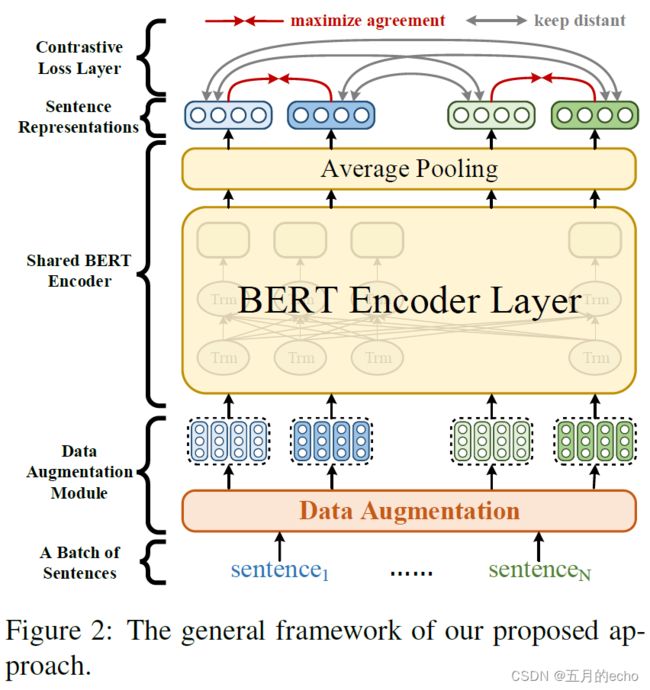
本文探究了四种不同的数据增强方法:

- Adversarial Attack。使用快速梯度值(FGV) 来实现这一策略,它直接使用梯度来计算扰动。
- Token Shuffling。通过将变换后的位置id传递给嵌入层,同时保持令牌id的顺序不变。
- Cutoff。通过随机删除一些tokens或是feature的维度来实现。
- Dropout。按照特定的概率在tokens的嵌入层中随机删除元素,并将它们的值设为零。
本文也对上述不同的增广策略的组合效果进行了探究:

Self-Guided Contrastive Learning for BERT Sentence Representations, ACL 2021

本文采取了一个非常有趣的增强策略,即保证BERT不同layer学习到的表征的一致性。因为作者认为,数据增强难免会产生噪声,因此很难保证增强之后的结果与原样本的语义一致性。模型的框架如下:

首先,对于BERT,产生两个copies,一个是固定参数,被称为 B E R T F BERT_F BERTF;另一个根据下游任务进行微调,被称为 B E R T T BERT_T BERTT。第二,同样给定一个mini-batch中的 b b b个句子,利用 B E R T F BERT_F BERTF计算token-level的表示 H i , k ∈ R l e n ( s i ) × d H_{i,k}\in \mathcal{R}^{len(s_i)×d} Hi,k∈Rlen(si)×d如下:

之后,句子级别的表示 h i , k h_{i,k} hi,k则使用一个简单的最大池化得到。其中, k ∈ [ 1 , l ] k\in [1,l] k∈[1,l], l l l为BERT的层数。然后,应用一个层级别的采样函数 σ \sigma σ,得到正例的最终表征:
![]()
第三,经过 B E R T T BERT_T BERTT得到的句子的表征 c i c_i ci如下:
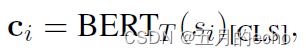
这样,增强之后的样本构成的集合 X X X则已经确定:
![]()
接下来就是常用的对比损失了NT-Xent loss:

具体的符号的含义就不多解释了,就是拉近正样本,拉远负样本之间的距离,很好理解:

然后,理论上来说,尽管 B E R T T BERT_T BERTT做了微调,但是还是需要尽量保证和 B E R T F BERT_F BERTF的距离不是很远,因此又添加了一个正则化:
![]()
最终的损失则是联合的损失函数:

SimCSE:EMNLP2021
Code:【https://github.com/princeton-nlp/SimCSE】

本文提出的方法相当优雅,引入了dropout方法对样本进行增强。将相同的句子传递给预先训练的编码器两次:通过两次应用标准dropout,可以得到两个不同的嵌入作为正对。然后,在无监督和有监督(natural language inference,NLI)两个不同类型的增强任务中探究了相应的性能。

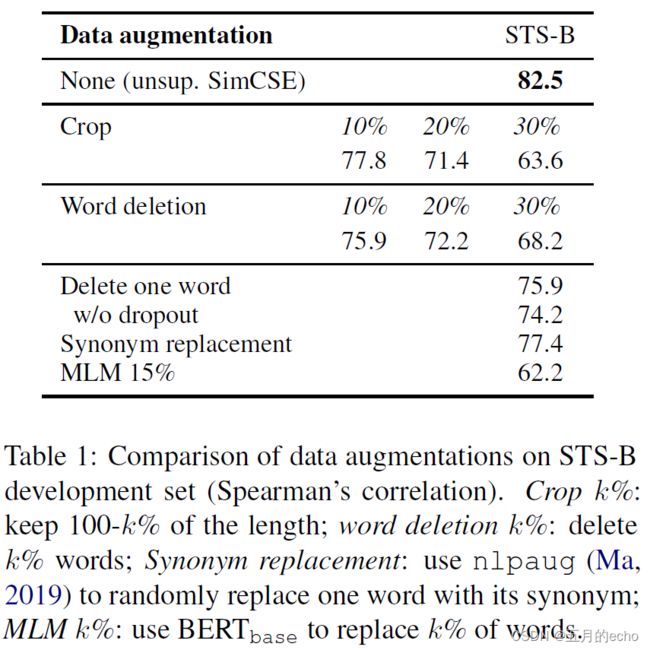
这里NLI之所以是有监督的,主要还是因为NLI本身就是一个匹配文本对的任务,所以本身一个就是一对文本的比较,匹配则是正例,不匹配则是负例。本文提出的dropout方法要比一些常见的增强方法,比如裁剪、删除、同义词替换效果更出色:
Pairwise Supervised Contrastive Learning of Sentence Representations,EMNLP 2021
ESimCSE, arxiv2021
SimCSE中的每个正对实际上都包含相同的长度信息,毕竟是通过一个输入dropout而来的。因此,用这些正对训练的unsup-SimCSE可能有偏倚,它会倾向于认为相同或相似长度的句子在语义上更相似。通过统计观察,本文发现确实存在这样的问题。为了缓解这一问题,我们对输入的句子进行简单的重复操作,对输入的句子进行修改,然后将修改后的句子分别传递给经过训练的Transformer编码器,之后进行的训练过程都差不多啦。

ESimCSE对批处理执行单词重复操作,因此正对的长度可以在不改变句子语义的情况下变化。当预测正对时,这种机制削弱了模型的相同长度提示。此外,ESimCSE还在一个称为动量对比(momentum contrast)的队列中维护了之前的几个小批量模型输出,这可以扩大损失计算中涉及的负对(这里仿照的是MOCO)。这种机制允许在对比学习中对配对进行更充分的比较。
DiffCSE,NAACL2021

Code:【https://github.com/voidism/DiffCSE】
本文的工作建立于SimCSE的基础上,增加了一个difference prediction的额外预测目标:

difference prediction主要用于判别一个被maks的句子中的token是否是被mask过的。首先,给定长度为 T T T的输入 x x x,利用随机mask获取到包含[MASK]的版本 x ′ x' x′,之后利用另一个pretrained的MLM作为Generator,对被mask的token进行还原,这时候的句子被表示为 x ′ ′ x'' x′′。之后,借助 D D D来判别一个token是否被替换:
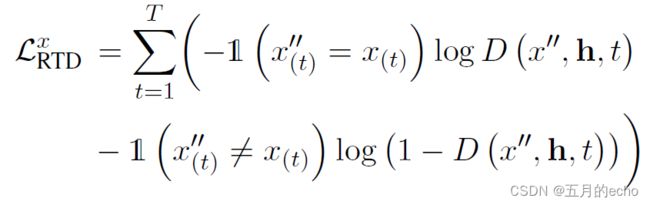
其实,该工作本质上还是对token级别的预训练任务与句子级别的预训练任务的合理结合。
PromptBERT,arxiv2022

本文给出了基于提示学习的增强方法用于对比学习。其实主要的思路也很简单。给定一个输入样本 x i x_i xi,利用Prompt方法计算得到其相应的句子嵌入作为样本的增强表示。然后,利用对比通用的对比学习框架,训练BERT模型,得到了比SimCSE好2%以上的结果。
具体来说,构建的Prompt形式如下:[X] means [MASK]。其中[X]表示原句子,[MASK]则用于表示最终学习到的句子嵌入。句子的表示不再使用token表示的加权平均,这样避免了BERT学习中产生的bias问题。
关于为什么使用token的平均表示会产生bias,在本文的一开始就进行了大段的论述。不过总的来说,就是token级别的信息会包含词频、大小写、subword等不同的偏差,因此导致基于句子中全部token的平均表示产生的向量也包含了这些偏差。并且,作者也通过实验否认了之前的一些研究的结果:BERT效果的不好是因为学习到了anisotropic的表征(这个词就是说,不同的句子嵌入之间的相似度过高,导致其区分度下降)。这里的实验设置得也蛮美观的,如果有需要可以自行阅读一下原文,我在这里就不赘述了。
而本文另一个小的创新在于,由于prompt模板内部也不可避免地包含一些token,比如下面的例子:

“is”,"means"这种词每一个模板中都会出现,因此属于高频。而作者在最开始又论述了高频token会引入bias,因此提出了一种简单的去噪方法去解决这个问题。前文提到带有模板的句子表示为 h i h_i hi,作者把模板单独扔进BERT,并且保证与之前的template popsition ids相同,也就是把[X]原句子去除,然后保证模板的position的信息不对最终结果产生影响,这样得到的表征就都是模板本身的了。这个模板的表征用 h ^ i \hat{h}_i h^i表示,就是模板自身带有的噪声了。那么,去噪的句子表征就是一个减法计算: h i − h ^ i h_i-\hat{h}_i hi−h^i。最终,对比学习的损失为:

最后上个实验结果吧:

另外,推荐李rumor小姐姐的知乎以及公众号。
SNCSE,arxiv2022

Code:【https://github.com/Sense-GVT/SNCSE】
本文指出,由于现有的对比学习中的正例都从一个样本派生,因此模型不能区分和解耦文本相似度和语义相似度。这种现象被称为feature suppression。比如:Tom and Jerry are good friends,以及Tom and Jerry are not good friends。他们在文本上具有高度的相似性,但是其语义相似度却截然相反。因此,本文给出了一种Soft negative的派生方法,用于解决feature suppression。
具体来说,Soft negative通过句法依赖的解析,找到核心谓词,在之前添加not来更改句子的语义倾向。比如下面的例子:

之后,在得到正例、负例以及soft negative之后,对传统的正负例使用以InfoNCE loss为损失的对比学习策略。参照之前的工作,本文使用了PromptBERT中的模板方法以获取句子的表征:
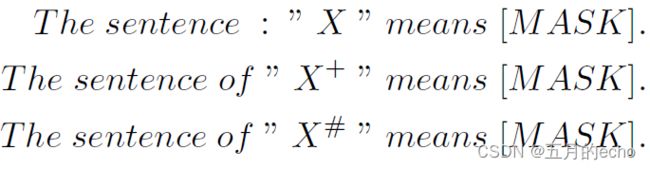
此外,利用样本与soft负例、样本与正例之间的的余弦相似度的差值 Δ \Delta Δ,作为衡量学习到的语义差异的判别方法:

也即是说,样本 h i h_i hi的表示与 h i # h_i^\# hi#的表示之间的相似度,与样本 h i h_i hi的表示与 h i + h_i^+ hi+的表示之间的相似度的差值要尽可能地大,为了区分其语义上的差别。然后,提出双向边际损失(BML)来模拟语义相似度差异:

总体的损失依然是联合损失:

本文最后也做了详细的case study来说明这种方法对语义、本文相似度的区分。