论文阅读报告:ReliefF for Multi-label Feature Selection,Newton Spolaˆor, 2013
文章目录
- 1. 多标签知识
-
- 1.1 多标签数据(Multi-label data)
- 1.2 差异函数(Dissimilarity function)
- 2. 算法
- 3. 原文
1. 多标签知识
1.1 多标签数据(Multi-label data)
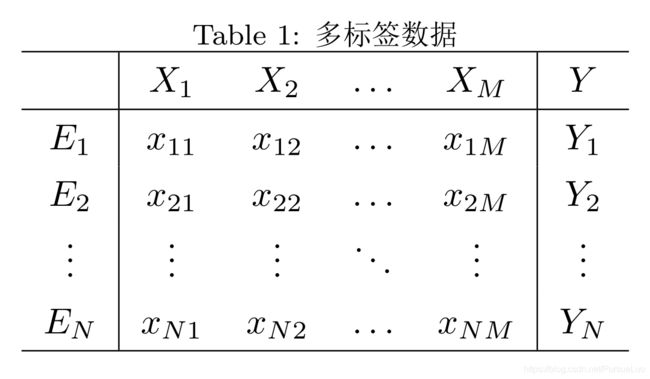
其中:
D D D 是多标签数据集;
X j X_j Xj 是第 j j j 个特征(属性), j = 1 , 2 , … , M j=1,2,\dots,M j=1,2,…,M;
x i = ( x i 1 , x i 2 , … , x i M ) \bm{x}_i = (x_{i1},x_{i2}, \dots, x_{iM}) xi=(xi1,xi2,…,xiM) 是包含 M M M 个特征的向量;
L = { y 1 , y 2 , … , y q } L=\{y_1,y_2,\dots,y_q\} L={y1,y2,…,yq} 是数据集 D D D 的 q q q 个可能标签;
Y i Y_i Yi 是和 x i \bm{x}_i xi 关联的标签集合, Y i ⊆ L Y_i \subseteq L Yi⊆L;
E i = ( x i , Y i ) E_i = (\bm{x}_i, Y_i) Ei=(xi,Yi) 是第 i i i 个样本, i = 1 , 2 , … , N i = 1, 2, \dots, N i=1,2,…,N;
1.2 差异函数(Dissimilarity function)
使用汉明距离(Hamming Distance,HD)作为多标签 Y a Y_a Ya 和 Y b Y_b Yb 之间的差异函数。
记
m l d ( E a , E b ) = H D ( Y a , Y b ) mld(E_a, E_b)=HD(Y_a,Y_b) mld(Ea,Eb)=HD(Ya,Yb)
两个集合(多标签)之间 HD 定义为 ∣ Y a ∪ Y b ∣ − ∣ Y a ∩ Y b ∣ \lvert Y_a \cup Y_b \rvert - \lvert Y_a \cap Y_b \rvert ∣Ya∪Yb∣−∣Ya∩Yb∣。
它统计了 Y a Y_a Ya 和 Y b Y_b Yb 之间不同标签的数量。
假设, Y a = { y 3 , y 6 } Y_a=\{y_3,y_6\} Ya={y3,y6}, Y b = { y 1 , y 4 } Y_b=\{y_1,y_4\} Yb={y1,y4},则 H D ( Y a , Y b ) = 4 HD(Y_a,Y_b)=4 HD(Ya,Yb)=4;
又比如 Y a = { y 2 , y 3 , y 5 , y 6 } Y_a=\{y_2,y_3,y_5,y_6\} Ya={y2,y3,y5,y6}, Y b = { y 1 , y 2 , y 4 , y 5 } Y_b=\{y_1,y_2,y_4,y_5\} Yb={y1,y2,y4,y5},则 H D ( Y a , Y b ) = 4 HD(Y_a,Y_b)=4 HD(Ya,Yb)=4。
在这篇文章中,使用归一化的 HD
H D ( Y a , Y b ) = ∣ Y a ∪ Y b ∣ − ∣ Y a ∩ Y b ∣ q HD(Y_a, Y_b) = \frac{\lvert Y_a \cup Y_b \rvert - \lvert Y_a \cap Y_b \rvert}{q} HD(Ya,Yb)=q∣Ya∪Yb∣−∣Ya∩Yb∣
2. 算法

其中:
W d Y W_{dY} WdY 是标签之间的差异;
W d X W_{dX} WdX 是属性值之间的差异;
W d Y X W_{dYX} WdYX 标签和属性值之间的差异;
d ( E i , E K z ) d(E_i,EK_z) d(Ei,EKz) 是距离权重;
d i f f ( X j , E i , E K z ) diff(X_j, E_i, EK_z) diff(Xj,Ei,EKz) 计算了样本 E i E_i Ei 和 E K z EK_z EKz 在特征 X j X_j Xj 上值的差异;
W W W 代表最终特征的权重。
3. 原文
DOI 10.1109/BRACIS.2013.10