描述性统计分析
概要
描述性统计,是指运用制表和分类,图形以及计算概括性数据来描述数据特征的各项活动。描述性统计分析要对调查总体所有变量的有关数据进行统计性描述,主要包括数据的频数分析、集中趋势分析、离散程度分析、分布以及一些基本的统计图形。①数据的频数分析。在数据的预处理部分,利用频数分析和交叉频数分析可以检验异常值。②数据的集中趋势分析。用来反映数据的一般水平,常用的指标有平均值、中位数和众数等。③数据的离散程度分析。主要是用来反映数据之间的差异程度,常用的指标有方差和标准差。④数据的分布。在统计分析中,通常要假设样本所属总体的分布属于正态分布,因此需要用偏度和峰度两个指标来检查样本数据是否符合正态分布。⑤绘制统计图。用图形的形式来表达数据,比用文字表达更清晰、更简明。在SPSS软件里,可以很容易地绘制各个变量的统计图形,包括条形图、饼图和折线图等。
————摘自百度百科
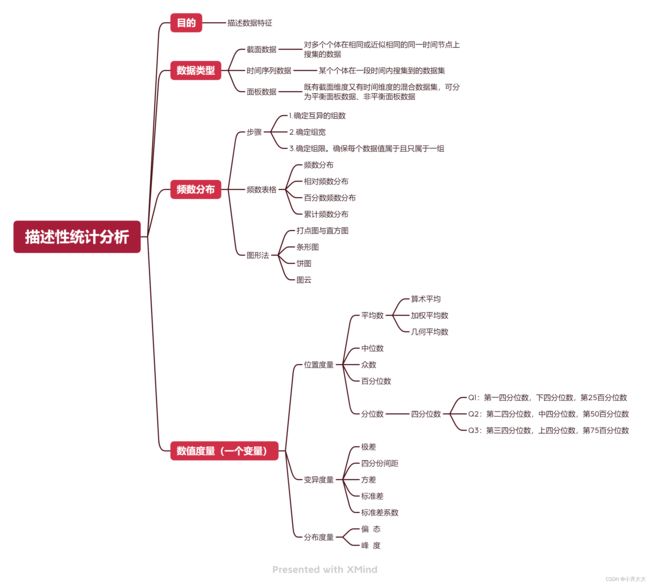
数据类型
- 截面数据
对多个个体在相同或近似相同的同一时间节点上搜集的数据
- 时间序列数据
某个个体在一段时间内搜集到的数据集
- 面板数据
既有截面维度又有时间维度的混合数据集,可分为平衡面板数据、非平衡面板数据
数据的频数分析
步骤
1. 确定互异的组数
2. 确定组宽
3. 确定组限。确保每个数据值属于且只属于一组
数据的位置度量
数据的集中趋势分析是用来反映数据的一般水平,常用的指标有平均值、中位数和众数等。各指标的具体意义如下:
平均值:是衡量数据的中心位置的重要指标,反映了一些数据必然性的特点,包括算术平均值、加权算术平均值、调和平均值和几何平均值。
加权平均数:当观测值具有不同的权重(重要性),使用加权平均数
几何平均数:也是数据位置的一种度量,但它是n 个数值乘积的 n 次方根。在财金领域中,几何平均数常用于分析财务数据的年、季度、月、周甚至天的平均变化率。
中位数:是另外一种反映数据的中心位置的指标,其确定方法是将所有数据以由小到大的顺序排列,位于中央的数据值就是中位数。
众数:是指在数据中发生频率最高的数据值。
除此之外,还有百分位数,四分位数。
如果各个数据之间的差异程度较小,用平均值就有较好的代表性;而如果数据之间的差异程度较大,特别是有个别的极端值的情况,用中位数或众数有较好的代表性。
| 位置 | 极端值影响 | 应用 | |
|---|---|---|---|
| 平均数 mean | 重心 | 极易 | 存在极端值时,可用 中位数或调整平均数替代 |
| 中位数 median | 排序后的中间 | 不受 | 存在极端值时,是比平均数更为准确的确定数据中心位置的参数 |
| 众数 mode | 出现频次最高 | 不受 |
数据的变异度量
变异程度(variability)被称作变异性或者可变性,它描述了数据点彼此之间以及距分布中心的距离。可变性有时也称为扩散或者分散。 因为它告诉你点是倾向于聚集在中心周围还是更广泛地分散。低变异性是理想的,因为这意味着可以根据样本数据更好地预测有关总体的信息。 高可变性意味着值的一致性较低,因此更难做出预测。
- 极差
极差,又称全距,可以显示数据从分布中的最低值到最高值的分布。极差=最大值-最小值
极差的度量仅使用了 2 个数字因此受异常值影响很大,并且不会提供有关值分布的任何信息。 所以它最好与其他方法结合使用。
- 四分位距
又被称作四分差,可以提供数据分布中间的分布。
四分位数
Q1:第一四分位数,下四分位数,第25百分位数
Q2:第二四分位数,中四分位数,第50百分位数
Q3:第三四分位数,上四分位数,第75百分位数第三四分位数与第一四分位数的差距又称四分位距(InterQuartile Range, IQR)。
对于从低到高排序的任何分布,四分位距包含数据中一半的值。 第一个四分位数 (Q1) 包含前 25% 的值,而第四个四分位数 (Q4) 包含最后 25% 的值。
它衡量数据如何围绕均值分布。 基本公式为:
IQR = Q3 - Q1就像极差一样,四分位距在其计算中仅使用 2 个值。 但是IQR受异常值的影响较小:这2个值来自数据集的中间一半,所以不太可能是极端分数。
- 方差
方差表示数据集的分布范围,但它是一个抽象数字。它反映了数据集中的分散程度。 数据越分散,方差与均值的关系就越大。
总体方差

样本方差
- 小方差 - 数据点往往非常接近均值且彼此非常接近
- 高方差 - 数据点与均值和彼此之间非常分散
- 零方差——所有数据值都相同
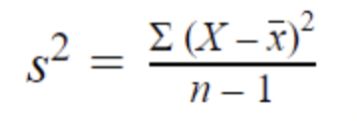
- 标准差
标准偏差是数据集中的平均变异量。 它平均表示每个数据点与平均值相差多远。标准差越大,数据集的可变性越大。
总体标准差:
样本标准差:

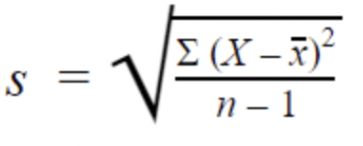
- 标准差系数
标准差系数,又称为均方差系数,离散系数。它是从相对角度观察的差异和离散程度,在比较相关事物的差异程度时较之直接比较标准差要好些。

什么是变异性的最佳衡量标准?
可变性的最佳衡量标准取决于不同衡量标准和分布水平。
对于在序数水平上测量的数据,极差和四分位距是唯一合适的变异性度量。
对于更复杂的区间和比率的数据,标准差和方差也适用。
对于正态分布,可以使用所有度量。 但标准差和方差是首选,因为它们考虑了整个数据集,但这也意味着它们很容易受到异常值的影响。
对于偏态分布或具有异常值的数据集,四分位距是最好的度量。 它受极值影响最小,因为它侧重于数据集中间的部分。
| 总体参数 | 样本统计量 | |
|---|---|---|
| 平均数 mean | μ | x ˉ \bar x xˉ |
| 方差 variance | σ 2 σ^2 σ2 | s 2 s^2 s2 |
| 标准差 standard deviation | σ | s |
分布形态的度量
偏度
偏度(skewness),是统计数据分布偏斜方向和程度的度量,是统计数据分布非对称程度的数字特征。定义上偏度是样本的三阶标准化矩。
数据分布偏斜程度使用偏态系数(skewness)进行测度,记为$SK = \frac{\bar x-M_0}{\sigma} $
SK= 0:对称分布
SK> 0:右偏分布
SK< 0:左偏分布

峰度
峰度(peakedness;kurtosis)又称峰态系数。表征概率密度分布曲线在平均值处峰值高低的特征数。直观看来,峰度反映了峰部的尖度。随机变量的峰度计算方法为:随机变量的四阶中心矩与方差平方的比值。
峰度包括正态分布(峰度值=3),厚尾(峰度值>3),瘦尾(峰度值<3)

相对位置的度量
z-分数
**z-**分数:离差/标准差,表明每一个观测值与均值的相对位置

切比雪夫定理
与平均数距离在 z 个标准差之内的数据值所占比例至少为( 1 − 1 / z 2 1-1/z^2 1−1/z2),其中 z 是大于1的任意实数
数值分布越接近对称或钟形分布,切比雪夫定理越准确
探索性数据分析
五数概括法:
五数概括法使用5个统计量确定较大数据集的多重特征
小知识:每个分布都可以使用五个数字摘要进行组织
- 最低值
- Q1:第 25 个百分位
- Q2:中位数
- Q3:第 75 个百分位
- 最高值 (Q4)
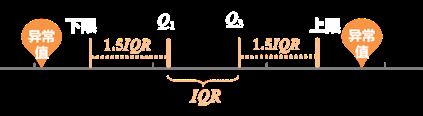
箱型图
箱线图也称箱须图、箱形图、盒图,用于反映一组或多组连续型定量数据分布的中心位置和散布范围。箱形图包含数学统计量,不仅能够分析不同类别数据各层次水平差异,还能揭示数据间离散程度、异常值、分布差异等等。
箱形图是五数概括法的具象化,箱形图最大的优点就是不受异常值的影响,可以以一种相对稳定的方式描述数据的离散分布情况。
在箱线图中,箱子的中间有一条线,代表了数据的中位数。箱子的上下底,分别是数据的上四分位数(Q3)和下四分位数(Q1),这意味着箱体包含了50%的数据。因此,箱子的高度在一定程度上反映了数据的波动程度。上下边缘则代表了该组数据的最大值和最小值。有时候箱子外部会有一些点,可以理解为数据中的“异常值”。
通过箱形图可以判断数据集的分布形态,箱形图最重要的用途就是识别异常值

异常值检验
经验法则
几乎所有的数据值与平均数的距离在3个标准差之内
z-分数(标准化数值)检验
对<−3或>3的任何数值均视为异常值
四分位数法(箱型图)
下限 = − .
上限 = + .
找出异常值后需再次检验其准确性,确定它是否属于数据集
双变量之间关系的度量
协方差、相关系数
协方差的值依赖于和的计量单位,不同计量单位下容易出现判断误差
相关系数对于刻画两个变量之间的关系更为准确,即相关系数可以刻画关系的强度
数据分析工具
matlab中基本统计量的函数
| 函数名 | 功能 |
|---|---|
| min | 数组的最小元素 |
| mink | 计算数组的k个最小元素 |
| max | 数组的最大元素 |
| maxk | 计算数组的k个最大元素 |
| bounds | 最小元素和最大元素 |
| topkrows | 按排序顺序的前若干行 |
| mean | 数组的均值 |
| median | 数组的中位数值 |
| mode | 数组的众数 |
| skewness | 数组的偏度 |
| kurtosis | 数组的峰度 |
| std | 标准差 |
| var | 方差 |
EXCEL的数据分析工具
数据 – 数据分析
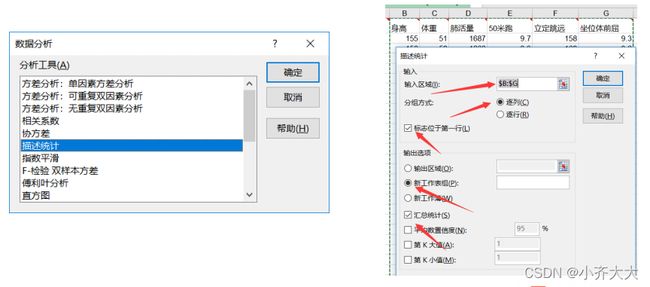
SPSS数据分析
