Datawhale7月组队学习task5模型建立和评估
Datawhale7月组队学习task5模型建立和评估
文章目录
- Datawhale7月组队学习task5模型建立和评估
-
- 引入
-
-
-
- preparation
-
-
- 一.模型搭建和评估--建模
-
- 模型搭建
-
- 1.任务一:切割训练集和测试集
- 2.任务二:模型创建
- 3.任务三:输出模型预测结果
- 二.模型搭建和评估-评估
-
- 模型评估
-
- 1.任务一:交叉验证
-
- 提示4
- 思考4
- 2.任务二:混淆矩阵
-
- 提示5
- 3.任务三:ROC曲线
-
- 提示6
- 思考6
- 三.感谢Datawhale
引入
经过前面的两章的知识点的学习,可以对数数据的本身进行处理,比如数据本身的增删查补,还可以做必要的清洗工作。那么下面我们就要开始使用我们前面处理好的数据了。这一章我们要做的就是使用数据,我们做数据分析的目的也就是,运用我们的数据以及结合我的业务来得到某些我们需要知道的结果。那么分析的第一步就是建模,搭建一个预测模型或者其他模型;我们从这个模型的到结果之后,我们要分析我的模型是不是足够的可靠,那我就需要评估这个模型。
我们拥有的泰坦尼克号的数据集,那么我们这次的目的就是,完成泰坦尼克号存活预测这个任务
preparation
引入库和数据集
2
import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns from IPython.display import Image%matplotlib inlineplt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签 plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号 plt.rcParams['figure.figsize'] = (10, 6) # 设置输出图片大小%matplotlib inline #能在控制台生成图像plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签 plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号 plt.rcParams['figure.figsize'] = (10, 6) # 设置输出图片大小# 读取原数据数集 train = pd.read_csv('train.csv')#读取清洗过的数据集 data = pd.read_csv('clear_data.csv')
一.模型搭建和评估–建模
模型搭建
我们这里使用一个机器学习最常用的一个库(sklearn)来完成我们的模型的搭建
1.任务一:切割训练集和测试集
【思考】
-
划分数据集的方法有哪些?
sklearn数据集分割方法汇总
-
为什么使用分层抽样,这样的好处有什么?
分层抽样的优缺点
from sklearn.model_selection import train_test_split
X = data
y = train['Survived']
# 对数据集进行切割
X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y, random_state=0)
# 查看数据形状
X_train.shape, X_test.shape
【思考】
-
什么情况下切割数据集的时候不用进行随机选取
数据集本身随机性较高
2.任务二:模型创建
- 创建基于线性模型的分类模型(逻辑回归)
- 创建基于树的分类模型(决策树、随机森林)
- 分别使用这些模型进行训练,分别的到训练集和测试集的得分
- 查看模型的参数,并更改参数值,观察模型变化
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
默认参数逻辑回归模型:
lr = LogisticRegression()
lr.fit(X_train, y_train)
查看训练集和测试集score值:
print("Training set score: {:.2f}".format(lr.score(X_train, y_train)))
print("Testing set score: {:.2f}".format(lr.score(X_test, y_test)))
调整参数后的逻辑回归模型:
lr2 = LogisticRegression(C=100)
lr2.fit(X_train, y_train)
print("Training set score: {:.2f}".format(lr2.score(X_train, y_train)))
print("Testing set score: {:.2f}".format(lr2.score(X_test, y_test)))
默认参数的随机森林分类模型:
rfc = RandomForestClassifier()
rfc.fit(X_train, y_train)
print("Training set score: {:.2f}".format(rfc.score(X_train, y_train)))
print("Testing set score: {:.2f}".format(rfc.score(X_test, y_test)))
调整参数后的随机森林分类模型:
rfc2 = RandomForestClassifier(n_estimators=100, max_depth=5)
rfc2.fit(X_train, y_train)
print("Training set score: {:.2f}".format(rfc2.score(X_train, y_train)))
print("Testing set score: {:.2f}".format(rfc2.score(X_test, y_test)))
【思考】
- 为什么线性模型可以进行分类任务,背后是怎么的数学关系
- 对于多分类问题,线性模型是怎么进行分类的

3.任务三:输出模型预测结果
- 输出模型预测分类标签
- 输出不同分类标签的预测概率
预测标签
pred = lr.predict(X_train)
可以看到0和1的数组
pred[:10]
预测标签概率
pred_proba = lr.predict_proba(X_train)
【思考】
-
预测标签的概率对我们有什么帮助
评判结果的可信度
二.模型搭建和评估-评估
引入
根据之前的模型的建模,我们知道如何运用sklearn这个库来完成建模,以及我们知道了的数据集的划分等等操作。那么一个模型我们怎么知道它好不好用呢?以至于我们能不能放心的使用模型给我的结果呢?那么今天的学习的评估,就会很有帮助。
from sklearn.model_selection import train_test_split
# 一般先取出X和y后再切割,有些情况会使用到未切割的,这时候X和y就可以用,x是清洗好的数据,y是我们要预测的存活数据'Survived'
data = pd.read_csv('clear_data.csv')
train = pd.read_csv('train.csv')
X = data
y = train['Survived']
# 对数据集进行切割
X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y, random_state=0)
# 默认参数逻辑回归模型
lr = LogisticRegression()
lr.fit(X_train, y_train)
模型评估
1.任务一:交叉验证
- 用10折交叉验证来评估之前的逻辑回归模型
- 计算交叉验证精度的平均值
#提示:交叉验证
Image('Snipaste_2020-01-05_16-37-56.png')
提示4
- 交叉验证在sklearn中的模块为
sklearn.model_selection
from sklearn.model_selection import cross_val_score
lr = LogisticRegression(C=100)
scores = cross_val_score(lr, X_train, y_train, cv=10)
# k折交叉验证分数
scores
# 平均交叉验证分数
print("Average cross-validation score: {:.2f}".format(scores.mean()))
思考4
-
k折越多的情况下会带来什么样的影响?
k折越多,评估结果的稳定性越高
2.任务二:混淆矩阵
- 计算二分类问题的混淆矩阵
- 计算精确率、召回率以及f-分数
【思考】什么是二分类问题的混淆矩阵,理解这个概念,知道它主要是运算到什么任务中的
混淆矩阵
提示5
from sklearn.metrics import confusion_matrix
# 训练模型
lr = LogisticRegression(C=100)
lr.fit(X_train, y_train)
# 模型预测结果
pred = lr.predict(X_train)
# 混淆矩阵
confusion_matrix(y_train, pred)
from sklearn.metrics import classification_report
# 精确率、召回率以及f1-score
print(classification_report(y_train, pred))
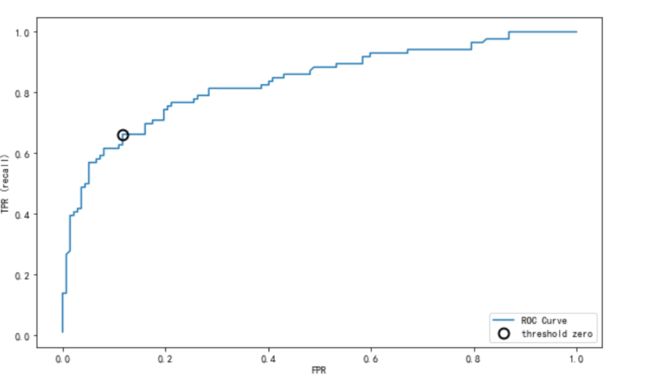
3.任务三:ROC曲线
- 绘制ROC曲线
【思考】什么是OCR曲线,OCR曲线的存在是为了解决什么问题?
什么是ROC曲线?为什么要使用ROC
提示6
- ROC曲线在sklearn中的模块为
sklearn.metrics - ROC曲线下面所包围的面积越大越好
from sklearn.metrics import roc_curve
fpr, tpr, thresholds = roc_curve(y_test, lr.decision_function(X_test))
plt.plot(fpr, tpr, label="ROC Curve")
plt.xlabel("FPR")
plt.ylabel("TPR (recall)")
# 找到最接近于0的阈值
close_zero = np.argmin(np.abs(thresholds))
plt.plot(fpr[close_zero], tpr[close_zero], 'o', markersize=10, label="threshold zero", fillstyle="none", c='k', mew=2)
plt.legend(loc=4)
思考6
-
对于多分类问题如何绘制ROC曲线
ROC曲线绘制(python+sklearn+多分类)
三.感谢Datawhale
之前在了解数据科学竞赛的时候,偶然发现了datawhale这样一个组织,现在发现真的是个宝!
这种引导式的学习方式,还有开源的理念,都让一个我这样大一的计算机学生感觉看到了另一个世界!
8月的组队学习再见!