多元分析(Multivariate Analysis)
多元分析
- 简介
- 多元回归分析
-
- 一元线性回归
- 聚类分析
-
- K-means聚类算法
- K-means++算法
- 系统(层次聚类)
- 典型相关分析
- 主成分分析
简介
多元分析(Multivariate Analysis)是多变量的统计分析方法,是数理统计中应用广泛的一个重要分支。
多元回归分析
回归分析是数据分析中最基础也是最重要的分析工具,绝大多数的数据分析问题,都可以使用回归的思想来解决。回归分析的任务就是,通过研究自变量X和因变量Y的相关关系,尝试去解释Y的形成机制,进而达到通过X去预测Y的目的。
常见的回归分析有五类:线性回归、 0‐1回归、定序回归、计数回归和生存回归,其划分的依据是因变量Y的类型。本文主要简述线性回归。
回归分析:研究X和Y之间相关性的分析。回归分析的任务就是,通过研究X和Y的相关关系,尝试去解释Y的形成机制,进而达到通过X去预测Y的目的
相关性不等于因果性
在绝大多数情况下,我们没有能力去探究严格的因果关系,所以只好退而求其次,改成通过回归分析,研究相关关系。
回归分析的三个使命:
(1)识别重要变量
(2)判断相关性的方向
(3)要估计权重(回归系数)
数据的分类:
(1)横截面数据:在某一时点收集的不同对象的数据。如在确定时间发放的问卷数据、全国各省份2021年GDP的数据
(2)时间序列数据:对同一对象在不同时间连续观察所取得的数据。如从出生到现在你的体重数据(每年生日称一次体重,得到一次观测数据)、中国历年来的GDP数据
(3)面板数据:横截面数据与时间序列数据综合起来的一种 数据资源
不同数据类型的处理方法
| 数据类型 | 常见建模方法 |
|---|---|
| 横截面数据 | 多元线性回归 |
| 时间序列数据 | 移动平均、指数平滑、ARIMA、GARCH、VAR |
| 面板数据 | 固定效应和随机效应、静态面板和动态面板 |
建模比赛中,前两种数据类型最常考到;面板数据较为复杂,是经管类学生在中级计量经济学中才会学到的模型。
横截面数据往往可以使用回归来进行建模,我们通过回归可以得到自变量与因变量之间的相关关系以及自变量的重要程度。横截面数据容易出现异方差的问题。
时间序列数据往往需要进行我们进行预测,时间序列模型的选择也很多,需要随机应变选择合适的模型来建模。时间序列数据容易出现自相关的问题。
一元线性回归
一元线性回归其实就是从一堆训练集中去算出一条直线,使数据集到直线之间的距离差最小。
对线性的理解:
线性假定并不要求初始模型都呈上述的严格线性关系,自变量与因变量可通过变量替换而转化成线性模型。
什么时候取对数:
取对数意味着原解释变量对解释变量的弹性,即百分比的变化而不是数值的变化。
目前,对于什么时候取对数还没有固定的规则,但是有一些经验法则:
(1)与市场价值相关的,例如,价格、销售额、工资等都可以取对数;(2)以年度量的变量,如受教育年限、工作经历等通常不取对数;
(3)比例变量,如失业率、参与率等,两者均可;
(4)变量取值必须是非负数,如果包含0,则可以对y取对数ln(1+y);
取对数的好处:(1)减弱数据的异方差性(2)如果变量本身不符合正态分布,取了对数后可能渐近服从正态分布(3)模型形式的需要,让模型具有经济学意义。
四类模型回归系数的解释
一元线性回归:y=a+bx+u,x每增加一个单位,y平均变化b个单位。
双对数模型:lny=a+blnx+u,x每增加1%,y平均变化b%
半对数模型:y=a+blnx+u,x每增加1%,y平均变化b/100个单位
半对数模型:lny=a+bx+u,x每增加一个单位,y平均变化(100b)%
特殊的自变量:虚拟变量X
如果自变量中有定性变量,例如性别、地域等,在回归中要怎么处理呢?
例如:我们要研究性别对于工资的影响(性别歧视)
y i = β 0 + δ 0 Female i + β 1 x 1 i + β 2 x 2 i + ⋯ + β k x k i + μ i y_{i}=\beta_{0}+\delta_{0} \text { Female }_{i}+\beta_{1} x_{1 i}+\beta_{2} x_{2 i}+\cdots+\beta_{k} x_{k i}+\mu_{i} yi=β0+δ0 Female i+β1x1i+β2x2i+⋯+βkxki+μi
其中 F e m a l e i = 1 Female_i=1 Femalei=1表示第i个样本为女性; F e m a l e i = 0 Female_i=0 Femalei=0表示第i个样本为男性,核心解释变量: F e m a l e Female Female,控制变量: x m ( m = 1 , 2 , … … , k ) x_m(m=1,2,……,k) xm(m=1,2,……,k)
E ( y ∣ Female = 1 以及其他自变量给定 ) = δ 0 × 1 + C E ( y ∣ Female = 0 以及其他自变量给定 ) = δ 0 × 0 + C E ( y ∣ Female = 1 以及其他自变量给定 ) − E ( y ∣ Female = 0 以及其他自变量给定 ) = δ 0 所以 δ 0 可解释为: 在其他自变量给定的情况下, 女性的平均工资与男性的平均工资的差异 E(y \mid \text { Female }=1 \text { 以及其他自变量给定 })=\delta_{0} \times 1+C \\ E(y \mid \text { Female }=0 \text { 以及其他自变量给定 })=\delta_{0} \times 0+C \\ E(y \mid \text { Female }=1 \text { 以及其他自变量给定 })-E(y \mid \text { Female }=0 \text { 以及其他自变量给定 })=\delta_{0} \\ \text { 所以 } \delta_{0} \text { 可解释为: 在其他自变量给定的情况下, 女性的平均工资与男性的平均工资的差异} E(y∣ Female =1 以及其他自变量给定 )=δ0×1+CE(y∣ Female =0 以及其他自变量给定 )=δ0×0+CE(y∣ Female =1 以及其他自变量给定 )−E(y∣ Female =0 以及其他自变量给定 )=δ0 所以 δ0 可解释为: 在其他自变量给定的情况下, 女性的平均工资与男性的平均工资的差异
拟合优度 R 2 R^2 R2较低怎么办?
(1)回归分为解释型回归和预测型回归。预测型回归—般才会更看重R2。解释型回归更多的关注模型整体显著性以及自变量的统计显著性和经济意义显著性即可。
(2)可以对模型进行调整,例如对数据取对数或者平方后再进行回归。
(3)数据中可能有存在异常值或者数据的分布极度不均匀
聚类分析
“物以类聚,人以群分”,所谓的聚类,就是将样本划分为由类似的对象组成的多个类的过程。聚类后,我们可以更加准确的在每个类中单独使用统计模型进行估计、分析或预测;也可以探究不同类之间的相关性和主要差异 聚类分析又称群分析,是对多个样本或指标进行定量分类的一种多元统计分析方法。对样本进行分类称为Q型聚类分析,对指标进行分类称为R型聚类分析。聚类分析作为一种定量方法,将从数据分析的角度,给出一个更准确、细致的分类工具。
K-means聚类算法
优点:
(1)算法简单、快速。(2)对处理大数据集,该算法是相对高效率的。
缺点:
(1)要求用户必须实现给出要生成的簇的数目K (2)对初值敏感 (3)对于孤立点数据敏感
ps: K-means++算法可解决2和3这两个缺点
K-means++算法
k-means++算法选择初始聚类中心的基本原则是:初始的聚类中心之间的相互距离要尽可能的远。
算法描述如下:
(只对K-means算法“初始化K个聚类中心”这一步进行了优化)
步骤一:随机选取一个样本作为第一个聚类中心;
步骤二:计算每个样本与当前已有聚类中心的最短距鹃‘(即与最近一个聚类中心的距离),这个值越大,表示被选取作为聚类中心的概率较大;最后,用轮盘法(依据概率大小来进行抽选)选出下一个聚类中心;
步骤三:重复步骤二,直到选出K个聚类中心。选出初始点后,就继续使用标准的K-means算法了。
Spss软件操作

K-means算法的一些讨论
(1)聚类的个数K值怎么定?
答:分几类主要取决于个人的经验与感觉,通常的做法是多尝试几个K值,看分成几类的结果更好解释,更符合分析目的等。
(2)数据的量纲不一致怎么办?
答:如果数据的量纲不一样,那么算距离时就没有意义。例如:如果X1单位是米,X2单位是吨,用距离公式计算就会出现“米的平方"加上“吨的平方"再开平方,最后算出的东西没有数学意义,这就有问题了。遇到这种情况要先对数据进行标准化(先减去均值再除以标准差)处理,消除量纲的影响
系统(层次聚类)
系统聚类的合并算法通过计算两类数据点间的距离,对最为接近的两类数据点进行组合,并反复迭代这一过程,直到将所有数据点合成一类,并生成聚类谱系图。

系统(层次)聚类的算法流程:
一、将每个对象看作一类,计算两两之间的最小距离;
二、将距离最小的两个类合并成一个新类;
三、重新计算新类与所有类之间的距离
四、重复二三两步,直到所有类最后合并成一类;
五、结束。
Spss软件操作
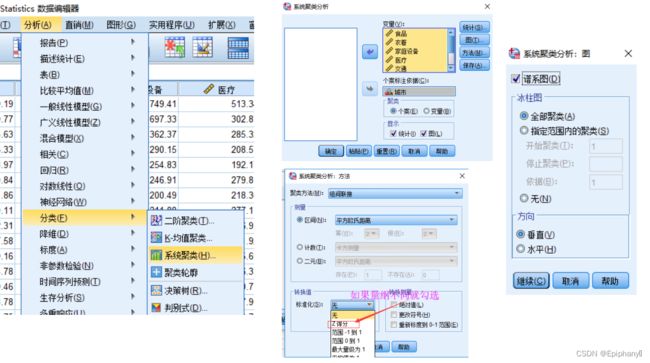
聚类谱系图(树状图)

典型相关分析
研究两组变量(每组变量中都可能有多个指标)之间相关关系的一种多元统计方法。它能够揭示出两组变量之间的内在联系
典型相关分析由Hotelling提出,其基本思想和主成分分析非常相似。
首先在每组变量中找出变量的线性组合,使得两组的线性组合之间具有最大的相关系数;
然后选取和最初挑选的这对线性组合不相关的线性组合,使其配对,并选取相关系数最大的一对;
如此继续下去,直到两组变量之间的相关性被提取完毕为止。
被选出的线性组合配对称为典型变量,它们的相关系数称为典型相关系数。典型相关系数度量了这两组变量之间联系的强度。
基本步骤
- 数据的分布有假设:两组数据服从正态分布
- 首先要对两组变量的相关性进行检验(构造似然比统计量)
- 确定典型相关变量的个数(直接看典型相关系数对应的P值即可)
- 利用标准化后的典型相关变量分析问题
- 进行典型载荷分析
- 计算前r个典型变量对样本总方差的贡献
spss操作步骤
- 导入数据
- 检验数据的类型(变量视图,全部设置为标度)
- 点击菜单功能 分析-相关-典型相关性
- 将数据移动到对应的集和
- 导出分析结果
- 对结果进行分析,有几个显著的典型相关系数就要写出几对来,典型变量每个分量前面的系数代表着重要程度,可结合典型相关系数进行分析
主成分分析
本节将介绍主成分分析(Principal Component Analysis,PCA),主成分分析是一种降维算法,它能将多个指标转换为少数几个主成分,这些主成分是原始变量的线性组合,且彼此之间互不相关,其能反映出原始数据的大部分信息。一般来说,当研究的问题涉及到多变量且变量之间存在很强的相关性时,我们可考虑使用主成分分析的方法来对数据进行简化。
用较少的新变量代替原来较多的旧变量,而且使这些较少的新变量尽可能多地保留原来变量所反映的信息。主成分分析是把原来多个变量划为少数几个综合指标的一种统计分析方法。从数学角度来看,这是一种降维处理技术。
降维是将高维度的数据(指标太多)保留下最重要的一些特征,去除噪声和不重要的特征,从而实现提升数据处理速度的目的。在实际的生产和应用中,降维在一定的信息损失范围内,可以为我们节省大量的时间和成本。降维也成为应用非常广泛的数据预处理方法
降维具有如下的一些优点:
- 使得数据更易使用
- 降低算法的计算开销
- 去除噪声
- 使得结果容易理解
主成分分析的思想:
主成分分析是利用降维的思想,在损失很少信息的前提下把多个指标转化为几个综合指标的多元统计方法。转化生成的综合指标称之为主成分,其中每个主成分都是原始变量的线性组合,且各个主成分之间互不相关,这就使得主成分比原始变量具有某些更优越的性能。
基本原理


基本步骤
- 将原始数据标准化,以消除量纲的影响(spss自动计算)
- 建立变量之间的相关系数矩阵R
- 计算相关系数矩阵R的特征值和特征向量
- 写出主成分并计算综合得分
spss操作
选择“分析-降维-因子分析”命令,打开因子分析对话框
主成分分析适用于变量之间存在较强相关性的数据,如果原始数据相关性较弱,应用主成分分析后不能起到很好的降维作用,所得的各个主成分浓缩原始变量信息的能力相差不大。一般认为当原始数据大部分变量的相关系数都小于0.3时,应用主成分分析取得的效果不理想。
1)主成分分析的结果受量纲的影响,由于各变量的单位可能不一样,如果各自改变量纲,结果会不一样,这是主成分分析的最大问题,回归分析是不存在这种情况的,所以实际中可以先把各变量的数据标准化,然后使用协方差矩阵或相关系数矩阵进行分析。
2)为使方差达到最大的主成分分析,所以不用转轴(由于统计软件常把主成分分析和因子分析放在一起,后者往往需要转轴,使用时应注意)。
3)主成分的保留。用相关系数矩阵求主成分时,Kaiser主张将特征值小于1的主成分予以放弃(这也是SPSS软件的默认值)。
4)在实际研究中,由于主成分的目的是为了降维,减少变量的个数,故一般选取少量的主成分(不超过5或6个),只要它们能解释变异的70%~80%(称累积贡献率)就行了。
的数据标准化,然后使用协方差矩阵或相关系数矩阵进行分析。
2)为使方差达到最大的主成分分析,所以不用转轴(由于统计软件常把主成分分析和因子分析放在一起,后者往往需要转轴,使用时应注意)。
3)主成分的保留。用相关系数矩阵求主成分时,Kaiser主张将特征值小于1的主成分予以放弃(这也是SPSS软件的默认值)。
4)在实际研究中,由于主成分的目的是为了降维,减少变量的个数,故一般选取少量的主成分(不超过5或6个),只要它们能解释变异的70%~80%(称累积贡献率)就行了。