ICLR2022系列解读之一:基于Transformer的跨域方法CDTrans
本文解读我们ICLR2022上发表的论文《CDTrans: Cross-domain Transformer for Unsupervised Domain Adaptation》。这篇文章提出一种基于Transformer的跨域方法:CDTrans。它使用Transformer中的CrossAttention机制来实现SourceDomain和TargetDomain特征对齐。具体来说,在传统方法给TargetDomain打伪标签的过程中难免存在噪声。由于噪声的存在,需要对齐的Source和Target的图片对可能不属于同一类,强行对齐会对训练产生很大的负面影响。该方法经过实验发现Transformer中的CrossAttention可以有效避免噪声给对齐造成的影响。CrossAttention让模型更多的关注Source和Target图片对中相似的信息。换句话说,即使图片对不属于同一类,被拉近的也只会是两者相似的部分。因此,CDTrans具有一定的抗噪能力。最终实验也表明CDTrans的效果大幅领先SOTA方法。
论文链接:CDTrans: Cross-domain Transformer for Unsupervised Domain Adaptation
代码链接:https://github.com/CDTrans/CDTrans
一、前言
大多数现有的UDA方法都集中在学习域特征表示上,希望能够学习到一个跟类别种类相关的而跟域无关的特征。目前的研究无论是从域层面(粗粒度)还是类别层面(细粒度)上的特征对齐操作,都是使用基于卷积神经网络(CNN)的框架。大体上主流的解决思路有两种,分别是基于分布度量一致性约束的方法和基于对抗学习的方法。具有代表性的技术分别是MMD[1] 和DANN[2] 。
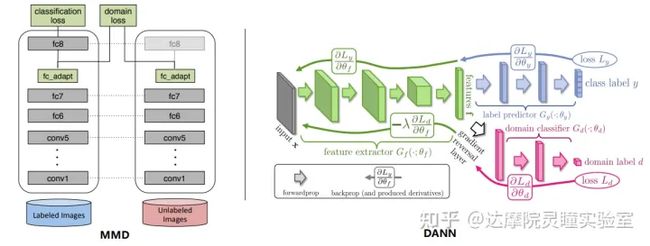
左右图分别是MMD和DANN的网络结构图
在最近的一些研究进展中,基于类别层面的UDA的方法中一个主流思路是在target数据上得到伪标签,用伪标签训练模型。但是一个比较重要的问题是,这些伪标签通常存在一定的噪音,不可避免地会影响UDA的性能。
随着Transformer在各种任务中的成功,特别是MulT [3]和CrossViT [4]等基于transformer的工作分别在多模态和多尺度上取得成功,证明了Cross Attention可以处理不同形式的内容,可以用来对齐不同尺度或者不同模态的数据。所以我们希望借助Transformer的Cross Attention机制来处理UDA任务里面的不同域的特征。CrossViT 模型的输入是同一张图片的不同尺度下的图片patch,MulT 模型输入的是同一种含义下不同模态的数据,他们两者的数据都具有含义一致性,即数据在不同的数据表现形式(多尺度或者多模态)下,表达的含义是一致的。
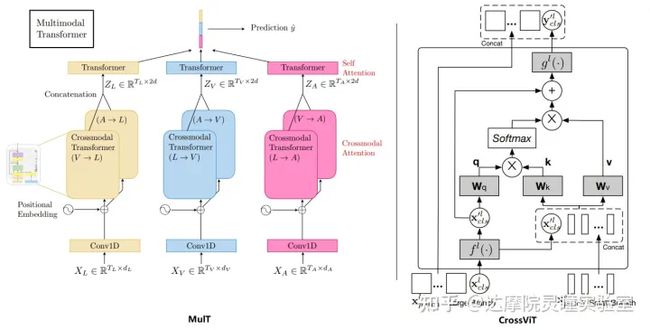
左右图分别是MulT和CrossViT的Cross Attention 机制
我们把Source域和Target域的图片看作不同的数据表现形式,拉近两个域的分布的过程就是追求含义一致性的过程。所以使用Transformer来解决跨域(Domain Adaption, DA)的问题。另一个使用Cross Attention的原因是,我们发现Cross Attention有一定的抗噪能力,可以大幅度弱化伪标签中的噪声对UDA性能的影响。
二、方法介绍
1、Cross Attention及其鲁棒性
我们工作的核心思想是使用Transformer的Cross Attention机制来拉近source域和target域的图片的分布距离。据我们所知,这应该是较早使用纯Transformer在UDA上进行尝试的工作。
具体来说,在利用Transformer的Cross Attention来做两个域分布对齐时,它的输入需要是一个样本对。类似于多模态里面的图文对,这里我们的输入是由一个source图片和一个target图片组成的样本对。正常来说,两张图片应该是属于同一个类别,但是来自于不同的domain(一个source,一个target)。由于在UDA任务中,target是没有标签的。因此我们只能借鉴伪标签[5]的思路,来生成潜在的可能属于同一个ID的样本对。但是,伪标签生成的样本对中不可避免的会存在噪声。这时,我们惊喜的发现Cross Attention对样本对中的噪声有着很强的鲁棒性。
我们分析这主要是因为Attention机制所决定的,Attention的weight更多的会关注两张图片相似的部分,而忽略其不相似的部分。如果Source域图片和Target域图片不属于同一个类别的话,比如下图1.a“小轿车vs卡车”的例子,Attention的weight主要集中于两个图片中相似部分的对齐(比如轮胎),而对其他部位的对齐会给很小的weight。换句话说,Cross Attention没有在使劲拉近对齐小轿车和卡车,而更多的是在努力对齐两个图片中的轮胎。一方面,Cross Attention避免了强行拉近小轿车和卡车,减弱了噪声样本对UDA训练的影响;另一方面,拉近不同域的轮胎,在一定程度上可能帮助到目标域轮胎的识别。
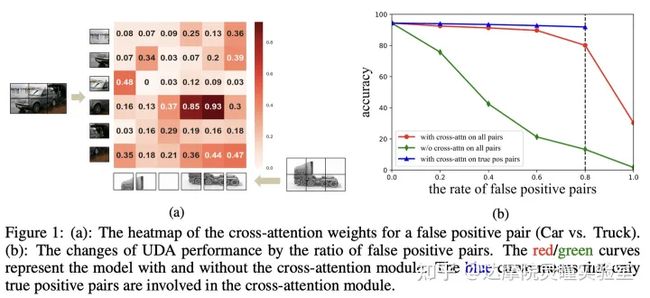
图1.b是Cross-Attention在不同噪声比例的情况下的结果。从图1.b中我们可以看出使用Cross-Attention(红线)的表现接近只用正确样本的结果(蓝线),而不使用Cross-Attention(绿线)的表现受到噪声影响较大。因此,进一步表明Cross-Attention对噪声具有良好的鲁棒性,可以从含有噪声数据中学习到有用的信息。
2、共享参数的三分支网络结构

基于Cross Attention,我们设计了共享参数的三分支网络结构,如上图所示。左侧的Source分支(绿色)和右侧的Target分支(蓝色)使用Self Attention来学习各自数据的特征信息,而中间的Source-Target分支(橙色)通过使用Source的Quey和Target的Key、Value来学习他们相同的信息。
Source分支通过Source的label保持模型在Source数据集的表现,同时为Cross Attention提供合适的Query信息。Target分支通过伪标签进行监督学习,让模型对Target进行合理的学习,同时为Cross Attention提供合适的Key和Value信息。Source-Target分支用来使用对齐两个domain的特征分布。
注意,这里我们并不是直接用伪标签对Source-Target分支进行训练,而是使用蒸馏技术,让Target分支的输出去学习Source-Target分支的输出。公式如下:
Ldtl=∑kqklogpk
之所以使用蒸馏技术,是因为我们相信Cross Attention的对齐能力和抗噪能力。如果输入的两张图片是相同类别,则中间的Source-Target分支可以用于学习他们共同的特征。相比于Target分支,Source-Target分支的特征实现了两个域的对齐。如果输入的两张图片是不同类别(即噪声),这时Target分支的label完全是错误的,会影响训练。但是中间的Source-Target分支使用了Cross Attention,是有抗噪能力的。因此,我们相信,用中间的Source-Target分支去指导Target分支可以取得更好的效果。
3、Source-Tareget域样本匹配策略
最后,我们介绍下我们的如何借鉴伪标签的思路,来生成我们的样本对的。为了产生准确稳定的Source-Target样本对,我们设计了一种双向中心匹配算法,该算法是寻找合适的样本对信息输入到三分支参数共享的的CDTrans。算法公式如下所示:
PS={(s,t)|t=minkd(fs,fk),∀k∈T,∀s∈S}PT={(s,t)|s=minkd(ft,fk),∀t∈T,∀k∈S}
这里两个集合分别是从Source域样本去寻找Target域中距离最近的样本和Target域样本去寻找Source中距离最近的样本。最终的集合则是两者的并集,。这样的好处是确保Source样本和Target样本尽可能参与到Source-Target样本对中,提高样本利用率。
同时我们发现,来自目标域的数据将其经过“源域数据训练的模型”时它会输出一个分类预测结果,这个结果可以用来进一步过滤我们生成的样本对集合P,提高样本对精度。具体来说,对P中的每一个样本对,目标域图片经过“源域数据训练的模型”的分类结果如果和源域图片的标签不一致时,我们认为可能这个样本对是一个噪声,将它删掉。如果一致,则保留。这里值得一提的是,我们发现SHOT [5]方法中采用自监督方式得到的分类结果相比于原始模型输出的分类结果要更准确,因此,文章中我们采用了SHOT 的方式来生成分类结果。
三、实验结果
1、和SOTA比较
我们在四个数据集上做了实验,分别是Office31,Office-Home,Visda-2017和DomainNet。
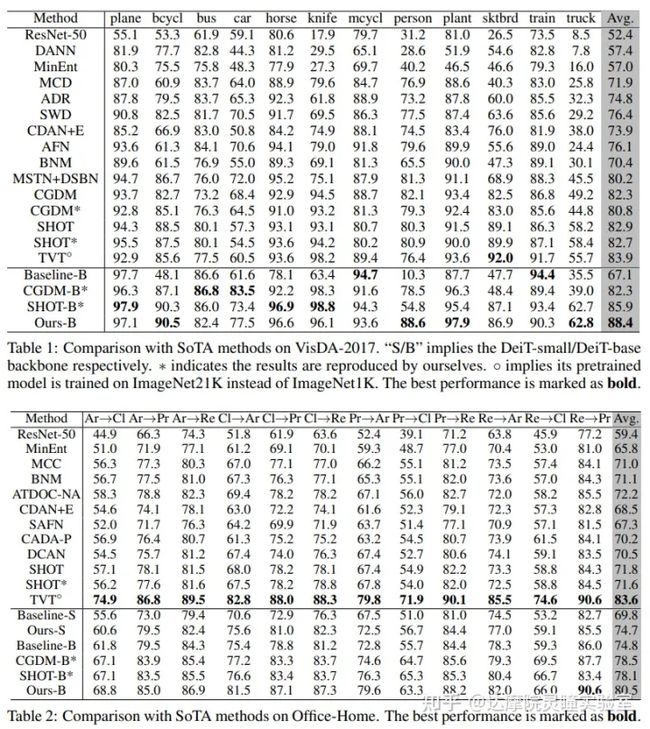
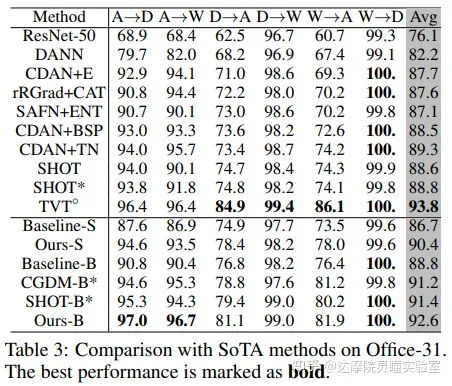
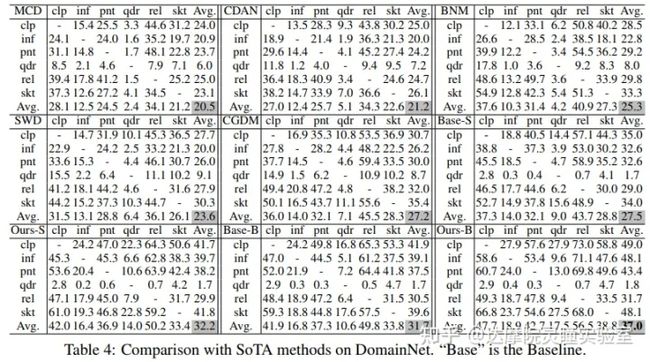
为了公平的跟基于CNN方法做比较,在Office31,Office-Home和DomainNet上,原有的方法基于ResNet50的数据集,我们提供了DeiT-Small和DeiT-Base两种结构的结果。DeiT-Small整体参数量跟ResNet50差不多。在VisDA-2017上,原有的方法基于Resnet-101,我们直接使用和其參数量大致相近的DeiT-Base模型作为对比。需要注意的是TVT方法使用的是在ImageNet-21k上预训练的模型初始化,而我们使用的DeiT的预训练模型和ResNet一致,都是在Image-1k上进行的预训练。
从结果上看,我们的方法在四个数据集上均取得了非常不错的结果,我们的效果远超之前SOTA方法,相比于之前最好的方法,分别提高了5.5%/8.3%/3.3%/9.8%。
2、消融实验
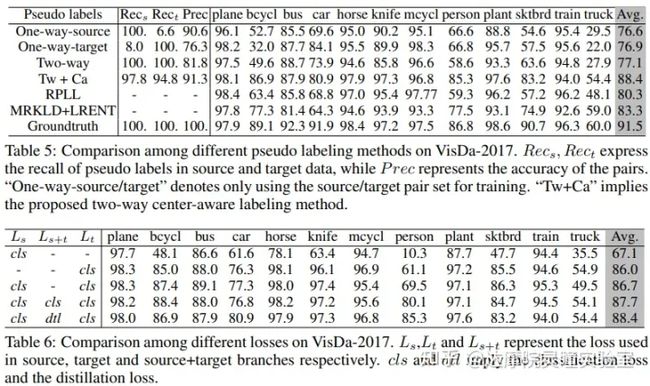
表5展示了CDTrans中各个部分起到的作用。RPLL和MRKLD+LRENT作为其他的伪标签技术引入作为对比。因为UDA任务拉进Source Domain和Target Domain的样本分布特征,那就应该要保证在训练阶段让模型尽可能利用更多的Source Domain和Target Domain的样本。可以看到单纯使用One-way-source或者One-way-target策略时,Target Domain或者Source Domain的样本利用率并不高,这会限制模型精度的提高。但是简单把One-way-source和One-way-target策略加起来的Two-way策略,虽然source 和target域的样本利用率高了,但是精度只提升了一点点。这主要的原因就是source-target样本匹配成对的精度不够高。当添加Ca策略之后,Tw+Ca的样本对匹配精度提高,最终模型在Target Domain的精度接近GroundTruth上的表现。可以看出Tw+Ca方法要比单纯的RPLL和MRKLD+LRENT伪标签技术要好很多。
表6展示了CDTrans中不同损失函数的作用。CDTrans主要包含三部分的损失函数,Source Domain 分支的带有source label的交叉熵损失, Target Domain 分枝的伪标签的交叉熵损失,中间Fusion 分支的蒸馏损失。单纯使用Target Domain分支的损失,模型精度可以实现不错的精度表现,因为这更像是单纯的对Target Domain的样本进行学习,Source Domain的样本仅仅经过一次模型,没有监督信息。当同时使用Source-Target样本对中的Source和Target分支的损失函数的时候,精度又有一点提升,说明Source Domain的监督学习对Target Domain也有帮助。当Fusion分支使用交叉熵损失加入到训练中的时候,模型相对获得1%的提升效果。这证明了Fusion Branch的作用。当Fusion分支使用蒸馏损失的时候,模型可以获得获得1.7%的提升效果,证明了蒸馏损失比交叉熵损失更适合做融合操作,更有利于拉进带有噪声的Source-Target样本对的分布关系。
3、可视化结果
以下是样本对的可视化结果。每一列的结果分别是:Source原图, Source Self-Attention, Target原图,Target Self-Attention,Source-Target Cross-Attention。
(1)正确的Souce-Target样本匹配

bus

plane

motor

knife
(2)错误的Source-Tareget样本匹配

Source: plane Target: bus

Source: plane Target: car

Source: truck Target: plane

Source: truck Target: bus

Source: truck Target: car

Source: plane Target: plant
从可视化的图中可以看出,Source-Target正确匹配的样本的Cross Attention相关性得到了加强,相同特征的区域得到更多的注意力,而Source-Target错误的匹配样本,Cross Attention朝着有相似特征的区域关注,注意力相比于Target的Self-Attention可以更好的关注与Source相似的区域,而更少的关注Target自身独特区域。例如“truck和car”的样本对中,Source-Target的Cross-Attention关注于车顶和车轮上部位置,这是卡车和汽车中都有的共同点。在“plane和plant”图中,Plant与Plane的相似度比较低,Cross Attention关注到了背景部分。这样的好处是在Source-Target样本对中,Target的伪标签同Source样本一致,Cross Attention关注的背景使得这个Target样本避免把Plant的特征学习到Plane类里面去,减少了模型从噪声样本中学习到类别特征。
四、总结
CDTrans是一种首先把Cross Attention机制引入到UDA场景的Transformer方法。这个方法最大的特点就是使用Cross Attention把Source Domain和Target Domain的信息融合起来,拉进跨域样本的分布距离。注意力机制可以是得模型更加聚焦于Source Domain和Target Domain的相似的特征表示,使得模型可以获得更好的跨域精度表现。通过共享参数的三分支结构,即可以实现Source Domain、Target Domain单独学习其特征表示,也可以实现Source Domain和Target Domain的相同特征表示的学习。在训练的时候输入Source-Target样本对进行三分支模型训练,测试阶段仅仅需要进行单分支特征提取即可。这样既保证了模型高效训练,又可以实现模型同时对Source Domain和Target Domain数据提取能力,而不仅仅是学习Target Domain而遗忘Source Domain的提取特征能力。最后希望Cross Attention机制可以在UDA场景中发挥更多的作用。
Refenrece
[1] Deep Domain Confusion: Maximizing for Domain Invariance
[2] Domain-Adversarial Training of Neural Networks
[3] Tsai, Yao-Hung Hubert, et al. "Multimodal transformer for unaligned multimodal language sequences." Proceedings of the conference. Association for Computational Linguistics. Meeting. Vol. 2019. NIH Public Access, 2019.
[4] CrossViT: Cross-Attention Multi-Scale Vision Transformer for Image Classification
[5] Do We Really Need to Access the Source Data? Source Hypothesis Transfer for Unsupervised Domain Adaptation