一些bug
Python DataFrame 的 append() 方法无效_萌宅鹿同学的博客-CSDN博客_pythonappend用不了
(这个真的搞了好久可烦死我了,append之后没有数据,然后寻思转成numpy吧,又运行的超级慢!!!)
机器学习模型fit model时报错:" ValueError: Input contains NaN, infinity or a value too large for dtype('float32'64) "
数据中有缺失值啥的,运行下面的代码可以解决:
df = df.drop_duplicates(keep='first')
df = df.dropna(axis=0, how='any')---------------------------------------------------------------------------------------------------------------------------------redis.exceptions.ConnectionError: Error 10061 connecting to localhost:6379. 由于目标计算机积极拒绝,无法连接-pudn.com当运行出现如下报错的时候,可以按照上面链接操作一下,完美解决我的问题!!
redis.exceptions.ConnectionError: Error 10061 connecting to localhost:6379. 由于目标计算机积极拒绝,无法连接
--------------------------------------------------------------------------------------------------------------------------------
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xbc in position 0: invalid start byte
解决方法:encoding="gbk"
---------------------------------------------------------------------------------------------------------------------------------
read_pickle选择特定列:
使用usecols报错。
解决方法:从pickle文件中读取特定列 - 问答 - Python中文网
df = pd.read_pickle('data.pkl')
df = df.filter(['a', 'b', 'c'])--------------------------------------------------------------------------------------------------------------------------------
看linux服务器上文件的最后修改时间:
在Linux中如何查看文件的修改日期 - 知乎
stat 服务器上的文件路径
--------------------------------------------------------------------------------------------------------------------------------
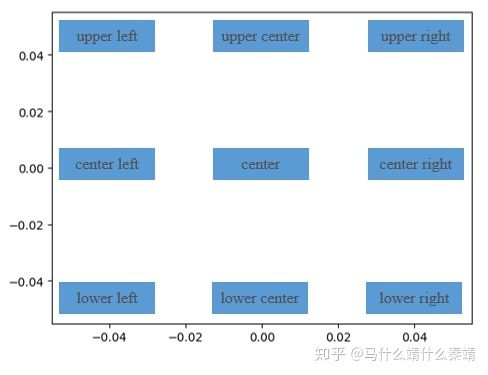
plt.legend() 方位图
--------------------------------------------------------------------------------------------------------------------------------
pycharm本地文件上传linux服务器特定文件夹
我遇到的问题是每次都上传到我名字下面而不是我名字下面新建的文件夹。
修改方式:
Tools ——>Deployment——>Mappings——>Deployment path 改成想要的文件夹路径
如何利用Pycharm将工程文件上传到服务器_褚峤松的博客-CSDN博客_pycharm上传文件到服务器
---------------------------------------------------------------------------------------------------------------------------------
本地和服务器文件/文件夹上传、下载
从服务器上把文件复制到本地_rainbowcode的博客-CSDN博客_怎么从服务器拷贝到本地
---------------------------------------------------------------------------------------------------------------------------------
from sklearn.externals import joblib
cannot import name 'joblib' from 'sklearn.externals'
直接改成import joblib
---------------------------------------------------------------------------------------------------------------------------------
Python按行打乱csv文件
import pandas as pd
import os
from sklearn.utils import shuffle
data = pd.read_csv('data.csv')
data = shuffle(data) # 打乱
data.to_csv('data_shuffle.csv')