【目标检测】10、LEDNet
文章目录
-
- 摘要
- 1. 引言
- 本文网络结构
-
- 2.1 带有 Split and Shuffle Operations 的残差模块
- 2.2 LEDNet 网络设计
- 3. 实验
-
- 3.1 实验落实细节
- 3.2 实验结果
- 4. 总结和展望
摘要
大量的计算限制了 CNNs 在移动设备上的部署,本文提升了一个轻量级网络 LEDNet 来解决该问题,该结构使用不对称的 “编码-解码” 机制来解决实时语义分割问题。
详细来说,编码器采用 RestNet 作为 backbone,每个残差模块都使用了 channel split 和 channel shuffle,来减小计算量并提高分割准确率。
另外,解码器中使用注意力金字塔网络 attention pyramid network(APN),降低网络复杂度
本文模型参数低于1M,在单个 GTX 1080Ti GPU 上运行速度超过71 FPS。
最终实验结果验证了本文的方法在 CityScapes 数据集上,同时达到了速度和准确率的平衡。
1. 引言
目前,解决基于场景的问题基本上是靠搭建更深更大的卷积网络来实现的。效果优异的 CNNs 一般都有上百个卷积层和成千的特征通道。为了获得更好的效果,通常要以牺牲时间和速度为代价。尤其在真实情景下,如 augmented reality、机器人、自动驾驶等,规模较小、计算成本较低的网络能够进行在线估计,高精度的网络需要庞大的算力,不适合部署于算力较低的移动平台。
该限制在语义分割任务上的限制也很明显,语义分割要对每个像素进行类别划分。
为了克服这些问题,出现了一些网络来解决准确率和效果直接的平衡,大概可以分为两类:网络压缩 [9,10,11] 和卷积分解 [13,14,15] 。
网络压缩:
通过压缩预训练网络,包括 hashing[9] ,pruning [10] 和 quantizaiton [11,12] 等推理阶段的算法。为了更好的去除冗余,另一种方法是稀疏编码 [16,17]。
卷积分解:
卷积分解机制 convolution factorization principle(CFP),是将标准的卷积过程分解为 group convolution 和深度可分离卷积 [3,15,18],之后直接训练小的网络。
如 ENet[13]使用 RestNet作为backbone,来实现高效的推断。[19] 中提出了级联的网络,将 high-level 标签集成到网络,来提升性能。
[7,14,20] 中都使用一个对称的编码解码机制,可以减小参数同时提升准确率。
虽然已有部分工作对轻量级体系结构网络进行了初步研究,但在非常有限的计算预算下追求最佳精度仍然是实时语义分割任务的一个有待研究的问题。
本文将该效率和准确率的 trade-off 作为一个整体来解决,而非单个解决。本文引入一个 LEDNet,使用不对称的 编码-解码 机制来实现实时语义分割。
如图1所示, LEDNet 由两部分构成:编码网络和解码网络
编码模块:
CFP之后,编码器的核心单元是一个新型残差模型来实现 skip connections 和 convolutions with channel split and shuffle 。skip connection 允许卷积学习残差函数来帮助训练,split 和 shuffle 过程能够加强通道间的信息转换同时保持类似于一维分解卷积的计算开销。
解码模块:
解码模块,我们设计了一个 attention pyramid network(APN)来抽取丰富特征,使用注意力机制来估计每个像素的语义标签,本文贡献如下:
-
LEDNet 的非对称机制使得可以减少参数量,加速推理过程
-
残差模块中的 channel split 和 shuffle 机制可以减小网络规模,提升特征表达能力,且 channel shuffle 是可微的,意味着其可以嵌入网络进行端到端的训练。
-
解码端,使用特征金字塔注意力机制来设计APN,可以减小整个网络的复杂度。
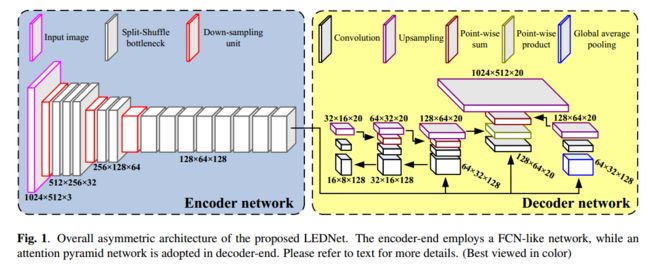
本文网络结构
2.1 带有 Split and Shuffle Operations 的残差模块
我们的重点是解决残差模块存在的效率限制,残差块是近年来用于图像分类和语义分割的较好的神经网络。
目前,已有一些轻量级网络获得了较好的效果,如 bottleneck(图2(a))、non-bottleneck-1D(图2(b))、 ShuffleNet 模型(图2(c)),其中逐点卷积使用的很多。然而,逐点的卷积很耗费算力,对轻量级网络不利。
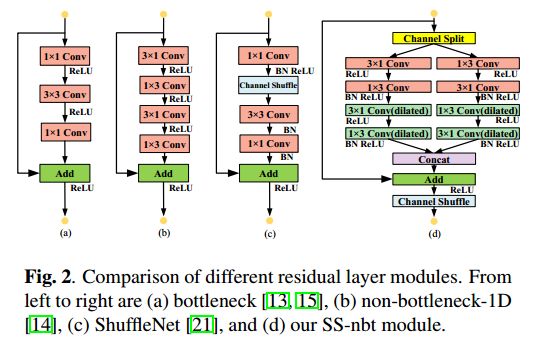
为了更好的平衡性能和效率问题,我们在 residual layer 引入了两个简单的操作,channel split 和 channel shuffle。
该模型称为 split-shuffle-non-bottleneck(SS-nbt),如图2(d)所示,受[12,18]启发, SS-nbt 的设计中使用了 split-transform-merge 策略,可以实现接近复杂网络的特征表达效果。
SS-nbt:
SS-nbt 开始时,输入被分为两个更低维的分支,每个分支的输入都是原始输入的一半,为了避免逐点卷积,卷积变换是使用一系列的特殊一维卷积核(13或31),之后将这两个子分支的卷积的输出级联合并起来,最终的通道数不变。
为了便于训练,利用 identity mapping 分支将该输出叠加到输入上,最后再次使用 channel shuffle 操作来对两个 split 分支进行信息融合。
shuffle 之后,下一个 SS-nbt 单元开始工作。显而易见,本文的 residual 模块简单且准确。
首先,每个 SS-nbt 中的高效性使得我们能够使用更多的特征 channels
其次,每个 SS-nbt 中,合并的特征 channel 随机被 shuffle,之后输入下一个单元,该过程可以看做一种特征重复使用,虽然在一定程度上增加了网络容量,但是没有显著性增加复杂性。
2.2 LEDNet 网络设计
如表1所示,LEDNet 是由编码器和解码器组成的,不同于[7],本方法使用非对称机制,其中编码器能够对特征图下采样,之后的解码器采用APN对特征图上采样,来保持和输入分辨率匹配。
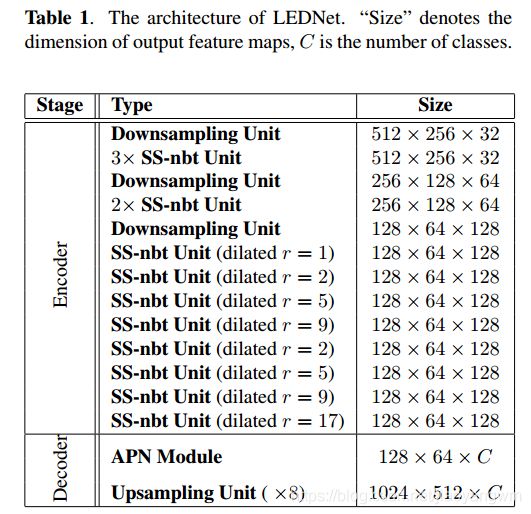
除过 SS-nbt 单元外,编码器也包括了下采样单元,该单元通过将两个并行输出进行步长为2,卷积核大小为 3*3 的最大池化来实现。
下采样使得更深层的网络能够聚焦上下文语义,同时有助于降低计算量,注意,此处将编码器放到下采样之后。
此外,使用扩张卷积使得卷积过程有更大的感受野,保证了精度的提升,这比直接使用大尺度的卷积核更好,该过程更有效。
受注意力机制启发,解码器设计了一个APN,使用 spatial-wise 来实现稠密估计。
为了提高感受野,APN 使用金字塔注意力模型,综合了三种不同层级的金字塔尺度,如图1所示,首先使用 3x3,5x5 和 7x7 的卷积核,步长为2,来获得不同层级的特征金字塔,之后金字塔结构逐步的融合不同层级的信息,可以更加精确的合并相邻层级上下文信息。
由于高层特征图分辨率低,使用大的卷积核也不会带来很大的计算开销,所以给编码器的输出特征使用 1x1 的卷积核进行卷积,之后卷积特征图逐像素的和金字塔注意力特征相乘。
为了提高性能,使用全局平均池化方式来在注意力机制之前来整合全局上下文。最后,使用上采样单元来使得特征图和输入分辨率一致。
受益于金字塔机制, APN 可以捕捉多尺度的上下文特征,并且得到像素级的注意力。
不同于 DeepLab[5] 和 PSPNet[8] 中将多尺度特征图进行堆叠的方法,本文的上下文信息和原始卷积特征是像素级相乘的,没有引入过多的计算开销。
3. 实验
3.1 实验落实细节
本文选择广泛使用的 CityScapes dataset [26] 来验证 LEDNet 的效果,该数据集包含19种不同类别的目标,和一个背景信息,有较好的像素级别的标记,包含2975个训练样本,500个验证样本,1525个测试样本,此处使用20k个粗糙标记的图像进行训练,使用类间的 mean IoU(mIoU)来估计分割准确率,使用FPS来作为速度衡量单位。
为了体现 LEDNet 的优势,我们选择了 6 种不同的轻量级网络作为基准,包括SegNet [7], ENet [13], ERFNet [14], ICNet [19], CGNet [25] 和 ESPNet [20],公平起见,所有的算法都在单个 GTX 1080Ti GPU 上实现,我们使用较大的minibatch(设置为5)来保证 GPU 内存使用的最大化,初始学习率是 5x10^-4,“poly” 学习率动量采样0.9,动量和权值衰减分别设置为0.9和 10^-4。
3.2 实验结果
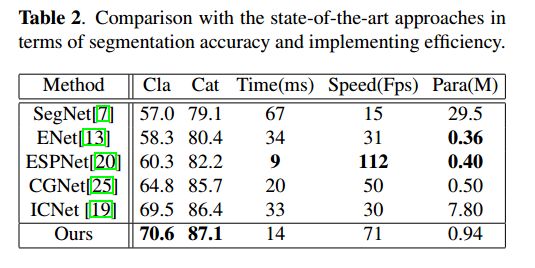
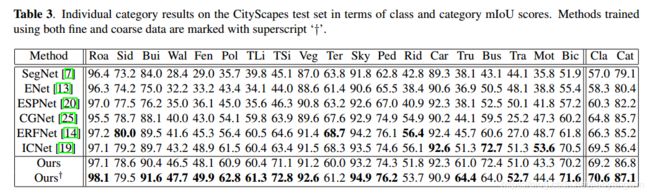
表2和表3呈现了对比结果,结果表明 LEDNet 达到了准确率和效率的最好平衡,
所有方法中, LEDNet 获得了 70.6% 的 class mIoU(细类别),和81.7%的 category mIoU(粗类别),共19个 category,有13个都达到了最好的效果。
LEDNet 比 SegNet[7] 快5倍多,模型是其1/30 左右
LEDNet 比 ENet[7] 快1.5倍多,模型参数是其1/3左右,准确率高10%左右
图3展示了一些可视化输出,从图中可知,LEDNet 不仅仅能够正确的分类不同尺度的目标,也可以对所有类别获得更好的效果。
4. 总结和展望
本文提出了 LEDNet,使用非对称的编码-解码机制进行实时语义分割,编码器在 residual layer 使用 channel split 和 channel shuffle 操作,以特征重复利用的方式来增强信心直接的融合交流。
另一方面,解码器使用 APN,其空域金字塔结构有益于在扩大感受野的同时不引入过大的计算开销。
网络可以端到端的训练
实验结果表明,LEDNet 达到了 CityScapes dataset 的分割效果和实施效率的最好平衡。
未来的工作中,可以对标准卷积分解成1维卷积,可以在获得更简单网络的同时保持分割效果。
