【有坑待填】Maskrcnn mmdetection 人像 分割结果 抠图 二值化 原图提取 像素点操作
待填:1.关于result实际意义的讨论
2.len、size、shape的用法
简介: 基于mmdetection的架构,在其demo给出的范例代码中,我们应用maskrcnn算法,从github上mmdetection的官方文档中,下载了maskrcnn的预训练模型
mask_rcnn_r50_fpn_mstrain-poly_3x_coco_20210524_201154-21b550bb.pth
然后在官方给出的demo中,进行修改,完成了单张图片的(人物)分割测试,同时抠出单个人像,详情如下:
!!看代码注释!
1.加载预训练模型并输出单张图片的分割结果
from torch import device
import torch
import os
from PIL import Image
import numpy as np
from mmdet.apis import init_detector,show_result_pyplot,inference_detector
#配置文件,根据不同的算法选择不同配置文件
config_file ='configs/mask_rcnn/mask_rcnn_r50_fpn_mstrain-poly_3x_coco.py'
#预训练模型加载路径,需提前从github mmdetection的库中提前下载
checkpoint_file = 'checkpoints/mask_rcnn_r50_fpn_mstrain-poly_3x_coco_20210524_201154-21b550bb.pth'
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
model = init_detector(config_file, checkpoint_file, device=device)
img_file ='demo/pic1.jpg'
savepath='runs/'
#进行推理 result为推理结果
result = inference_detector(model, img_file)
out_file = os.path.join(savepath, 'pic1.jpg')
#推理结果可视化
show_result_pyplot(model, img_file, result,score_thr=0.9,out_file=out_file)输出结果如图:

2.通过推理结果来抠图
image = Image.open("demo/pic1.jpg")
#将图片转换为numpy数组
np_img = np.array(image)
#图片分辨率为640*854,result[1][0][0]的大小是854*640
#通过判断result的bool类型值,来判断某一像素点是否需要被抠出
#若需要被抠出,则保留原像素值;否则,将该点像素值置为[255,255,255],即纯白背景
for i in range (0,854):
for j in range(0,640):
if result[1][0][0][i,j]== False:
np_img[i,j] = [255,255,255]
#格式转换操作,确保可以从numpy数组转换为img
np_img = np_img.astype(np.uint8)
#numpy转换为img
img_kou = Image.fromarray(np_img)
img_kou.save('runs/kou1.jpg')#图片分辨率为640*854,result[1][0][0]的大小是854*640
#通过判断result的bool类型值,来判断某一像素点是否需要被抠出
#若需要被抠出,则保留原像素值;否则,将该点像素值置为[255,255,255],即纯白背景
效果如下

3.改进为黑白分割图片
image = Image.open("demo/pic1.jpg")
#将图片转换为numpy数组
np_img = np.array(image)
#图片分辨率为640*854,result[1][0][0]的大小是854*640
#通过判断result的bool类型值,来判断某一像素点是否需要被抠出
#若需要被抠出,则保留原像素值;否则,将该点像素值置为[255,255,255],即纯白背景
for i in range (0,854):
for j in range(0,640):
if result[1][0][0][i,j]== True:
np_img[i,j] = [255,255,255]
else:
np_img[i,j] = [0,0,0]
#格式转换操作,确保可以从numpy数组转换为img
np_img = np_img.astype(np.uint8)
#numpy转换为img
img_kou = Image.fromarray(np_img)
img_kou.save('runs/kou1.jpg')将result[1][0][0]中掩码为True的像素点置为白色,False置为黑色

一些讨论与反思:
1.关于result的讨论:
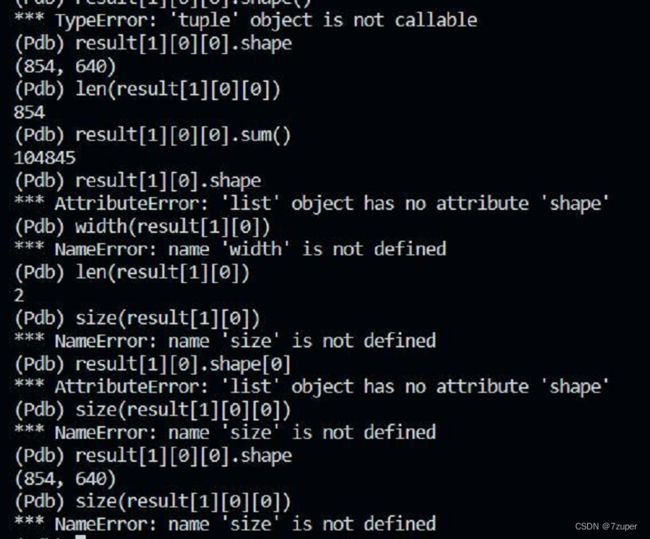
result的len为2,经过查找,初步确定reuslt[0]为检测框,result[1]为识别出的object,而result[0]和result[1]的长度均为80,因为本例程采用的是coco数据集格式,coco中共有80个可被检测出的类别,而第0类是人,所以我们选择result[1][0],此时result[1][0]表示图片中人物的mask的集合,经过命令result[1][0].shape,我们发现其结果为图片的分辨率(854,640),打印后,验证得知此时result[1][0]表示每一个像素点为人物的bool值(True or False)
坑:result的第三维度!!!代表着什么含义?为什么改变了之后,出现了肢体不同部分?
如下图:([0]是完整人体,下图分别是result第三维是[1][2][3])



2.关于numpy基本函数len、size、shape的讨论:
坑:
1.每一个变量都可以有len,但len不是实际个数,只代表行数?列数?
2.shape和size能不能用()?什么情况下可以使用?
代码总览如下:
from torch import device
import torch
import os
from PIL import Image
import numpy as np
from mmdet.apis import init_detector,show_result_pyplot,inference_detector
config_file ='configs/mask_rcnn/mask_rcnn_r50_fpn_mstrain-poly_3x_coco.py'
checkpoint_file = 'checkpoints/mask_rcnn_r50_fpn_mstrain-poly_3x_coco_20210524_201154-21b550bb.pth'
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
model = init_detector(config_file, checkpoint_file, device=device)
img_file ='demo/pic1.jpg'
savepath='runs/'
result = inference_detector(model, img_file)
image = Image.open("demo/pic1.jpg")
np_img = np.array(image)
for i in range (0,750):
for j in range(0,502):
if result[1][0][0][i,j]== False:
np_img[i,j] = [255,255,255]
np_img = np_img.astype(np.uint8)
img_kou = Image.fromarray(np_img)
img_kou.save('runs/kou1.jpg')
#import pdb ; pdb.set_trace()
out_file = os.path.join(savepath, 'pic1.jpg')
show_result_pyplot(model, img_file, result,score_thr=0.9,out_file=out_file)