【人工智能算法】算法基础之K均值聚类算法
本文重点主要有:
- 聚类
- 质心
- 非监督训练
- K均值算法
理解训练集
多组观测值通常被划分为称作“训练集”的大型集合,这些数据都被用于训练机器学习算法。“训练”指的是通过调整算法的内部状态,使得机器学习算法的输出符合预期输出的过程。
按所使用的训练集不同,机器学习算法宽泛地分为两类:监督学习和非监督学习。在非监督学习过程中,你仅仅向算法提供向量形式的输入数据,但却不设置预期输出;聚类算法就是一种非监督学习。
非监督学习
以鸢尾花的数据集为例来了解监督学习和非监督学习的过程。
这个数据集由与鸢尾花花瓣和花萼尺寸有关的4个比率量组成,还有一个“种属”量指明了每个鸢尾花的种类。
示例如下:

就非监督的聚类算法而言,我们最可能用到的是前4个量而忽略“种属”这个量。在进行比较之后我们可能会给这些数据打上标签,但由于是非监督学习,聚类算法并不需要知道哪个数据属于哪个“种属”。这个算法的目的不在于判断某个鸢尾花属于什么种类,而在于按相似度把这些数据分为几簇。
另外还要注意一个问题,就是这4个观测值都不必进行归一化,K均值聚类算法本身并不需要归一化的过程;当然这并不是说别的算法也不需要。就对这个鸢尾花数据集进行聚类的问题而言,归一化的过程是可有可无的。要是数据的一个或多个特征量过大,以致掩盖了其他的特征量,就一定要先将数据归一化;在本例中,鸢尾花数据集的四个比率量特征值在数值上都比较接近,因此并不一定要将数据进行归一化处理。
鸢尾花数据集中的4个比率量特征值提供的信息并不足以将它按“种属”分类;这完全没有关系,就聚类这个操作而言,我们只是想看看这些数据之间到底有多相似,以及这些数据究竟可以被分为多少组。

在上图中,各个分好的簇按颜色在图上标注了出来,并且都用曲线围了起来,以便在黑白媒介上也能够区分这些簇。
如果聚类算法能够正确地区分鸢尾花的种类,那么同种符号就应当是同样的颜色;
我们可以看到的簇与簇之间边界十分明晰,但很显然它们并不是按照“种属”这个属性来划分的,这一点几乎无法避免。由于随机性,K均值算法有时确实会得到与按种类划分相近的结果。在上图中簇与簇之间是线性可分的(“线性可分”的意思是可以通过画一条直线把它们分隔开来),而鸢尾花的不同种类之间却不是线性可分的。种类与种类之间存在一部分重叠的区域,仅靠非监督的聚类算法是不可能将两个种类区分开来的。
监督学习
监督学习的限制比非监督学习要高一些,其中的训练集要由输入数据和预期输出组成的成对数据构成。就鸢尾花数据集而言,你要输入4个比率量观测值作为一个四维输入向量,可能还需要用突显编码法将“种属”数据编码为预期输出向量。机器学习算法的性能由给定输入时,产生对应的预期输出的比例来评估。
理解K均值算法
K均值算法实现起来比较简单,效果主要是将数据划分为指定数量的集群。其中,算法的实现有3个泾渭分明的步骤:
- 初始化(两种方法)
- 分配
- 更新
分配
“分配”和“更新”两步会不断重复,直到再也没有新的数据需要划分到新的簇中。每一个簇都会从两方面来定义。首先是“质心”。“质心”也是一个与被聚类数据等长的向量,实际上其本身就是一个数据,只不过表示的是簇内数据的平均值。因此,“质心”究其本质是簇内所有数据的中心点。除了“质心”外,每个簇还有一个由分配给各个簇的数据组成的列表。
“分配”这一步会对所有数据进行循环,并把每个数据分配到其质心与该数据最接近的簇中去。其中“最近”指的是两个向量之间距离最短,一般用的是欧氏距离。
对“更新”这一步来讲,一定要记得检查是否有数据从一个簇被划分到了另一个簇,这样K均值算法才知道算法在何时完成使命——如果不再有数据被移动到其他的簇中,就认为K均值算法已经达成了它的目的。
伪代码如下:
done = true
for cluster in clusters: #检查每一个簇,判断是否存在需要被移动到另一个簇的数据。
for observation in cluster:
targetCluster = findNearestCluster(observation)
if targetCluster!=cluster:#如有必要,将数据重新分配。
cluster.remove(observation)#如果targetCluster不是当前所在的簇,则需要将当前数据移动到对应的簇中去。
targetCluster.add(observation)
done = false;
return done
更新
更新”紧跟在“分配”之后执行。这两个步骤会一直循环到在“分配”这一步中,不再有数据改变所属的簇为止。跟许多机器学习算法一样,K均值算法也是迭代型算法,其训练过程要经过大量迭代,而每个迭代性能都会逐步改善;到每次迭代性能都只有很微小的提升甚至不再提升时,机器学习算法就会停止了。
更新”这一步实际上就是重新计算每个簇的质心。在“分配”这一步中,每个簇的内容都可能会被改变,因此每个簇的质心也都有可能不再有效,考虑到这一点,我们就需要重新计算一下每个簇的质心,这就是一个简单的计算簇中数据各个特征值的平均值的过程。举例来说,下列3个鸢尾花都属于同一个簇,我们要计算出一个四维的平均值向量,也就是这个簇所谓的“质心”。

计算一个质心如下:

可以得到质心向量为:【5.7,3.2,2.5,0.6】
K均值算法的初始化
之前是说分配和更新的过程,但是这都是基于已经分配好的数据,所以接下来来了解初始化的方法。
K均值聚类算法的初始化是随机的,而其“分配”和“更新”两个步骤都是确定性的,但由于算法的初始状态是非确定性的,因此整个算法也是非确定性的。
均值聚类算法有两种常用的初始化方法:
- 随机算法
- Forgy算法
随机K均值初始化
创建指定的K个簇,并且把各个数据随机分配到每一个簇中即可,同时还要注意,不要存在数据为空的簇。“随机初始化”之后要直接进行“更新”操作,这样才可以分别计算出这些新生成的簇的质心。
首先我们要计算各个数据的维度数目,K均值算法要求每个数据都具有相同的维数。也就是需取数组的“长度(length)”属性即可。
dimensions = theObservations.length
接下来创建K个簇,从0到K(不包含K)
for i in range(0,k):
clusters.add(new Cluster(dimensions))
然后把每个数据都随机分配到一个簇中,首先对每一个数据进行循环,之后随机选择一个簇,分配(0,k-1)区间内的随机整数用来代步这个簇,把数据添加到其中。
for observation in theObservations:
clusterIndex = randint(k)
cluster = clusters[clusterIndex]
cluster.add(observation)
接着就要对可能存在的没有数据的空簇进行处理:
for cluster in clusters:
if cluster.length==0:
done = false;
while(!done):
sourceIndex = randInt(K)
source = clusters[sourceIndex]
if(source!=cluster&&source.length>1):
#一旦找到了这么一个符合要求的簇,我们就可以进行数据移动的操作了。具体过程是从选定簇中随机选取一个数据,并把这个数据移动到空簇中,然后把done这个标记置为“真”。
sourceObservationIndex = randInt(source.length)
sourceObservation = source[sourceObservationIndex]
source.remove(sourceObservationIndex)
cluster.add(sourceObservation)
done = true;
updateStep()
随机初始化K均值算法流程图:
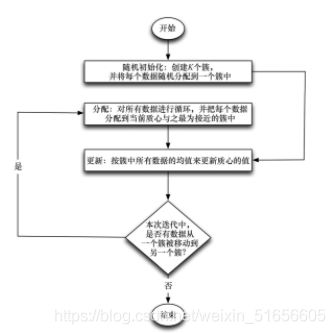
K均值算法的Forgy初始化
Forgy初始化的工作原理是首先设置各个簇的质心值,然后把每个数据分配到与之最近的质心对应的簇中。
第一步,判断数据的维数。各个数据的维数应当相同。同时我们还要设置一个名为usedObservation的哈希集合用于保存已分配的数据。我们不会在初始化中使用全部数据,但也不希望有数据被重复使用。
dimensions = theObservations.length
usedObservations = new HashSet()
for i in range(0,K):#循环创建K个簇
cluster = new Cluster(dimensions) #以正确的维数创建每个簇:
clusters.add(cluster)
#创建好一个簇之后,随机为其选取一个数据,注意不要选到用过的数据
observationIndex = -1;
while(observationIndex == -1):
observationIndex = randInt(theObservations.length)
if(usedObservations.contains(observationIndex)):
observationIndex = -1
#获得了一个没有被用过的随机数据,单用这个数据来创建一个簇,并将这个数据作为簇的质心。
observation = theObservations[observationIndex]
usedObservations.add(observationIndex)
cluster.add(observation)
Forgy初始化K均值算法流程图:

初始化之后紧跟着的是“分配”操作。这是由于Forgy初始化只是设置了每个簇的质心,还需要把其他所有数据都分配到各个簇中去。