实时障碍更新 局部路径寻优算法 矢量地图数据 局部路径规划解集_自动驾驶近期行为预测和规划的一些文章介绍(下)...

继续介绍最近公开的文章。
“Driving with Style: Inverse Reinforcement Learning in General-Purpose Planning for Automated Driving”
由于城市环境的场景复杂性高,行为规划器未能匹配预定义的行为模板这种不可预测的情况可能发生。最近,引入了通用规划器(general-purpose planner),将行为和局部运动规划相结合。给定单一奖励,这些通用规划器允许行为觉察的运动规划。然而,出现了两个挑战:首先,该功能必须将复杂的特征空间映射到奖励中。其次,奖励函数必须由专家手动调整。手动调整此奖励函数的工作变得繁琐。
本文提出一种依靠人类驾驶来自动调整奖励函数的方法。它为最大熵逆强化学习(maximum entropy inverse reinforcement learning)的通用规划器提供了驾驶风格优化的重要见解。
下图解释这里的自动驾驶通用规划器。可视化状态空间的颜色编码指示状态-动作的值(z-轴对应于速度)。 三种颜色编码策略:黑色表示规划的最佳策略,红色表示人类操作演示的里程表(odometry),绿色表示操作演示投影到状态空间。

与直接模仿和奖励学习等有监督学习方法相比,强化学习(RL)通过经验学习和与环境的互动来解决规划问题。其他交通参与者的意图预测可以通过多代理交互(multi-agent interactions)直接学习。
学习行为可能包括多个驾驶参与者的复杂谈判。目前大部分工作都侧重于模拟驾驶体验,并面临着从模拟到现实驾驶的挑战,特别是对城市场景。另一个挑战是如何在方法中制定功能安全性。目前IRL大部分都采用最大熵原理,通过梯度下降的概率模型训练,其中梯度计算取决于状态访问频率(state visitation frequency),通常类似强化学习的后向值迭代(backward value iteration)算法。由于维数诅咒(curse of dimensionality)问题,该算法对高维连续空间中的驾驶风格优化是难以实现的。
代理与环境的相互作用通常被表述为由5元组{S,A,T,R,γ}组成的马尔可夫决策过程(MDP),其中S表示状态集,A表示动作集合。对于s,s'∈S,a∈A,用转移函数T(s,a,s')使得连续动作a在时间t积分。奖励函数R为状态S的每个动作A分配奖励,其中奖励在时间t上被γ打折扣。
环境M的模型在状态s动作a执行之后返回特征向量fi和和结果状态s'。
奖励函数R由K个特征值fi与权重θi的线性组合给出,使得,∀(s,a)∈S×A:
策略π是一系列时间连续转移T,策略π的特征路径积分fiπ由下式定义
在环境模型M中迭代执行采样的状态-动作(state-action)集As可近似通路积分(path integral)。策略π的值Vπ是连续转移期间折现奖励的积分。最优策略π*具有最大累积值,
车辆行驶里程记录提供了人类操作演示ζ,里程表记录ζ在状态-动作(state-action)空间的投影将这种操作演示公式化为策略πD。
在每个规划周期,考虑一组在几何上接近里程记录ζ的操作演示ΠD。规划算法返回具有不同驾驶特性的有限策略集Π。最终选择的驾驶策略πS满足基于模型的约束。
下面这个功能流程图的规划系统利用MPC来讨论环境模型的更新:模块的左侧输入对应于前一个功能的输出。模块顶部的输入表示前一个功能的中间输出。粗实线表示从环境感知fp到驾驶轨迹ζ的主流。重点关注的是,影响奖励学习体系结构的深灰色块。模块之间的虚线连接指示训练过程中的信息流。数据收集过程记录了环境以及司机隐驾驶策略πH的里程数ζ。
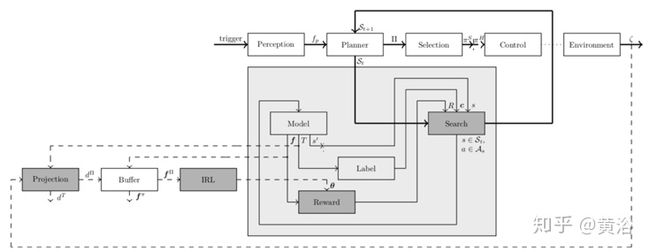
如下算法1正式描述了基于搜索的规划方法。规划器为指定的规划范围(planning horizon)H生成轨迹。为离散的转移长度(transition lengths)做规划可迭代地构建时间范围(the time horizon)H的轨迹。规划器用GPU并行地为所有状态s∈St采样一些离散的连续动作As。该分布是基于车辆约束条件计算的,并且近似表示了每个状态s几乎所有动态地可行动作。这些动作本身由时间连续的多项式函数表示:纵向动作由速度曲线描述,直到五阶多项式;横向动作由轮角的三阶多项式描述。
搜索算法针对所有状态s∈St调用环境M的模型,观察结果状态s',转移T和每个状态-动作元组(state-action tuple)的特征f。环境模型中时间连续动作整合生成特征向量f。 标注函数将类别标签分配给转换,例如与碰撞关联的标签。 修剪操作会限制下一个转移步骤t+1∈H的状态集St+1。基于价值V(s)、标签c和可访问集合St的属性修剪可终止低价值V的冗余状态(S)。 该算法类似于并行广度优先搜索(BSF)和前向值迭代。 基于策略价值V(π)和基于模型的约束选择最终驾驶策略πS。

在IRL公式中,找到在规划周期内最能描述人类操作演示πD∈ΠD的奖励函数权重θ,最大化策略集Π中专家行为的对数似然函数L,如下
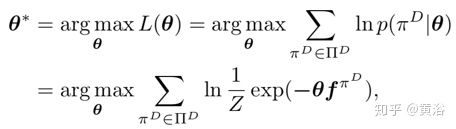
然后,在人类操作演示的特征路径积分fπ与研究策略的特征期望匹配的约束下,进行优化,即

对数似然函数的梯度可以推导如下

并做梯度下降优化。
下面是一个实验的规划性能结果:展示多个细分的训练和验证指标以及训练初始化示意图。 通过训练时最大熵IRL的收敛性与人类操作的预期距离缩小来验证训练结果。(a)左图是在学习的奖励功能下,人类驾驶操作期望值与规划器策略期望值之间的差异。(b)在学习的奖励功能下,规划器策略与人类驾驶示范的预期距离。

“Behavior Planning of Autonomous Cars with Social Perception”
自动驾驶汽车往往在充满不确定性的动态环境中航行。不确定性可能来自1)传感器限制,例如遮挡和有限的传感器范围,2)来自对其他车辆的概率预测,3)来自新地区未知的社会行为。在这些不确定性的情况下,为了安全有效地驾驶,自动驾驶的决策和规划模块应智能地利用所有可用信息并适当地解决不确定性,以便产生适当的驾驶策略。
本文提出了一种社会感知(social perception)方案,该方案将所有车辆视为分布式传感器网络中的传感器。通过观察个体行为以及群体行为,在置信空间(belief space)统一地更新这三种不确定性。将来自社会感知的更新置信明确地并入模型预测控制(MPC)的概率规划框架中。
MPC的成本函数通过反向强化学习(IRL)学习。这种社会性增强感知(enhanced perception)的综合概率规划模块使自主车辆产生有防御性、但不过度保守且社会兼容的驾驶行为。
如图演示了几种示例性场景,其中其他车辆和行人可以作为传感器来克服遮挡或传感器受限范围。 在(a)中,由于V1和V2引起的遮挡,主车V0不能检测到行人。 V1的行为可被用作传感器,实现社会感知这个潜在行人。 在(b)中,主车V0在单向T形交叉口处右转。 在(c)中是有信号灯的交叉口。 主车V0(右转)只能检测前方的信号(红灯)并控制自己方向。它应让步于较高速度的V3和V4。但是,左转车道上的V1和V2加速,说明它们是受保护的左转弯,并且V0可以继续右转。因此,当其他道路车辆的运动属性超出有限的传感器范围时,就需要社会感知功能。

现在考虑具有感知不确定性的多智能体环境自动驾驶汽车的行为规划。除自动驾驶汽车之外,假定所有其他代理均为人。不明确地模拟人与人之间的交互,而要关注汽车与单个人之间的交互。那么这里感知不确定性就是:诸如遮挡和传感器范围有限之类的物理状态不确定性,和诸如本地驾驶偏好之类的社会行为不确定性。
关键的观察事实是,交通参与者不仅被看成机器人汽车需要觉察的动态障碍物,而且还应被视为分布式传感器,其行为可以提供超出自动驾驶车传感器范围之外的其他信息。下面强调几点:
i)分布式代理可以看作是发出行为信号的分布式传感器。
Ii)假设每个人都是最佳的规划者,并在人行为建模时考虑机器人汽车与人之间的交互作用。
iii)用人作为环境传感器,为机器人汽车构建观测模型,更新其估计的置信度。对于环境状态和社会信息,设计不同的观察模型。为了更新社会信息估计的置信度,机器人汽车需要从多个人收集常见行为。
iv)为了机器人汽车通过收集人类的行为信息来更新其置信度,机器人汽车用人类的成本函数,通过逆向强化学习(IRL)计算成本函数。在学习过程中,假设人类操作不是最佳的,并且不考虑感知不确定性。那么,其目的是找到人类操作集UD的最大似然权重。这样,基于最大熵原理,假设当轨迹有较低的成本时其指数性似然值更大。
由于置信度的概率性,用基于模型预测控制(MPC)的概率框架作为自动驾驶汽车的规划者。在成本设计中考虑安全性,效率,舒适性和燃料消耗度,包括以下因素的惩罚权重:跟踪错误、安全度、效率、加速和抖动等。为了保证规划轨迹的可行性,引入以下约束:
运动学限制(采用自行车模型)、动态约束(包括车辆的曲率和加速度)和安全约束(包括静态道路结构,如多边形,和动态障碍物,如圆形)。
下面是整个带社会感知的行为规划算法伪代码:

本文实验设置一个具有传感器遮挡的示例场景,验证有社会感知的规划框架有效性。如图所示,自动驾驶车(红色)和人类司机车(黄色)并排行驶,同时行人将要过马路。实验中,用保守的规划、激进的规划和提出的社会感知规划来模拟这种交通场景。

下图给出在行人过马路时采用激进规划(左图)和建议的规划(右图)二者实验的比较。


“Combining Planning and Deep Reinforcement Learning in Tactical Decision Making for Autonomous Driving”
由于环境的多样性,传感器信息的不确定性以及与其他车辆/行人的交互复杂性,自动驾驶的战术决策(tactical decision)是一个挑战性问题。 本文介绍了战术决策的一般框架,以蒙特卡罗树搜索和深度强化学习的形式将规划和学习相结合。
该方法基于谷歌DeepMind的AlphaGo Zero算法,扩展到不用自驾(self-play)的连续状态空间域。该框架适用于模拟环境中两个不同的高速公路驾驶情况。
该框架下,参数θ的NN fθ用于指导MCTS(蒙特卡罗树搜索)。其网络输入是状态s,输出是状态的估计价值V(s,θ)和代表不同动作先验概率p(s,θ)的向量。从给定状态选择采取的动作,实行的是如下所示算法1中的SELECTACTION函数。
此函数构造一个搜索树,其中每个状态动作节点存储一组统计信息{N(s,a),Q(s,a),C(s,a)},其中N(s,a)是 节点的访问次数,Q(s,a)是估计的状态-动作值,C(s,a)是子节点的集合。为了构建搜索树,要进行n次迭代,其中每次迭代都从根节点s0开始,并持续时间步长t = 0,1,...,L,直到在步骤L到达叶节点sL。

算法2是生成训练数据、优化NN参数的过程。首先,从模拟环境中获得经验。对于每个新情节(episode),对随机初始状态进行采样,然后运行情节直到步骤Ns终止,根据算法1的SELECTACTION函数选择执行的动作。终止后,针对每个步骤i = 0,... Ns -1,对情节期间收到的奖励ri求和计算得到折现收益zi 如


将规划和强化学习相结合的框架可以应用于自动驾驶。在研究中,涉及了两种高速驾驶案例的框架特性,如下图所示。(a)表示高速公路连续行驶情况的初始状态,而(b)表示当自车接近道路右侧出口时的出口状况。 自车是绿色卡车,而周围车辆的颜色代表其相应驾驶员模型的激进水平。 红色是激进的驱动程序,蓝色是胆小的驱动程序,紫色的不同阴影表示介于两者之间的级别。

然后,对这两种情况进行驾驶员和物理学建模,既作生成模型,又用于模拟环境。智能驾驶员模型(IDM,Intelligent Driver Model)用于控制每辆车的纵向运动。最小化变道引起的总制动(MOBIL,Minimizing Overall Braking Induced by Lane changes)策略用于对周围车辆的变道建模。
纵向动力学假定恒定的加速度,而横向动力学假定恒定的横向速度。两个高速公路驾驶案例的决策问题被表述为部分可观察的马尔可夫决策过程(POMDP,partially observable Markov decision process),涉及状态空间、动作空间、奖励模型、状态转换模型、生成模型、观察空间和模型,以及置信度状态估计等。
NN估计采取不同动作的先验概率以及当前状态的价值。 在实现中,状态s在通过神经网络之前转换为ξ,对所有状态进行归一化,即ξ∗∈[-1,1],而周围车辆的位置和速度需要相对于自车表示。下图说明了采用的NN体系结构:卷积和最大池化层在周围不同车辆输入之间具有平移不变性,这样车辆的序号和数目变得无关紧要。

实验中,在连续状况,自车(长12.0 m的卡车)从随机车道开始,在出口状况,自车从最左侧车道开始,初始速度为vx,0。周围的车辆由IDM和MOBIL模型控制。模型参数的边际分布均匀地分布在积极、正常和胆小的规划参数之间,如下表所示。

下图是需要规划的情况示例。(a)显示初始状态,(b),(c)和(d)是三个代理15s之后的状态。绿色卡车是自车。

如图是为解决特定情况需要规划相对较远未来的示例。(a)显示初始状态,而(b),(c)和(d)显示三个代理的退出状态。其中点表示机动车辆在操纵过程中相对于其他车辆的位置,(b)和(c)显示自车加速并超越较慢的车辆,而(d)显示自车减速并停在同一辆车后面。

为了说明训练有素的MCTS / NN代理行为,如图显示在高速公路出口情况下、在没有其他车辆的时候和接近出口时,针对不同状态采取的学习价值和行动。箭头表示不同状态采取的动作。 指向右侧的箭头对应于动作a1,而向下的箭头对应于动作a4。

另外,代理的动作空间如下表所示。

“A Hierarchical Architecture for Sequential Decision-Making in Autonomous Driving using Deep Reinforcement Learning”
战术决策是高级驾驶系统的关键特征,其中的挑战包括诸如不确定环境的复杂性和自主系统的可靠性等。本文开发了一种多模态架构,完成自我环境(ego surrounding)建模,并训练深度强化学习(DRL)的代理,其在随机高速公路驾驶场景保持一致性。
为此,将自我环境的占用网格(occupancy grid)馈送到DRL代理获得高级串行命令(即车道变换)发送到较低级别的控制器中。本文将自动驾驶问题划分为多层控制架构,这样能够利用AI能力分别解决每一层,并获得可接受的可靠性分(reliability score)。与端到端方法相比,这种架构能够最终获得更可靠的系统。下图是该层方法的示意图。

而如图是ADAS分级结构和端到端方法的比较图。

该方法采用占用格(occupancy grid)作为自车周围的环境模型。在现实世界中,这种实现方式比可用的端到端技术更可靠,因为后者无法执行从具有大量不确定性的最高层观测到最低层执行器控制层的单映射变换。
这项工作主要用Q-学习的经典强化学习技术求解自动驾驶汽车高层决策的问题,在自己设计的Deep-Cars仿真环境中对问题实施ε-greedy算法求解,而动态规划(DP)和强化学习(RL)是解决决策问题的算法,在与世界互动的过程中实现所需目标。
DP需要系统行为的模型,而RL是一种无模型的方法,可以在与环境交互的同时改善生成的策略。在数学上RL使用马尔可夫决策过程(MDP)形式化离散随机环境。RL中的状态和动作通常是离散的,从而引出串行决策问题。奖励提供了有关代理性能的信息指标,其目标是在与环境互动的过程中最大化所累积的长期回报。
Q-学习通过学习动作价值函数Q(s,a)评估在特定状态下采取某项动作的效果。在Q-学习中,构建内存表(memory table)Q [s,a]存储状态-动作所有可能组合的Q值。从当前状态采样一个动作,找出奖励R和新状态,从而从存储表中获取具有最大Q(s',a')的下一个动作a。在特定状态下采取行动的Q-值计算为

由于计算量问题,所以用深度Q网络(DQN)来近似动作价值函数Q(s,a)。
DQN创建并训练了两个网络θ-和θ,一个用于检索Q值,另一个包括训练中的所有更新。最终,使θ-和θ同步以临时固定Q价值的目标,同时可以防止目标函数突变现象发生。
损失函数的计算为

经验重播(Experience Replay)用作一个缓冲区,从中进行微批量(mini-batch)采样训练深度神经网络。利用经验重播和目标网络,模型的输入和输出使训练更稳定,并且网络表现地更像是监督学习算法。另外,本文应用双DQN(DDQN)算法,其使用两个Q网络来对付过分乐观(overoptimistic)的价值估计。
下面是DQN算法的伪代码实现。

实验中使用pygame设计环境,以此构建游戏环境,称为DeepCars环境,如图所示。

游戏能接收高级控制命令作为输入向量,并给出游戏状态和奖励作为输出。为了能够形式化MDP中的问题以采用RL算法,这里状态和动作是离散的。实际上,动作空间包括三个动作:A = {左,停留,右},模拟的目的是训练代理,以避免与其他车辆发生碰撞。
“Design Space of Behavior Planning for Autonomous Driving”
本文探索了自动驾驶行为规划的复杂设计空间。若能成功地解决行为规划一个方面的设计选择,就可以严格限制其他的方面。这项工作根据当前最好方法分解设计空间,并讨论其中的权衡。作者提出了设计空间的三个轴,如图所示。

人类司机控制动作是连续的,但驾驶过程还包含由道路连通性、标志、信号、道路-用户的交互等引起的离散事件。车辆驾驶必须遵循道路的平滑连续轨迹。因此,离散抽象和连续抽象的可能范围,是考虑的设计空间第一轴。
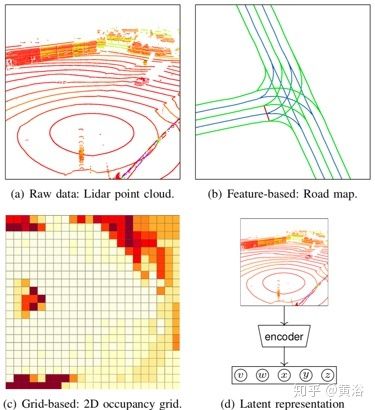
下图展示的是在第一个设计轴中关于用于自动驾驶运动规划的四种环境表示形式,从最小到最大的抽象的演变,即原始数据、特征表示、网格表示和潜在变量表示。
根据任务规划器提供的一系列要遵循的道路,BP必须制定一系列离散的高层控制措施,在环境中导航。控制动作可能包括基本操作,如加速,减速和停止。这些动作还必须与实际路况一致,必须根据传感器输入在线地生成。因此,感知是行为规划的重要组成部分,它自身具有许多挑战,包括噪声、遮挡和传感器融合。
尽管存在不完善的假设和感知的问题,但BP必须对环境的动态性做出反应。无人驾驶车的本地规划目的是设计一个从当前位置到目标位置的安全且平滑的轨迹,并避开障碍物、满足舒适性要求和普遍地遵守运动动力学(kino-dynamic)约束条件等。BP选择的抽象动作必须考虑自车和环境的实际状态。BP可参数化选项或与LP通信。
如图是环境表示的几种方式:
- 车载传感器和其他来源(相机,雷达,激光雷达等),
- 从原始传感器数据中提取的一组特征
- 几何路网作为连续特征
- 占用网格
- 潜在变量表示

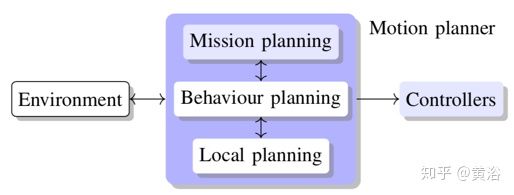
驾驶问题的分解将高级离散决策(直线,左转,停止,......)分配给行为规划器(BP),而低级连续动作留下由本地规划器(LP)制定。离散动作的选择非常适合程序化来做,而连续动作要通过优化找到。这样,设计空间考虑的第二个轴涉及运动规划器的整体架构。
如图是运动规划器的总体架构。
下图是第二设计轴中架构设计的选项。行为规划架构分成运动规划和预测两部分。

运动规划器,有两种相互排斥的和BP集成的方法:一种是BP模块在结构上与运动规划器的其余部分分开,另一种是BP可以部分或完全地和其他部分集成。
分开的方法可能导致计算冗余;集成方法主要以端到端方式工作,这种方式依赖于大标签数据。
给定状态信息和过去的轨迹,预测任务是预测以下的一项或多个项:轨迹、低层运动单元(加速、减速和保持速度等)或意图(让路、变道和过马路)等。
环境预测方法因环境表示、预测模型的设计、预测的抽象、先验知识的合作度、预测范围和对噪声的鲁棒性而异。预测方法包括三类:i)基于物理的模型,仅根据物理定律预测动态目标的运动; ii)基于机动的模型,该模型对预期的道路参与者机动进行建模并预测其执行; iii)交互觉察(interaction-aware)模型,该模型说明了环境中各种代理之间的相互依赖性。大多数公开的方法都是基于物理或机动的方法,仅在最近热点转移到基于交互的方法。
预测的体系结构与预测和行为规划之间耦合的不同程度有关。首先要选择的是,显式还是隐式定义的预测模型。
显式定义的预测模型会输入状态观测,并对道路使用者的未来行为做出明确的预测。这些显式预测模型可以是外部(External)或内部(internal)两种方式。
显式模型的外部预测与规划过程完全解耦,它们的输出增强了馈入规划器的环境表示;这种设计在预测和规划之间提供了清晰的接口,有助于模块化实现。注意大多数预测方法都属于此类。
另一方面,显式模型的内部预测是将预测与运动规划过程集成在一起,存于规划器中。例如,具有部分可观察的马尔可夫决策过程(POMDP)模型的规划器,将道路参与者的意图视为规划状态空间内的潜在表示。在每个规划步骤中,规划器都会保持对道路参与者意图的置信度,并会定期根据新的观测结果进行更新。这样可能会使轨迹更安全,特别当道路参与者响应目标车辆的行为而主动改变其意图的情况下。
但是,目前在有许多道路参与者的场景中,预测的计算是棘手的。取而代之的是,BP体系结构用隐式定义的预测体系结构,这使预测和规划之间的耦合度更高。
隐式预测模型并不将道路参与者的意图表示为显式特征。其预测算法在学习驾驶策略的同时,可根据目标车辆与环境的相互作用学习预测道路参与者的行为。
考虑到BP和LP之间的整合和通信级别,以及对BP设计影响最大的预测方式,设计空间第三个也是最后一个轴,是决策逻辑的表示。底层逻辑表示用于做出高级决策,如图所示。

规划器的决策逻辑可分为两个范式:(1)通过一组明确编程的工作规则表示的逻辑, 2)依赖那些参数作为学习先验知识的数学模型表示的逻辑。虽然学习逻辑(learning-logic)模型能够在各种情况下进行概括,但它们不可解释,很难确保安全。另一方面,编程逻辑(programmed logic)需要大量的人力工作,并且要服从传统的软件工程原理。
可以使用两个完全不同的编程范例来实现编程逻辑系统:命令式(imperative)和声明式(declarative)。命令式系统包含了一系列操作,这些操作表达给定的程序从一种状态转移到另一种状态的控制流。另一方面,声明式系统无需特意去描述控制流,而是能够表达底层逻辑。
由于缺乏严格的系统流程,因此声明式系统更难以更改,因为它具有较少的相互依赖关系,也更难以实现。另一方面,命令式系统需要大量规则和转换,才能完全处理复杂的驾驶情况,结果就是它很难扩展到更复杂的驾驶任务。
声明式系统有两种内部逻辑的表示方式: i)专家系统通过一组规则评估一个世界状态来获得决策,并通过推理将它们组合起来,获得最终的行为决策。ii)优化系统将驾驶行为封装为一组数学变量,相对最佳行为进行优化。
学习逻辑系统的决策可以细分下去,根据学习是来自专家示例还是来自与逼近现实世界的模拟环境的交互来定。简单的端到端表示学习法已被证明,能成功地在道路和高速公路上执行基本操作。在实践中,尽管需要大量标注的驾驶数据,但“从示例中学习(learning from example)”已显示出更强大的功能。
使用示例的另一类学习算法是从演示中学习(learning from demonstrations)。行为规划系统可以用模仿学习来复制(copy)或者克隆(clone)参考驾驶员的行为。它也可以使用人类演示示例来构建奖励函数,该奖励函数可用于驾驶行为的逆强化学习(IRL)。另一方面,“从交互中学习(learning from interaction)”可以从更多样化的驾驶情况(甚至潜在的危险情况)中获取知识。
最后,同时用“从示例中学习”和“从交互中学习”的方法具有优势,例如鲁棒性和同时满足多个目标函数。
“Decision making in dynamic and interactive environments based on cognitive hierarchy theory: Formulation, solution, and application to autonomous driving ”
本文描述了基于认知分层理论(cognitive hierarchy theory)在动态和交互环境中的自主决策(autonomous decision making)框架。它把自代理(ego agent)及其操作环境之间交互建模为双人的动态游戏,并整合认知行为模型(cognitive behavioral models)、贝叶斯推理和滚动(receding/rolling-horizon)最优控制,从而定义自我代理在动态演化中的决策策略(decision strategy)。
特别是,在规划范围内可能会强制实施严格的约束条件,以满足安全的要求。交互式决策过程被表述为受约束的部分可观察的马尔可夫决策过程(POMDP)。
这里“认知分层结构(CH)”框架取代了“ k-层”框架,在CH框架中,以σ-层(σ= 0,···,k)决策的混合模型对CH-k决策进行建模和优化,战略性响应交互的环境。
博弈论是用于建模智能代理之间战略交互的有用工具。在许多实验研究中,与基于均衡的理论(equilibrium-based theories)相比,因为认知分层理论(CHT)提高了预测人类行为的准确性,引起了博弈论者的关注。CHT通过基于迭代合理性的水平(levels of iterated rationalizability)来表征人类行为,从而描述了战略游戏中的人类思维过程。
特别是,与许多基于均衡理论的无界/完美理性假设(unbounded/perfect rationality)相比,CHT假设决策者具有有限理性(bounded rationality)。当自代理对其操作环境有充分的了解时,可以预先指定级别-σ模型的混合比率。在不确定的环境中运行时,可将有关交互环境的认知水平的推理纳入决策过程。
首先,考虑在动态和交互式环境中运行的智能代理的决策过程。自代理与环境之间的交互建模为一个两人动态游戏,表示为6元组
R = {R1,R2}代表决策目标的两个参与者的奖励函数,即
C = {Xt}t∈N, Xt⊆X是一组“安全”状态,代表了自代理决策的硬约束(hard constraints)。
自代理基于滚动优化做出决策,即
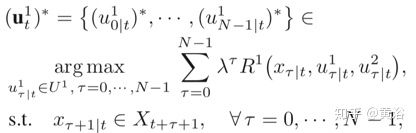
相反,一种方法是考虑最坏情况,上面的优化问题被视为
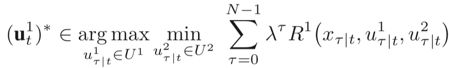
但是,由于它假定是一个对抗性参与者2,而不是那个追求自己目标并且不一定要对抗自代理的理性参与者2,该优化结果可能会造成自代理过于保守的决策。
因此,需要寻求基于认知分层理论(CHT)的一种替代解决方案。这里有两个框架作为选项:k-层框架和认知分层(CH)框架。
在k-层框架中,假定战略游戏中的每个玩家基于对其他玩家可能采取行动的有限深度的推理来做出决策。推理层次结构始于某种称为0-层的非战略行为模型。然后, k-层的玩家k = 1、2,····,假设其他所有玩家均为(k − 1)层,并以此为基础预测其他玩家的行动并做出自己的决策。如果其他参与者执行σ < k − 1的σ-层决策,则k -层决策可能变差。
CT框架在有界的k认知层上表征每个玩家的行为方面与k-层框架类似。CH框架的独特是,在众玩家某种比例适合每种原型(archetype)的假设条件下,猜测玩家可以行动。假定其他每个玩家σ-层都满足σ 策略πi,i∈P是从状态X到动作Ui的随机映射。任意k = 0、1,...,要定义环境的k-层模型,首先要定义自代理的0-层模型(由策略π1,0定义)和环境的0-层模型(由策略π2,0定义)。基于“ softmax决策规则”构造环境π2,k,k≥1的k-层模型,该模型捕获了决策的次优性和可变性,如下所示: 而各自对应的状态-行动对Q-函数定义为 构造了k = 0,1,···,kmax 的环境k-层模型π2,k之后,定义代理-环境系统x-t = [xt, σ]⊤,其中σ ∈K = {0,1,···,kmax}表示环境的实际认知层,并假定自我代理不知道这一点。接着,考虑以下代理-环境系统的增强动态模型, 环境行为u2t视为随机干扰。然后,考虑自代理的以下决策优化问题 现在考虑随机的决策规则,在决策空间(U1)N定义的优化问题转换为在概率空间定义的优化问题,如下所示:首先,将γ1τ| t,τ= 0,···,N -1定义为集合U1上的概率分布,根据该概率分布选择预测动作u1τ| t;然后,将其重新表述为以下优化问题: 该问题称为具有时间联合机会约束(time-joint chance constraint)的POMDP,其中部分可观测性来自隐态σ∈K的不可观测性。 实验中将基于认知分层理论的决策框架应用于各种交通场景中的自动驾驶自车(ego vehicle),同时与人类司机驾驶的其他车辆进行交互。交通场景包括四路交叉口场景,高速公路超车场景和高速公路强行合并场景。 在k-层模型中考虑L-1和L-2模型。 不同的人类驾驶员可能具有不同的认知层,自动驾驶的自车不知道与之交互的人类驾驶员特定认知层σ,但根据其观测到的信息推断σ的大小。如果t = 0时没有任何信息,则将自动驾驶车在人类驾驶车的L-1/-2模型的置信度初始化为0.5。用离散时间模型表示如下车辆纵向的运动学: 而变道(lane change)建模为瞬间事件,即一次完成。 如下图是交叉路口场景实验。 (a-1)和(a-2)显示模拟自动驾驶自车(蓝色汽车)与L-1型人类驾驶车(红色汽车)相互作用的两个后续步骤; (b-1)和(b-2)显示了与L-2型人类驾驶车互动的过程。 当与L-0模型的L-1型人类驾驶车交互时,它代表谨慎/保守的驾驶员,自动驾驶的自车决定首先驶过交叉路口。 当与L-2型人类驾驶车互动(激进的,基于L-0模型)时,自动驾驶自车会对人类驾驶车让路。自动驾驶车通过不同的方式观察人类驾驶员的行为来了解驾驶员的认知水平,然后预测驾驶员的未来行为并做出最佳反应,从而不同的方式对两个驾驶员做出反应。 如图是超车交通情况。 (a-1)至(a-4)示出模拟的自动驾驶自车(蓝色汽车)与L-1人类驾驶车(红色汽车)相互作用的四个后续步骤; (b-1)至(b-4)示出与L-2人类驾驶车交互的情况。 在仿真中,人类驾驶车的最大速度小于自动驾驶自车的最大速度,以确保超车的可能性。 与L-1人类驾驶互动时,自动驾驶自车会相对较快地完成超车,如(a-2)所示,L-1人类驾驶员会缓慢驾驶让自车驶入。与L-2驾驶员交互时,自动驾驶的自车需要较长的时间才能通过超车道(passing lane),然后返回原行驶车道(traveling lane)。 最后一个实验是并道的场景。 (a-1)至(a-4)显示自车(蓝色汽车)与L-1型人类驾驶车(红色汽车)交互的四个后续步骤; (b-1)至(b-4)示出了自车与L-2型人类驾驶车辆交互的情况。 准确跟踪和预测周围目标的行为是智能系统(如自动驾驶车辆)实现安全、高质量决策和运动规划的关键先决条件。然而,由于目标数量波动和遮挡存在,多目标跟踪仍然存在挑战。 这里提出一种约束的混合串行蒙特卡罗(constrained mixture sequential Monte Carlo,CMSMC)方法,将混合模型表示结合到估计的后验分布中实现多模态。在统一框架内,它可以同时跟踪多个目标而无需对观察值和跟踪目标之间做数据关联。这个框架可以将任意预测模型作为CMSMC的隐式提议分布(implicit proposal distribution)。 一个例子是基于学习的分层时间序列预测模型(hierarchical time-series prediction model,HTSPM),由行为识别模块和状态演化模块组成。两个模块通用且灵活,在一类时间序列预测问题应用时可以把行为分成不同级别。它不仅关注单实体(single entity)的预测轨迹,而且共同预测交互实体(interactive entities)的连续运动。 这里忽略多目标跟踪算法,重点介绍一下本文的预测算法HTSPM。识别模块旨在解决概率分类问题,而演化模块旨在将当前状态传播到未来。 下图是HTSPM模型图。 (a)识别模块:深度马尔可夫模型(DHMM);(b-1)演化模块:外部信息直接影响状态;(b-2)演化模块:外部信息和行为模式通过一个动作项(输入)间接影响状态。黑色实心箭头表示一阶马尔可夫假设(first-order Markov assumption),红色虚线表示较高阶假设。 下面是HTSPM算法的伪代码实现细节。 关于预测模型的应用,如图给出一个驾驶行为的分层表示。在日常驾驶情况下,相应地可以通过三种常见行为模型到达目的地:车道保持、变道和转弯。 这些行为也可以分解为更主要的动作,例如速度调节和转向,这些动作本身也有构成的元素。每个行为层对应于一个层,并且某个行为层的每个行为类对应于一个HMM。 具体跟踪和预测的算法实验就此略过。 从这些文章的介绍,我们可以看到目前作为规划中最有挑战的行为规划和决策(预测模块也牵涉到)大概的一些研究热点,模拟学习和逆强化学习是比较普遍的两个常用途径,但各自面临不同的困难。这个领域面临的不确定性比感知模块的不确定性更难以建模,决策的逻辑表示仍然不是那么清晰,功能安全的约束也增大了问题的复杂度。其中一些细节设计到离散和连续空间的考虑、和其他驾驶车的交互方式、还有计算复杂度和空间划分的均衡问题。感知仍然十分重要,预测可以说是感知的一部分,其中更细节化的传感器数据特征会影响整个决策,比如驾驶员意图的判断。强化学习的调参比CNN的调参难度也不会小,动态目标造成新的泛化问题,另外本身谷歌的NAS(网络架构搜索)也是基于强化学习的。数据也是一个大问题,训练的结果和采用的数据种类、场景和形式紧密相关。 把这些文章的题目放一起就是了。
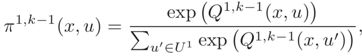










“Generic Tracking and Probabilistic Prediction Framework and Its Application in Autonomous Driving”



参考文献