R语言_电信客户流失数据分析
1 引言
近年来,各行各业往往都会不可避免地面临用户流失的问题。研究表明,发展新用户所花费的宣传、促销等成本显然高于维持老用户的成本,因此,做好"客户流失预警"可以有效降低营销成本,做到精准营销。
如今,随着运营商的竞争不断加剧,电信运营商亟需提高用户留存率、增加用户黏性,减少客户流失。因此,需要对电信客户进行流失分析与预测,发掘客户流失的原因,进而改善自身业务,提高用户的满意度,延长用户生命周期。
2 数据来源与数据概况
2.1 数据来源
数据来源kaggle电信用户流失数据集。
https://www.kaggle.com/blastchar/telco-customer-churn
2.2 数据概况
电信客户流失数据集描述了电信用户是否流失以及其相关信息,共包含7043条记录,21个字段。 读入数据集后,了解数据集的基本信息。
> telco.data <- read.csv("WA_Fn-UseC_-Telco-Customer-Churn.csv")
> # 展示数据集的前六行数据
> head(telco.data)
customerID gender SeniorCitizen Partner Dependents tenure PhoneService
1 7590-VHVEG Female 0 Yes No 1 No
2 5575-GNVDE Male 0 No No 34 Yes
3 3668-QPYBK Male 0 No No 2 Yes
4 7795-CFOCW Male 0 No No 45 No
5 9237-HQITU Female 0 No No 2 Yes
6 9305-CDSKC Female 0 No No 8 Yes
MultipleLines InternetService OnlineSecurity OnlineBackup DeviceProtection
1 No phone service DSL No Yes No
2 No DSL Yes No Yes
3 No DSL Yes Yes No
4 No phone service DSL Yes No Yes
5 No Fiber optic No No No
6 Yes Fiber optic No No Yes
TechSupport StreamingTV StreamingMovies Contract PaperlessBilling
1 No No No Month-to-month Yes
2 No No No One year No
3 No No No Month-to-month Yes
4 Yes No No One year No
5 No No No Month-to-month Yes
6 No Yes Yes Month-to-month Yes
PaymentMethod MonthlyCharges TotalCharges Churn
1 Electronic check 29.85 29.85 No
2 Mailed check 56.95 1889.50 No
3 Mailed check 53.85 108.15 Yes
4 Bank transfer (automatic) 42.30 1840.75 No
5 Electronic check 70.70 151.65 Yes
6 Electronic check 99.65 820.50 Yes
> # 数据集的维度
> dim(telco.data)
[1] 7043 21
每个字段的介绍如下表所示:
| 字段名 | 字段含义 | 字段内容 |
|---|---|---|
| customerID | 客户ID | |
| gender | 性别 | Female & Male |
| SeniorCitizen | 老年用户 | 1表示是,0表示不是 |
| Partner | 伴侣用户 | Yes or No |
| Dependents | 亲属用户 | Yes or No |
| tenure | 在网时长 | 0-72月 |
| PhoneService | 是否开通电话服务服务 | Yes or No |
| MultipleLines | 是否开通多线服务 | Yes 、No or No phoneservice 三种 |
| InternetService | 是否开通上网服务 | No, DSL数字网络,fiber optic光纤网络 |
| OnlineSecurity | 是否开通网络安全服务 | Yes,No,No internetserive |
| OnlineBackup | 是否开通在线备份服务 | Yes,No,No internetserive |
| DeviceProtection | 是否开通设备保护服务 | Yes,No,No internetserive |
| TechSupport | 是否开通技术支持服务 | Yes,No,No internetserive |
| StreamingTV | 是否开通网络电视 | Yes,No,No internetserive |
| StreamingMovies | 是否开通网络电影 | Yes,No,No internetserive |
| Contract | 签订合同方式 | 按月,一年,两年 |
| PaperlessBilling | 是否开通电子账单 | Yes or No |
| PaymentMethod | 付款方式 | bank transfer,credit card,electronic check,mailed check |
| MonthlyCharges | 月租费 | 18.85-118.35 |
| TotalCharges | 累计付费 | 18.85-8684.8 |
| Churn | 该用户是否流失 | Yes or No |
3 研究问题
- 分析用户特征与流失的关系
- 流失客户普遍具有哪些特征?
- 尝试找到合适的模型预测流失客户。
- 针对性给出增加用户黏性、降低客户流失率的建议。
4 数据预处理
查看数据集中每个变量的类型。
> str(telco.data)
'data.frame': 7043 obs. of 21 variables:
$ customerID : chr "7590-VHVEG" "5575-GNVDE" "3668-QPYBK" "7795-CFOCW" ...
$ gender : chr "Female" "Male" "Male" "Male" ...
$ SeniorCitizen : int 0 0 0 0 0 0 0 0 0 0 ...
$ Partner : chr "Yes" "No" "No" "No" ...
$ Dependents : chr "No" "No" "No" "No" ...
$ tenure : int 1 34 2 45 2 8 22 10 28 62 ...
$ PhoneService : chr "No" "Yes" "Yes" "No" ...
$ MultipleLines : chr "No phone service" "No" "No" "No phone service" ...
$ InternetService : chr "DSL" "DSL" "DSL" "DSL" ...
$ OnlineSecurity : chr "No" "Yes" "Yes" "Yes" ...
$ OnlineBackup : chr "Yes" "No" "Yes" "No" ...
$ DeviceProtection: chr "No" "Yes" "No" "Yes" ...
$ TechSupport : chr "No" "No" "No" "Yes" ...
$ StreamingTV : chr "No" "No" "No" "No" ...
$ StreamingMovies : chr "No" "No" "No" "No" ...
$ Contract : chr "Month-to-month" "One year" "Month-to-month" "One year" ...
$ PaperlessBilling: chr "Yes" "No" "Yes" "No" ...
$ PaymentMethod : chr "Electronic check" "Mailed check" "Mailed check" "Bank transfer (automatic)" ...
$ MonthlyCharges : num 29.9 57 53.9 42.3 70.7 ...
$ TotalCharges : num 29.9 1889.5 108.2 1840.8 151.7 ...
$ Churn : chr "No" "No" "Yes" "No" ...
4.1 因子变量处理
需要将该数据集中的部分变量转化为因子类型。
> telco.data <- within(telco.data,{
+ SeniorCitizen <- factor(SeniorCitizen, levels = c(0,1), labels = c("No", "Yes"))
+ Partner <- factor(Partner)
+ Dependents <- factor(Dependents)
+ })
> Factors <- c("gender", "PhoneService", "MultipleLines", "InternetService", "OnlineSecurity", "OnlineBackup", "DeviceProtection", "TechSupport", "StreamingTV", "StreamingMovies", "Contract", "PaperlessBilling", "PaymentMethod", "Churn")
> telco.data[Factors] <- lapply(telco.data[Factors],factor)
4.2 缺失值处理
从图中可以看出,TotalCharges列有11个缺失值,占比大约0.16%。
> colSums(is.na(telco.data))
customerID gender SeniorCitizen Partner
0 0 0 0
Dependents tenure PhoneService MultipleLines
0 0 0 0
InternetService OnlineSecurity OnlineBackup DeviceProtection
0 0 0 0
TechSupport StreamingTV StreamingMovies Contract
0 0 0 0
PaperlessBilling PaymentMethod MonthlyCharges TotalCharges
0 0 0 11
Churn
0
> library(VIM)
> par(cex = 0.72, font.axis = 3)
> VIM::aggr(telco.data, prop = TRUE, numbers = TRUE)

处理缺失值数据的一种方法是插补均值、中位数或者众数。
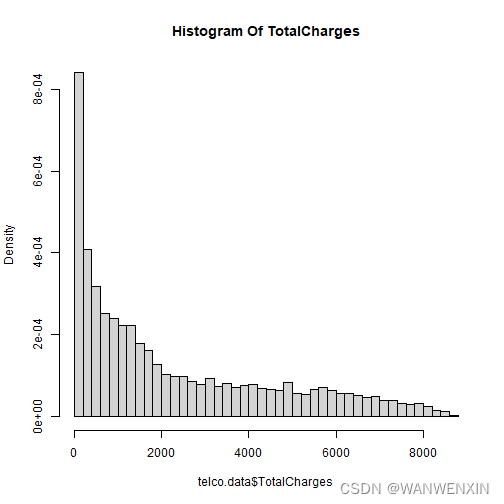
从直方图可知,TotalCharges数据呈偏态分布。根据正态分布选均值、中位数填充,偏态分布选中位数填充的原则,选择用TotalCharges列的中位数去填充这11个缺失值。
> hist(telco.data$TotalCharges, breaks = 50, prob = TRUE,
+ main = "Histogram Of TotalCharges")
> library(Hmisc)
> # 插补中位数
> telco.data$TotalCharges <- as.numeric(Hmisc::impute(telco.data$TotalCharges, median))
4.3 简化分类变量的属性值
OnlineSecurity、OnlineBackup、DeviceProtection、TechSupport、StreamingTV、StreamingMovies这六个变量的属性值有Yes、No、No internet serive 三种。
通过分析这六个变量和Churn生成的二维列联表,不难发现"No internetserive"出现 的频数是一致的,可以认为该属性值不影响客户流失率,所以简化属性值,将其并入"No"这一属性值。
> for(i in 10:15)
+ {
+ print(xtabs(~ Churn + get(names(telco.data)[i]), data = telco.data))
+ }
结果如下:
get(names(telco.data)[i])
Churn No No internet service Yes
No 2037 1413 1724
Yes 1461 113 295
get(names(telco.data)[i])
Churn No No internet service Yes
No 1855 1413 1906
Yes 1233 113 523
get(names(telco.data)[i])
Churn No No internet service Yes
No 1884 1413 1877
Yes 1211 113 545
get(names(telco.data)[i])
Churn No No internet service Yes
No 2027 1413 1734
Yes 1446 113 310
get(names(telco.data)[i])
Churn No No internet service Yes
No 1868 1413 1893
Yes 942 113 814
get(names(telco.data)[i])
Churn No No internet service Yes
No 1847 1413 1914
Yes 938 113 818
> # 将“No internetserive”并入“No”这一属性值
> levels(telco.data$OnlineSecurity)[2] <- "No"
> levels(telco.data$OnlineBackup)[2] <- "No"
> levels(telco.data$DeviceProtection)[2] <- "No"
> levels(telco.data$TechSupport)[2] <- "No"
> levels(telco.data$StreamingTV)[2] <- "No"
> levels(telco.data$StreamingMovies)[2] <- "No"
4.4 处理"量纲差异大"
目前属于这类特征的变量有:MonthlyCharges和TotalCharges。我打算采用连续特征离散化的处理方式。原因是离散化后的特征对异常数据有更强的鲁棒性,降低过拟合的风险,模型会更稳定,预测的效果也会更好。
数据离散化也称为分箱操作,其方法分为有监督分箱(卡方分箱、最小熵法分箱)和无监督分箱(等频分箱、等距分箱)。 本次为采用无监督分箱中的等频分箱进行操作。
> library(Hmisc)
> describe(telco.data[c("MonthlyCharges","TotalCharges")])
telco.data[c("MonthlyCharges", "TotalCharges")]
2 Variables 7043 Observations
-----------------------------------------------------------------------------------
MonthlyCharges
n missing distinct Info Mean Gmd .05 .10 .25
7043 0 1585 1 64.76 34.39 19.65 20.05 35.50
.50 .75 .90 .95
70.35 89.85 102.60 107.40
lowest : 18.25 18.40 18.55 18.70 18.75, highest: 118.20 118.35 118.60 118.65 118.75
-----------------------------------------------------------------------------------
TotalCharges
n missing distinct Info Mean Gmd .05 .10 .25
7043 0 6531 1 2282 2447 49.65 84.61 402.23
.50 .75 .90 .95
1397.47 3786.60 5973.69 6921.02
lowest : 18.80 18.85 18.90 19.00 19.05, highest: 8564.75 8594.40 8670.10 8672.45 8684.80
-----------------------------------------------------------------------------------
> #根据描述性统计量将变量按0.25,0.5,0.75分位数分成4份
> c_u_t <- function(x, n = 1) {
+ result <- quantile(x, probs = seq(0, 1, 1/n))
+ result[1] <- result[1]-0.001
+ return(result)
+ }
> telco.data <- transform(telco.data,
+ MonthlyCharges_c = cut(telco.data$MonthlyCharges,
+ breaks =c_u_t(telco.data$MonthlyCharges, n=4),
+ labels = c(1,2,3,4)),
+ TotalCharges_c = cut(telco.data$TotalCharges,
+ breaks = c_u_t(telco.data$TotalCharges, n=4),
+ labels = c(1,2,3,4)))
> telco.data <- within(telco.data, {
+ MonthlyCharges_c <- relevel(MonthlyCharges_c, ref = 1)
+ TotalCharges_c <- relevel(TotalCharges_c, ref = 1)
+ })
5 探索性数据分析
查看流失客户的数量和占比,由图可知,客户流失率约为26.54%。
> table(telco.data$Churn)
No Yes
5174 1869
> library(ggplot2)
> options(digits=4)
> ggplot(telco.data, aes(x = "" ,fill = Churn))+
+ geom_bar(stat = "count", width = 0.5, position = 'stack')+
+ coord_polar(theta = "y", start=0)+
+ geom_text(stat="count",
+ aes(label = scales::percent(..count../nrow(telco.data), 0.01)),
+ size=4, position=position_stack(vjust = 0.5)) +
+ theme(
+ panel.background = element_blank(),
+ axis.title = element_blank(),
+ axis.text = element_blank(),
+ axis.ticks = element_blank()
+ )

5.1 用户特征与流失的关系
根据数据集描述,将变量划分为用户属性、服务属性、合同属性,并从这三个维度进行分析。
用户属性
- 人口统计指标:‘gender’,‘SeniorCitizen’,‘Partner’,‘Dependents’
- 用户活跃度:‘tenure’
服务属性
- 手机服务:‘PhoneService’, ‘MultipleLines’
- 网络服务:‘InternetService’,‘OnlineSecurity’,‘OnlineBackup’, ‘DeviceProtection’,‘TechSupport’, ‘StreamingTV’,‘StreamingMovies’
合同属性
‘MonthlyCharges’,‘TotalCharges’, ‘Contract’, ‘PaperlessBilling’, ‘PaymentMethod’
5.1.1 用户属性分析
用户属性包括:‘gender’,‘SeniorCitizen’,‘Partner’,‘Dependents’,‘tenure’。
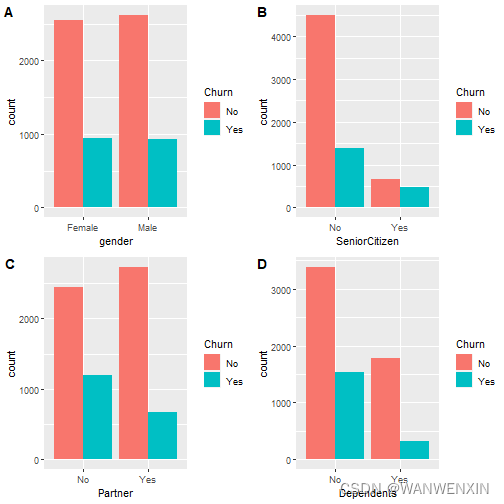
从图中可以得出以下结论:
- 性别对客户流失并无显著影响;
- 老年群体相较于其他群体,客户流失率较高;
- 无伴侣的客户流失率高于有伴侣的客户流失率;
- 无亲属的客户流失率高于有亲属的客户流失率。
说明增加关联客户数量的产品有利于增加客户的忠诚度,减小客户流失。
> library(cowplot)
> p1 <- ggplot(telco.data, aes(x = gender, fill = Churn)) +
+ geom_bar(stat = 'count',position = "dodge")
> p2 <- ggplot(telco.data, aes(x = SeniorCitizen, fill = Churn)) +
+ geom_bar(stat = 'count',position = "dodge")
> p3 <- ggplot(telco.data, aes(x = Partner, fill = Churn)) +
+ geom_bar(stat = 'count',position = "dodge")
> p4 <- ggplot(telco.data, aes(x = Dependents, fill = Churn)) +
+ geom_bar(stat = 'count',position = "dodge")
> cowplot::plot_grid(p1, p2, p3, p4, nrow = 2, labels = LETTERS[1:4])
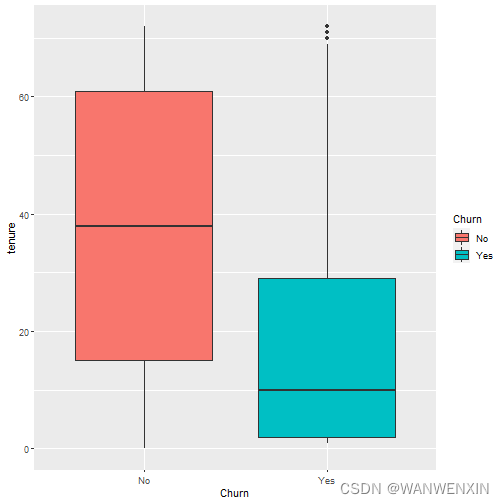
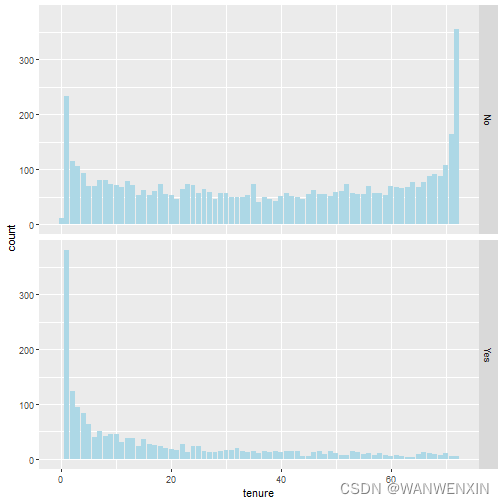
从用户活跃度即在网时长’tenure’来看,流失客户的在网时间较短,平均为10个月,且呈左偏分布;在网时间越长,客户流失率越低。
> ggplot(telco.data, aes(x = Churn, y = tenure)) + geom_boxplot(aes(fill = Churn))
> ggplot(telco.data, aes(x = tenure)) + geom_bar(fill = "lightblue") + facet_grid(Churn ~ .)
5.1.2 服务属性分析
服务属性
手机服务:‘PhoneService’, ‘MultipleLines’
网络服务:‘InternetService’,‘OnlineSecurity’,‘OnlineBackup’, ‘DeviceProtection’,‘TechSupport’, ‘StreamingTV’,‘StreamingMovies’
> p <- apply(telco.data, 2, function(R){
+ ggplot(telco.data) + aes(x = R, fill = Churn) + geom_bar(stat = 'count',position = "fill")
+ })
> p5 <- p['PhoneService']$PhoneService + labs(x = "PhoneService")
> p6 <- p['MultipleLines']$MultipleLines + labs(x = "MultipleLines")
> p7 <- p['InternetService']$InternetService + labs(x = "InternetService")
> p8 <- p['OnlineSecurity']$OnlineSecurity + labs(x = "OnlineSecurity")
> p9 <- p['OnlineBackup']$OnlineBackup + labs(x = "OnlineBackup")
> p10 <- p['DeviceProtection']$DeviceProtection + labs(x = "DeviceProtection")
> p11 <- p['TechSupport']$TechSupport + labs(x = "TechSupport")
> p12 <- p['StreamingTV']$StreamingTV + labs(x = "StreamingTV")
> p13 <- p['StreamingMovies']$StreamingMovies + labs(x = "StreamingMovies")
> cowplot::plot_grid(p5, p6, p7, nrow = 2)

> cowplot::plot_grid(p8, p9, p10, p11, p12, p13, nrow = 2)

由图可知:
- PhoneService电话服务对客户流失率影响不大。
- 开通多线通话服务的客户相比其他两类客户,流失率较高,可能是因为多条通话渠道导致的费用升高而且功能过剩。
- 开通Fiber optic光纤服务的客户流失率远高于开通DSL数字网络的客户流失率,这说明光纤服务是导致开通网络服务的客户流失的主要原因,需要进一步调查客户对光纤服务的反馈。总体而言,开通网络服务的客户流失率偏高。
- 在技术性服务(OnlineSecurity、OnlineBackup、DeviceProtection、TechSupport)中,开通的客户流失率均比整体流失率26.54%低,而未开通的则高出整体流失率不少。
- 在娱乐性服务(StreamingTV、StreamingMovies)中,开通的客户流失率都比未开通的高。
5.1.3 合同属性分析
合同属性包括:
‘MonthlyCharges’,‘TotalCharges’, ‘Contract’, ‘PaperlessBilling’, ‘PaymentMethod’。
> p14 <- p['Contract']$Contract + labs(x = 'Contract')
> p15 <- p['PaperlessBilling']$'PaperlessBilling' + labs(x = 'PaperlessBilling')
> p16 <- p['PaymentMethod']$PaymentMethod + labs(x = 'PaymentMethod')
> cowplot::plot_grid(p14, p15, p16, nrow = 3)
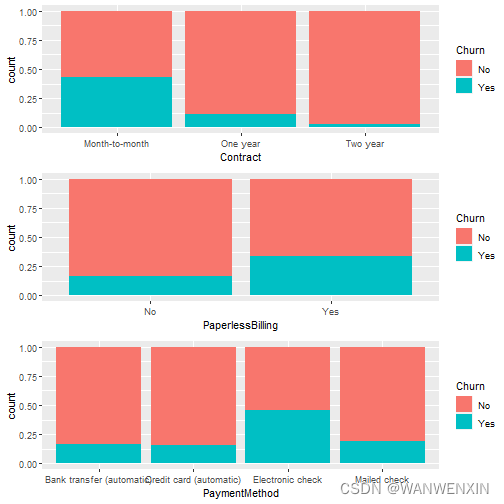
由图可知:
- 在签订合同上,按月签约的客户流失率最高,并且签约时间越长,客户流失率越低。这说明,按月签约的客户对产品的粘性不高。
- 在是否开通电子账单上,选择电子账单的客户流失率高于选择纸账单的客户流失率。
- 在支付方式上,选择Electronic check支付方式的客户流失率最高,其他三种流失率 差别不大。可以进一步调查选择Electronic check支付方式的客户,了解流失原因。
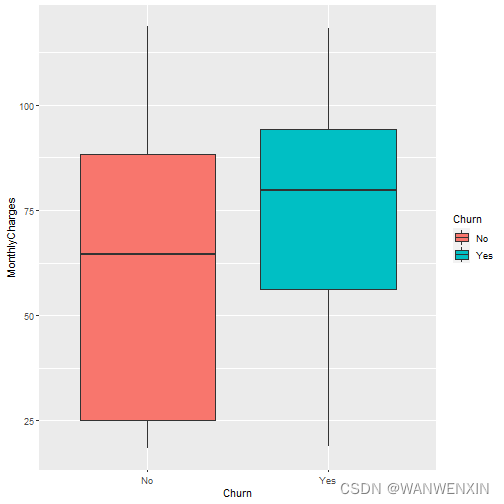
> ggplot(telco.data, aes(x = Churn, y = MonthlyCharges)) + geom_boxplot(aes(fill = Churn))
> p17 <- ggplot(telco.data, aes(x = MonthlyCharges, fill= Churn, alpha = 0.5)) +
+ geom_density()
> p18 <- ggplot(telco.data, aes(x = TotalCharges, fill= Churn, alpha = 0.5)) +
+ geom_density()
> cowplot::plot_grid(p17, p18, nrow = 2)

由图可知,在月租费方面,流失客户的月租费整体水平要高于非流失客户; 月租费金额大约在70-100元的客户流失率较高。
5.2 流失客户普遍具有的特征
从用户属性来看,老年群体、无伴侣、无亲属、在网时间小于10个月的客户流失率较高。
从服务属性来看,开通多线通话服务、开通Fiber optic光纤服务、未开通技术性服 务(OnlineSecurity、OnlineBackup、DeviceProtection、TechSupport)、开通娱乐性服务(StreamingTV、StreamingMovies)的客户流失率较高。
从合同属性来看,按月签约、开通电子账单、选择Electronic check支付方式、月租 费70-100元的客户流失率较高。
6 电信客户流失预测模型
6.1 特征选择
经过上文的分析,目前认为与客户流失率关联较小的变量有:gender、PhoneService,而customerID是随机数,不影响建模,故可以筛选掉。
观察变量之间的相关性。
首先对分类变量进行相关性分析,一般使用卡方检验。
在分类变量和目标变量Churn的卡方检验中,gender的P值为0.49,PhoneService的p值为 0.35,其他分类变量的P值都远小于0.01,所以不能拒绝gender、PhoneService和Churn相互独立的原假设,应被筛选掉。
> sapply(telco.data[c(-1, -6, -19, -20, -21)], function(x){
+ ch <- chisq.test(x, telco.data$Churn, simulate.p.value = T)
+ list(chi_v=ch$statistic, p=ch$p.value)
+ })
gender SeniorCitizen Partner Dependents PhoneService MultipleLines
chi_v 0.5224 160.4 159.4 189.9 1.004 11.33
p 0.4748 0.0004998 0.0004998 0.0004998 0.3388 0.005997
InternetService OnlineSecurity OnlineBackup DeviceProtection TechSupport
chi_v 732.3 206.5 47.65 30.83 191
p 0.0004998 0.0004998 0.0004998 0.0004998 0.0004998
StreamingTV StreamingMovies Contract PaperlessBilling PaymentMethod
chi_v 28.16 26.54 1185 259.2 648.1
p 0.0004998 0.0004998 0.0004998 0.0004998 0.0004998
MonthlyCharges_c TotalCharges_c
chi_v 359.8 400.1
p 0.0004998 0.0004998
其次,观察连续变量之间的相关性。
tenure和TotalCharges的相关性为0.83,是强相关,去掉TotalCharges保留tenure方便计算。
> # 计算相关矩阵
> telco.cor <- cor(telco.data[,c('tenure','MonthlyCharges','TotalCharges')])
> round(telco.cor, digits = 2)
tenure MonthlyCharges TotalCharges
tenure 1.00 0.25 0.83
MonthlyCharges 0.25 1.00 0.65
TotalCharges 0.83 0.65 1.00
最终,customerID、gender、PhoneService和TotalCharges被筛出掉。
> telco <- telco.data[,c(-1, -2, -7, -19, -20, -23)]
> head(telco)
SeniorCitizen Partner Dependents tenure MultipleLines InternetService
1 No Yes No 1 No phone service DSL
2 No No No 34 No DSL
3 No No No 2 No DSL
4 No No No 45 No phone service DSL
5 No No No 2 No Fiber optic
6 No No No 8 Yes Fiber optic
OnlineSecurity OnlineBackup DeviceProtection TechSupport StreamingTV
1 No Yes No No No
2 Yes No Yes No No
3 Yes Yes No No No
4 Yes No Yes Yes No
5 No No No No No
6 No No Yes No Yes
StreamingMovies Contract PaperlessBilling PaymentMethod Churn
1 No Month-to-month Yes Electronic check No
2 No One year No Mailed check No
3 No Month-to-month Yes Mailed check Yes
4 No One year No Bank transfer (automatic) No
5 No Month-to-month Yes Electronic check Yes
6 Yes Month-to-month Yes Electronic check Yes
MonthlyCharges_c
1 1
2 2
3 2
4 2
5 3
6 4
6.2 划分数据集
数据集中,流失客户有1869个样本,未流失客户有5174个样本。
按照7:3划分训练集和测试集,用于模型的训练和有效性的评估。
> set.seed(123)
> train <- sample(nrow(telco), 0.7*nrow(telco))
> telco.train <- telco[train,]
> telco.test <- telco[-train,]
> table(telco.train$Churn)
No Yes
3577 1353
> table(telco.test$Churn)
No Yes
1597 516
6.3 构建分类器并进行模型评估
采用决策树、随机森林、支持向量机、逻辑回归四个模型。
观察模型的准确度、精确度、召回率、特异度、f1值,绘制ROC曲线图,计算AOC值。
> # 定义分类器性能标准
> library(pROC)
> telco_prediction <- function(algorithm, prob, test = telco.test, n = 2){
+ pred <- predict(algorithm, telco.test, type = "class")
+ table <- table(telco.test$Churn, pred)
+ if(!all(dim(table)==c(2,2)))
+ stop("Must be a 2 x 2 table")
+ tn = table[1,1]
+ fp = table[1,2]
+ fn = table[2,1]
+ tp = table[2,2]
+ accuracy = round((tn+tp)/(tn+fp+fn+tp),n)
+ precision = round(tp/(tp+fp),n)
+ sensitivity = round(tp/(tp+fn),n)
+ specificity = round(tn/(tn+fp),n)
+ f1_score = round((2*precision*sensitivity)/(precision+sensitivity),n)
+ # 绘制ROC
+ modelroc <- roc(telco.test$Churn, prob[,2])
+ plot(modelroc, print.auc=TRUE, auc.polygon=TRUE,legacy.axes=TRUE,
+ grid=c(0.1, 0.2),
+ grid.col=c("green", "red"), max.auc.polygon=TRUE,
+ auc.polygon.col="skyblue", print.thres=TRUE)
+ auc <- auc(modelroc)
+ # 输出指标
+ data.frame(accuracy, precision, sensitivity, specificity, f1_score, auc)
+ }
6.3.1 决策树
在建立决策树之后,可以打印决策树的复杂性参数cp,观察决策树的误差等数据。 cp是参数复杂度(complexity parameter)作为控制树规模的惩罚因子,cp越大, 树分裂规模(nsplit)越小。
输出参数(rel error)指示了当前分类模型树与空树之间的平均偏差比值。
xerror为交叉验证误差,xstd为交叉验证误差的标准差。
可以看到,当cp为0.01的时候,交叉误差最小。
而决策树剪枝的目的就是为了得到更小交叉误差(xerror)的树。
> library(rpart)
> set.seed(123)
> dtree <- rpart(Churn~., data = telco.train, method = "class",
+ parms = list(split="information"))
> dtree$cptable
CP nsplit rel error xerror xstd
1 0.06245 0 1.0000 1.0000 0.02316
2 0.01000 3 0.7871 0.8086 0.02156
> # 按3次分割对应的复杂度参数0.01剪枝
> dtree.pruned <- prune(dtree, cp=0.01)
> # 绘制决策树
> library(partykit)
> plot(as.party(dtree.pruned), main = "Decision Tree")

> dtree.prob <- predict(dtree.pruned, telco.test, type="prob")
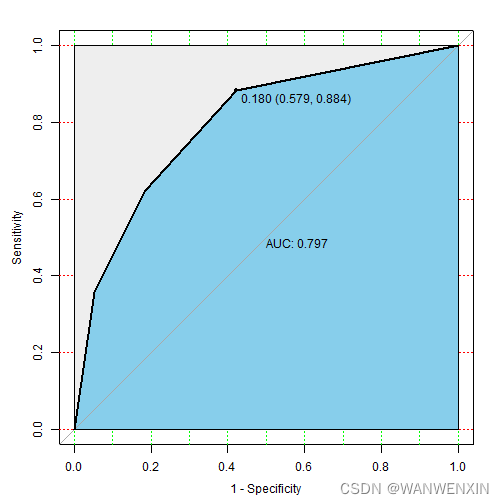
> telco_prediction(dtree.pruned, dtree.prob, telco.test, 2)
accuracy precision sensitivity specificity f1_score auc
1 0.8 0.68 0.36 0.95 0.47 0.7972
6.3.2 随机森林
随机森林就是通过集成学习的思想将多棵树集成的一种算法,它的基本单元是决策树。随机森林是通过自助法重复抽样技术,从原始样本训练集中有放回地随机抽取k个样本生成新的训练集样本集合,然后根据自助样本集生成k个决策树组成的随机森林,最后根据所有决策树的预测结果来最终确定样本的预测结果。
randomForest()函数中的两个重要参数为ntree和mtry,其中ntree为基分类器个数,默认为500;mtry为每个决策树包含的变量个数,默认为logN,数据量不大时可以循环选择最优参数值。
> library(randomForest)
> set.seed(123)
> # 选择mtry
> err <- as.numeric()
> for(i in 1:(length(names(telco.train)))-1){
+ mtry_test <- randomForest(Churn~., data = telco.train, mtry=i)
+ err <- append(err, mean(mtry_test$err.rate))
+ }
> print(err)
[1] 0.3500 0.3479 0.2722 0.2769 0.2802 0.2837 0.2783 0.2784 0.2799 0.2817 0.2812
[12] 0.2831 0.2829 0.2849 0.2843 0.2829 0.2876
> mtry <- which.min(err)
> mtry
[1] 3
> # 选择ntree
> ntree_fit <- randomForest(Churn~., data = telco.train, mtry=mtry, ntree=1000)
> plot(ntree_fit)

发现,mtry取3时err最小,ntree取500时误差趋于稳定。 因此,得到最终分类器,观察模型效果。
> set.seed(123)
> fit.rf <- randomForest(Churn~., data = telco.train, mtry = 3,
+ ntree= 500)
> rf.prob <- predict(fit.rf, telco.test, type="prob")
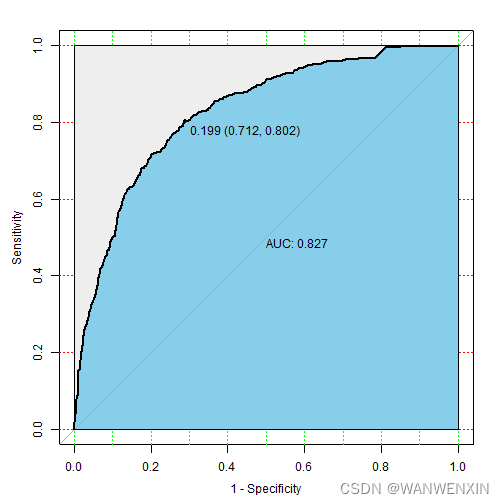
> telco_prediction(fit.rf, rf.prob, telco.test, 2)
accuracy precision sensitivity specificity f1_score auc
1 0.8 0.62 0.5 0.9 0.55 0.8269
6.3.3 支持向量机
支持向量机,一般简称SVM,通俗来讲,它是一种二类分类模型,其基本模型定义为特征空间上的间隔最大的线性分类器,其学习策略便是间隔最大化,最终可转化为一个凸二次规划问题的求解。
kernel指定建模过程中使用的核函数,目的在于解决支持向量机线性不可分问题。有四类核函数可选,即线性核函数、多项式核函数、径向基核函数(高斯核函数)和神经网络核函数。研究人员发现,识别率最高,性能最好的是径向基核函数(默认的kernel值),其次是多项式核函数,最差的是神经网络核函数。
> library(e1071)
> set.seed(123)
> fit.svm <- svm(Churn~., data =telco.train, probability=TRUE)
> pred.svm <- predict(fit.svm, telco.test, probability=TRUE)
> svm.prob <- attr(pred.svm, "probabilities")
> telco_prediction(fit.svm, svm.prob, telco.test, 2)
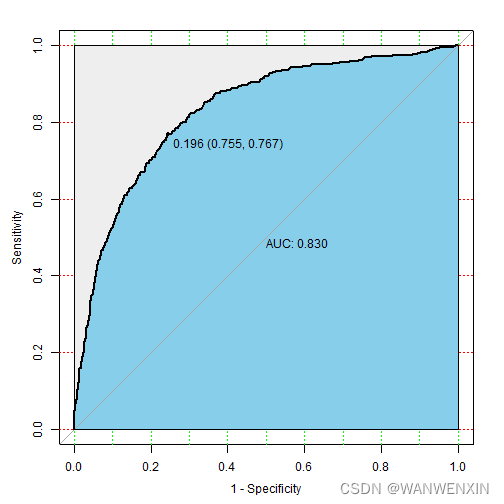
accuracy precision sensitivity specificity f1_score auc
1 0.81 0.67 0.47 0.92 0.55 0.8295
6.3.4 Logistic回归分析
数据集中自变量较多,为了使构建的Logistic回归模型比较稳定和便于解释,应尽可能地剔除对回归模型贡献程度很小的变量。
首先在训练集上使用所有自变量建立一个模型,然后使用逐步法构建一个模型,通过F检验对两个模型进行方差分析,评估两个模型是否有显著不同。
> full.fit <- glm(Churn~.,data = telco.train, family = binomial())
> summary(full.fit)
> both.fit <- step(full.fit,direction = "both")
> summary(both.fit)
> anova(full.fit, both.fit, test = "Chisq")
Analysis of Deviance Table
Model 1: Churn ~ SeniorCitizen + Partner + Dependents + tenure + MultipleLines +
InternetService + OnlineSecurity + OnlineBackup + DeviceProtection +
TechSupport + StreamingTV + StreamingMovies + Contract +
PaperlessBilling + PaymentMethod + MonthlyCharges_c
Model 2: Churn ~ SeniorCitizen + Dependents + tenure + MultipleLines +
InternetService + OnlineSecurity + OnlineBackup + TechSupport +
StreamingTV + StreamingMovies + Contract + PaperlessBilling +
PaymentMethod
Resid. Df Resid. Dev Df Deviance Pr(>Chi)
1 4906 4159
2 4911 4162 -5 -2.92 0.71
由结果可知,两者的差距并不显著。后续利用both.fit该模型进行分析。
使用exp(coef())函数计算优势比,优势比可以解释为特征中1个单位的变化导致的结果发生比的变化。如果系数大于1,则说明当特征的值增加时,结果的发生比会增加。反之,系数小于1就说明,当特征的值增加时,结果的发生比会减小。
> # 查看优势比
> exp(coef(both.fit))
(Intercept) SeniorCitizenYes
0.5414 1.1781
DependentsYes tenure
0.7990 0.9670
MultipleLinesNo phone service MultipleLinesYes
1.5816 1.2939
InternetServiceFiber optic InternetServiceNo
2.3627 0.4557
OnlineSecurityYes OnlineBackupYes
0.6831 0.8750
TechSupportYes StreamingTVYes
0.7126 1.3219
StreamingMoviesYes ContractOne year
1.3802 0.5219
ContractTwo year PaperlessBillingYes
0.2259 1.4270
PaymentMethodCredit card (automatic) PaymentMethodElectronic check
0.9150 1.3394
PaymentMethodMailed check
0.9616
both.fit模型输出的是Churn=Yes时的概率。
可以看到,在保持其他变量不变的情况下:
- 开通Fiber optic互联网服务的客户流失风险是开通DSL服务的2.4倍,而未开通互联网服务的客户流失风险是开通DSL服务的0.5倍,所以,未开通互联网服务的客服流失风险最低;
- 按一年签订合同的客户流失风险是按月签订合同的0.5倍,按两年签订合同的客户流失风险是按月签订合同的0.2倍,所以签订合同的期限越长,客户流失的风险越低。
之后利用构建的模型进行预测。
> library(pROC)
> glm.prob <- predict.glm(both.fit, telco.test, type = "response")
> glm.class <- ifelse(glm.prob > 0.5, "Yes", "No")
> telco.test$predict <- glm.class
> true.value <- telco.test[,16]
> predict.value <- telco.test[,18]
> # 混淆矩阵
> table <- table(true.value,predict.value)
> tn = table[1,1]
> fp = table[1,2]
> fn = table[2,1]
> tp = table[2,2]
> accuracy = round((tn+tp)/(tn+fp+fn+tp),2)
> precision = round(tp/(tp+fp),2)
> sensitivity = round(tp/(tp+fn),2)
> specificity = round(tn/(tn+fp),2)
> f1_score = round((2*precision*sensitivity)/(precision+sensitivity),2)
> # 绘制ROC
> modelroc <- roc(true.value, glm.prob)
> plot(modelroc, print.auc=TRUE, auc.polygon=TRUE,legacy.axes=TRUE,
+ grid=c(0.1, 0.2),
+ grid.col=c("green", "red"), max.auc.polygon=TRUE,
+ auc.polygon.col="skyblue", print.thres=TRUE)
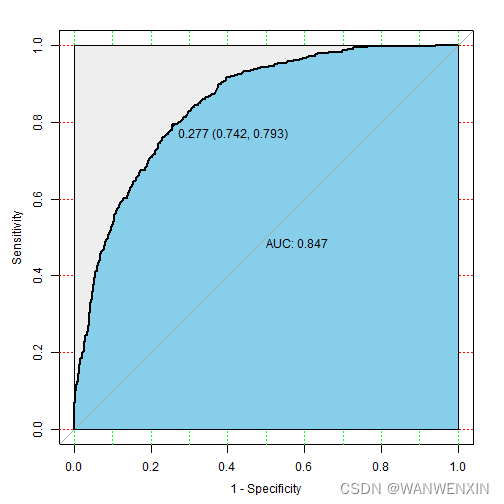
> auc <- auc(modelroc)
> # 输出指标
> data.frame(accuracy, precision, sensitivity, specificity, f1_score, auc)
accuracy precision sensitivity specificity f1_score auc
1 0.81 0.63 0.55 0.9 0.59 0.847
6.4 输出特征重要性
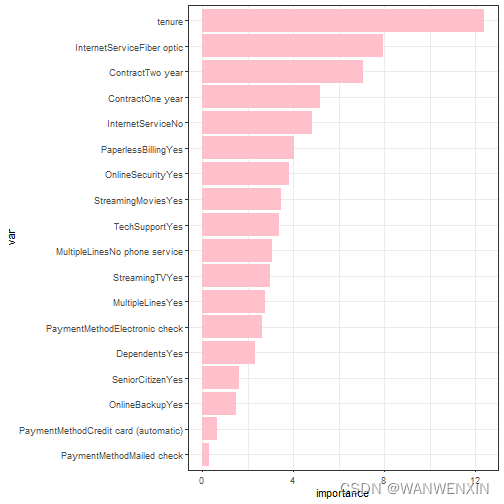
上述四个分类器的准确率都达到了80%以上,但由于正负样本比例不均衡,所以,accuracy不能客观评价算法的优劣。
从结果来看,Logistic回归模型的sensitivity、f1值和auc值都较高,因此基于Logistic回归模型,输出特征重要性。
±---------------±---------±----------±------------±------------±---------±-------+
| 模型 | accuracy | precision | sensitivity | specificity | f1_score | auc
±-----------------±---------±----------±------------±------------±---------±-------+
| 决策树 | 0.8 | 0.68 | 0.36 | 0.95 | 0.47 | 0.7972 |
±-----------------±---------±----------±------------±------------±---------±-------+
| 随机森林 | 0.8 | 0.62 | 0.5 | 0.9 | 0.55 | 0.8269 |
±-----------------±---------±----------±------------±------------±---------±-------+
| SVM | 0.81 | 0.67 | 0.47 | 0.92 | 0.55 | 0.8295 |
±-----------------±---------±----------±------------±------------±---------±-------+
| Logistic回归分析 | 0.81 | 0.63 | 0.55 | 0.9 | 0.59 | 0.847 |
±-----------------±---------±----------±------------±------------±---------±-------+
> library(caret)
> library(ggplot2)
> library(dplyr)
> importance <- caret::varImp(both.fit, scale = FALSE)
> importance$var <- row.names(importance)
> imp <- importance %>%
+ mutate(var = factor(var, levels = var[order(Overall)]))
> ggplot(imp, aes(x = Overall, y=var)) + geom_bar(stat = "identity", fill = 'pink')+ theme_bw() + labs(x = "importance")
7 运营建议
根据预测模型,构建一个潜在流失客户的列表。通过用户调研,详细了解客户对产品不满意的方面。
7.1 用户层面
- 针对老年用户、无亲属、无伴侣用户,制定专属的个性化服务,如推出亲属套餐、温暖套餐等,提升用户的满意度。
- 可以为其提供签到积分换购、会员日充值优惠等活动。
7.2 服务层面
- 针对新注册客户,降低第一年的月租费,以此渡过用户的流失高峰期。
- 重点改善“光纤网络”服务。
- 针对开通互联网服务、网络电视服务或电影服务的客户,提升网络体验,完善增值服务,例如对用户承诺免费提供网络升级的服务。
- 针对开通在线安全、在线备份、设备保护、技术支持等增值服务,对客户大力推广,可对其给予优惠,如首月免费体验、满减券等,鼓励客户使用增值服务。
7.3 合同层面
- 针对单月合同用户,可推出“充值返钱”的活动,例如充值50返120,分6个月返,将月用户转化为半年用户,提高用户的在网时长,增加用户的黏性。
- 减少目前月租费在70-110元客户的部分费用,或采用赠送充值话费抵扣券的活动,以降低流失率。