DataWhale 6月组队学习——动手学数据分析 Task04
2 第二章:数据可视化
2.1 导入相应的包和数据
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns # 多用于统计画图
#加载并查看result.csv这个数据
result=pd.read_csv('result.csv')
result.shape
result.head() # 查看数据
【思考】最基本的可视化图案有哪些?分别适用于那些场景?(比如折线图适合可视化某个属性值随时间变化的走势)
最基本的可视化图案包括以下几种:
(1)折线图。折线图一般描述趋势,变量在时间维度上的变化
(2)散点图。两个数字型变量之间的相关性 以及 其他关系等
(3)条形图。能够使人们一眼看出各个数据的大小。易于比较数据之间的差别。能清楚的表示出数量的多少。
(4)饼图。用扇形的面积表示部分在总体中所占的百分比。易于显示每组数据相对于总数的大小。
(5)玫瑰花图。用于广告、宣传等画面具有新意。
(6)swarm图——展现数据的分布情况,如展现类似密度曲线和频数分布的类似内容。
(7)heatmap图——展现不同变量之间的相关关系。
(8)箱线图——展现一组数据的四位数下的分布情况,可以用于异常检测
(9)配对图——展现多个数值变量两两之间的关系——多变量相关图
(10)jointplot图——联合分布图(双变量图)jointplot把描述变量的分布图(一维)和变量相关的散点图(二维)组合在一起,是相关性分析最常用的工具,图片上还能展示回归曲线,以及相关系数 针对数值型变量。
2.2 任务二:可视化展示泰坦尼克号数据集中男女中生存人数分布情况
#代码编写
sex=result.groupby('Sex')['Survived'].sum() # 首先按性别进行分组,再对幸存者进行数量加总
plt.figure(figsize=(8,6)) # 制定画布大小
position=['male','female'] # 每个bar存放的对应的位置坐标(横轴坐标)
plt.bar(position,sex,label='survived',width=0.3) # width整个bar的宽度是0.3,则对应position左右各0.15
## 添加数据标签
for a,b in zip(position,sex): ## a和b分别从po和male里面取元素,同时取外面加个zip函数 这里a,b代表数据标签的横纵坐标
plt.text(a,b+0.05,'%.f'%b,ha='center',va='bottom',fontsize=12) # '%.1f'是将该浮点数(float)保留一位小数
## horizontalalignment(ha):设置垂直对齐方式,可选参数:left,right,center
## verticalalignment(va):设置水平对齐方式 ,可选参数 : ‘center’ , ‘top’ , ‘bottom’ ,‘baseline’
## rotation(旋转角度):可选参数为:vertical,horizontal 也可以为数字 alpha:透明度,参数值0至1之间
## backgroundcolor:字体背景颜色
plt.xlabel('sex',fontsize=14)
plt.ylabel('count',fontsize=14) # 纵轴标签
plt.title('Survived_count',fontsize=14) # 制定标题
plt.legend(loc='best')
plt.show() # 图形显示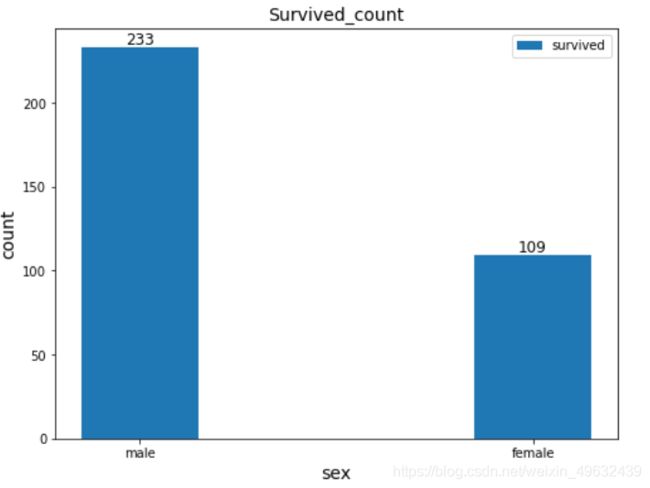
【思考】计算出泰坦尼克号数据集中男女中死亡人数,并可视化展示?如何和男女生存人数可视化柱状图结合到一起?看到你的数据可视化,说说你的第一感受。
从可视化结果来看,在幸存者中男性的数量明显多于女性,且为2倍以上。初步说明,性别可能会影响存活率。
2.3 任务三:可视化展示泰坦尼克号数据集中男女中生存人与死亡人数的比例图(用柱状图试试)。
#代码编写
# 提示:计算男女中死亡人数 1表示生存,0表示死亡
sex_2=result.groupby(['Sex','Survived'])['Survived'].count().unstack()
plt.figure(figsize=(8,6))
sex_2.plot(kind='bar',stacked='True')
plt.xlabel('Sex',fontsize=14)
plt.ylabel('Counts',fontsize=14)
plt.show()
2.4 任务四:可视化展示泰坦尼克号数据集中不同票价的人生存和死亡人数分布情况。(用折线图试试)(横轴是不同票价,纵轴是存活人数)
# 对数据排序下的可视化展示
# 求取不同票价下的死亡和存活的人数
fare_sur=result.groupby(['Fare'])['Survived'].value_counts().sort_values(ascending=False)
# fare_sur2=pd.DataFrame(fare_sur)
# # fare_sur2.to_excel('1.xlsx',index=False)
# fare_sur2.head()
plt.figure(figsize=(15,12))
fare_sur.plot(grid=True,color='r') # grid 参数添加网格线
plt.xlabel('fare_sur',fontsize=15)
plt.ylabel('counts',fontsize=15)
plt.legend()
plt.show()
# 不对数据进行排序下的图形展示
fare_sur3=result.groupby(['Fare'])['Survived'].value_counts()
plt.figure(figsize=(15,12))
fare_sur3.plot(grid=True,color='b') # grid 参数添加网格线
plt.xlabel('fare_sur',fontsize=15)
plt.ylabel('counts',fontsize=15)
plt.legend()
plt.show()

2.5 任务五:可视化展示泰坦尼克号数据集中不同仓位等级的人生存和死亡人员的分布情况。(用柱状图试试)
#代码编写
# 1表示生存,0表示死亡
pclass_sur=result.groupby(['Pclass'])['Survived'].value_counts()
pclass_sur## sns.countplot()方法介绍说明:
countplot是seaborn库中分类图的一种,作用是使用条形显示每个分箱器中的观察计数。
* countplot方法中必须要x或者y参数,不然就报错。
x: x轴上的条形图,以x标签划分统计个数
y: y轴上的条形图,以y标签划分统计个数
hue: 在x或y标签划分的同时,再以hue标签划分统计个数
sns.countplot(x='Pclass',hue='Survived',data=result)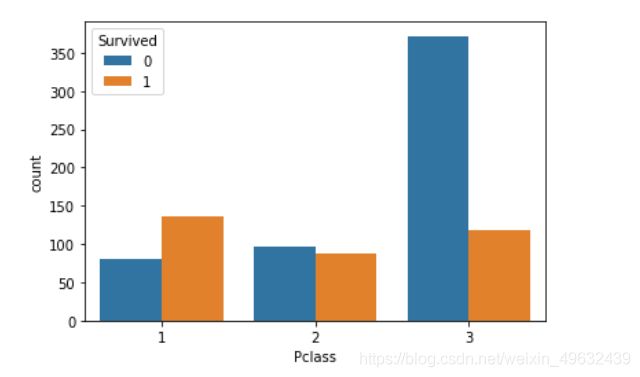
#思考题回答
基于上述数据可视化分析,有以下感受和总结:
(1)在数据可视化展示上,发现折线图适合于表达某一变量下的数据变化趋势,更加的直观;
而条形图和柱状图更加直观的展现了数据量的对比,不同类别下数据量的大小。
(2)对样本数据的分析,可以发现性别、票价和舱位对于乘客是否幸存有着一定的影响。
其中,男性的存活数高于女性,高票价和高级舱位的人员的存活数高于低票价和低舱位的人员。
同时也发现从人员数量上看,2等舱位的人员存活数少于3等舱位,但从占比情况来看1,2等舱位的存活率显著高于3等舱位。
2.6 任务六:可视化展示泰坦尼克号数据集中不同年龄的人生存与死亡人数分布情况。
#代码编写
facet=sns.FacetGrid(data=result,hue='Survived',aspect=3) # 构建结构化多绘图网格
facet.map(sns.kdeplot,'Age',shade=True) # 将绘图功能应用于每个方面的数据子集。
facet.set(xlim=(0,result['Age'].max()))
facet.add_legend()
2.7 任务七:可视化展示泰坦尼克号数据集中不同仓位等级的人年龄分布情况。
#代码编写
plt.figure(figsize=(10,8))
result.Age[result.Pclass==1].plot(kind='kde')
result.Age[result.Pclass==2].plot(kind='kde')
result.Age[result.Pclass==3].plot(kind='kde')
plt.ylabel('Density',fontsize=15)
plt.xlabel('Age',fontsize=15)
plt.legend(('class 1','class 2','class 3'),loc='best',fontsize=15)