Python文字识别之tesseract-ocr和EasyOCR
Python文字识别之tesseract-ocr和EasyOCR
本文主要是将手机拍摄的图片文字通过Python OCR转换成Word文件,并尝试通过tesseract-ocr和EasyOCR两种方式进行图片文字识别,展示两种方式的文字识别效果,为小伙伴在选择tesseract-ocr或EasyOCR识别图片文字时提供参考。本人所使用的环境windows,所以本文涉及到的安装、编程都是在Windows下进行的。
一、tesseract-ocr图片文字识别
1、tesseract-ocr 在Windows下的安装
1)安装两个python模块
pip install pytesseract
pip install pillow
2)下载tesseract-ocr,安装、配置、下载语音包。
tesseract-ocr下载地址为:
Home · UB-Mannheim/tesseract Wiki · GitHub

下载完成后双击点.exe 文件,安装到相应目录下,我本安装到D:\Program Files\目录下。
安装完成以后配置环境变量,在计算机-->属性-->高级系统设置-->环境变量-->系统变量path中添加D:\Program Files\Tesseract-OCR;
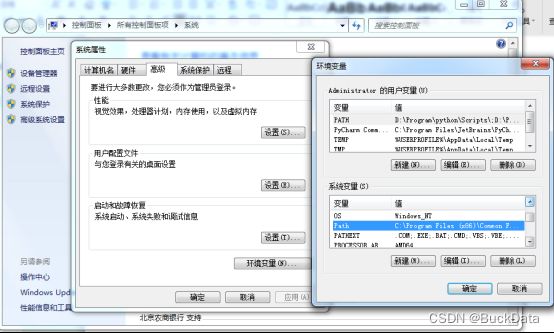
Tesseract默认是不支持中文的,如果想要识别中文或者其它语言需要下载相应的语言包,中文语言包为:chi_sim.traineddata,下载地址为:https://github.com/tesseract-ocr/tessdata_best
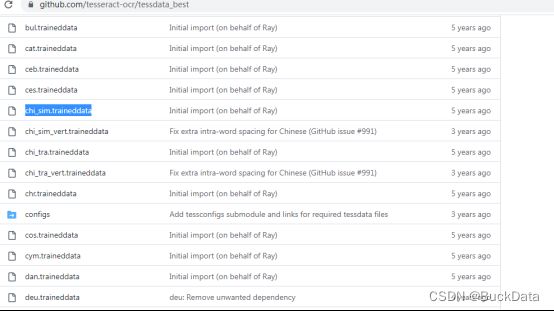
若无法下载,请到本人csdn账号的资源下下载。
下载完成后将chi_sim.traineddata放到D:\Program Files\Tesseract-OCR\tessdata目录下即可。
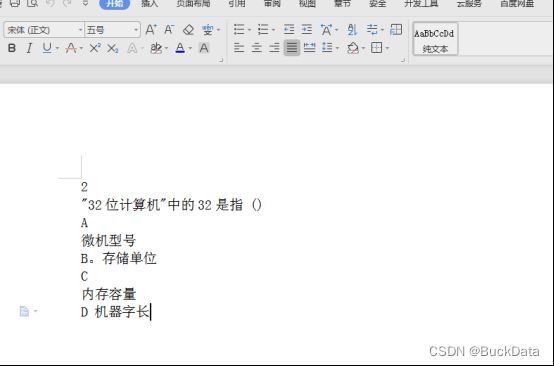
2、示例图片
本文示例图片如下:

3、程序
程序如下:
import pytesseract
from PIL import Image
import os
def test_tesseract():
# 文字图片路径
path=r'E:\test\test.jpg'
im=Image.open(path)
# 文字识别
str1=pytesseract.image_to_string(im,lang='chi_sim')
print("str1===",str1)
# 将文字输出到word文件中
f = open('test1.doc', 'w+', encoding='utf-8')
f.write(str1 + '\n')
f.close()
4、运行结果

二、EasyOCR图片文字识别
1、安装EasyOCR 、文本检测模型、识别模型(语言包)
1)安装EasyOCR
通过pip install easyocr
也可以下载easyocr-1.5.0-py3-none-any.whl,
通过pip install easyocr-1.5.0-py3-none-any.whl 安装
easyocr-1.5.0-py3-none-any.whl 下载地址为:easyocr · PyPI

2)下载文本检测模型
文本检查模型craft_mlt_25k,下载地址为:
Jaided AI: EasyOCR model hub
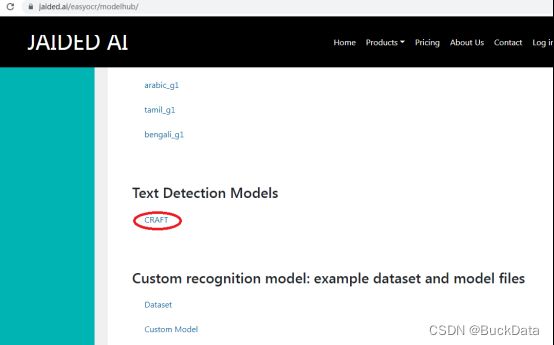
3)下载中文和英文识别模型
英文识别模型:english_g2,中文识别包:zh_sim_g2
下载地址:https://www.jaided.ai/easyocr/modelhub/
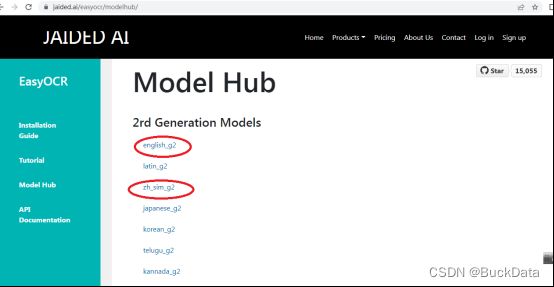
以上地址若无法下载,请到本人csdn的资源下下载。
将craft_mlt_25k.pth,english_g2.pth,zh_sim_g2.pth 放在C:\Users\Administrator\.EasyOCR\model 目录下,安装成功。

2、图片示例

3、程序
import easyocr
import os
def test_easyocr():
# 文字图片路径
path = r'E:\test\test.jpg'
# 创建reader
reader=easyocr.Reader(['ch_sim', 'en'])
# 读取图片
result=reader.readtext(path)
# 打印结果
print("result===",result)
# 将结果输出到word文件中
f = open('test2.doc', 'w+', encoding='utf-8')
for i in result:
word=i[1]
f.write(word + '\n')
f.close()
4、运行结果
本人又试了一些其它文字图片转成word,有些情况下tesseract-ocr识别情况好些,有些情况下EasyOCR识别的度更高一些,如果想要得到识别度更高的结果还需要对tesseract-ocr和EasyOCR进行训练。