2020 Front. Pharmacol | Molecular Sets (MOSES): A Benchmarking Platform for Molecular Generation Mod

本文由香港英矽科医药有限公司、哈佛大学、瑞士阿斯利康、俄罗斯国立研究大学、多伦多大学、多伦多人工智能矢量研究所等发表在Front. Pharmacol., 18 December 2020
Paper:https://arxiv.org/abs/1811.12823
Code: https://github.com/molecularsets/moses
2020 Front. Pharmacol | Molecular Sets (MOSES): A Benchmarking Platform for Molecular Generation Models
摘要
生成模型正在成为探索分子空间的首选工具。这些模型在大型训练数据集上学习,并产生具有相似特性的新型分子结构。生成的结构可用于虚拟筛选或在下游任务中训练半监督预测模型。虽然有很多生成模型,但尚不清楚如何对它们进行比较和排名。在这项工作中,引入了一个名为 Molecular Sets (MOSES) 的基准测试平台来标准化分子生成模型的训练和比较。MOSES 提供训练和测试数据集,以及一组指标来评估生成结构的质量和多样性。并比较了几种分子生成模型,并建议将结果作为参考点,以进一步推动生成化学研究。
介绍
在这项工作中,分子生成提供了一个基准套件——分子集 (MOSES):标准化数据集、数据预处理实用程序、评估指标和分子生成模型。能够为当前和未来的生成模型提供清晰统一的测试平台。如下图1所示:
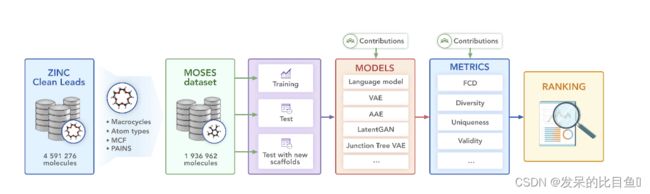
图1:分子集合(MOSES)管道。开源库提供了数据集、基线模型和评估指标
分布学习
分布学习模型。给定一组训练样本 X t r = { x 1 t r , x 2 t r , . . . , x N t r } X_{tr}=\{x_1^{tr}, x_2^{tr}, ...,x_N^{tr}\} Xtr={x1tr,x2tr,...,xNtr}来自一个未知的分布 p ( x ) p(x) p(x),分布学习模型近似 p ( x ) p(x) p(x)与一些分布 q ( x ) q(x) q(x)。
分布学习模型的质量是 p ( x ) p(x) p(x)和 q ( x ) q(x) q(x)之间的偏差度量。该模型可以隐式或显式定义一个概率质量函数 q ( x ) q(x) q(x)。比如隐马尔可夫模型、N元语言模型或规范化流等显式模型可以解析计算 q ( x ) q(x) q(x)并从中采样。隐式模型,如变分自编码器、对抗性自编码器或生成式对抗网络可以从 q ( x ) q(x) q(x)中采样,但不能计算概率质量函数的确切值。为了比较模型,本文评价指标仅依赖于q(x)的样本。
分子表示
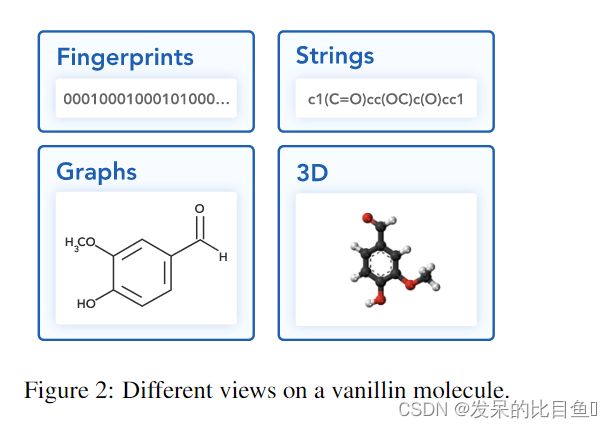
图2. 对香兰素分子的不同表示
- 字符串表示:将分子结构表示为字符串。SMILES 算法以深度优先顺序遍历分子图的生成树,并存储原子和边标记。
- DeepSMILES:作为 SMILES 的扩展被引入,通过改变分支和闭环的语法来减少无效序列。
- 分子图: 在分子图中,每个节点对应一个原子,每条边对应一个键。这样的图可以显式或隐式指定氢。
指标
- 有效 (Valid) 和唯一 (Unique@k): 生成SMILES 字符串的有效性和唯一性。使用 RDKit 的分子结构解析器来定义有效性,该解析器检查原子的化合价和芳环中键的一致性。
- 新颖性:生成的分子中不存在于训练集中的部分。低新颖性表明过度拟合。
- 过滤器: 虽然生成的分子通常在化学上是有效的,但它们可能包含不需要的片段:在构建训练数据集时,我们删除了带有此类片段的分子,并期望模型避免产生它们。
- 片段相似度 (Frag): 表示cf(A)子结构f在集合A的分子中出现的次数,以及一组出现在G或R中的片段为f,度量被定义为余弦相似度:
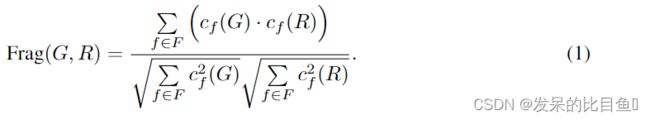
- 支架相似度 (Scaff):用该算法的 RDKit 实现,该算法另外将连接到环上的羰基视为支架的一部分。表示cs(A)从集合A中分子中出现支架s的次数,以及一组出现在G或R中的片段的次数为s,度量被定义为余弦相似度:
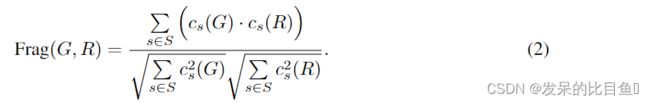
- 与最近邻相似度 (SNN): 一个分子 m G m_G mG的指纹均值Tanimoto相似度 T ( m G , m R ) T(m_G,m_R) T(mG,mR)(也称为Jaccard指数)与参考数据集 R R R中最近邻分子 m R m_R mR之间的均值Tanimoto相似度 T ( m G , m R ) T(m_G,m_R) T(mG,mR)
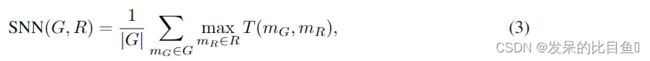
- 内部多样性 (IntDivp ) :该度量的较高值对应于生成集中较高的多样性。该指标的限制为 [0,1]。
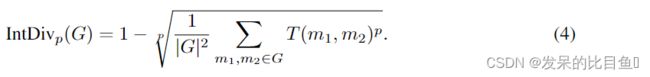
- Fréchet ChemNet 距离 (FCD) :使用深度神经网络 ChemNet 的倒数第二层的激活来计算的,该网络经过训练可预测药物的生物活性。μG,μR是平均向量和ΣG,ΣR分别是来自集合G和R的分子的激活的全协方差矩阵。
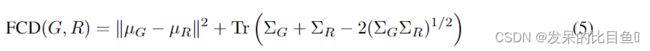
- 属性分布
- 分子量 (MW): 分子中原子量的总和。
- LogP:辛醇-水分配系数
- 合成可及性分数 (SA):对合成给定分子的难易程度 (10) 或难易程度 (1) 的启发式估计。
- 药物相似性的定量估计 (QED): 一个 [0,1] 值,用于估计分子成为药物可行候选者的可能性。
数据集
训练和测试的建议数据集基于 ZINC Clean Leads 集合,其中包含 4、591、276 个分子量在 250 到 350 Da 范围内的分子,可旋转键不大于 7,并且 XlogP不大于 3.5。
图3:来自MOSES数据集的分子示例
基线
- 字符级递归神经网络 (CharRNN)
- 变分自动编码器 (VAE)
- 对抗性自动编码器 (AAE)
- Junction Tree VAE (JTN-VAE)
- 基于潜在向量的生成对抗网络 (LatentGAN)
结果
表 1。基线模型的性能指标:有效分子的比例、独特分子的比例和分子。
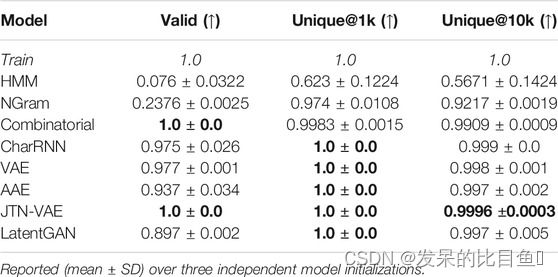
隐马尔可夫模型和 NGram 模型无法生成有效分子,因为它们的上下文有限。组合生成器和 JTN-VAE 具有内置的有效性约束,因此它们的有效性是 100%。
表 2。基线模型的性能指标:通过过滤器的分子分数(MCF、PAINS、环大小、电荷、原子类型)、新颖性和内部多样性。
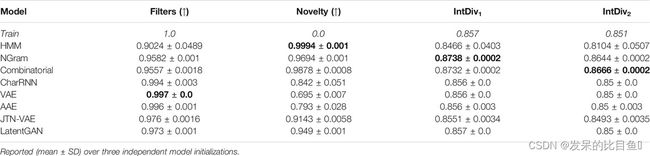
组合生成器比训练数据集具有更高的多样性,这可能有利于发现新的化学结构。基于自动编码器的模型的新颖性较低,表明这些模型过拟合训练集。
表 3。基线模型的性能指标:Fréchet ChemNet 距离 (FCD) 和最近邻相似度 (SNN)。
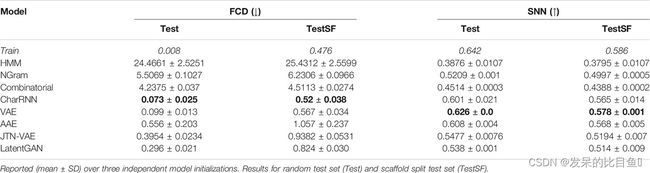
所有基于神经网络的模型都显示出低 FCD,表明模型成功地捕获了数据集的统计数据。
表 4. 片段相似度(Frag),脚手架相似度(Scaff)
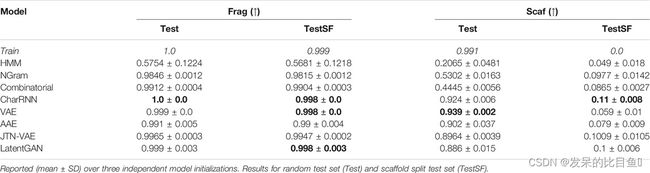
结构分布的相似性——片段和支架。从训练集到脚手架测试集 (TestSF) 的脚手架相似度在设计上为零。请注意,CharRNN 成功发现了许多新的支架(11%),这表明该模型具有很好的泛化性。
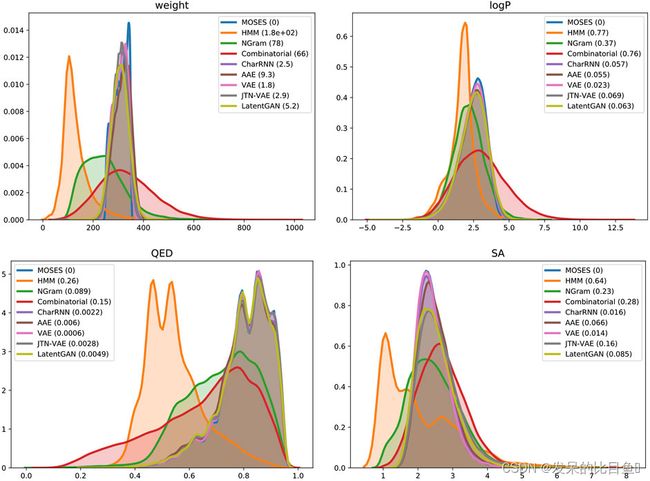
图 4. MOSES 数据集和生成的分子集的化学性质分布。括号中——Wasserstein-1 到 MOSES 测试集的距离。参数:分子量、辛醇-水分配系数 (logP)、药物相似性的定量估计 (QED) 和合成可及性评分 (SA)。
四种分子特性的分布:分子量 (MW)、辛醇-水分配系数 (logP)、药物相似性的定量估计 (QED) 和合成可及性评分 (SA )。较大的分子施加了更多的效度约束。组合生成器的分子量变化更大,产生的分子比训练集中的分子更大和更小。
参考
https://www.frontiersin.org/articles/10.3389/fphar.2020.565644/full#B55